


 Snowflake, команда LandingAI, 4 ноября 2025 г. Поделиться:
Snowflake, команда LandingAI, 4 ноября 2025 г. Поделиться:
Практически каждое предприятие работает с документами. Юридические соглашения, пакеты документов, бланки, заявки на кредиты, контракты — это лишь некоторые примеры. Эти документы могут быть длинными, запутанными, сложными и содержать множество элементов, включая отсканированные формы, вложенные/сложные таблицы, диаграммы, графики, инженерные и архитектурные схемы, флажки, переключатели, изображения, подписи, сноски и многое другое. Часто пользователи тратят часы на повторный ввод или поиск деталей, содержащихся в этих документах. Даже при использовании инструментов искусственного интеллекта качество может пострадать, если решение не сохраняет исходную структуру и визуальный контекст.
Эти сложности создают скрытые издержки, влияющие на принятие решений, качество обслуживания клиентов и соблюдение нормативных требований. Но что, если бы PDF-файлы функционировали одновременно как таблицы и как доступные для поиска знания, и всё это внутри Snowflake?
С помощью подключенного приложения LandingAI Agentic Document Extraction (ADE) для Snowflake вы можете преобразовывать документы в управляемые данные, готовые к использованию ИИ, с визуальной привязкой, которая связывает ответы с источником.
Вкратце:
В этой статье мы подробно рассмотрим полный пример преобразования неструктурированных документов в данные, готовые для использования в аналитике и интеллектуальных приложениях с помощью технологии Agentic Document Extraction (ADE) от LandingAI и Snowflake .
Вы увидите, как это сделать:
- С помощью ADE можно анализировать и извлекать информацию из мультимодальных документов , чтобы получить полный контекст — текст, рисунки и таблицы — и при этом связать каждый элемент с его источником.
- Храните и управляйте документами и результатами их обработки непосредственно в Snowflake для обеспечения безопасности и соответствия нормативным требованиям.
- С помощью Cortex Analyst выполняйте запросы Text-to-SQL к структурированным полям.
- Включите приложения RAG , извлекая фрагменты проанализированных документов с помощью Cortex Search.
- Расширьте возможности анализа данных с помощью сторонних источников, используя Cortex Knowledge Extensions.
- Создайте интеллектуального агента , который будет координировать работу этих инструментов, с помощью Cortex Agents.
- Предоставьте бизнес-пользователям прямой доступ через Snowflake Intelligence.
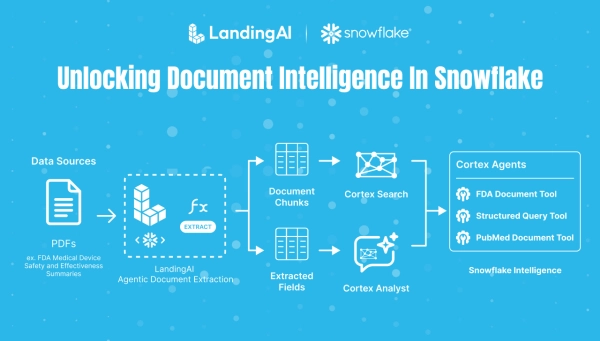
Вот как выглядит полное решение:

Мы проиллюстрируем это на примере документов FDA по безопасности и эффективности, но эта закономерность применима ко всем отраслям.
Почему это важно
Большинство инструментов для работы с документами на основе ИИ работают вне платформы данных. Это создает копии, теневые конвейеры и второй периметр безопасности. Однако с помощью функции Agentic Document Extraction от LandingAI в Snowflake предприятия получают следующие преимущества:
- Интеллектуальное понимание документов с помощью ADE в Snowflake – LandingAI позволяет фиксировать сложные детали документов с помощью анализа без предварительного обучения и извлечения полей, подготавливая ваши данные для последующего анализа и применения в приложениях искусственного интеллекта.
- Единое управление – безопасность и соответствие нормативным требованиям остаются неизменными, включая управление доступом на основе ролей, маскирование и отслеживание происхождения данных.
- Аналитика и ИИ вместе : структурированные поля легко интегрируются с корпоративными данными, а блоки, учитывающие структуру данных, обеспечивают поиск информации и рабочие процессы агентов.
- Автоматизация рабочих процессов – анализ контента обеспечивает сквозную автоматизацию процессов во всех бизнес-функциях.
- Более быстрая итерация – отсутствие переключения контекста, копирований и потери доверия.
Пошаговое руководство: Специалист по исследованиям медицинских устройств в сфере здравоохранения и медико-биологических наук.
Рассмотрим реальный пример использования в области медико-биологических наук: анализ и извлечение информации из отчетов Управления по санитарному надзору за качеством пищевых продуктов и медикаментов (FDA) о безопасности и эффективности медицинских изделий. Эти документы — отличный тест на прочность: они содержат множество сложных разделов, таблиц, сносок и рисунков. Кроме того, они включают ценную информацию, которую компании могут захотеть преобразовать в структурированные поля, одновременно сделав ее доступной для бизнес-пользователей и рабочих процессов агентов. В этом пошаговом руководстве мы продемонстрируем, как извлекать и анализировать эти документы, а затем быстро создать сложного агента для взаимодействия с ними.
Вот как выглядит рабочий процесс, и все действия происходят внутри Snowflake.

Ниже более подробно описаны следующие 8 процессов. Полный исходный код доступен в этом репозитории GitHub. Этот рабочий процесс поддерживает широкий спектр сценариев, включая генерацию с расширенным извлечением данных (Retrieval-Augmented Generation, RAG), последующую бизнес-аналитику и сценарии использования преобразования текста в SQL.
1. Загрузка документов: Неструктурированные PDF-документы FDA, хранящиеся в среде Snowflake.
2. Установите приложение LandingAI ADE Connected: приложение ADE доступно в Snowflake Marketplace и повторно активирует периметр безопасности вашей учетной записи Snowflake.
3. Анализ и извлечение документов с помощью ADE: Возможности ADE Extract and Parse позволяют создавать стандартные операционные процедуры (SOP), извлекать и обрабатывать документы. Результаты ADE в форматах Markdown и JSON, которые можно преобразовать в плоский формат, затем сохраняются в таблицах, представлениях и/или этапах Snowflake.
4. Создание сервиса поиска Cortex: Сервис поиска Cortex, созданный на основе интеллектуально проанализированных документов FDA.
5. Преобразование извлеченного контента для аналитики / Cortex Analyst: извлеченные поля выводятся в таблицу Snowflake. Cortex Analyst используется для создания диалогового интерфейса для работы с данными.
6. Обогащение с помощью расширения Cortex Knowledge Extension: статьи по биомедицинским исследованиям из PubMed, загруженные с Snowflake Marketplace.
7. Создайте агента Cortex: Агент Cortex используется для обеспечения логического вывода, координации и использования инструментов для различных источников данных. 8. Обеспечьте взаимодействие с пользователем через Snowflake Intelligence: Snowflake Intelligence предоставляет бизнес-пользователям мощную возможность безопасно взаимодействовать с данными.
Предварительные требования
Для использования подключенного приложения LandingAI Agentic Document Extraction (ADE) и необходимых функций Snowflake Cortex вам потребуется учетная запись Snowflake с правами администратора (или соответствующими ролями).
Пользователям потребуется учетная запись Snowflake с правами администратора или соответствующими ролями, предоставленными для использования функции извлечения документов LandingAI Agentic Document Extraction и необходимых функций Snowflake Cortex.
1. Загрузка документов
Загрузите неструктурированные документы FDA в среду Snowflake. Для этой демонстрации примеры файлов находятся в папке /docs репозитория GitHub. Вы можете загрузить их с помощью команд PUT или напрямую через пользовательский интерфейс Snowflake.
2. Установите приложение LandingAI ADE Connected.
Установите приложение непосредственно со страницы объявления на Snowflake Marketplace. Вся обработка происходит внутри вашей учетной записи Snowflake, что обеспечивает безопасность и управление. Возможно, вам сначала потребуется запросить приложение и дождаться одобрения запроса командой LandingAI.
3. Анализ и извлечение документов с помощью ADE.
После настройки необходимых разрешений, баз данных и схем для хранения результатов мы используем две хранимые процедуры, предоставленные LandingAI, для анализа всех документов на этапе и применения схемы извлечения.
Найдите вызовы CALL api.parse() и CALL api.extract() в приведенном ниже блоке кода.
— Анализ и извлечение всех PDF-файлов на этапе после фильтрации до нужных документов. DECLARE file_cursor CURSOR FOR SELECT RELATIVE_PATH FROM DIRECTORY(@ADE_APPS_DB.FDA.DOCS) WHERE SIZE < 1000000 -- Файлы меньше 1 МБ (1 000 000 байт) AND RELATIVE_PATH LIKE 'devices/P%.pdf' -- Фильтрация на основе имен файлов в каталоге LIMIT 10; current_file_path STRING; full_stage_path STRING; parse_ret OBJECT; extract_ret OBJECT; BEGIN FOR file_record IN file_cursor DO current_file_path := file_record.RELATIVE_PATH; full_stage_path := '@"ADE_APPS_DB"."FDA"."DOCS"/' || :current_file_path; -- Анализ документа (получение возвращаемого объекта) CALL api.parse( file_path => :full_stage_path, model => 'dpt-2-latest', output_table => 'medical_device_parse' — Имя вашей выходной таблицы для анализа. Она будет создана автоматически. ) INTO :parse_ret; — Извлечение с использованием возвращаемого объекта анализа CALL api.extract( parse_result => :parse_ret, output_table => 'medical_device_extract', — Имя вашей выходной таблицы для извлечения. Она будет создана автоматически. model => 'extract-latest', schema => '{SCHEMA_OMITTED_FOR_CLARITY_SEE_BELOW}' ) INTO :extract_ret; END FOR; END;
Вот конкретная пользовательская JSON-схема, которая используется. Обратите внимание, что поле описания содержит много информации, необходимой для работы системы, что помогает ей идентифицировать нужные данные и вернуть их в желаемом формате.
{ «title»: «Статистика медицинских устройств FDA», «type»: «object», «properties»: { «device_generic_name»: { «type»: «string», «description»: «Общее название устройства из SSED/маркировки» }, «device_trade_name»: { «type»: «string», «description»: «Торговое/брендовое название» }, «applicant_name»: { «type»: «string», «description»: «Производитель/Спонсор/Заявитель» }, «applicant_address»: { «type»: «string», «description»: «Почтовый адрес заявителя, как указано» }, «premarket_approval_number»: { «type»: «string», «description»: «Основной PMA (или идентификатор De Novo/510(k)/HDE), например, P200022» }, «application_type»: { «type»: «string», «enum»: [ «PMA», «PMA_SUPPLEMENT», «DE_NOVO», «HDE», «510K» ], «description»: «Тип заявки, как указано» }, «fda_recommendation_date»: { «type»: «string», «description»: «Дата рекомендации группы экспертов/консультативного совета FDA, если указана и переведена в ГГГГ-ММ-ДД» }, «approval_date»: { «type»: «string», «description»: «Дата решения об одобрении FDA и переведена в ГГГГ-ММ-ДД» }, «indications_for_use»: { «type»: «string», «description»: «Краткая инструкция по применению (один абзац)» }, «key_outcomes_summary»: { «type»: «string», «description»: «Краткое описание эффективности и безопасности в одном абзаце (например, результаты конечной точки, основные нежелательные явления)» }, «overall_summary»: { «type»: «string», «description»: «Краткое описание: что делает устройство, для кого оно предназначено, основные результаты и заключение о соотношении пользы и риска» } }, «required»: [ «device_generic_name», «device_trade_name», «applicant_name», «applicant_address», «premarket_approval_number», «approval_date», «overall_summary», «application_type», «fda_recommendation_date», «indications_for_use», «key_outcomes_summary» ], «additionalProperties»: false }
На этом этапе возвращается не только необработанный текст. ADE выводит текстовые фрагменты, которые сохраняют структуру документа, поток данных, структурированные значения полей, выровненные по вашей схеме, а также сводные рисунки и таблицы. Каждое поле связано с его точным местоположением в исходном коде посредством визуальной привязки с использованием метаданных, местоположения фрагмента («привязки»), идентификатора фрагмента и ссылок на страницы для обеспечения отслеживаемости и достоверности.
Вот изображение первого фрагмента ответа на один из документов.

4. Создайте сервис поиска в Cortex.
После обработки результаты можно преобразовать в таблицу с фрагментами (см. landingai_apps_db.fda.medical_device_chunks), которая сохраняет текстовые сегменты и их метаданные. Проиндексируйте эту таблицу в службе Cortex Search для обеспечения быстрого и качественного поиска. После этого вы можете запускать алгоритм генерации с расширенным поиском (Retrieval-Augmented Generation, RAG) непосредственно в Snowflake, позволяя агентам и бизнес-пользователям запрашивать документы FDA с помощью семантического поиска, обоснованных ответов и ссылок на исходный текст.
5. Преобразовать извлеченный контент для аналитики / сервиса Cortex Analyst.
Далее, извлеките объекты из шага 3 и преобразуйте их в структурированную таблицу (см. landingai_apps_db.fda.medical_device_extracted). Она будет содержать следующее:

Эту таблицу можно использовать непосредственно для аналитики или расширить с помощью семантической модели.
Семантическая модель определяет бизнес-значение ваших данных (например, измерения, показатели и связи), а семантическое представление — это объект Snowflake, который предоставляет доступ к этой модели, чтобы такие инструменты, как Cortex Analyst, могли преобразовывать вопросы на естественном языке в SQL-запросы.
Например, вы можете создать семантическое представление (LANDINGAI_APPS_DB.FDA.MEDICAL_DEVICES) на основе извлеченной таблицы. Это позволит пользователям запрашивать данные об устройствах FDA с помощью простого языка через Cortex Analyst, без необходимости писать SQL-запросы. Семантические представления можно создавать в пользовательском интерфейсе Snowflake. Подробности см. в документации Cortex Analyst.
6. [Необязательно] Дополнить с помощью расширения знаний PubMed Cortex.
Для дальнейшего улучшения решения вы можете интегрировать расширения Cortex Knowledge Extensions, доступные на Snowflake Marketplace, такие как корпус биомедицинских исследований PubMed. Этот корпус содержит миллионы рецензированных статей по биомедицинским исследованиям, включая аннотации и метаданные, которые могут быть проиндексированы в поисковой системе Cortex.
Объединив ваши краткие описания медицинских изделий, одобренных FDA, с результатами поиска в PubMed, агент сможет отвечать на более сложные вопросы — например, связывать результаты по безопасности и эффективности устройства с более широкими клиническими данными или ссылаться на соответствующие исследования для обеспечения контекста. Этот этап обогащения превращает ваш рабочий процесс с документами FDA в мощную среду биомедицинских знаний, готовую для генерации с расширенным поиском (RAG) и передовых агентных приложений.
7. Создайте агента Cortex.
После внедрения наших сервисов поиска и аналитики следующим шагом станет создание агента Cortex . Агент координирует работу нескольких инструментов для обработки сложных, многоэтапных запросов о документах в агентном режиме. Это можно настроить непосредственно в пользовательском интерфейсе Snowflake или программно (см. исходный код в репозитории).
При определении агента вы указываете три основных компонента:
- Инструкции — общие указания о том, как агент должен отвечать и взаимодействовать с пользователями. Например, вы можете указать, что ответы всегда должны содержать ссылки на источники или что даты, установленные регулирующими органами, должны возвращаться в формате ГГГГ-ММ-ДД.
- Инструменты – возможности агента, которые в данном случае включают в себя:
- Поиск в Cortex по документам медицинских устройств, одобренных FDA (landingai_apps_db.fda.medical_device_chunks)
- Cortex Analyst для преобразования естественного языка в SQL на основе структурированных данных с устройств (landingai_apps_db.fda.medical_device_extracted)
- Поиск в Cortex в корпусе биомедицинских исследований PubMed для обогащения научной базы данных.
- Хранимая процедура для загрузки исходных документов по запросу.
- Оркестрация — это логика планирования, которая направляет агента на выбор правильного инструмента (или последовательности инструментов) для каждого запроса. Например, вопрос пользователя типа «Обобщите результаты оценки безопасности стентов и покажите подтверждающие клинические исследования» потребует от агента сначала извлечь структурированные данные из обзоров FDA, а затем найти соответствующие исследования в PubMed для дальнейшего анализа.
Инструкции и инструменты вы можете увидеть на этом скриншоте:

8. Обеспечьте взаимодействие с пользователем с помощью Snowflake Intelligence.
Заключительный этап — предоставление доступа к агенту бизнес-пользователям через Snowflake Intelligence, разговорный интерфейс, встроенный непосредственно в Snowflake. Пользователи могут взаимодействовать с агентом в привычном формате чата, задавая как структурированные (похожие на SQL) так и неструктурированные (повествовательные) вопросы. Ответы дополняются ссылками на фрагменты документов FDA и, при необходимости, ссылками для загрузки исходных файлов.
Доступ и использование регулируются встроенной в Snowflake системой управления доступом на основе ролей (RBAC), гарантирующей, что пользователи видят только те данные, к просмотру которых у них есть разрешение. Все взаимодействия регистрируются, что упрощает мониторинг использования и обеспечивает возможность аудита.
Для организаций, желающих расширить возможности решения за пределы Snowflake, REST API Cortex Agents может предоставить доступ к агенту для других бизнес-приложений, таких как панели мониторинга соответствия требованиям, инструменты автоматизации рабочих процессов или внутренние порталы знаний.
Взаимодействие с агентом
Давайте рассмотрим пример взаимодействия, чтобы увидеть возможности LandingAI Agentic Document Extraction в сочетании со Snowflake Cortex.
Пример 1: Задать вопрос, для ответа на который необходимо понимать изображение, встроенное в рисунок.
Рассмотрим краткое описание безопасности и эффективности устройства EXCOR Pediatric Ventricular Assist Device, представленное компанией Berlin Heart Inc. в рамках заявки PMA P160035. В большинстве приложений, основанных на алгоритмах распознавания образов (RAG), значительная часть документа — например, рисунок 12 на странице 38 — будет проигнорирована последующими системами искусственного интеллекта. Тем не менее, эти рисунки содержат богатый контекст, бесценный для медицинских исследователей.

Поскольку для анализа мы использовали инструмент Agentic Document Extraction от LandingAI, мы можем задать такой вопрос:
«Обобщите кривую Каплана-Мейера вероятности отсутствия летального исхода для всех групп пациентов, которым была имплантирована педиатрическая помпа EXCOR».
Как видно на скриншоте ниже, агент может дать точный, обоснованный ответ, используя извлеченный рисунок. Он выделяет такие моменты, как точки выравнивания кривой, различия между группами имплантатов и даже статистическую значимость. Важно отметить, что решение четко показывает, из какого именно рисунка и какой части страницы был получен ответ — чего не могут обеспечить большинство других подходов.


Пример 2: Вопрос о самом последнем документе.
В качестве другого примера представим, что мы хотим узнать:
«Какой самый последний документ по безопасности и эффективности у нас есть для заявителей в Соединенных Штатах? На основе этого документа предоставьте несколько соответствующих статей из PubMed».
Агент интерпретирует это как задачу, состоящую из двух частей:
- Используйте Cortex Analyst для генерации SQL-запросов, которые будут запрашивать данные из извлеченных структурированных полей и определять последнюю дату утверждения.
- После того как документ будет найден, используйте расширение PubMed Cortex Knowledge Extension, чтобы найти связанные биомедицинские исследования для дальнейшего анализа.
Эта схема демонстрирует, как агент может беспрепятственно объединять структурированные запросы, анализ неструктурированных документов и внешние источники информации.
Здесь представлены скриншоты процесса планирования агентом своего подхода и конечного результата.


Подводя итоги
Технология Agentic Document Extraction от LandingAI, интегрированная в Snowflake, преобразует неструктурированные мультимодальные документы в управляемые ресурсы, готовые к использованию в системах искусственного интеллекта. Результат:
- Обоснованные ответы для обеспечения доверия и возможности аудита
- Структурированные поля для аналитики и автоматизации
- Обработанные данные , обеспечивающие работу решений RAG и агентных систем.
- Единый периметр безопасности с унифицированным управлением
Мы продемонстрировали это на практическом примере из области медицинских наук, но та же закономерность применима ко всем отраслям и бизнес-функциям — от финансовых услуг до здравоохранения, производства и многого другого.
Теперь ваша очередь раскрыть потенциал ваших неструктурированных документов с помощью Agentic Document Extraction. И не останавливайтесь на достигнутом: используйте функции мониторинга и анализа на основе искусственного интеллекта Snowflake, чтобы измерять, отслеживать и доказывать эффективность вашего решения.
Ссылки и источники
Извлечение документов агентом | LandingAI
Визуальная игровая площадка | LandingAI
Использование ADE на Snowflake | Документация LandingAI
Поиск в коре головного мозга | Документация Snowflake
Аналитик Cortex | Документация Snowflake
Cortex Agents | Документация Snowflake
Расширения знаний Cortex | Документация Snowflake
Обзор системы Snowflake Intelligence
PubMed
Источники : пакеты документов Управления по санитарному надзору за качеством пищевых продуктов и медикаментов США (FDA) по одобрению медицинских изделий (краткие обзоры данных о безопасности и эффективности). Все документы находятся в открытом доступе по адресу https://www.accessdata.fda.gov/scripts/cdrh/cfdocs/cfpcd/classification.cfm
FDA не одобряет данный анализ или решение.
Содержание
Источник: landing.ai

























