
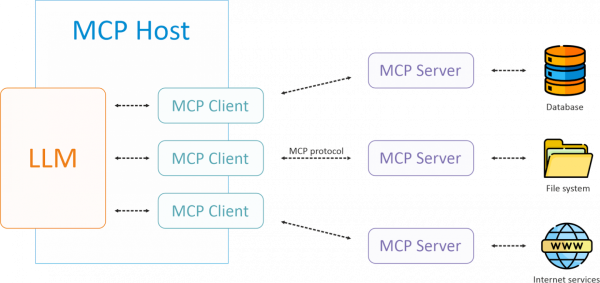
Model Context Protocol (MCP) — это открытый протокол, разработанный компанией Anthropic. Он призван унифицировать способ взаимодействия между LLM и сторонними сервисами, инструментами и источниками данных.
До появления MCP каждому разработчику приходилось пилить свой велосипед для каждого сервиса. При этом один API требовал одного формата, другой — совершенно другого. А в случае изменений сервиса приходилось менять и клиентскую сторону. В общем проблем было много. MCP же оставил большинство этих проблем позади.
В данной статье на примере простых CRUD-операций разберем, что такое MCP-сервер, как его создать и как подружить с LLM.
CRUD — это аббревиатура от английских слов Create, Read, Update, Delete (создать, прочитать, обновить, удалить). Это типовой набор запросов к любой реляционной базе данных.
Но сначала немного теории…
Архитектура MCP

В парадигме MCP есть три основных компонента:
Хост (Host) — это приложение, в котором работают пользователи. Например, чат-бот с функцией ИИ. Хост управляет общей логикой взаимодействия, обрабатывает пользовательские запросы и оркестрирует работу всей системы.
Клиент — это программа, которая обеспечивает связь между хостом и MCP-сервером. Обычно она находится внутри хоста и переводит потребности хоста в стандартизированные запросы, понятные MCP серверу.
MCP-сервер — это сервис, который предоставляет стандартизированный API, через который клиент может запрашивать и выполнять функции сервиса.
А взаимодействуют они примерно так:
Пользователь вводит запрос.
Хост, посредством LLM, интерпретирует запрос и определяет, нужно ли вызвать какую-то функцию MCP-сервера.
Если да, MCP-клиент производит вызов к MCP серверу.
Сервер выполняет действие и возвращает результаты клиенту.
Клиент передает ответ хосту.
LLM формирует окончательный ответ на основе полученной информации.
Бизнес-задача
Прежде чем приступать к реализации, сформулируем задачу с точки зрения бизнеса.
Допустим, у нас есть какой-то LLM чатик, в котором сидят сотрудники HR. И мы хотим, чтобы они посредством команд на естественном языке могли управлять базой данных персонала. Например:
Сотрудник пишет… | … а в БД происходит |
Покажи данные Петра Романова | SELECT * FROM employees WHERE name LIKE ‘Петр Романов’ |
Повысь зарплату Сергею Никонову до 10 000 | UPDATE employees SET salary = 10000 WHERE name = ‘Сергей Никонов’ |
Добавь в БД нового сотрудника: Петров Иван Николаевич, должность инженер, возраст 40 лет, с зп 200 000 | INSERT INTO employees (name, position, salary, age) |
Переведи Елизавету Смирнову в Плановый отдел | UPDATE employees SET position = ‘Плановый отдел’ WHERE name = ‘Елизавета Смирнова’ |
Удали из БД идентификатор 984565 | DELETE FROM employees WHERE id = 984565 |
и тому подобное…
Реализация
Шаг 1. База данных
В качестве подопытного кролика будет выступать БД SQLite. Она уже интегрирована в Python, поэтому никаких дополнительных дистрибутивов ставить не нужно.
Сначала создадим БД и таблицу в ней (для сотрудников) :
import sqlite3 # Создание подключения к БД (файл создастся автоматически) conn = sqlite3.connect(‘dbs/my_db.db’) cursor = conn.cursor() # Создание таблицы cursor.execute(»’ CREATE TABLE IF NOT EXISTS employees ( id INTEGER PRIMARY KEY AUTOINCREMENT, name TEXT NOT NULL, position TEXT, salary REAL, age INTEGER ) »’) conn.commit() # Сохранение изменений
Заполним таблицу тестовыми примерами:
# Вставка данных employees = [ (‘Иван Иванов’, ‘Разработчик’, 50000, 25), (‘Петр Петров’, ‘Менеджер’, 60000, 31), (‘Мария Сидорова’, ‘Дизайнер’, 45000, 43) ] cursor.executemany(»’ INSERT INTO employees (name, position, salary, age) VALUES (?, ?, ?, ?) »’, employees) conn.commit() # Сохранение изменений
Шаг 2. Модель
Для экспериментов будем использовать Qwen3-14B.
Для того чтобы использовать LLM как агента она должна уметь вызывать инструменты (function calling или tool calling). Не каждая LLM может вызвать инструменты — на это ее должны специально обучать. Обычно о таких возможностях пишут в карточке модели.
Из карточки Qwen3-14B: Expertise in agent capabilities, enabling precise integration with external tools in both thinking and unthinking modes and achieving leading performance among open-source models in complex agent-based tasks.
А запускать ее будем с помощью движка vLLM:
Сначала скачаем докер-образ vLLM:
docker pull vllm/vllm-openai:v0.10.1.1
Для запуска модели выполните в терминале примерно такую команду:
docker run —gpus all -v /models/qwen/Qwen3-14B/:/Qwen3-14B/ -p 8000:8000 —env «TRANSFORMERS_OFFLINE=1» —env «HF_DATASET_OFFLINE=1″ —ipc=host —name vllm vllm/vllm-openai:v0.10.1.1 —model=»/Qwen3-14B» —tensor-parallel-size 2 —max-model-len 40960 —enable-auto-tool-choice —tool-call-parser hermes —reasoning-parser deepseek_r1
Последние три параметры нужны непосредственно для использования инструментов в Qwen:
—enable-auto-tool-choice — включает автоматический выбор инструментов во время генерации. Если в запросе указаны доступные инструменты (tools), модель может решить, вызывать ли один из них или отвечать напрямую.
—tool-call-parser hermes — указывает, какой парсер использовать для извлечения вызовов инструментов из сгенерированного текста. LLM сообщает о желании вызвать инструменты в виде текста. Этот текст нужно правильно понять и структурировать. Для этого и нужен парсер. В данном случае используется Hermes.
—reasoning-parser deepseek_r1 — указываем парсер для извлечения цепочек рассуждений (reasoning traces) из сгенерированного текста. В данном случае используется формат DeepSeek-R1.
Более подробно, как в Qwen можно вызывать инструменты можно почитать тут: https://qwen.readthedocs.io/en/latest/framework/function_call.html
Теперь наша модель доступна как сервис по адресу: http://localhost:8000
Шаг 3. MCP-сервер
А теперь на сцену выходит звезда нашего шоу 🙂 Разрабатывать его будем с помощью библиотеки FastMCP.
Создайте файл mcp_server.py с таким кодом:
import sqlite3 from contextlib import contextmanager from typing import List, Dict, Any, Optional from fastmcp import FastMCP # Инициализация MCP сервера mcp = FastMCP(‘Employee Management System’) # Контекстный менеджер для работы с БД conn = sqlite3.connect(‘dbs/my_db.db’) cursor = conn.cursor() #### ИНСТРУМЕНТЫ #### # Создать сотрудника @mcp.tool() def create_employee(name, position, salary, age): »’Создать нового сотрудника в базе данных»’ employee = conn.execute( ‘INSERT INTO employees (name, position, salary, age) VALUES (?, ?, ?, ?)’, (name, position, salary, age) ) conn.commit() employee_id = employee.lastrowid return f’Сотрудник успешно создан. id: {employee_id}’ # Получить информацию о сотруднике @mcp.tool() def get_employee(employee_id): »’Получить информацию о сотруднике по ID»’ employee = conn.execute( ‘SELECT * FROM employees WHERE id = ?’, (employee_id,) ).fetchone() return employee # Обновиление зарплаты сотрудника @mcp.tool() def update_salary(employee_id, salary): »’Обновить зараплату сотруднику»’ cursor.execute( f’UPDATE employees SET salary = ? WHERE id = ?’, (salary, employee_id) ) conn.commit() return ‘Данные сотрудника успешно обновлены’ # Удалить сотрудника @mcp.tool() def delete_employee(employee_id): »’Удалить сотрудника по ID»’ conn.execute(‘DELETE FROM employees WHERE id = ?’, (employee_id,)) conn.commit() return f’Сотрудник с ID {employee_id} успешно удален’ if name == ‘__main__’: # Запуск сервера mcp.run(transport=»http», host=»192.168.0.108″, port=9000)
Здесь у нас несколько крупных частей:
Инициируем сервис «Employee Management System».
Создаем подключение к БД, которую создали на Шаге 1.
Вводим четыре функции:
create_employee
get_employee
update_salary
delete_employee
Каждую функцию мы обязательно сопровождаем описанием.
Запускаем сервис на протоколе http.
Чтобы запустить сервис выполните в терминале команду: python3 mcp_server.py
Теперь MCP-сервер доступен как сервис по адресу: http://192.168.0.108:9000/mcp
Шаг 4. Client
MCP-клиент выглядит следующим образом:
import asyncio from fastmcp import Client mcp_client = Client(‘http://192.168.0.108:9000/mcp’) async def call_tool(tool_name: str, arguments: dict): async with mcp_client: result = await mcp_client.call_tool(tool_name, arguments) result = result.content[0].text if result.content else ‘Инструмент вернул пустой результат.’ return result
Здесь мы создаем подключение к MCP-серверу и объявляем функцию call_tool. Это, по сути, и есть наш клиент. Она предназначена для вызова функций MCP-сервера. Принимает на вход название выполняемой функции и ее параметры.
Шаг 5. Использование
Создаем подключение к LLM:
from openai import OpenAI llm_client = OpenAI( api_key = ‘EMPTY’, base_url = ‘http://localhost:8000/v1’ )
Прежде чем взаимодействовать с MCP сервером нужно получить от него список доступных инструментов:
# Получаем все инструменты в формате OpenAI Tool async def get_tools(): async with mcp_client: tools = await mcp_client.list_tools() json_tools = [] for tool in tools: json_tool = { «type»: «function», «function»: { «name»: tool.name, «description»: tool.description, «parameters»: tool.inputSchema, # MCP уже предоставляет JSON Schema } } json_tools.append(json_tool) return json_tools json_tools = await get_tools()
Модель Qwen принимает инструменты в формате OpenAI. А MCP возвращает их в виде объектов. Поэтому мы сначала переводим их в JSON формат. Результат будет примерно таким:
Скрытый текст[ { «type»: «function», «function»: { «name»: «create_employee», «description»: «Создать нового сотрудника», «parameters»: { «type»: «object», «properties»: { «name»: {«type»: «string»}, «position»: {«type»: «string»}, «salary»: {«type»: «number»}, «age»: {«type»: «integer»} }, «required»: [«name», «position», «salary», «age»] } } }, { «type»: «function», «function»: { «name»: «get_employee», «description»: «Получить информацию о сотруднике по ID», «parameters»: { «type»: «object», «properties»: { «employee_id»: {«type»: «integer»} }, «required»: [«employee_id»] } } } ]
Обратите внимание, мы получаем полное описание каждого из инструментов: как называется, для чего предназначен, какие параметры содержит и какие из них обязательные и т.д. Все эти данные помогут LLM правильно распорядиться инструментом. Поэтому к разработке MCP-сервера нужно подходить основательно.
Далее объявляем функцию, которая будет обрабатывать запросы пользователя:
async def get_llm_answer(query, tools): messages = [ {‘role’: ‘system’, ‘content’: ‘Вы — помощник для управления сотрудниками. Используйте предоставленные инструменты для работы с базой данных сотрудников.’}, {‘role’: ‘user’, ‘content’: query} ] # Передаем в LLM исходный запрос response = llm_client.chat.completions.create( model = ‘/Qwen14-8B’, messages = messages, tools = tools ) # Если в ответе есть инструменты — итеративно проходимся по ним tool_calls = response.choices[0].message.tool_calls if tool_calls: for tool in tool_calls: # вызываем инструмент tool_result = await call_tool( tool_name=tool.function.name, arguments=eval(tool.function.arguments) ) # Ответ инструмента добавляем в сообщения messages.append({ ‘role’: ‘tool’, ‘tool_call_id’: tool.id, ‘name’: tool.function.name, ‘content’: tool_result }) response = llm_client.chat.completions.create( model = ‘/Qwen3-8B’, messages = messages ) # возвращем ответ return response.choices[0].message.content
Здесь мы:
Формируем изначальное сообщение для LLM (на основе запроса пользователя)
Отправляем запрос к LLM. При этом на вход также подаем список инструментов в формате JSON, чтобы LLM знала, что она может ими воспользоваться при необходимости.
Если LLM решила что ей нужно вызвать какие-то инструменты, то в ответе будет заполнен раздел tool_calls со списком необходимых инструментов. И тогда мы итеративно проходимся по всем инструментам и поочередно:
Вызываем их посредством нашей функции call_tool. При этом передавая ей все параметры, которые сообщила LLM.
Ответы бережно складируем в список сообщений.
Повторно вызываем LLM с исходным запросом пользователя и ответами всех инструментов, которые мы вызывали. На основе этого полного набора LLM выдает окончательный ответ.
Теперь можно дернуть функцию get_llm_answer с запросом пользователя:
query = ‘Добавь в БД нового сотрудника. Его данные: Смирнов Николай Викторович, 20 лет, на позицию кассир с зарплатой 10 000.’ answer = await get_llm_answer(query=query, tools=json_tools)
Примечания:
LLM это генераторы текста и сами по себе они не могут вызывать никаких функций. Но они могут нам сообщить в сгенерированном тексте, что они хотят что-то вызвать. Нам нужно это понять (с помощью парсера; в данном случае это hermes) и самим вызвать эти инструменты. А затем результат их работы вернуть в LLM для формирования окончательного ответа. Этот цикл называется tool loop.
LLM может решить, что ей нужно вызвать как один, так и несколько инструментов.
Также LLM может решить, что инструменты ей вовсе не нужны и напрямую ответить на вопрос пользователя.
Что в итоге мы получили?
Мы получили единую точку входа для сервиса.
Чтобы узнать обо всех доступных инструментах, достаточно выполнить одну команду (list_tools).
Нам не нужно никак дополнительно описывать и поддерживать инструменты. Владелец MCP-сервера сам добавляет/обновляет свои методы. А мы просто их подтягиваем по мере необходимости.
Функции сервиса отделены от клиентского приложения.
При изменении инструментов MCP сервера клиентскую часть никак переписывать не нужно.
И так с каждым сервисом — работаем по единому формату. Не нужно под каждый сервис пилить свой кастыль.
Что дальше?
Еще больше возможностей
Выше мы рассмотрели одну из возможностей MCP — инструменты. Но вообще стандарт предоставляет три основных компонента:
Инструменты (Tools) — функции, которые LLM может вызывать для выполнения различных действий: поиск в интернете, отправка email, поиск в БД, генерация изображений и т.д.
Ресурсы (Resources) — это статичные источники данных, предоставляемые сервером. Например, содержимое файлов или БД. В отличии от инструментов, ресурсы обычно предназначены только для чтения, они не занимаются вычислениями или изменения данных.
Подсказки (Prompts) — заранее подготовленные шаблоны промтов, которые сервер может предоставить для организации взаимодействий с LLM.
И это еще не все. Есть и другие интересные фишки: хранилище контекста, оркестрация сессий, кеширование, сэмплинг и прочее…
Готовые решения
После публикации стандарта энтузиасты и официальные сервисы принялись пилить MCP-сервера. Образовались целые коллекции:
https://mcp.so
https://mcpservers.org
https://mcpmarket.com
https://github.com/modelcontextprotocol/servers
https://smithery.ai/servers
Что почитать?
Описание стандарта MCP: https://modelcontextprotocol.io/docs/getting-started/intro
Документация FastMCP сервера: https://gofastmcp.com/getting-started/welcome
Как вызывать инструменты у различных моделей:
Gemma: https://ai.google.dev/gemma/docs/capabilities/function-calling?hl=ru
Qwen: https://qwen.readthedocs.io/en/latest/framework/function_call.html
Вызов функции в vLLM: https://docs.vllm.ai/en/stable/features/tool_calling.html
На обниамтьлицо huggingface вышел целый курс про MCP: https://huggingface.co/learn/mcp-course
Мои курсы: Разработка LLM с нуля | Алгоритмы Машинного обучения с нуля
Источник: habr.com

























