Этот небольшой трюк может обеспечить повышенную стабильность обучения, использование более высоких скоростей обучения и улучшенные свойства масштабирования.
Делиться

Этот небольшой трюк может обеспечить повышенную стабильность обучения, использование более высоких скоростей обучения и улучшенные свойства масштабирования.
Непреходящая популярность самой престижной конференции по искусственному интеллекту
По общему мнению, конференция NeurIPS этого года, ведущая мировая конференция по искусственному интеллекту, стала одной из крупнейших и наиболее активных в своей истории. В этом году конференция проходила в конференц-центре Сан-Диего, штат Калифорния, с воскресенья, 30 ноября 2025 года, по воскресенье, 7 декабря 2025 года. Чтобы оценить масштаб, NeurIPS 2025 получила 21 575 действительных заявок на доклады. По сравнению с 2023 годом (~12,3 тыс.) и 2025 годом (~21,6 тыс.) это отражает рост примерно на 75–80% за два года, что составляет примерно 30% в среднем за год. Посещаемость очных мероприятий также впечатляет: обычно десятки тысяч человек, как правило, ограничены размером площадки, а в прошлые годы места проведения работали на пределе своих физических возможностей. В этом году в центре внимания было обучение с подкреплением, и в этой области происходит переход от масштабирования моделей к их настройке для конкретных сценариев использования. В центре внимания отрасли, похоже, находилась компания Google, особенно Google DeepMind, которая демонстрировала стремительный рост и продвигала новые, перспективные направления исследований, например, непрерывное обучение и вложенное обучение, а не просто «более крупные магистерские программы». Масштаб и интенсивность конференции, возможно, отражают как темпы прогресса в области ИИ, так и культурный пик современной «золотой лихорадки» в сфере ИИ.

В этом году выставочный зал был переполнен: ведущие игроки отрасли из сферы технологий, финансов и инфраструктуры ИИ разместили свои стенды, чтобы продемонстрировать свои последние достижения, рассказать об открытых вакансиях для талантливых участников и раздать желанные фирменные сувениры — ручки, футболки, бутылки для воды и многое другое. Особенно удачливые участники конференции могли даже получить приглашение на организованные компаниями «вечеринки после конференции», которые стали неотъемлемой частью NeurIPS и идеальной возможностью расслабиться, избавиться от информационной перегрузки и наладить контакты, от Laude Lounge в Konwinski до закрытого круиза на модельном судне, где собираются ведущие исследователи. В этом году бриллиантовыми спонсорами стали Ant Group, Google, Apple, ByteDance, Tesla и Microsoft. В этом году особенно сильным было присутствие инвестиционных компаний, таких как Citadel, Citadel Securities, Hudson River Trading, Jane Street, Jump Trading и The DE Shaw Group. Что касается инфраструктуры и инструментов, Lambda продемонстрировала свою облачную платформу на базе графических процессоров, а такие компании, как Ollama и Poolside, рассказали о достижениях в области локальных сред выполнения LLM и разработке передовых моделей.

На выставке NeurIPS Expo было представлено множество не менее интересных демонстраций прикладного ИИ. Среди наиболее ярких моментов — BeeAI, демонстрирующая, как автономные агенты могут надежно работать с различными бэкэндами LLM; многомодальная система криминалистического поиска, способная сканировать большие видеоархивы с помощью ИИ; демонстрация ускоренной обработки LiDAR с использованием ИИ, показывающая, как гетерогенные вычисления могут значительно ускорить 3D-восприятие; и рабочие процессы обработки данных на основе LLM, автоматизирующие ввод, преобразование и проверку качества. Из выставки становится ясно, что ИИ полным ходом движется к агентам, многомодальному интеллекту, ускоренному восприятию и сквозным автоматизированным системам обработки данных.

Церемония вручения премии NeurIPS за лучшую статью, пожалуй, является кульминацией конференции и чествованием наиболее значимых работ. Премии за лучшие статьи присуждаются за исключительно инновационные и значимые исследования, которые, вероятно, окажут немедленное и долгосрочное влияние на область искусственного интеллекта. Само собой разумеется, что премия за лучшую статью — это крупное профессиональное достижение в высококонкурентной и быстро развивающейся области исследований. Это еще более впечатляет, если учесть огромный объем статей, представленных на NeurIPS. Выделиться из этой толпы чрезвычайно сложно.
Анатомия лучшей статьи NeurIPS: Изучение преимуществ метода «вентилируемого внимания» в магистерских программах.
Объяснение принципа работы вентиля: как крошечный клапан управляет большими нейронными моделями
В оставшейся части статьи мы подробно рассмотрим одну из лучших работ этого года с конференции NeurIPS: «Вентиляторное внимание для больших языковых моделей: нелинейность, разреженность и отсутствие механизма «отсечки внимания»» команды Qwen. Можно утверждать, что это объемное название статьи вмещает много информации в очень небольшой объем, поэтому далее я разберу статью по частям с целью дать практикующим специалистам по анализу данных четкую ментальную модель механизма «вентиляторного внимания» и конкретные выводы из статьи, которые они смогут немедленно применить в своей работе.
Для начала разберемся, что такое вентиль — основной модуль, изучаемый в данной статье. Что же такое вентиль в контексте нейронных сетей? Вентиль — это не что иное, как механизм модуляции сигнала, вычислительная единица, которая принимает выход существующего преобразования в сети и регулирует его путем избирательного усиления, ослабления или подавления частей входного сигнала.
Вместо того чтобы позволять каждой активации проходить через сеть без изменений, вентиль вводит обученный управляющий путь, который определяет, какая часть преобразованной информации должна передаваться дальше.
С точки зрения функционирования, вентиль вычисляет вектор коэффициентов, обычно используя сигмоидную функцию, функцию softmax или, иногда, функцию сжатия на основе ReLU, и эти коэффициенты применяются умножительно к другому вектору активаций, полученному в результате вычислений на предыдущем этапе. Это позволяет регулировать объем входных данных, поступающих на следующий этап, подобно тому, как вы регулируете объем воды, проходящей через кран, поворачивая ручку крана туда-обратно. Вот и все, теперь вы понимаете, что такое вентиль, что это такое и как он применяется.

Поскольку весовые коэффициенты вентиля обычно являются обучаемыми параметрами, сеть может в процессе обучения определить, как модулировать внутренние сигналы таким образом, чтобы минимизировать общие потери сети. Таким образом, вентиль становится динамическим фильтром, регулирующим поток внутренней информации на основе контекста входных данных, постоянно изменяющихся параметров модели и градиентов, полученных в процессе оптимизации.
Краткий экскурс в прошлое: долгая история создания ворот для людей с ограниченными возможностями.
Прежде чем перейти к основным результатам работы, стоит немного ознакомиться с историей механизма управления потоком информации (Gating). Gating — это не что-то новое, и статья Квена не изобрела этот стандартный компонент; их вклад лежит в другой области и будет рассмотрен чуть позже. Фактически, механизм управления потоком информации является ключевым в глубоких архитектурах уже много десятилетий. Например, сети с долговременной кратковременной памятью (LSTM), представленные в 1997 году, первыми начали систематически использовать мультипликативные вентили — вентили ввода, забывания и вывода — для регулирования потока информации во времени. Эти вентили действуют как обученные фильтры, определяющие, какие сигналы должны быть записаны в память, какие должны быть сохранены, а какие должны быть переданы нижестоящим слоям. Контролируя поток информации таким тонким образом, LSTM эффективно смягчили мультипликативный взрыв или исчезновение градиентов, которые препятствовали развитию ранних рекуррентных сетей, обеспечивая стабильное долговременное распределение кредитов во время обратного распространения ошибки во времени (BPTT).
Применение механизма «гейтинга» к блоку внимания в рамках программы LLM.
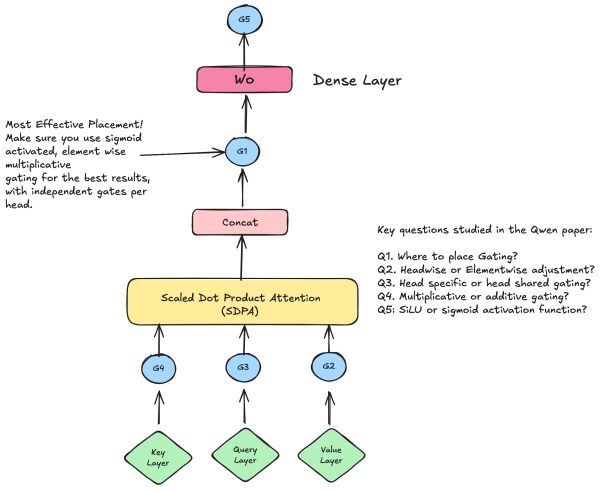
Вклад команды Qwen сосредоточен на применении механизма внимания softmax непосредственно к механизму внимания трансформера, а именно на особом типе конфигурации, называемом механизмом внимания. В этой статье я не буду подробно останавливаться на сути механизма внимания, поскольку существует множество ресурсов для его изучения, включая этот недавний курс от команды DeepLearning.ai и мою предыдущую статью на эту тему. Вкратце, внимание — это основной механизм в архитектуре трансформера, который позволяет каждому токену входной последовательности собирать контекстную информацию от любого другого токена в последовательности, обеспечивая «коммуникацию» токенов во время обучения и вывода, обмен информацией независимо от того, насколько далеко друг от друга они находятся во входных данных. Вычислительный граф для популярного механизма внимания с масштабированным скалярным произведением (SDPA) показан ниже:

Хотя механизм управления вниманием используется уже много лет, команда Qwen указывает на удивительный пробел в наших знаниях: как специалисты в области ИИ, мы широко применяли этот механизм, не понимая до конца, почему он работает и как влияет на динамику обучения. Работа команды Qwen показывает, что мы долгое время пользовались преимуществами этого модуля, не имея строгого, систематического описания его эффективности или условий, при которых он работает наилучшим образом. Статья Qwen как раз и заполняет этот пробел, о чем свидетельствует упоминание в цитате комитета по отбору лучшей статьи NeurIPS:
«Эта статья представляет собой значительный объем работы, которая стала возможной только при наличии доступа к вычислительным ресурсам промышленного масштаба, и то, что авторы поделились результатами своей работы, которые будут способствовать углублению понимания механизмами внимания в больших языковых моделях, заслуживает всяческой похвалы, особенно в условиях, когда наблюдается отход от открытого обмена научными результатами, касающимися больших языковых моделей».
Заявление Специального комитета конференции NeurIPS 2025.
Учитывая огромные финансовые вложения и колоссальный коммерческий интерес к ИИ в наши дни, очень приятно видеть, что команда Qwen решила поделиться этим ценным опытом с более широким сообществом, а не держать эти ценные сведения за закрытыми дверями. Таким образом, команда Qwen подготовила прекрасную статью, наполненную практическими уроками и четкими объяснениями причин работы механизма «внимания», изложенными в доступной форме, которую специалисты по анализу данных могут немедленно применить в реальных моделях.
Систематическое исследование команды Qwen вносит ряд конкретных вкладов в знания, которые можно легко и незамедлительно применить для улучшения многих стандартных архитектур LLM:
- Расположение модуля управления: размещение модуля управления непосредственно после вычисления матрицы значений обеспечивает улучшенную производительность LLM за счет введения нелинейности и создания разреженности, зависящей от входных данных. Также изучаются ключевые параметризации модуля управления, такие как тип функции активации (SiLU или сигмоидная) и функция комбинации (умножение, сложение).
- Эффект «поглощения внимания» и массовые активации: управление может радикально ограничить эффект «поглощения внимания», когда большая часть, если не всё внимание в слое, концентрируется на одном токене — я подробно расскажу об этом явлении позже. Подавление этих экстремальных активаций делает модель гораздо более численно стабильной во время оптимизации, устраняя скачки потерь, которые обычно появляются при глубоких или длительных обучающих циклах. Эта повышенная стабильность позволяет модели выдерживать значительно более высокие темпы обучения, обеспечивая лучшее масштабирование без расхождения, наблюдаемого в трансформерах без управления.
- Расширение длины контекста: Функция Gating также облегчает расширение длины контекста без необходимости полной переобучения модели. На практике это означает, что модель может быть обучена с относительно коротким контекстным окном, а затем масштабирована до гораздо более длинных последовательностей путем ретроспективной корректировки таких компонентов, как базовый RoPE. Эта корректировка фактически перепараметризует геометрию позиционного встраивания, позволяя модели работать с расширенной длиной контекста (например, до 32 000 токенов), сохраняя при этом стабильность и не ухудшая ранее изученные представления.

Использование механизма управления вниманием для повышения эффективности, стабильности обучения и улучшения механизмов концентрации внимания.
В своих исследованиях команда Qwen сосредоточилась на том, как механизм управления потоком данных взаимодействует с модулем внимания softmax в LLM, стремясь понять его влияние на динамику обучения модуля и определить оптимальное расположение механизма управления потоком данных — например, после проекций Q, K или V, после вычисления внимания или после плотных слоев. Схема исследования представлена на диаграмме ниже:

Авторы оценивают модели на основе смешанных экспертов — MoE (15 млрд, 2,54 млрд активных) и плотных (1,7 млрд) — сетей прямого распространения (FFN). Вариант MoE использует 128 экспертов, топологию softmax top-8 и мелкозернистых экспертов. Модели обучаются на подмножествах высококачественного корпуса из 4T токенов, охватывающего многоязычные, математические и общезнательные данные, с длиной последовательности 4096. Обучение использует настройки AdamW по умолчанию, при этом конкретные параметры скорости обучения и размера пакета предоставляются для каждого эксперимента. Они обнаружили, что использование топологий добавляет минимальные накладные расходы — задержка <2%. Оценка охватывает стандартные тесты с малым количеством примеров: HellaSwag, MMLU, GSM8K, HumanEval, C-Eval и CMMLU, а также тесты на перплексию в различных областях, включая английский, китайский, программирование, математику, право и литературу.
Экспериментальная оценка организована таким образом, чтобы систематически изучить следующие вопросы. Под каждым исследовательским вопросом я также привожу основные выводы, которые в равной степени применимы к моделям MoE и FFN, протестированным авторами:
В1: Где лучше всего разместить механизм управления вниманием? После проекций K, Q, V? После механизма управления вниманием на основе масштабированного скалярного произведения? После финальной конкатенации многоголовочного механизма управления вниманием?
- Авторы обнаружили, что наиболее эффективными вариантами размещения являются вставка стробирующих элементов на выходе модуля внимания с масштабированным скалярным произведением (SDPA) или после карты значений (G2).
- Кроме того, размещение внимания в SDPA более эффективно, чем в G2. Для объяснения этого авторы показывают, что размещение внимания в SDPA приводит к очень низким показателям разреженного размещения внимания, что коррелирует с более высокими показателями выполнения задачи.
- Фильтрация по значению (G2) дает более высокие, менее разреженные оценки и работает хуже, чем фильтрация на выходе SDPA (G1). Разреженность является ключевым фактором производительности. Это говорит о том, что разреженность наиболее полезна, когда фильтрация зависит от текущего запроса, позволяя модели отфильтровывать нерелевантный контекст. Фильтрация решает, что подавлять или усиливать в зависимости от потребностей текущего токена.

- Их эксперименты с независимым от входных данных управлением подтверждают это: оно обеспечивает незначительные преимущества за счет добавления нелинейности, но не обладает избирательной разреженностью, обеспечиваемой управлением, зависящим от запроса.
Вышеизложенное лучше всего объяснить на примере. Хотя карты K и V технически зависят от входных данных, они не обусловлены текущим токеном запроса. Например, если запрос — «Париж», то токены значений могут быть «Франция», «столица», «погода» или «Эйфелева башня», но каждый токен значения знает только свое собственное представление, а не то, что запрашивается для Парижа. G2-фильтрация основывает свое решение на самих исходных токенах, которые могут быть нерелевантны потребностям запроса. В отличие от этого, G1-фильтрация вычисляется на основе представления запроса, поэтому она может избирательно подавлять или усиливать контекст в зависимости от того, что запрос фактически пытается получить. Это приводит к более разреженной и чистой фильтрации и лучшей производительности для G1, в то время как команда Qwen обнаружила, что G2, как правило, дает более высокие, более шумные оценки и более слабые результаты.
В2: Регулируем ли мы выходные данные с помощью поэлементного умножения для точного управления или просто обучаем скалярную величину, которая грубо корректирует выходные данные?
Результаты, представленные в статье, показывают, что мультипликативный механизм управления SDPA лучше аддитивного. При использовании функции управления в механизме внимания softmax предпочтительнее умножать её выходные значения, а не складывать их.
В3: Поскольку в LLM-системах внимание обычно многоголовое, используем ли мы общие механизмы управления вниманием для всех голов или же обучаемся управлению вниманием только для одной головы?
Авторы однозначно утверждают, что управление входными и выходными сигналами должно обучаться для каждой отдельной головы, а не быть общим для всех. Они обнаружили, что при совместном использовании входных и выходных сигналов модель, как правило, выдает большие, менее избирательные значения, что снижает специализацию на уровне головы и ухудшает производительность. Напротив, управление входными и выходными сигналами, специфичное для каждой головы, сохраняет уникальную роль каждой головы и неизменно дает лучшие результаты. Интересно, что авторы заявляют, что управление входными и выходными сигналами, специфичное для каждой головы, является наиболее важным проектным решением, оказывающим наибольшее влияние на производительность, в то время как детализация управления и выбор функции активации оказывают меньшее влияние.
Вопрос 4: Мы можем модулировать выходной сигнал либо мультипликативно, либо аддитивно. Какой подход работает лучше?
Результаты, представленные в статье, показывают, что мультипликативный механизм управления SDPA лучше аддитивного. При использовании функции управления в механизме внимания softmax предпочтительнее умножать её выходные значения, а не складывать их.
В5: Какая функция активации больше подходит для модуля управления: сигмоидная или SiLU?
Сигмоидная функция превосходит SiLU при использовании в наиболее эффективной конфигурации, а именно, при поэлементном управлении выходными данными SDPA (G1). Замена сигмоидной функции на SiLU в этой конфигурации неизменно приводит к худшим результатам, что указывает на то, что сигмоидная функция является более эффективным механизмом активации для управления.
Как бороться с проблемой чрезмерного внимания
Ключевой проблемой в LLM является эффект «поглощения внимания», когда первый токен поглощает большую часть веса внимания и подавляет остальную часть последовательности, что приводит к непропорционально большим активациям, которые могут дестабилизировать обучение и исказить представления модели. Важно отметить, что команда Qwen показала, что управление может смягчить этот эффект, при этом управление выходными данными SDPA уменьшает массивные активации и эффект «поглощения внимания».

Увеличение длины контекста путем изменения базового параметра встраивания положения вращения (RoPE).
Для создания моделей с длинным контекстом команда Qwen использует трехэтапную стратегию обучения, подробно описанную ниже. Эта стратегия обучения дает дополнительное интересное представление о том, как передовые лаборатории обучают крупномасштабные модели и какие инструменты они считают эффективными:
- Расширение базы RoPE: Во-первых, они расширяют базу данных Rotary Position Embeddings (RoPE) с 10 тыс. до 1 млн, что выравнивает кривую частоты положения и обеспечивает стабильное внимание на гораздо больших расстояниях.
- Промежуточный этап обучения: команда Qwen затем продолжает обучение модели для дополнительных 80 миллиардов токенов, используя последовательности длиной 32 тысячи токенов. Эта фаза продолжения (иногда называемая «промежуточным этапом обучения») позволяет модели естественным образом адаптироваться к новой геометрии RoPE без повторного обучения всего.
- Расширение YaRN: затем они применяют Yet Another RoPE eNhancement (YaRN), чтобы увеличить длину контекста до 128 КБ без дополнительного обучения.
Давайте немного отступим назад и кратко проясним, что такое RoPE и почему это важно в LLM. Без добавления позиционной информации механизм внимания трансформера не имеет представления о том, где токены появляются в последовательности. Как и во многих методах в ИИ, в их работе лежит простая, лежащая в основе геометрическая интуиция, которая делает все действительно понятным. Это, безусловно, относится к позиционным эмбеддингам и RoPE. В простой двумерной аналогии можно представить эмбеддинги токенов как облако точек, разбросанных в пространстве, без указания их порядка или относительного расстояния в исходной последовательности.
RoPE кодирует положение, поворачивая каждый двумерный срез векторного представления запроса/ключа на угол, пропорциональный положению токена. Векторное представление разбивается на множество двумерных подвекторов, каждому из которых присваивается своя частота вращения (θ₁, θ₂, …), поэтому разные срезы вращаются с разной скоростью. Срезы с низкой частотой вращения вращаются медленно и захватывают широкую, дальнюю позиционную структуру, в то время как срезы с высокой частотой вращения вращаются быстро и захватывают тонкие, ближние связи. Вместе эти многомасштабные вращения позволяют механизму внимания определять относительные расстояния между токенами как в локальном, так и в глобальном контексте. Это прекрасная идея и реализация, и именно такие методы заставляют меня быть благодарным за работу в области искусственного интеллекта.

Ключевая идея здесь заключается в том, что относительный угол между двумя повернутыми векторами естественным образом кодирует их относительное расстояние в последовательности, позволяя механизму внимания определять порядок и расстояние только на основе геометрии. Это делает позиционную информацию свойством взаимодействия запросов и ключей. Например, если токены находятся близко друг к другу в последовательности, их повороты будут схожими, что соответствует большому скалярному произведению, дающему больший вес внимания. И наоборот, когда токены находятся дальше друг от друга, их повороты различаются сильнее, поэтому скалярное произведение между их запросами и ключами изменяется в зависимости от положения, обычно уменьшая внимание к удаленным токенам, если модель не научилась учитывать важность взаимодействий на больших расстояниях.
YaRN — это современный и гибкий способ расширения контекстного окна LLM без переобучения и без возникновения нестабильности, наблюдаемой в наивно экстраполированном RoPE. RoPE начинает давать сбои на больших расстояниях, потому что его высокочастотные вращательные измерения слишком быстро зацикливаются. Как только позиции выходят за пределы горизонта обучения, эти измерения создают повторяющиеся фазы, а это означает, что токены, находящиеся далеко друг от друга, могут казаться обманчиво похожими в позиционном пространстве. Это фазовое наложение (или совпадение) дестабилизирует внимание и может привести к его коллапсу. YaRN исправляет это, плавно растягивая частотный спектр RoPE, сохраняя позиционное поведение модели на коротких расстояниях, и постепенно интерполируя к более низким частотам для позиций на больших расстояниях. В результате получается схема позиционного встраивания, которая ведет себя естественно до 32 тыс., 64 тыс. или даже 128 тыс. токенов, с гораздо меньшими искажениями, чем старые методы NTK или линейного масштабирования. После того как было установлено, что их модель стабильна на уровне 32 тыс., команда Qwen применила YaRN для дальнейшей интерполяции частот RoPE, расширив эффективное контекстное окно до 128 тыс.
В ходе своей оценки команда Qwen обнаружила, что в пределах обученного окна размером 32 000 пикселей модели с использованием SDPA-фильтра немного превосходят базовый уровень, что указывает на то, что фильтрация улучшает динамику внимания, не нанося вреда стабильности долговременного контекста, даже при существенном масштабировании положения.
Кроме того, с использованием расширения YaRN и в режиме большого контекста они обнаружили, что сеть с управляемым входом SDPA значительно превосходит базовую модель в диапазоне длин контекста от 64 000 до 128 000. Авторы связывают это повышение производительности с ослаблением феномена «поглотителя внимания», на который, по их предположению, опирается базовая модель для распределения оценок внимания по токенам. Они выдвигают гипотезу, что модель с управляемым входом SDPA гораздо менее чувствительна к изменениям схемы кодирования позиционирования и корректировкам длины контекста, вызванным RoPE и YaRN. Применение YaRN, которое не требует дополнительного обучения, может нарушить эти усвоенные паттерны «поглотителя внимания», что приводит к наблюдаемому ухудшению производительности базовой модели. Модель с управляемым входом SDPA, напротив, не использует «поглотитель внимания» для стабилизации внимания.
Разработка собственной реализации механизма управления входными и выходными параметрами.
Прежде чем завершить, полезно будет попробовать реализовать метод искусственного интеллекта непосредственно из научной статьи, и это отличный способ закрепить ключевые концепты. С этой целью мы рассмотрим простую реализацию на Python механизма внимания с масштабированным скалярным произведением и управлением softmax.
Сначала определим наши ключевые гиперпараметры, такие как длина последовательности (seq_len), размерность скрытого слоя модели (d_model), количество голов (n_heads) и размерность голов (head_dim).
import numpy as np np.random.seed(0) # —- Игровая конфигурация —- seq_len = 4 # токены d_model = 8 # размерность модели n_heads = 2 head_dim = d_model // n_heads
Далее мы определяем несколько (фиктивных) векторных представлений токенов (просто сгенерированных случайным образом), а также наши случайно инициализированные веса проекта (не обучаемые для целей этого простого примера).
# Поддельные векторные представления токенов x = np.random.randn(seq_len, d_model) # [T, D] # —- Веса проекции —- W_q = np.random.randn(d_model, d_model) W_k = np.random.randn(d_model, d_model) W_v = np.random.randn(d_model, d_model) W_o = np.random.randn(d_model, d_model) # выходная проекция
Затем мы определяем общеизвестные алгоритмы: softmax, sigmoid, а также метод для разделения размерности D на n_heads:
def softmax(logits, axis=-1): logits = logits — np.max(logits, axis=axis, keepdims=True) exp = np.exp(logits) return exp / np.sum(exp, axis=axis, keepdims=True) def sigmoid(z): return 1 / (1 + np.exp(-z)) # —- Вспомогательная функция: разделение/объединение голов —- def split_heads(t): # [T, D] -> [H, T, Dh] return t.reshape(seq_len, n_heads, head_dim).transpose(1, 0, 2) def concat_heads(t): # [H, T, Dh] -> [T, D] return t.transpose(1, 0, 2).reshape(seq_len, d_model)
Теперь мы можем углубиться в основную реализацию механизма управления и посмотреть, как он работает на практике. Во всех приведенных ниже примерах мы используем случайные тензоры в качестве заменителей параметров управления, которые обучались бы в реальной модели от начала до конца.
#=================================================== # Прямой проход # =========================================================== def attention_with_gates(x): # 1) Линейные проекции Q = x @ W_q # [T, D] K = x @ W_k V = x @ W_v # —— G4: вентиль для запросов (после W_q) —— G4 = sigmoid(np.random.randn(*Q.shape)) Q = G4 * Q # —— G3: вентиль для ключей (после W_k) —— G3 = sigmoid(np.random.randn(*K.shape)) K = G3 * K # —— G2: вентиль включен для значений (после W_v) —— G2 = sigmoid(np.random.randn(*V.shape)) V = G2 * V # 2) Разделение на головы Qh = split_heads(Q) # [H, T, Dh] Kh = split_heads(K) Vh = split_heads(V) # 3) Масштабированное скалярное произведение Внимание на каждую голову scale = np.sqrt(head_dim) scores = Qh @ Kh.transpose(0, 2, 1) / scale # [H, T, T] attn = softmax(scores, axis=-1) head_out = attn @ Vh # [H, T, Dh] # 4) Объединение голов multi_head_out = concat_heads(head_out) # [T, D] # —— G1: вентиль на объединенных головках (до W_o) —— G1 = sigmoid(np.random.randn(*multi_head_out.shape)) multi_head_out = G1 * multi_head_out # 5) Проекция выходных данных y = multi_head_out @ W_o # [T, D] # —— G5: вентиль на конечном плотном выходе —— G5 = sigmoid(np.random.randn(*y.shape)) y = G5 * y return { «Q»: Q, «K»: K, «V»: V, «G2»: G2, «G3»: G3, «G4»: G4, «multi_head_out»: multi_head_out, «G1»: G1, «final_out»: y, «G5»: G5, } out = attention_with_gates(x) print(«Форма конечного выхода:», out[«final_out»].shape)
Приведённый выше код вставляет модули управления в четырёх местах, воспроизводя расположение, описанное в статье Qwen: карта запросов (G4), карта ключей (G3), карта значений (G2) и выход модуля SDPA (G1). Хотя команда Qwen рекомендует на практике использовать только конфигурацию G1 — размещая один модуль управления на выходе SDPA — мы включили здесь все четыре для иллюстрации. Цель состоит в том, чтобы показать, что управление — это просто лёгкий механизм модуляции, применяемый к различным путям внутри блока внимания. Надеемся, это сделает общую концепцию более конкретной и интуитивно понятной.
Выводы и заключительные мысли
В этой статье мы кратко рассмотрели концепцию управления вниманием softmax в больших языковых моделях и изучили ключевые выводы из статьи «Управляемое внимание для больших языковых моделей: нелинейность, разреженность и отсутствие «поглотителя внимания», представленной на конференции NeurIPS 2025.
Статья Qwen — это шедевр в области искусственного интеллекта и кладезь практических результатов, которые можно немедленно применить для улучшения большинства современных архитектур LLM. Команда Qwen провела исчерпывающее исследование конфигурации управления для механизма внимания softmax в LLM, проливая свет на этот важный компонент. У меня нет никаких сомнений в том, что большинство, если не все, передовые лаборатории ИИ будут лихорадочно обновлять свои архитектуры в соответствии с рекомендациями, изложенными в статье Qwen, одной из лучших статей NeurIPS этого года, — весьма престижном достижении в этой области. В настоящий момент, вероятно, тысячи графических процессоров работают над обучением LLM с конфигурациями модулей управления, вдохновленными ясными уроками из статьи Qwen.
Выражаем благодарность команде Qwen за то, что они сделали эти знания общедоступными на благо всего сообщества. Оригинальный код можно найти здесь, если вы заинтересованы в использовании реализации команды Qwen в своих собственных моделях или в дальнейшем развитии их исследований (каждый большой вклад в исследования порождает новые вопросы, черепахи тянутся до самого низа!), чтобы ответить на нерешенные вопросы, такие как изменение внутренней динамики при добавлении вентиля и почему это приводит к наблюдаемой устойчивости в различных позиционных режимах.
Оговорка: Взгляды и мнения, выраженные в этой статье, являются исключительно моими собственными и не отражают взгляды моего работодателя или каких-либо аффилированных организаций. Содержание основано на личных размышлениях и предположениях о будущем науки и техники. Его не следует интерпретировать как профессиональные, академические или инвестиционные рекомендации. Эти перспективные взгляды призваны стимулировать дискуссию и воображение, а не давать окончательные прогнозы.
📚 Дальнейшее обучение
- Алекс Хит (2025) — Взлет Google, мания обучения с подкреплением и вечеринка на борту судна — Обзор основных выводов NeurIPS 2025, в котором освещаются всплеск интереса к обучению с подкреплением, динамика развития Google/DeepMind и все более экстравагантная культура вечеринок на конференциях. Опубликовано в Sources, информационном бюллетене, анализирующем тенденции в индустрии ИИ.
- Цзяньлинь Су и др. (2024) — RoFormer: Усовершенствованный трансформер с встраиванием вращательного положения — Оригинальная статья о RoPE, в которой были представлены встраивания вращательного положения, теперь повсеместно используемые в LLM. В ней объясняется, как кодирование вращения сохраняет информацию об относительном положении, и разъясняется, почему изменение базового значения RoPE влияет на поведение внимания на больших расстояниях.
- Боуэн Пэн и др. (2023) — YaRN: Эффективное расширение контекстного окна для больших языковых моделей — Основная работа, лежащая в основе интерполяции YaRN. В этой работе показано, как корректировка частоты RoPE посредством плавной экстраполяции может расширить модели до более чем 128 тысяч контекстов без переобучения.
- Цзихань Цю и др. (2025) — Вентилируемое внимание для больших языковых моделей: нелинейность, разреженность и отсутствие «поглотителей внимания» — В этой статье представлен обзор исследования вентилирования в механизме внимания softmax. В ней описывается вентильирование с выходом SDPA (G1), объясняется, почему сигмоидное вентилирование вносит нелинейность и разреженность, показано, как вентилирование устраняет «поглотители внимания», и демонстрируется превосходная обобщающая способность в зависимости от длины контекста при модификациях RoPE/YaRN.
- Гуансюань Сяо и др. (2023) — StreamingLLM: Эффективные потоковые языковые модели с механизмами привлечения внимания — Статья, в которой формально определен феномен «механизма привлечения внимания»: ранние токены привлекают непропорционально большие весовые коэффициенты внимания. В ней объясняется, почему базовые трансформеры часто объединяют внимание с первым токеном.
- Минцзе Сунь и др. (2024) — Массивные активации в больших языковых моделях — показывают, что чрезвычайно большие скрытые активации в определенных слоях распространяются по остаточному потоку и вызывают патологическое распределение внимания. Статья Квена эмпирически подтверждает эту связь и демонстрирует, как управление подавляет массивные активации.
- Ноам Шазир (2020) — Варианты GLU улучшают Transformer — основополагающий справочник по управлению внутри блоков прямого распространения (SwiGLU, GEGLU). Современные LLM в значительной степени опираются на это семейство управляемых активаций FFN; статья Квена связывает эту линию с управлением внутри самого механизма внимания.
- Хохрайтер и Шмидхубер (1997) — LSTM: долговременная кратковременная память — самая ранняя и наиболее влиятельная архитектура управления. LSTM вводят входные, выходные и забывающие вентили для избирательной передачи информации — концептуальный предшественник всех современных стратегий управления, включая управление выходом SDPA в трансформаторах.
- Сянмин Гу и др. (2024) — Когда в языковых моделях возникает эффект «поглотителя внимания» — Предлагает современное эмпирическое исследование эффектов «поглотителя внимания», ключевых искажений и неинформативного доминирования ранних токенов.
- Донг и др. (2025) — LongRed: Смягчение деградации коротких текстов в LLM с длинным контекстом — Предлагает математический вывод (ссылка на который приведена в работе Квена), показывающий, как модификация RoPE изменяет распределение внимания и геометрию скрытого состояния.
Источник: towardsdatascience.com











![Кадр из фильма с мужчиной в форме, текст: "Вы ведь включали сегодня [ценз], верно?"](https://ideipro.ru/wp-content/uploads/2026/03/file_1882.jpg)