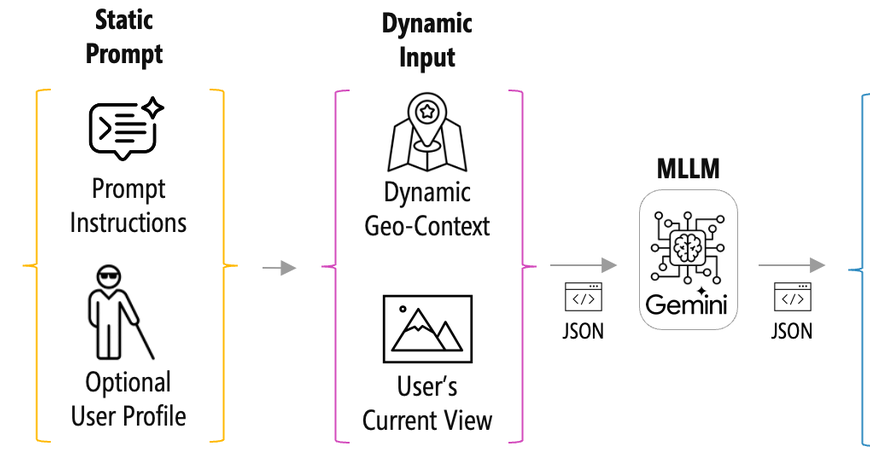
Как оптимизировать контекст — ценный, ограниченный ресурс для агентов искусственного интеллекта.
Делиться

Мы много говорим о более совершенных моделях, больших контекстных окнах и более мощных агентах. Но большинство реальных сбоев происходит не из-за возможностей модели, а из-за того, как контекст строится, передается и поддерживается.
Это сложная задача. Область исследований быстро развивается, и методы всё ещё совершенствуются. Многое остаётся экспериментальной наукой и зависит от контекста (игра слов), ограничений и условий, в которых вы работаете.
В моей работе по созданию многоагентных систем выявилась повторяющаяся закономерность: производительность в гораздо меньшей степени зависит от объема контекста, предоставляемого модели, и в гораздо большей степени от точности ее формирования.
В этой статье я попытался изложить свои знания в доступной для вас форме.
В центре внимания — принципы управления контекстом как ограниченным ресурсом: принятие решений о том, что включать, что исключать и как структурировать информацию, чтобы агенты оставались согласованными, эффективными и надежными с течением времени.
Потому что в конечном счете, самые сильные агенты — это не те, кто видит больше всего. Это те, кто видит нужные вещи, в нужной форме, в нужное время.
Терминология
Контекстная инженерия
Разработка контекста — это искусство предоставления юридическому лицу, обучающемуся на уровне магистратуры (LLM), необходимой информации, инструментов и формата для выполнения задачи. Эффективная разработка контекста подразумевает поиск наименьшего возможного набора ключевых слов, которые обеспечивают юридическому лицу, обучающемуся на уровне магистратуры, наибольшую вероятность получения положительного результата.
На практике качественная разработка контекста обычно сводится к четырем шагам. Вы переносите информацию во внешние системы ( перенос контекста ), чтобы модели не приходилось хранить все данные внутри системы. Вы динамически извлекаете информацию, а не загружаете ее всю сразу ( извлечение контекста ). Вы изолируете контекст, чтобы одна подзадача не загрязняла другую ( изоляция контекста ). И вы сокращаете историю при необходимости, но только таким образом, чтобы сохранить то, что понадобится агенту позже ( сокращение контекста ).
С другой стороны, распространённой проблемой является загрязнение контекста : наличие слишком большого количества ненужной, противоречивой или избыточной информации, которая отвлекает от работы с LLM.
Контекстная деградация
«Контекстное затухание» — это ситуация, когда производительность LLM снижается по мере заполнения контекстного окна, даже если оно находится в пределах установленного лимита. У LLM ещё есть место для дальнейшего чтения, но его рассуждения начинают размываться.
Вы, наверное, заметили, что эффективное контекстное окно, в котором модель демонстрирует высокое качество работы, часто намного меньше, чем то, на что модель технически способна.
Здесь есть два аспекта. Во-первых, модель не может обеспечить идеальную воспроизводимость информации на протяжении всего контекстного окна. Информация в начале и конце запоминается надежнее, чем информация в середине.
Во-вторых, более крупные контекстные окна не решают проблем корпоративных систем. Корпоративные данные фактически неограниченны и часто обновляются, поэтому даже если бы модель могла обрабатывать все данные, это не означало бы, что она смогла бы поддерживать целостное понимание этой информации.
Подобно тому, как у людей ограничен объем рабочей памяти, каждый новый токен, введенный в LLM, в некоторой степени истощает имеющийся у него бюджет внимания. Дефицит внимания обусловлен архитектурными ограничениями трансформера, где каждый токен обращает внимание на каждый другой токен. Это приводит к n²-шаблону взаимодействия для n токенов. По мере расширения контекста модель вынуждена распределять свое внимание все более равномерно по большему числу взаимосвязей.
Сжатие контекста
Сжатие контекста — это общее решение проблемы деградации контекста.
Когда модель приближается к пределу своего контекстного окна, она суммирует его содержимое и создает новое контекстное окно с предыдущим сводным отчетом. Это особенно полезно для длительных задач, позволяя модели продолжать работу без существенного снижения производительности.
Недавние исследования по сворачиванию контекста предлагают иной подход — агенты активно управляют своим рабочим контекстом. Агент может отделиться для выполнения подзадачи, а затем свернуть её после завершения, объединив промежуточные шаги, но сохранив краткое резюме результата.
Однако сложность заключается не в обобщении, а в решении вопроса о том, что следует оставить. Некоторые вещи должны оставаться стабильными и практически неизменными, например, цель задачи и жесткие ограничения. Другие можно смело отбросить. Проблема в том, что важность информации часто проявляется лишь позже.
Таким образом, качественная компакция должна сохранять факты, которые продолжают ограничивать будущие действия: какие подходы уже потерпели неудачу, какие файлы были созданы, какие предположения оказались недействительными, какие дескрипторы можно пересмотреть и какие неопределенности остаются неразрешенными. В противном случае вы получите аккуратное, краткое резюме, которое хорошо читается человеком, но бесполезно для агента.
Агентская обвязка
Модель — это не агент. Именно снаряжение превращает модель в агента.
Под «системой обеспечения контекста» я подразумеваю все компоненты модели, определяющие способ формирования и поддержания контекста: сериализацию запросов, маршрутизацию инструментов, политику повторных попыток, правила сохранения данных между шагами и так далее.

Если взглянуть на реальные агентские системы под таким углом, многие предполагаемые «сбои модели» начинают выглядеть иначе. На работе я сталкивался со многими подобными случаями. На самом деле это сбои в работе программного обеспечения: агент забыл, потому что ничто не сохранило правильное состояние; он повторил работу, потому что программное обеспечение не выявило устойчивых следов предыдущих сбоев; он выбрал неправильный инструмент, потому что программное обеспечение перегрузило пространство действий; и так далее.
Хорошая система, в некотором смысле, представляет собой детерминированную оболочку, обернутую вокруг стохастического ядра. Она делает контекст понятным, стабильным и достаточно восстанавливаемым, чтобы модель могла использовать свой ограниченный вычислительный бюджет для решения задачи, а не для восстановления собственного состояния из запутанного следа.
Коммуникация между агентами
По мере усложнения задач команды все чаще используют многоагентные системы.
Ошибка заключается в предположении, что больше агентов означает больше общего контекста. На практике, передача огромного общего текста каждому субагенту часто приводит к прямо противоположному результату специализации. Теперь каждый агент читает всё, наследует ошибки других и снова и снова платит один и тот же счет за контекст.
Если известна лишь общая информация, возникает новая проблема. Что считается авторитетным источником, когда стороны не согласны друг с другом? Что остается локальным, и как разрешаются конфликты?
Выход заключается в том, чтобы рассматривать коммуникацию не как общую память, а как передачу состояний через четко определенные интерфейсы .
Для дискретных задач с четко определенными входными и выходными данными агенты обычно должны обмениваться информацией посредством артефактов, а не необработанных трассировок. Например, агенту веб-поиска не нужно передавать всю свою историю просмотров. Ему достаточно отображать только тот материал, который могут использовать последующие агенты.
Это означает, что промежуточные рассуждения, неудачные попытки и результаты исследований остаются конфиденциальными, если в них нет явной необходимости. Передаются только обобщенные данные: извлеченные факты, подтвержденные результаты или решения, определяющие следующий шаг.
Для задач с более тесной взаимосвязью, таких как отладочный агент, где последующие рассуждения действительно зависят от предыдущих попыток, можно ввести ограниченную форму обмена трассировкой. Но это должно быть преднамеренным и целенаправленным, а не использоваться по умолчанию.
штраф кэша KV
Когда модели ИИ генерируют текст, они часто повторяют многие из одних и тех же вычислений. Кэширование ключ-значение — это метод оптимизации времени вывода, который ускоряет этот процесс, запоминая важную информацию из предыдущих шагов вместо того, чтобы пересчитывать все заново.
Однако в многоагентных системах, если каждый агент использует один и тот же контекст, это приводит к путанице в модели из-за множества нерелевантных деталей и значительному увеличению нагрузки на кэш ключ-значение. Несколько агентов, работающих над одной и той же задачей, должны взаимодействовать друг с другом, но это не должно происходить посредством совместного использования памяти.
Именно поэтому агенты должны общаться посредством минимальных, структурированных выходных данных контролируемым образом.
Набор инструментов агента должен быть небольшим и актуальным.
Выбор инструмента — это проблема контекста, замаскированная под проблему возможностей.
По мере того, как агент накапливает все больше инструментов, ориентироваться в пространстве действий становится сложнее. Теперь возрастает вероятность того, что модель выберет неправильное действие и неэффективный маршрут.
Это влечет за собой последствия. Схемы инструментов должны быть гораздо более четкими, чем большинство людей себе представляют. Инструменты должны быть хорошо понятны и иметь минимальное совпадение в функциональности. Должно быть совершенно ясно, для чего они предназначены, и иметь четкие, недвусмысленные входные параметры.
Одна из распространенных проблем, которую я заметил даже в своей команде, заключается в том, что у нас, как правило, очень раздутый набор инструментов, которые добавляются со временем. Это приводит к нечеткому принятию решений о том, какие инструменты использовать.
Агентная память
Это метод, при котором агент регулярно записывает заметки, сохраняемые в памяти вне контекстного окна. Эти заметки впоследствии возвращаются в контекстное окно.
Самое сложное — решить, что именно заслуживает запоминания. Моё эмпирическое правило таково: долговременная память должна содержать вещи, которые продолжают ограничивать дальнейшее мышление: устойчивые предпочтения. Всё остальное должно иметь очень высокую планку. Хранение слишком большого объёма информации — это просто ещё один путь к загрязнению контекста, только теперь вы сделали его устойчивым.
Но память без пересмотра — это ловушка. Как только агенты сохраняют заметки между этапами или сессиями, им также необходимы механизмы разрешения конфликтов, удаления и понижения статуса. В противном случае долговременная память превращается в свалку устаревших убеждений.
Подводить итоги
Контекстная инженерия все еще находится в стадии развития, и не существует единственно правильного способа ее применения. Большая часть остается эмпирической, формируясь под влиянием создаваемых нами систем и ограничений, в рамках которых мы работаем.
Если не контролировать ситуацию, контекст разрастается, изменяет свою структуру и в конечном итоге рушится под собственной тяжестью.
При грамотном управлении контекст становится тем фактором, который отличает агента, который просто реагирует, от агента, способного рассуждать, адаптироваться и сохранять согласованность действий при выполнении длительных и сложных задач.
Клара Чонг. Все работы Клары Чонг.
Источник: towardsdatascience.com