
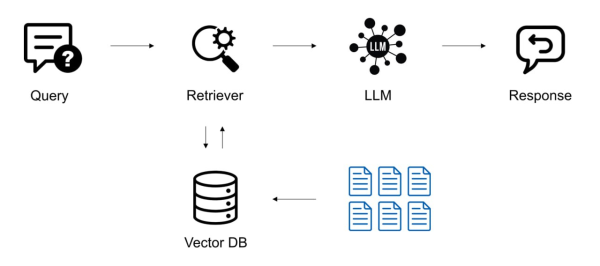
Надеюсь, все знают что такое RAG 🙂 Для тех, кто не знает: это такая система, которая позволяет искать информацию и отвечать на вопросы по внутренней документации.
Архитектура RAG может быть как очень простой, так и весьма замысловатой. В самом простом виде она состоит из следующих компонентов:
Векторное хранилище — хранит документы в виде чанков — небольших фрагментов текста.
Ретривер — механизм поиска. Получает на вход искомую строку и ищет в векторном хранилище похожие на нее чанки (по косинусному сходству).
LLM — большая языковая модель, которая на основе найденных чанков формирует окончательный ответ.

Более сложные решения могут включать в себя реранкер, гибридный поиск и другие хитрые плюшки (на Хабре есть много статей с подробным описанием RAG’а).
Но, даже самая навороченная архитектура не справится с некоторыми вопросами. Рассмотрим такой пример:
Какая была прибыль в компании Магнит за 2020
Тут ничего сложного. С таким вопросом справится даже RAG на одном семантическом поиске. Но если его “немного” усложнить:
Найди в годовых отчетах компании Магнит за последние 3 года упоминания ключевых рисков. Выдели, как менялась формулировка этих рисков от года к году.
Это уже не вопрос. Это целая задача. Причем аналитическая. Чтобы ее успешно решить, нужно разбить ее на более мелкие подзадачи:
Определить, какой сейчас год (допустим 2025).
Затем найти в БД информацию за каждый год:
Какие были ключевые риски в годовом отчете компании Магнит в 2022 году?
Какие были ключевые риски в годовом отчете компании Магнит в 2023 году?
Какие были ключевые риски в годовом отчете компании Магнит в 2024 году?
Проанализировать полученные ответы и выдать финальный ответ.
Обычный RAG ни на что подобное не способен. Для такой задачи нужен агентный RAG.
Чем же они отличается? Обычный RAG, хотя и может иметь некоторые ответвления, но это всегда прямолинейный последовательный конвейер: ретривер → реранкер → LLM.
В агентном раге нет никакого жестко заданного пайплайна. Есть агент (на базе LLM) и есть набор инструментов (один из которых — ретривер), к которым он может обращаться. И агент сам решает когда и какой инструмент вызвать для выполнения задачи. Он может вызвать один инструмент, а может все (причем в любой последовательности), а может вызвать один и тот же инструмент множество раз, если предыдущие результаты ему не понравились. В процессе работы над запросом агент накапливает историю всех вызовов. И в конце концов LLM выдает финальный ответ.

А сейчас попробуем реализовать игрушечный пример агентного RAG’а, который сможет ответить на такой вопрос:
Найди в годовых отчетах компании Магнит за последние 5 лет упоминания ключевых рисков. Выдели, как менялась формулировка этих рисков от года к году.
Легенда:
Шаг 1. Векторное хранилище
Шаг 2. Загрузка документов
Шаг 3. MCP-сервер
Шаг 4. LLM
Шаг 5. Агент
Вместо вывода
Реализация
Шаг 1. Векторное хранилище
Векторное хранилище необходимо чтобы хранить чанки и вектора на их основе. По этим векторам мы будем сопоставлять запрос пользователя и чанк. И тем самым находить и возвращать наиболее релевантные чанки.
В качестве векторного хранилища будем использовать хорошо зарекомендовавшую себя БД Qdrant:
1.1. Скачиваем docker-образ кудранта:
docker pull qdrant/qdrant
1.2. Запускаем контейнер:
docker run -p 6333:6333 -p 6334:6334 -v «$(pwd)/qdrant_storage:/qdrant/storage:z» qdrant/qdrant
После этого web-интерфейс Qdrant будет доступен по адресу:
localhost:6333/dashboard
1.3. Создаем коллекцию, в которой будут храниться чанки документов:
from qdrant_client import QdrantClient from qdrant_client.models import Distance, VectorParams # Создаем подключение client = QdrantClient(url=’http://localhost:6333′) # Создаем коллекцию client.create_collection( collection_name = ‘rag_agent’, vectors_config = VectorParams(size=1536, distance=Distance.DOT), )

Шаг 2. Загрузка документов

Для экспериментов я накачал с сайта ИНИОН РАН кучу разных отчетов за разные года и от разный компаний (и положил их все в одной папке).
Если взглянуть на них, то можно обнаружить что они имеют довольно сложную структуру: много колонок, много графиков, много таблиц и т.д. Я перепробовал пару десятков PDF-парсеров. В принципе с задачей справились три: Marker, olmOCR, Docling. По внешнему виду мне больше всего понравился Marker — его и будем использовать
Для красивого оформления Marker вставляет много служебных символов (тире). Другие кандидаты — olmOCR, Docling — делают это проще. Например, с помощью HTML-тэгов. Поэтому с т.з. RAG может лучше подойдут другие два кандидата — надо тестировать.
2.1. Т.к. отчеты довольно длинные, а Marker работает очень небыстро, то мы предварительно распарсим все PDF файлы и сохраним их текстовое содержимое в TXT-файлах.
import os import glob from marker.converters.pdf import PdfConverter from marker.models import create_model_dict from marker.output import text_from_rendered # Формируем PDF-парсер converter = PdfConverter(artifact_dict=create_model_dict()) # Формируем список всех PDF файлов и путей до них files = glob.glob(os.path.join(‘/docs’, ‘*.pdf’)) # Проходимся по каждому файлу for f in files: full_file_name = f.split(‘/’)[-1] # вытаскиваем название файла из пути file_name = full_file_name.split(‘.’)[0] # вытаскиваем название без расширения # Парсим PDF файл rendered = converter(f) text, _, _ = text_from_rendered(rendered) # Сохраняем файл with open(f’/docs/{file_name}.txt’, ‘w’, encoding=’utf-8′) as new_file: new_file.write(text)
Здесь мы:
Создаем PDF-парсер.
Формируем список всех PDF файлов в указанной папке:
Вытаскиваем текст из PDF файла с помощью Marker’а.
Сохраняем текст в TXT-файле с тем же названием.
2.2. Теперь нам нужно перевести эти отчеты в вектор и загрузить в кудрант. Для получения эмбедингов из чанков мы будем использовать один из топовых (согласно MTEB) энкодеров для русского языка — FRIDA.
Сначала скачайте его:
git lfs clone https://huggingface.co/ai-forever/FRIDA
2.3. Для загрузки документов в коллекцию выполните такой код:
import os import glob import uuid from qdrant_client import QdrantClient from qdrant_client.models import PointStruct from sentence_transformers import SentenceTransformer from langchain_text_splitters import RecursiveCharacterTextSplitter # Создаем подключение к Qdrant q_client = QdrantClient(url=’http://localhost:6333′) # Подгружаем эмбедер emb_model = SentenceTransformer(‘/models/FRIDA’) # Создаем сплиттер text_splitter = RecursiveCharacterTextSplitter( chunk_size = 1500, chunk_overlap = 500, separators = [‘nn’, ‘n’, ‘ ‘, »]) # Формируем список всех TXT файлов и путей до них files = glob.glob(os.path.join(‘/docs’, ‘*.txt’)) # Проходимся по каждому файлу for f in files: print(f) file_name = f.split(‘/’)[-1] # вытаскиваем название файла из пути # Подгружаем файл text = open(f, ‘r’).read() # Разбиваем текст на чанки chunks = text_splitter.split_text(text) # Проходимся по каждому чанку for chunk_text in chunks: # Добавляем к чанку название файла chunk_text = f’Файл: {file_name}n{chunk_text}’ # Формируем структуру для Qdrant point = PointStruct( id = str(uuid.uuid4()), vector = emb_model.encode(chunk_text, prompt_name=’search_document’), payload = {‘file’: file_name, ‘chunk’: chunk_text}) # Отправляем в Qdrant _ = qclient.upsert(collection_name = ‘rag_agent’, points = [point], wait = True)
Тут мы:
Создаем:
Подключение к Qdrant.
С помощью SentenceTransformer загружаем эмбедер.
Сплитер.
Вытаскиваем все TXT файлы из папки и проходимся по каждому из них:
Считываем текст из файла.
Разбиваем текст на чанки (по 1500 на чанк с нахлестом в 500).
Проходимся по всем чанкам:
Формируем объект, который содержит:
Уникальный идентификатор
Вектор — эмбединг который выдала нам FRIDA на основе текста чанка.
Название файла
Текст чанка.
Отправляем чанк в кудрант.
З.Ы.1. Обратите внимание, что мы в каждый чанк добавляем название файла. Если название файла будет содержательным, то это добавит общий контекст происходящего к каждому чанку. Эта техника называется Contextual Retrieval.
З.Ы.2. При работе с FRIDA для качественного перевода текста в вектора нужно использовать правильные префиксы: search_query, search_document, paraphrase, categorize, categorize_sentiment, categorize_topic, categorize_entailment. Почитайте в документации как это нужно делать: HF, Хабр.

Шаг 3. MCP-сервер
Теперь нам нужно создать MCP сервер. MCP сервер дает LLM информацию, какие инструменты ей доступны, а также выступает как прокси для вызова этих самых инструментов. Чуть более подробно (и с примером) про MCP-сервера можете почитать в моей статье: Разработка MCP-сервера на примере CRUD операций.
Создайте файл python3 mcp_server.py:
from datetime import date from fastmcp import FastMCP from qdrant_client import QdrantClient from sentence_transformers import SentenceTransformer # Инициализация MCP сервера mcp = FastMCP(‘Employee Management System’) # Создаем подключение q_client = QdrantClient(url=’http://localhost:6333′) # Подгружаем эмбедер emb_model = SentenceTransformer(‘/models/FRIDA’) # Получить текущую дату @mcp.tool() def get_current_date(): »’Возвращает текущую дату»’ return str(date.today()) # Поиск по чанкам @mcp.tool() def chunks_search(query): »’ Ищет релевантные фрагменты текста в векторной базе данных. Возвращает список наиболее релевантных чанков объединенных в один текст. »’ search_result = q_client.query_points( collection_name = ‘rag_agent’, query = emb_model.encode(query, prompt_name=’search_query’), with_payload = True, limit = 10 ).points chunks = [s.payload[‘chunk’] for s in search_result] chunks = ‘nn’.join(chunks) return chunks if __name__ == ‘__main__’: # Запуск сервера mcp.run(transport=’http’, host=’192.168.0.108′, port=9000)
Здесь мы:
Инициируем сервер.
Создаем подключение к кудрант.
Подгружаем фриду — она нам понадобится для получения эмбединов из искомого запроса.
Объявляем две функции:
get_current_date — возвращает текущую дату.
chunks_search — выполняет поиск чанков на основе входящей строки. Найденные чанки объединяются в одну длинную строку.
Запускаем сервер на 9000 порту.
Запускаем сервер в терминале:
python3 mcp_server.py
Теперь сервис доступен по адресу:
http://192.168.0.108:9000/mcp
Шаг 4. LLM
LLM это мозг нашего агента. Она обрабатывает информацию и определяет какие инструменты вызвать. Но чтобы использовать LLM в качестве агента она должна обладать одной важной функцией — Function Calling (или Tool Calling). Не многие локальные LLM да еще и небольшого размера могут похвастаться таким функционалом. Одна из них — Qwen3 14B — ее и будем использовать.
4.1. Скачаем LLM:
git lfs clone https://huggingface.co/Qwen/Qwen3-14B
4.2. Далее скачиваем докер-образ vLLM:
docker pull vllm/vllm-openai:v0.10.1.1
4.3. Для запуска модели выполните в терминале примерно такую команду:
docker run —gpus all -v /models/qwen/Qwen3-14B/:/Qwen3-14B/ -p 8000:8000 —env «TRANSFORMERS_OFFLINE=1» —env «HF_DATASET_OFFLINE=1″ —ipc=host —name vllm vllm/vllm-openai:v0.10.1.1 —model=»/Qwen3-14B» —tensor-parallel-size 2 —max-model-len 40960 —enable-auto-tool-choice —tool-call-parser hermes —reasoning-parser deepseek_r1
Теперь наша модель доступна как сервис по адресу: http://localhost:8000
Более подробно, как в Qwen можно вызывать инструменты можно почитать в официальной документации.
Шаг 5. Агент
Ну вот мы и добрались до агента 🙂 Запилить его можно и на чистом питоне, но это довольно громоздкая махина, а изобретать велосипед не хочется. Поэтому мы воспользуемся готовым фреймворком — Agno. Это относительно новая библиотека. Она неплохо себя показала в работе, еще не успела обрасти ненужным функционалом как некоторые ее коллеги и обладает приличной документацией (что примечательно со своим AI-ассистентом для ответов на вопросы по этой самой документации).
from agno.agent import Agent from agno.models.vllm import VLLM from agno.db.sqlite import SqliteDb from agno.tools.mcp import MCPTools from agno.utils.pprint import pprint_run_response mcp_tools = MCPTools(transport=’streamable-http’, url=’http://192.168.0.108:9000/mcp’) await mcp_tools.connect() instruction = »’Ты — интеллектуальный ассистент. Твоя задача — отвечать на вопросы пользователей на основе предоставленных документов. Для обработки запроса тебе доступны два инструмента: getcurrent_date — возвращает текущую дату. chunkssearch — выполняет поиск по корпоративной документации. В корпоративной базе данных хранятся различные отчеты. Например: «Газпром, Годовой отчет, 2021», «ЛУКОЙЛ, Финансовый отчет по РСБУ, 2020», «X5 Group, Отчет устойчивого развития, 2018″. Информация в корпоративной базе данных разбита на чанки. Каждый чанк содержит название отчета и кусок текста. Для семантического поиска по чанкам используется инструмент chunkssearch. Инструкция: 1. Сначала проанализируй запрос и определяйте необходимые подзадачи. 2. Используйте поиск для нахождения релевантной информации. 3. Если необходимо найти информацию из разных периодов, то ищи их с помощью самостоятельных подзапросов. 4. Всегда используй функцию getcurrent_date, если необходимо определить текущую дату. 5. Отвечай на основе найденной информации, не придумывай факты. Если информации недостаточно, укажи это в ответе. »’ agent = Agent( model = VLLM(id=’/Qwen3-14B’, base_url=’http://192.168.0.108:8000/v1′), db = SqliteDb(db_file=’/rag_agent/agno.db’), tools = [mcp_tools], #[current_date,chunks_search] instructions = instruction ) query = »’Найди в годовых отчетах компании Магнит за последние 5 лет упоминания ключевых рисков. Выдели, как менялась формулировка этих рисков от года к году.»’ result = await agent.arun(query, debug_mode=True) pprint_run_response(result, markdown=True)
Здесь мы:
Подключаемся к MCP серверу и запрашиваем доступные инструменты.
Описываем инструкцию для агента.
Объявляем агента, которому передаем:
Способ подключения к LLM.
Способ хранения истории запросов.
Все доступные инструменты.
Инструкцию.
Выполняем запрос через агента и распечатываем результат.
Если посмотреть на лог вызовов, то можно увидеть, что сначала LLM запросила текущую дату.

А затем выполнила 5 вызовов к ретриверу, в которых извлекла информацию по годовым отчетам за каждый из 5 лет.

Обработала всю полученную информацию и выдала вот такой финальный ответ:
Анализ ключевых рисков в годовых отчетах «Магнита» за 2020–2024 гг.
───────────────────────────────────────────────────────2020 год:
Основные риски:
— Риск ликвидности — контроль за резервами, банковскими операциями и денежными потоками.
— Пандемия COVID-19 — изменение потребительского поведения, нормативного регулирования и прерывание цепочек поставок.
— Экономическая нестабильность — влияние санкций и геополитических факторов (упомянуты в контексте прогнозов).Формулировка: Акцент на операционную устойчивость, особенно в условиях пандемии. Риски представлены как внешние (пандемия, санкции) и внутренние (ликвидность).
───────────────────────────────────────────────────────
2021 год:
Основные риски:
— Инфляция и рост цен на сырье — давление на потребителей и затраты.
— Геополитическая напряженность — рост волатильности на финансовых рынках и девальвация рубля (с февраля 2022 г.).
— Цифровая трансформация — необходимость адаптации к изменяющимся технологическим требованиям.
— Управление оборотным капиталом — оптимизация запасов и ликвидности.Формулировка: Расширение списка рисков до макроэкономических и технологических. Появление ESG-аспектов (устойчивое развитие, экологические и социальные обязательства).
───────────────────────────────────────────────────────
2022 год:
Основные риски:
— Санкционное давление — ограничения на международные операции и доступ к финансовым ресурсам.
— Импортозамещение — необходимость перестройки поставок и локализации производства.
— Долговая нагрузка — контроль за уровнем задолженности и дивидендными выплатами.Формулировка: Акцент на геополитические и финансовые риски, связанные с санкциями. Упоминается стратегическое реорганизование (например, приобретение «Дикси»).
───────────────────────────────────────────────────────
2023 год:
Основные риски:
— Количественная оценка рисков — внедрение систематического подхода к анализу всех бизнес-процессов.
— Экологические и социальные риски (ESG): сокращение выбросов, расхода воды, пищевых отходов.
— Развитие ответственных источников продукции — сотрудничество с местными поставщиками.
— Цифровизация — переход на ERP-системы и электронную торговлю.Формулировка: Переход от реактивного управления к проактивному. Риски структурированы по категориям (экологические, операционные, стратегические), с акцентом на устойчивое развитие.
───────────────────────────────────────────────────────
2024 год:
Основные риски:
— Интеграция новых структур — риски, связанные с приобретениями и расширением бизнеса.
— Обучение сотрудников — развитие компетенций в управлении рисками.
— Цифровая трансформация — внедрение ИТ-решений для поставщиков и клиентов.
— Долгосрочные обязательства — выполнение целей по снижению долговой нагрузки и росту EBITDA.Формулировка: Упор на стратегическую подготовленность и инновации. Риски рассматриваются как возможность для развития (например, цифровизация и ESG).
───────────────────────────────────────────────────────
Итог: эволюция формулировок
— 2020–2021: Акцент на внешние шоки (пандемия, санкции) и операционную устойчивость.
— 2022–2023: Расширение до ESG-рисков и цифровизации, акцент на долгосрочные стратегии.
— 2024: Формулировки становятся более систематизированными, риски рассматриваются как инструменты для роста, а не только угрозы.
Вместо вывода
Мы рассмотрели относительно простую реализацию. Но агенты несколько сложнее: у них есть сессии, есть состояния, есть хранилища и много чего другого. Еще можно реализовать кучу агентов, каждый из которых выполняет свою задачу и они взаимодействуют между собой. Но это уже на самостоятельное изучение 🙂
Из улучшений, которые так и напрашиваются после реализации этого игрушечного примера:
Гибридный поиск (BM25 + семантика).
Метаданные и фильтры для чанков.
Подобрать гиперпараметры для вызова LLM.
Что касается инструментов. В данном пример у нас их всего два инструмента. Но даже сейчас этого кажется уже недостаточно. Возьмем такой пример:
Сравни доходы трех самых крупных компаний за прошлый год.
Он очень похож на уже рассмотренный нами пример. Нам также нужно: определитель текущую дату и выполнить поиск по чанкам. Но очевидно здесь нужен еще один инструмент — какая-то табличка, в которой хранится статистическая информация по доходам компаний, чтобы вернуть три с самым большим доходом.
И нигде нет конечного списка инструментов, которые вам могут понадобится. Нужно самим мониторить запросы пользователей и смотреть что им нужно.
З.Ы. Современные агентные библиотеки уже включают в себя готовые инструменты для многих популярных сервисов.
Из недостатков агентного рага:
Мониторинг и анализ работоспособности требует больше усилий, чем обычный RAG, поскольку генерируется куда больше информации.
Тратится гораздо больше токенов (и не всегда с пользой). Если у вас LLM платная, то это может стать проблемой.
Время выполнения значительно дольше. И что самое плохое, всю эту простыню выполнения нельзя вывести пользователю в режиме стрима, поскольку там много служебной информации. Так что пользователю остается только ждать.
Мои курсы: Разработка LLM с нуля | Алгоритмы Машинного обучения с нуля
Источник: habr.com

























