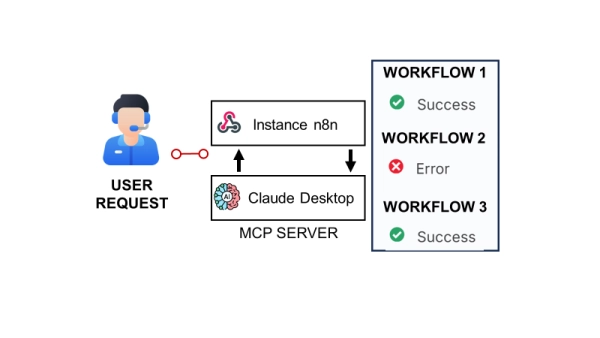
Используйте Claude AI для мониторинга, анализа и устранения неполадок в рабочих процессах автоматизации n8n посредством естественного общения.
Делиться

Если вы когда-либо развертывали рабочие процессы n8n в производственной среде, то вы знаете, каково это — слышать о сбое процесса и копаться в журналах, чтобы найти первопричину.
Пользователь: Самир, ваша автоматизация больше не работает, я не получил уведомление!
Первый шаг — открыть интерфейс n8n и просмотреть последние выполнения, чтобы выявить проблемы.

Через несколько минут вы обнаружите, что переключаетесь между выполнениями, сравниваете временные метки и читаете ошибки JSON, чтобы понять, где что-то сломалось.

Что если бы агент мог сказать вам, почему ваш рабочий процесс дал сбой в 3 часа ночи, и вам не пришлось бы копаться в журналах?
Это возможно!
В качестве эксперимента я подключил API n8n, который обеспечивает доступ к журналам выполнения моего экземпляра, к серверу MCP на базе Claude.

Результатом стал помощник на основе искусственного интеллекта, который может отслеживать рабочие процессы, анализировать сбои и объяснять на естественном языке, что пошло не так.

В этой статье я пошагово расскажу вам о процессе создания этой системы.
В первом разделе будет показан реальный пример из моего собственного экземпляра n8n, где ночью произошел сбой нескольких рабочих процессов.

Мы воспользуемся этим случаем, чтобы увидеть, как агент выявляет проблемы и объясняет их первопричины.
Затем я подробно расскажу, как я подключил API моего экземпляра n8n к серверу MCP с помощью веб-перехватчика, чтобы позволить Claude Desktop извлекать данные о выполнении для отладки на естественном языке.

Веб-хук включает в себя три функции:
- Получить активные рабочие процессы : список всех активных рабочих процессов.
- Получить последние казни : включает информацию о последних n казнях
- Получить сведения о выполнении (статус = ошибка) : сведения о неудачных выполнениях, отформатированные для поддержки анализа первопричин.
Полное руководство вместе с шаблоном рабочего процесса n8n и исходным кодом сервера MCP можно найти по ссылкам в этой статье.
Демонстрация: использование ИИ для анализа неудачных казней n8n
Давайте вместе рассмотрим один из моих экземпляров n8n, который запускает несколько рабочих процессов, собирающих информацию о событиях из разных городов по всему миру.
Эти рабочие процессы помогают деловым и сетевым сообществам находить интересные мероприятия, которые можно посетить и извлечь уроки.

Чтобы протестировать решение, я начну с того, что попрошу агента составить список активных рабочих процессов.
Шаг 1: Сколько рабочих процессов активно?

Основываясь только на вопросе, Клод понял, что ему необходимо взаимодействовать с инструментом n8n-monitor , который был создан с использованием сервера MCP.

Оттуда он автоматически выбрал соответствующую функцию Get Active Workflows , чтобы получить список активных автоматизаций из моего экземпляра n8n.

Вот здесь вы начинаете ощущать силу модели.
Он автоматически классифицировал рабочие процессы на основе их названий.
- 8 рабочих процессов для подключения к извлечению событий из API и их обработки
- 3 других рабочих процесса, которые находятся в процессе разработки, включая тот, который используется для извлечения журналов

Это знаменует начало анализа; все эти выводы будут использованы при анализе первопричин.
Шаг 2: Проанализируйте последние n казней
На этом этапе мы можем попросить Клода предоставить нам данные о последних казнях для анализа.

Благодаря контексту, предоставленному в строках документации, который я объясню в следующем разделе, Клод понял, что ему необходимо вызвать выполнение рабочего процесса get.
Он получит сводку выполнений с указанием процента сбоев и количества рабочих процессов, затронутых этими сбоями.
{ «summary»: { «totalExecutions»: 25, «successfulExecutions»: 22, «failedExecutions»: 3, «failureRate»: «12.00%», «successRate»: «88.00%», «totalWorkflowsExecuted»: 7, «workflowsWithFailures»: 1 }, «executionModes»: { «webhook»: 7, «trigger»: 18 }, «timing»: { «averageExecutionTime»: «15.75 секунд», «maxExecutionTime»: «107.18 секунд», «minExecutionTime»: «0.08 секунд», «timeRange»: { «from»: «2025-10-24T06:14:23.127Z», «to»: «2025-10-24T11:11:49.890Z» } }, […]
Это первое, чем он с вами поделится: он даст четкий обзор ситуации.

Во второй части результатов вы можете найти подробную разбивку сбоев для каждого затронутого рабочего процесса.
«failureAnalysis»: { «workflowsImpactedByFailures»: [ «7uvA2XQPMB5l4kI5» ], «failedExecutionsByWorkflow»: { «7uvA2XQPMB5l4kI5»: { «workflowId»: «7uvA2XQPMB5l4kI5», «failures»: [ { «id»: «13691», «startedAt»: «2025-10-24T11:00:15.072Z», «stoppedAt»: «2025-10-24T11:00:15.508Z», «mode»: «trigger» }, { «id»: «13683», «startedAt»: «2025-10-24T09:00:57.274Z», «stoppedAt»: «2025-10-24T09:00:57.979Z», «mode»: «trigger» }, { «id»: «13677», «startedAt»: «2025-10-24T07:00:57.167Z», «stoppedAt»: «2025-10-24T07:00:57.685Z», «mode»: «trigger» } ], «failureCount»: 3 } }, «recentFailures»: [ { «id»: «13691», «workflowId»: «7uvA2XQPMB5l4kI5», «startedAt»: «2025-10-24T11:00:15.072Z», «mode»: «trigger» }, { «id»: «13683», «workflowId»: «7uvA2XQPMB5l4kI5», «startedAt»: «2025-10-24T09:00:57.274Z», «mode»: «trigger» }, { «id»: «13677», «workflowId»: «7uvA2XQPMB5l4kI5», «startedAt»: «2025-10-24T07:00:57.167Z», «mode»: «trigger» } ] },
Теперь, как пользователь, вы можете видеть затронутые рабочие процессы, а также подробную информацию о возникших сбоях.

В этом конкретном случае рабочий процесс «Встреча в Бангкоке» запускается каждый час.
Мы увидели, что за последние пять часов у нас возникли проблемы три раза (из пяти).
Примечание: последнее предложение можно проигнорировать, поскольку у агента пока нет доступа к сведениям о выполнении.
Последний раздел результатов включает анализ общей производительности рабочих процессов.
«workflowPerformance»: { «allWorkflowMetrics»: { «CGvCrnUyGHgB7fi8»: { «workflowId»: «CGvCrnUyGHgB7fi8», «totalExecutions»: 7, «successfulExecutions»: 7, «failedExecutions»: 0, «successRate»: «100.00%», «failureRate»: «0.00%», «lastExecution»: «2025-10-24T11:11:49.890Z», «executionModes»: { «webhook»: 7 } }, [… другие рабочие процессы …] , «topProblematicWorkflows»: [ { «workflowId»: «7uvA2XQPMB5l4kI5», «totalExecutions»: 5, «successfulExecutions»: 2, «failedExecutions»: 3, «successRate»: «40.00%», «failureRate»: «60.00%», «lastExecution»: «2025-10-24T11:00:15.072Z», «executionModes»: { «trigger»: 5 } }, { «workflowId»: «CGvCrnUyGHgB7fi8», «totalExecutions»: 7, «successfulExecutions»: 7, «failedExecutions»: 0, «successRate»: «100.00%», «failureRate»: «0.00%», «lastExecution»: «2025-10-24T11:11:49.890Z», «executionModes»: { «webhook»: 7 } }, [… другие рабочие процессы …] } ] }
Эта подробная разбивка поможет вам расставить приоритеты в обслуживании в случае сбоя нескольких рабочих процессов.

В этом конкретном примере у меня есть только один неудавшийся рабочий процесс — Ⓜ️ Встреча в Бангкоке .
Что делать, если я хочу узнать, когда начались проблемы?
Не волнуйтесь, я добавил раздел с подробностями казни по часам.
«timeSeriesData»: { «2025-10-24T11:00»: { «всего»: 5, «успех»: 4, «ошибка»: 1 }, «2025-10-24T10:00»: { «всего»: 6, «успех»: 6, «ошибка»: 0 }, «2025-10-24T09:00»: { «всего»: 3, «успех»: 2, «ошибка»: 1 }, «2025-10-24T08:00»: { «всего»: 3, «успех»: 3, «ошибка»: 0 }, «2025-10-24T07:00»: { «всего»: 3, «успех»: 2, «ошибка»: 1 }, «2025-10-24T06:00»: { «всего»: 5, «успех»: 5, «ошибка»: 0 } }
Вам просто нужно позволить Клоду создать красивое визуальное представление, подобное тому, что вы видите ниже.

Позвольте мне напомнить вам, что я не давал Клоду никаких предложений по представлению результатов; это все его собственная инициатива!
Впечатляет, не правда ли?
Шаг 3: Анализ первопричин
Теперь, когда мы знаем, в каких рабочих процессах возникают проблемы, нам следует найти основную причину(ы).

Клоду обычно следует вызывать функцию Get Error Executions , чтобы получить сведения о казни с неудачами.
К вашему сведению, сбой этого рабочего процесса произошел из-за ошибки в узле JSON Tech , который обрабатывает выходные данные вызова API.
- Meetup Tech отправляет HTTP-запрос к API Meetup
- Обработано узлом Result Tech
- Технология JSON должна преобразовать этот вывод в преобразованный JSON.

Вот что происходит, когда все идет хорошо.

Однако иногда может случиться, что вызов API завершится неудачей и узел JavaScript получит ошибку, поскольку входные данные не соответствуют ожидаемому формату.
Примечание: с тех пор эта проблема была исправлена в рабочей версии (теперь узел кода стал более надежным), но я оставил ее здесь для демонстрации.
Давайте посмотрим, сможет ли Клод найти первопричину.
Вот вывод функции Get Error Executions .
{ «workflow_id»: «7uvA2XQPMB5l4kI5», «workflow_name»: «Ⓜ️ Bangkok Meetup», «error_count»: 5, «errors»: [ { «id»: «13691», «workflow_name»: «Ⓜ️ Bangkok Meetup», «status»: «error», «mode»: «trigger», «started_at»: «2025-10-24T11:00:15.072Z», «stopped_at»: «2025-10-24T11:00:15.508Z», «duration_seconds»: 0.436, «finished»: false, «retry_of»: null, «retry_success_id»: null, «error»: { «message»: «Свойство 'json' не является объектом [элемент 0]», «description»: «В возвращаемых данных каждый Ключ с именем 'json' должен указывать на объект.», «http_code»: null, «level»: «error», «timestamp»: null }, «failed_node»: { «name»: «JSON Tech», «type»: «n8n-nodes-base.code», «id»: «dc46a767-55c8-48a1-a078-3d401ea6f43e», «position»: [ -768, -1232 ] }, «trigger»: {} }, [… 4 другие ошибки …] ], «summary»: { «total_errors»: 5, «error_patterns»: { «Свойство 'json' не является объектом [item 0]»: { «count»: 5, «executions»: [ «13691», «13683», «13677», «13660», «13654» ] } }, «failed_nodes»: { «JSON Tech»: 5 }, «time_range»: { «oldest»: «2025-10-24T05:00:57.105Z», «newest»: «2025-10-24T11:00:15.072Z» } } }
Теперь у Клода есть доступ к подробной информации о выполнениях, включая возраст сообщения об ошибке и затронутые узлы.

В ответе выше вы можете видеть, что Клод обобщил результаты нескольких казней в одном анализе.
Теперь мы знаем, что:
- Ошибки происходили каждый час, за исключением 08:00 утра.
- Каждый раз один и тот же узел, называемый «JSON Tech», подвергается воздействию
- Ошибка возникает вскоре после запуска рабочего процесса.
Этот описательный анализ завершается к началу диагностики.

Это утверждение не является неверным, о чем свидетельствует сообщение об ошибке в пользовательском интерфейсе n8n.

Однако из-за ограниченного контекста Клод начинает давать рекомендации по исправлению рабочего процесса, которые неверны.

Помимо исправления кода, он предоставляет план действий.

Поскольку я знаю, что проблема касается не только узла кода, я хотел помочь Клоду в анализе первопричины.

В конце концов он оспорил первоначальное предложение резолюции и начал делиться предположениями о коренных причинах.

Это приближает нас к истинной первопричине, давая достаточно информации для начала изучения рабочего процесса.

Исправленное исправление теперь лучше, поскольку оно учитывает возможность того, что проблема возникает из-за входных данных узла.
Для меня это лучшее, чего я мог ожидать от Клода, учитывая ограниченность имеющейся у него информации.
Заключение: Ценностное предложение этого инструмента
Этот простой эксперимент демонстрирует, как ИИ-агент под управлением Клода может выйти за рамки простого мониторинга и обеспечить реальную операционную ценность.
Прежде чем вручную проверять выполнения и журналы, вы можете сначала связаться со своей системой автоматизации, чтобы узнать, что именно не удалось, почему это произошло, и получить контекстно-зависимые объяснения в течение нескольких секунд.
Это не заменит вас полностью, но может ускорить процесс анализа первопричин.
В следующем разделе я кратко расскажу, как я настроил MCP Server для подключения Claude Desktop к моему экземпляру.
Создание локального сервера MCP для подключения Claude Desktop к микросервису FastAPI
Чтобы снабдить Клода тремя функциями, доступными в веб-перехватчике ( получить активные рабочие процессы, получить выполнение рабочих процессов и получить выполнение ошибок ), я реализовал сервер MCP.

В этом разделе я кратко расскажу о реализации, сосредоточившись только на Get Active Workflows и Get Workflows Executions, чтобы продемонстрировать, как я объясняю Клоду использование этих инструментов.
Для всестороннего и подробного ознакомления с решением, включая инструкции по его развертыванию на вашем компьютере, приглашаю вас посмотреть это руководство на моем канале YouTube.
Вы также найдете исходный код сервера MCP и рабочий процесс n8n веб-перехватчика.
Создайте класс для запроса рабочего процесса
Прежде чем рассмотреть, как настроить три различных инструмента, позвольте мне представить служебный класс, который определен со всеми функциями, необходимыми для взаимодействия с веб-перехватчиком.
Вы можете найти его в файле Python: ./utils/n8n_monitory_sync.py
import logging import os from datetime import datetime, timedelta from typing import Any, Dict, Optional import requests import traceback logger = logging.getLogger(__name__) class N8nMonitor: «»»Обработчик для операций мониторинга n8n — синхронная версия»»» def __init__(self): self.webhook_url = os.getenv(«N8N_WEBHOOK_URL», «») self.timeout = 30
По сути, мы извлекаем URL-адрес веб-перехватчика из переменной среды и устанавливаем время ожидания запроса в 30 секунд.
Первая функция get_active_workflows запрашивает веб-перехватчик, передавая в качестве параметра: «action»: get_active_workflows.
def get_active_workflows(self) -> Dict[str, Any]: «»»Извлечь все активные рабочие процессы из n8n»»» if not self.webhook_url: logger.error(«Переменная среды N8N_WEBHOOK_URL не настроена») return {«error»: «Переменная среды N8N_WEBHOOK_URL не установлена»} try: logger.info(«Извлечение активных рабочих процессов из n8n») response = requests.post( self.webhook_url, json={«action»: «get_active_workflows»}, timeout=self.timeout ) response.raise_for_status() data = response.json() logger.debug(f»Тип ответа: {type(data)}») # Список всех рабочих процессов workflows = [] if isinstance(data, list): workflows = [item for item in data if isinstance(item, dict)] if не рабочие процессы и данные: logger.error(f»Ожидался список словарей, получен список {type(data[0]).__name__}») return {«error»: «Webhook вернул недопустимый формат данных»} elif isinstance(data, dict): if «data» in data: workflows = data[«data»] else: logger.error(f»Неожиданный ответ словаря с ключами: {list(data.keys())} n {traceback.format_exc()}») return {«error»: «Неожиданный формат ответа»} else: logger.error(f»Неожиданный тип ответа: {type(data)} n {traceback.format_exc()}») return {«error»: f»Неожиданный тип ответа: {type(data).__name__}»} logger.info(f»Успешно извлечено {len(workflows)} активных рабочих процессов») return { «total_active»: len(workflows), «workflows»: [ { «id»: wf.get(«id», «unknown»), «name»: wf.get(«name», «Unnamed»), «created»: wf.get(«createdAt», «»), «updated»: wf.get(«updatedAt», «»), «archived»: wf.get(«isArchived», «false») == «true» } for wf in workflows ], «summary»: { «total»: len(workflows), «names»: [wf.get(«name», «Unnamed») for wf in workflows] } } except requests.exceptions.RequestException as e: logger.error(f»Ошибка при извлечении рабочих процессов: {e} n {traceback.format_exc()}») return {«error»: f»Не удалось извлечь рабочие процессы: {str(e)} n {traceback.format_exc()}»} except Exception as e: logger.error(f»Неожиданная ошибка при извлечении рабочих процессов: {e} n {traceback.format_exc()}») return {«error»: f»Неожиданная ошибка: {str(e)} n {traceback.format_exc()}»}
Я добавил много проверок, поскольку API иногда не возвращает ожидаемый формат данных.
Это решение более надежное и предоставляет Клоду всю информацию, необходимую для понимания причины сбоя запроса.
Теперь, когда первая функция рассмотрена, мы можем сосредоточиться на получении всех последних n выполнений с помощью get_workflow_executions.
def get_workflow_executions( self, limit: int = 50, includes_kpis: bool = False, ) -> Dict[str, Any]: «»»Извлечь выполнения рабочего процесса для последних 'limit' выполнений с KPI или без них «»» if not self.webhook_url: logger.error(«Переменная среды N8N_WEBHOOK_URL не задана») return {«error»: «Переменная среды N8N_WEBHOOK_URL не задана»} try: logger.info(f»Извлечение последних {limit} выполнений») payload = { «action»: «get_workflow_executions», «limit»: limit } response = requests.post( self.webhook_url, json=payload, timeout=self.timeout ) response.raise_for_status() data = response.json() if isinstance(data, list) and len(data) > 0: data = data[0] logger.info(«Данные о выполнении успешно получены») if includes_kpis and isinstance(data, dict): logger.info(«Включая KPI в данные о выполнении») if «summary» in data: summary = data[«summary»] failure_rate = float(summary.get(«failureRate», «0»).rstrip(«%»)) data[«insights»] = { «health_status»: «🟢 Healthy» if failure_rate < 10 else "🟡 Warning" if failure_rate < 25 else "🔴 Critical", "message": f"{summary.get('totalExecutions', 0)} выполнения с {summary.get('failureRate', '0%')} показателем отказов" } return data except requests.exceptions.RequestException as e: logger.error(f"HTTP error выборка выполнений: {e} n {traceback.format_exc()}") return {"error": f"Не удалось выбрать выполнения: {str(e)}"} except Exception as e: logger.error(f"Неожиданная ошибка при выборке выполнений: {e} n {traceback.format_exc()}") return {"error": f"Неожиданная ошибка: {str(e)}"}
Единственным параметром здесь является количество n выполнений, которое вы хотите получить: «limit»: n.
Выходные данные включают сводку с состоянием работоспособности, которая генерируется узлом кода «Аудит обработки». (Подробнее в руководстве)

Функция get_workflow_executions только извлекает выходные данные для форматирования перед отправкой их агенту.
Теперь, когда мы определили наши основные функции, мы можем создать инструменты для оснащения Клода через сервер MCP.
Настройка сервера MCP с помощью инструментов
Теперь пришло время создать наш MCP-сервер с инструментами и ресурсами для оснащения (и обучения) Клода.
из mcp.server.fastmcp импорт FastMCP импорт ведение журнала из ввода импорта Необязательный, Словарь, Любой из utils.n8n_monitor_sync импорт N8nMonitor ведение журнала.basicConfig( уровень=ведение журнала.INFO, формат='%(asctime)s — %(levelname)s — %(message)s', обработчики=[ ведение журнала.FileHandler(«n8n_monitor.log»), ведение журнала.StreamHandler() ] ) регистратор = ведение журнала.getLogger(__name__) mcp = FastMCP(«n8n-monitor») монитор = N8nMonitor()
Это базовая реализация с использованием FastMCP и импорта n8n_monitor_sync.py с функциями, определенными в предыдущем разделе.
# Ресурс для агента (Самир: обновляйте его каждый раз при добавлении инструмента) @mcp.resource(«n8n://help») def get_help() -> str: «»»Получить справочную документацию по инструментам мониторинга n8n»»» return «»» 📊 ИНСТРУМЕНТЫ МОНИТОРИНГА N8N ======================= МОНИТОРИНГ РАБОЧЕГО ПРОЦЕССА: • get_active_workflows() Список всех активных рабочих процессов с именами и идентификаторами ОТСЛЕЖИВАНИЕ ВЫПОЛНЕНИЯ: • get_workflow_executions(limit=50, include_kpis=True) Получить журналы выполнения с подробными KPI — limit: Количество последних выполнений для извлечения (1-100) — include_kpis: Рассчитать метрики производительности ОТЛАДКА ОШИБОК: • get_error_executions(workflow_id) Получить подробную информацию об ошибках для определенного рабочего процесса — Возвращает последний 5 ошибок с подробными данными отладки — Показывает сообщения об ошибках, неисправные узлы, данные триггера — Определяет шаблоны ошибок и проблемные узлы — Включает коды HTTP, уровни ошибок и информацию о времени ОТЧЕТНОСТЬ СОСТОЯНИЯ: • get_workflow_health_report(limit=50) Генерация всестороннего анализа состояния на основе недавних выполнений — Определяет проблемные рабочие процессы — Показывает показатели успеха/неудачи — Предоставляет метрики времени выполнения ПРЕДОСТАВЛЯЕМЫЕ КЛЮЧЕВЫЕ МЕТРИКИ: • Общее количество выполнений • Показатели успеха/неудачи • Время выполнения (среднее, мин., макс.) • Рабочие процессы со сбоями • Режимы выполнения (ручной, триггерный, интегрированный) • Шаблоны и частота ошибок • Идентификация неисправного узла ИНДИКАТОРЫ СОСТОЯНИЯ СОСТОЯНИЯ: • 🟢 Исправно: <10% частота сбоев • 🟡 Предупреждение: 10–25% частота сбоев • 🔴 Критически: >25% частота сбоев ПРИМЕРЫ ИСПОЛЬЗОВАНИЯ: — «Показать мне все активные рабочие процессы» — «Что Рабочие процессы дают сбои?» — «Создать отчёт о работоспособности моего экземпляра n8n» — «Показать показатели выполнения за последние 48 часов» — «Отладка ошибок в рабочем процессе CGvCrnUyGHgB7fi8» — «Что вызывает сбои в моём рабочем процессе обработки данных?» РАБОЧИЙ ПРОЦЕСС ОТЛАДКИ: 1. Используйте get_workflow_executions() для выявления проблемных рабочих процессов. 2. Используйте get_error_executions() для подробного анализа ошибок. 3. Проверьте шаблоны ошибок, чтобы выявить повторяющиеся проблемы. 4. Просмотрите сведения о сбойном узле и данные триггера. 5. Используйте workflow_id и execution_id для целевых исправлений.
Поскольку инструмент сложен для понимания, мы включили подсказку в форме ресурса MCP, чтобы обобщить цель и особенности рабочего процесса n8n, подключенного через веб-перехватчик.
Теперь мы можем определить первый инструмент для получения всех активных рабочих процессов.
@mcp.tool() def get_active_workflows() -> Dict[str, Any]: «»» Получает все активные рабочие процессы в экземпляре n8n. Возвращает: словарь со списком активных рабочих процессов и их подробностями. «»» try: logger.info(«Извлечение активных рабочих процессов») result = monitor.get_active_workflows() if «error» in result: logger.error(f»Не удалось получить рабочие процессы: {result['error']}») else: logger.info(f»Найдено {result.get('total_active', 0)} активных рабочих процессов») return result except Exception as e: logger.error(f»Неожиданная ошибка: {str(e)}») return {«error»: str(e)}
Строка документации, используемая для объяснения серверу MCP, как использовать инструмент, относительно коротка, поскольку для get_active_workflows() нет входных параметров.
Давайте сделаем то же самое для второго инструмента, чтобы получить последние n выполнений.
@mcp.tool() def get_workflow_executions( limit: int = 50, include_kpis: bool = True ) -> Dict[str, Any]: «»» Получить журналы выполнения рабочего процесса и ключевые показатели эффективности для последних N выполнений. Аргументы: limit: Количество выполнений для извлечения (по умолчанию: 50) include_kpis: Включить вычисленные ключевые показатели эффективности (по умолчанию: true) Возвращает: Словарь с данными о выполнении и ключевыми показателями эффективности «»» try: logger.info(f»Извлечение последних {limit} выполнений») result = monitor.get_workflow_executions( limit=limit, includes_kpis=include_kpis ) if «error» in result: logger.error(f»Не удалось получить выполнения: {result['error']}») else: if «summary» in result: summary = result[«summary»] logger.info(f»Выполнения: {summary.get('totalExecutions', 0)}, » f»Интенсивность отказов: {summary.get('failureRate', 'N/A')}») возвращает результат, за исключением исключения в виде e: logger.error(f»Неожиданная ошибка: {str(e)}») возвращает {«ошибка»: str(e)}
В отличие от предыдущего инструмента, нам необходимо указать входные данные со значением по умолчанию.
Теперь мы снабдили Клода этими двумя инструментами, которые можно использовать, как в примере, представленном в предыдущем разделе.
Что дальше? Разверните его на своём компьютере!
Поскольку я хотел сделать статью краткой, я расскажу только об этих двух инструментах.
Для ознакомления с остальными функциями приглашаю вас посмотреть это полное руководство на моем канале YouTube.
Я привожу пошаговые объяснения того, как развернуть это на вашем компьютере, а также подробный обзор исходного кода, размещенного на моем GitHub (сервер MCP) и в профиле n8n (рабочий процесс).
Заключение
Это только начало!
Мы можем рассматривать это как версию 1.0 того, что может стать суперагентом для управления вашими рабочими процессами n8n.
Что я имею в виду?
Существует огромный потенциал для улучшения этого решения, особенно в части анализа первопричин путем:
- Предоставление агенту большего контекста с помощью стикеров внутри рабочих процессов
- Демонстрация того, насколько хорошо выглядят входы и выходы с узлами оценки, чтобы помочь Клоду выполнить анализ пробелов
- Использование других конечных точек API n8n для более точного анализа
Однако я не думаю, что смогу, как основатель и генеральный директор стартапа, работающий полный рабочий день, разработать такой всеобъемлющий инструмент самостоятельно.
Поэтому я хотел поделиться этим с сообществами Towards Data Science и n8n в виде решения с открытым исходным кодом, доступного в моем профиле GitHub.
Вам нужно вдохновение, чтобы начать автоматизировать с помощью n8n?
В этом блоге я опубликовал несколько статей, в которых делюсь примерами автоматизации рабочих процессов, которые мы внедрили для малых, средних и крупных предприятий.

Основное внимание уделялось логистике и операциям в цепочке поставок с реальными примерами:
- Автоматизируйте рабочие процессы аналитики цепочки поставок с помощью агентов ИИ с использованием n8n
- Агенты ИИ для оптимизации цепочки поставок: планирование производства
На моем канале YouTube Supply Science также есть полный плейлист с более чем 15 обучающими материалами.

Вы можете следовать этим руководствам, чтобы развернуть рабочие процессы, которыми я делюсь в своем профиле создателя n8n (ссылка на него в описаниях), которые охватывают:
- Автоматизация процессов логистики и цепочки поставок
- Рабочие процессы на базе ИИ для создания контента
- Продуктивность и изучение языка
Не стесняйтесь задавать свои вопросы в комментариях к видео.
Другие примеры реализации MCP-сервера
Это не первая моя реализация MCP-серверов.
В другом эксперименте я подключил Claude Desktop к инструменту оптимизации сети поставок.

В этом примере рабочий процесс n8n заменяется микросервисом FastAPI, размещающим алгоритм линейного программирования.

Цель — определить оптимальный набор заводов для производства и поставки продукции на рынок с минимальными затратами и минимальным воздействием на окружающую среду.

В этом типе упражнений Клод прекрасно справляется с синтезом и представлением результатов.
Более подробную информацию можно найти в статье из рубрики «На пути к науке о данных».
Обо мне
Давайте общаться в Linkedin и Twitter. Я инженер по цепочке поставок, использующий аналитику данных для оптимизации логистических операций и снижения затрат.
Если вам нужна консультация или совет по аналитике и устойчивой трансформации цепочки поставок, свяжитесь со мной через Logigreen Consulting.
Если вас интересуют аналитика данных и цепочка поставок, посетите мой сайт.
Самир Сачи | Наука о данных и производительность
Источник: towardsdatascience.com