
Выходя за рамки математики, мы развиваем интуицию.
Делиться

Введение
В интернете есть множество хороших ресурсов, объясняющих архитектуру трансформатора, но вопрос о встраивании вращательного положения (RoPE) часто объясняется плохо или вовсе пропускается.
Метод RoPE был впервые представлен в статье RoFormer: Enhanced Transformer with Rotary Position Embedding, и хотя задействованные математические операции относительно просты — в основном, это операции с матрицами вращения и умножение матриц — настоящая сложность заключается в понимании интуитивного принципа его работы. Я постараюсь предложить способ визуализации того, что он делает с векторами, и объяснить, почему этот подход так эффективен.
Предполагаю, что вы имеете базовое представление о трансформерах и механизме внимания, изложенном в этом посте.
Интуиция RoPE
Поскольку трансформерам не хватает присущего им понимания порядка и расстояний, исследователи разработали позиционные эмбеддинги. Вот чего должны достигать позиционные эмбеддинги:
- Токены, расположенные ближе друг к другу, должны иметь больший вес, а токены, расположенные дальше, — меньший.
- Положение в последовательности не должно иметь значения, то есть, если два слова находятся близко друг к другу, они должны иметь больший вес друг для друга независимо от того, находятся ли они в начале или в конце длинной последовательности.
- Для достижения этих целей относительные позиционные векторные представления гораздо полезнее, чем абсолютные позиционные векторные представления.
Ключевой вывод : LLM-ы должны фокусироваться на относительном положении двух токенов, что действительно важно для механизма внимания.
Если вы понимаете эти концепты, вы уже на полпути к цели.
До появления RoPE
Исходные позиционные эмбеддинги из основополагающей статьи «Внимание — это всё, что вам нужно» были определены с помощью уравнения в замкнутой форме, а затем добавлены к семантическим эмбеддингам. Смешивание сигналов положения и семантики в скрытом состоянии было плохой идеей. Более поздние исследования подтвердили, что LLM-ы запоминают (переобучаются), а не обобщают положения, что приводит к быстрому ухудшению результатов, когда длина последовательности превышает длину обучающих данных. Но использование формулы в замкнутой форме имеет смысл, поскольку позволяет расширять её до бесконечности, и RoPE делает нечто подобное.
Одна из стратегий, доказавших свою эффективность на ранних этапах развития глубокого обучения, заключалась в следующем: если не было уверенности в том, как вычислить полезные признаки для нейронной сети, пусть сеть сама их изучит! Именно так поступали модели, подобные GPT-3 — они самостоятельно обучались построению векторных представлений позиций. Однако предоставление слишком большой свободы увеличивает риск переобучения и в данном случае создает жесткие ограничения на контекстные окна (их нельзя расширить за пределы обученного контекстного окна).
Наилучшие подходы были сосредоточены на модификации механизма внимания таким образом, чтобы близкие токены получали более высокие веса внимания, а удаленные — более низкие. Изолируя информацию о положении в механизме внимания, сохранялось скрытое состояние и фокусировалось на семантике. Эти методы в основном пытались хитро модифицировать Q и K таким образом, чтобы их скалярные произведения отражали близость. Во многих работах предлагались различные методы, но RoPE оказался лучшим решением проблемы.
Вращательная интуиция
RoPE изменяет Q и K, применяя к ним вращения. Одно из самых приятных свойств вращения заключается в том, что оно сохраняет модули вектора (размер), которые потенциально несут семантическую информацию.
Пусть q — проекция запроса для одного токена, а k — проекция ключа для другого. Для токенов, расположенных близко друг к другу в тексте, применяется минимальное вращение, тогда как для удаленных токенов применяются более значительные вращательные преобразования.
Представьте два одинаковых проекционных вектора — любое вращение уменьшит их расстояние друг от друга. Это именно то, что нам нужно.

А теперь рассмотрим потенциально запутанную ситуацию: если два проекционных вектора уже находятся далеко друг от друга, вращение может сблизить их. Это не то, что нам нужно! Они поворачиваются, потому что находятся далеко в тексте, поэтому им не следует присваивать высокий весовой коэффициент внимания. Почему это всё ещё работает?
- В двумерном пространстве существует только одна плоскость вращения (xy). Можно вращать только по часовой стрелке или против часовой стрелки.
- В трехмерном пространстве существует бесконечно много плоскостей вращения, что делает крайне маловероятным сближение двух векторов вращением.
- Современные модели работают в пространствах очень высокой размерности (более 10 000 измерений), что делает это еще менее вероятным.
Помните: в глубоком обучении вероятность имеет первостепенное значение! Допустимо иногда ошибаться, если вероятность этого невелика.
Угол поворота
Угол поворота зависит от двух факторов: m и i. Рассмотрим каждый из них.
Абсолютная позиция токена m
Вращение увеличивается по мере увеличения абсолютного положения токена m.
Я знаю, о чём вы думаете: «m — это абсолютное положение, но разве вы не говорили, что относительное положение имеет наибольшее значение?»
Вот в чём магия: рассмотрим двумерную плоскость, где один вектор повернут на α, а другой — на β. Разность углов между ними станет α-β. Абсолютные значения α и β не имеют значения, важна только их разность. Таким образом, для двух элементов в позициях m и n вращение изменяет угол между ними пропорционально mn.

Для простоты можно считать, что мы вращаем только q (это математически корректно, поскольку нас интересуют конечные расстояния, а не координаты).
Индекс скрытого состояния i
Вместо равномерного вращения по всем измерениям скрытого состояния, RoPE обрабатывает по два измерения за раз, применяя разные углы вращения к каждой паре. Другими словами, он разбивает длинный вектор на несколько пар, которые можно вращать в 2D на разные углы.
Мы по-разному вращаем измерения скрытого состояния — вращение сильнее, когда i низкое (начало вектора), и слабее, когда i высокое (конец вектора).
Понять эту операцию несложно, но для понимания того, зачем она нам нужна, требуется более подробное объяснение:
- Это позволяет модели выбирать, какие параметры должны иметь более короткий или более длинный диапазон влияния .
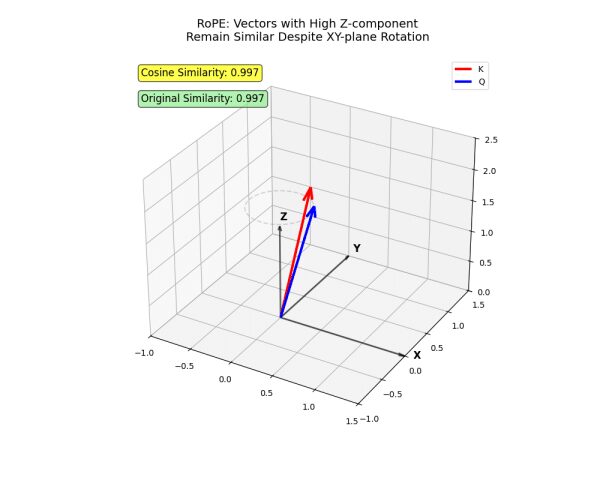
- Представьте себе векторы в трехмерном пространстве (xyz).
- Оси x и y представляют собой ранние измерения (низкий i), которые подвергаются более сильному вращению. Токены, проецируемые преимущественно на оси x и y, должны находиться очень близко друг к другу, чтобы привлекать внимание с высокой интенсивностью.
- Ось Z, где i больше, вращается меньше. Токены, спроецированные преимущественно на ось Z, могут привлекать внимание даже на значительном расстоянии.


Эта структура позволяет уловить сложные нюансы человеческого языка — довольно круто, правда?
Я знаю, о чём вы думаете: «после слишком большого вращения они снова начинают сближаться».
Это верно, но вот почему это всё ещё работает:
- Мы визуализируем в 3D, но на самом деле это происходит в гораздо более высоких измерениях.
- Хотя некоторые измерения сближаются, другие, вращающиеся медленнее, продолжают отдаляться друг от друга. Отсюда и важность вращения измерений на разные углы.
- RoPE не идеален — из-за своей вращательной природы в нем возникают локальные максимумы. См. теоретическую диаграмму от авторов оригинальной работы:

Теоретическая кривая имеет несколько неожиданных неровностей, но на практике я обнаружил, что она ведет себя гораздо спокойнее:

Одна из идей, которая мне пришла в голову, заключалась в том, чтобы ограничить угол поворота таким образом, чтобы сходство строго уменьшалось с увеличением расстояния. Я видел, как ограничение применялось в других методах, но не в RoPE.
Имейте в виду, что косинусное сходство имеет тенденцию расти (хотя и медленно) по мере того, как расстояние значительно превышает наше базовое значение (позже вы увидите, что именно представляет собой это базовое значение формулы). Простым решением здесь является увеличение базового значения или даже использование таких методов, как локальное или оконное внимание.

В итоге: LLM учит проецировать смысловое влияние на дальние и ближние расстояния в различных измерениях q и k.
Вот несколько конкретных примеров зависимостей дальнего и ближнего действия:
- LLM обрабатывает код Python, в котором к датафрейму df применяется первоначальное преобразование. Эта важная информация потенциально может передаваться на большие расстояния и влиять на контекстное встраивание последующих токенов df.
- Прилагательные обычно характеризуют находящиеся рядом существительные. В предложении «Прекрасная гора простирается за долину» прилагательное «прекрасный» описывает именно гору, а не долину, поэтому оно должно в первую очередь относиться к существительному, обозначающему гору.
Формула угла
Теперь, когда вы понимаете основные понятия и обладаете развитой интуицией, вот уравнения. Угол поворота определяется следующим образом:
[text{угол} = m times theta]
[theta = 10,000^{-2(i-1)/d_{model}}]
- m — это абсолютное положение токена.
- i ∈ {1, 2, …, d/2}, представляющее измерения скрытого состояния; поскольку мы обрабатываем два измерения одновременно, нам нужно итерировать только до d/2, а не до d.
- dmodel — это размерность скрытого состояния (например, 4096).
- 10 000 — это базовое значение.
Обратите внимание, что когда:
[i=1 Rightarrow theta=1 quad text{(высокое вращение)} ]
[i=d/2 Rightarrow theta approx 1/10,000 quad text{(низкое вращение)}]
Заключение
- Нам следует искать оригинальные способы внедрения знаний в программы магистратуры, а не позволять студентам изучать все самостоятельно.
- Мы достигаем этого, предоставляя нейронной сети необходимые операции для обработки данных — отличными примерами являются механизм внимания и свертки.
- Уравнения в замкнутой форме могут быть бесконечно длинными, поскольку нет необходимости изучать каждое вложение позиции.
- Именно поэтому RoPE обеспечивает превосходную гибкость в выборе длины последовательности.
- Наиболее важное свойство: весовые коэффициенты внимания уменьшаются по мере увеличения относительного расстояния.
- Это соответствует той же интуиции, что и локальное внимание в архитектурах с чередующимся вниманием.
Источник: towardsdatascience.com

























