
M-REGLE (Multimodal REpresentation learning for Genetic discovery on Low-dimensional Embeddings) — это метод искусственного интеллекта, который одновременно анализирует несколько потоков медицинских данных. Совместное обучение на основе различных типов данных создает более полные представления и значительно повышает вероятность обнаружения генетических связей с заболеваниями.
Быстрые ссылки
- Бумага M-REGLE
- Бумага REGLE / U-REGLE
- Делиться
Все, от медицинских специалистов с передовыми технологиями до простых умных часов, генерирует данные в беспрецедентных масштабах. Агрегация электронных медицинских карт, медицинской визуализации, диагностических тестов, геномных данных и даже измерений в реальном времени с помощью умных часов создает огромный массив данных для анализа исследователями и врачами. Эти разнообразные потоки данных часто несут уникальные и перекрывающиеся сигналы, даже в пределах одной и той же системы органов.
В сердечно-сосудистой системе, например, электрокардиограмма (ЭКГ) измеряет электрическую активность сердца, а фотоплетизмограмма (ФПГ) — распространенная в умных часах — отслеживает изменения объема крови. Совместный анализ этих методов позволяет одновременно оценить как электрическую систему сердца, так и эффективность его насосной функции, обеспечивая таким образом более полную картину здоровья сердца. Интеграция этих физиологических показателей с генетической информацией из крупных национальных биобанков может позволить выявить генетические основы заболеваний.
Наша предыдущая работа, REGLE, оказалась успешной для генетических исследований с использованием данных о здоровье, но она была разработана для одного типа данных (т.е., для одномодального подхода). В качестве альтернативы, анализ каждой модальности по отдельности с последующей попыткой объединения результатов (то, что мы называем U-REGLE или Unimodal REGLE) также может быть не самым эффективным способом. U-REGLE может упустить тонкую общую информацию между различными модальностями. Вместо этого мы предположили, что совместное моделирование этих взаимодополняющих потоков данных усилит важные биологические сигналы, уменьшит шум и приведет к более мощным генетическим открытиям.
Здесь мы представляем нашу недавнюю статью «Использование мультимодального ИИ для улучшения генетического анализа сердечно-сосудистых признаков», опубликованную в журнале American Journal of Human Genetics . Мы разработали мультимодальную версию REGLE, названную M-REGLE, которая позволяет одновременно анализировать несколько типов клинических данных. M-REGLE обеспечивает меньшую ошибку реконструкции, выявляет больше генетических ассоциаций и превосходит показатели риска в прогнозировании сердечных заболеваний по сравнению со своим предшественником, U-REGLE.

Обзор этапов работы M-REGLE по сравнению с запуском нашей предыдущей модели REGLE для каждой модальности отдельно (U-REGLE, или Unimodal REGLE).
Задача: увидеть картину целиком.
Основная идея M-REGLE заключается в том, что различные клинические методы, особенно те, которые относятся к одной системе органов (например, к кровеносной системе), кодируют как взаимодополняющую, так и перекрывающуюся информацию. Например, в 12-канальной ЭКГ различные отведения расположены в разных местах на теле. Для определения места инфаркта миокарда или диагностики аритмий врачи анализируют информацию из конкретных отведений. Подход M-REGLE, который объединяет несколько методов (например, 12 отведений ЭКГ или одно отведение плюс данные ФПГ) перед процессом обучения представлений, предлагает более точный инструмент, превосходящий другие в выявлении генетических ассоциаций, анализе сложных физиологических данных и прогнозировании заболеваний.
Для эффективного решения этой задачи M-REGLE использует надежный многоэтапный подход, основанный на совместном обучении. Вместо анализа 12 различных отведений ЭКГ или отдельных сигналов ЭКГ и ФПГ, M-REGLE сначала объединяет их. Затем он использует сверточный вариационный автокодировщик (CVAE) для обучения сжатой, объединенной «сигнатуры» (латентных факторов) из этих множественных потоков данных. CVAE предназначен для захвата наиболее важной информации в низкоразмерном, в значительной степени некоррелированном представлении. Он состоит из сетей кодировщика и декодера, где кодировщик сжимает сигналы ЭКГ и ФПГ до латентных факторов, а сеть декодера восстанавливает сигналы из созданных латентных факторов. Для обеспечения истинной независимости изученных факторов к этим сгенерированным CVAE сигнатурам применяется анализ главных компонентов (PCA). Наконец, мы находим ассоциации (значимую корреляцию) между вычисленными независимыми факторами и генетическими данными с помощью полногеномных ассоциативных исследований (GWAS). Результаты этих отдельных полногеномных ассоциативных исследований (GWAS) статистически объединяются для выявления генетических вариаций, связанных с лежащей в их основе физиологической системой.
Более качественно усвоенные представления
M-REGLE — это усовершенствованная версия U-REGLE, позволяющая стабильно получать более качественные «обученные представления» данных. Медицинские данные, такие как ЭКГ, состоят из сотен отдельных точек данных. При анализе нескольких медицинских методов, вместо обработки каждого метода по отдельности, M-REGLE выделяет наиболее важные характеристики и объединяет их в «скрытые факторы». Такой подход привел к значительному снижению ошибок реконструкции и лучшему сбору основной информации из исходных волновых форм по сравнению с обучением для каждого метода по отдельности. Для 12-канальных ЭКГ M-REGLE снизила ошибку реконструкции на 72,5%.
Интерпретируемость проливает свет на эмбеддинги.
Одним из преимуществ генеративного ИИ является его интерпретируемость. В нашем исследовании мы использовали эмбеддинги M-REGLE, чтобы показать связь между этими эмбеддингами и ЭКГ и ФПГ-волнами, в частности, как изменение координат отдельных эмбеддингов влияет на реконструированные ЭКГ и ФПГ-волны, полученные с помощью декодера M-REGLE.
Мы сосредоточились на определении координат, которые наилучшим образом различали бы образцы с фибрилляцией предсердий (ФП) и без нее. Наиболее отчетливыми оказались встраивания M-REGLE в позициях 4, 6 и 10. Когда мы изменяли значения в 4-м встраивании M-REGLE из диапазона [-2, 2], сохраняя при этом остальные встраивания M-REGLE неизменными, мы наблюдали соответствующие изменения в реконструированных отведениях ЭКГ I и ФПГ: амплитуда сегмента зубца Т в отведении ЭКГ I изменялась, а дикротическая выемка сигнала ФПГ демонстрировала небольшое изменение. Дикротическая выемка предоставляет ценную информацию о сердечно-сосудистой функции и здоровье. Например, менее выраженная или отсутствующая дикротическая выемка часто ассоциируется с повышенной жесткостью артерий.

Влияние изменения 4-го M-REGLE-встраивания на реконструированные отведения ЭКГ I и ФПГ, приводящее к уменьшению амплитуды сегмента Т в отведении ЭКГ I ( слева ) и изменению выраженности дихроичной выемки в ФПГ ( справа ).
Расширенные возможности генетических исследований
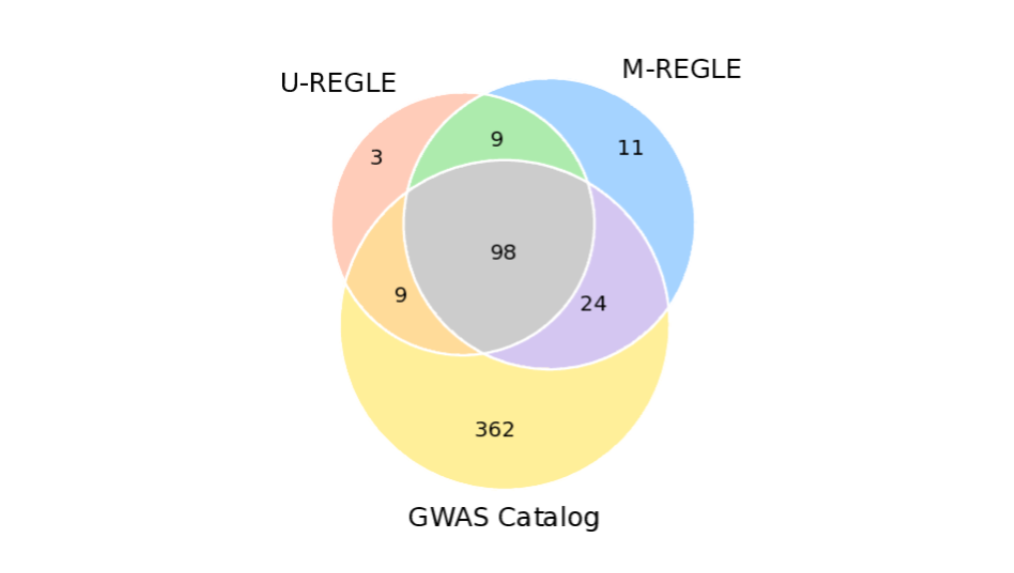
M-REGLE также превзошёл U-REGLE в выявлении генетических ассоциаций с сердечно-сосудистыми заболеваниями. Для 12-канальной ЭКГ M-REGLE выявил на 19,3% больше ассоциированных генетических локусов (регионов в геноме), чем одномодальный подход. Для ЭКГ отведения I + ФПГ M-REGLE обнаружил на 13,0% больше локусов. Важно отметить, что подавляющее большинство этих результатов (24/35 для 12-канальной ЭКГ и 11/12 для ЭКГ отведения I + ФПГ) подтвердили известные генетические ассоциации для признаков ЭКГ или ФПГ, как сообщается в каталоге GWAS. M-REGLE также обнаружил несколько новых локусов, ранее не ассоциированных с этими признаками, некоторые из которых показали связь с сердечно-сосудистыми признаками в других базах данных.

Трехсторонняя диаграмма Венна, отображающая локусы из каталога GWAS, локусы, обнаруженные с помощью M-REGLE (12-канальная ЭКГ), и локусы, обнаруженные с помощью U-REGLE. Каталог GWAS указывает на ранее обнаруженные локусы.
Улучшенные показатели полигенного риска
Полигенный показатель риска (ППР) количественно оценивает генетический риск развития заболевания у человека. Мы обнаружили, что ППР, разработанный с использованием генетических вариантов, выявленных с помощью M-REGLE (на основе данных 12-канальной ЭКГ), значительно превосходит ППР, разработанный с помощью U-REGLE, в прогнозировании сердечно-сосудистых заболеваний, особенно фибрилляции предсердий (ФП). ППР, разработанный с помощью M-REGLE, значительно лучше выявлял лиц из группы риска. Эти улучшения ППР для ФП наблюдались не только в UK Biobank, но и были независимо подтверждены в других крупных базах данных, таких как Indiana Biobank, EPIC-Norfolk и British Women's Heart and Health Study.

Сравнение полигенных показателей M-REGLE для фибрилляции предсердий (ФП). Вычислены распространенность, AUC-ROC и AUC-PR (* указывает на статистически значимую разницу).
Почему работает M-REGLE?
Сила M-REGLE заключается в способе обработки информации. Учитывая несколько модальностей на начальном этапе, M-REGLE получает три основных преимущества. Во-первых, он эффективно улавливает общую информацию, обучаясь ей один раз, а не многократно для каждой модальности. Во-вторых, он усиливает уникальные и взаимодополняющие сигналы, которые предоставляет каждая модальность. В-третьих, M-REGLE снижает уровень шума, поскольку информация из одной модальности может помочь уточнить или отфильтровать шум в другой. Все это приводит к более четкому и надежному сигналу для мощного последующего генетического анализа.
Будущее за мультимодальными технологиями.
Это исследование представляет собой шаг вперед в использовании богатых, мультимодальных данных о здоровье, которые становятся все более доступными. M-REGLE предлагает способ выявления новых генетических связей со сложными заболеваниями, улучшения нашей способности прогнозировать риск заболеваний и потенциального определения новых мишеней для терапии. Кроме того, с появлением интеллектуальных носимых устройств, непрерывно собирающих физиологические данные, такие как ЭКГ и ФПГ, методы, подобные M-REGLE, будут иметь решающее значение для преобразования данных о здоровье в ценные выводы и, в конечном итоге, для улучшения результатов лечения.
Благодарности
Эта работа представляет собой результат совместной работы многих участников и учреждений. Мы искренне благодарим наших сотрудников за их неоценимый вклад: Ючена Чжоу, Джастина Козентино, Говарда Янга, Эндрю Кэрролла, Кори Й. Маклина, Бабака Бехсаза (Google); Закари Р. Маккоу (Университет Северной Каролины); Тэ-Хви Швантес-Ан, Донгбина Лая (Университет Индианы); Махантеша И. Бирадара, Роберта Любена, Йоргена Энгманна, Руи Провиденсию, Энтони П. Хаваджу (Университетский колледж Лондона); Патрисию Б. Манро (Университет королевы Марии в Лондоне). Мы также благодарим Анастасию Беляеву за рецензирование рукописи, Грега Коррадо, Шравью Шетти и Майкла Бреннера за их поддержку, а также Моник Бруйетт за помощь в написании этого поста в блоге.
Источник: research.google