
Уроки, извлеченные с помощью LlamaIndex и Modal
Делиться

Я предполагал, что большинство компаний к настоящему времени уже создали или внедрили собственные агенты RAG.
Агент знаний ИИ может копаться во внутренней документации — веб-сайтах, PDF-файлах, случайных документах — и отвечать сотрудникам в Slack (или Teams/Discord) в течение нескольких секунд. Таким образом, эти боты должны значительно сократить время просеивания информации для сотрудников.
Я видел несколько таких проектов в крупных технологических компаниях, например, в AskHR от IBM, но пока они не получили широкого распространения.
Если вы хотите понять, как они устроены и сколько ресурсов требуется для создания простого из них, эта статья для вас.

Я расскажу об инструментах, методах и архитектуре, а также рассмотрю экономику создания чего-то подобного. Я также включу раздел о том, на чем вы в конечном итоге сфокусируетесь больше всего.

В конце также приведена демонстрация того, как это будет выглядеть в Slack.
Если вы уже знакомы с RAG, можете смело пропустить следующий раздел — это просто немного повторяющейся информации об агентах и RAG.
Что такое RAG и Agentic RAG?
Большинство из вас, кто это читает, знают, что такое генерация дополненной информации (RAG), но если вы новичок, то это способ извлечения информации, которая передается в большую языковую модель (LLM) до того, как она ответит на вопрос пользователя.
Это позволяет нам предоставлять боту актуальную информацию из различных документов в режиме реального времени, чтобы он мог правильно ответить пользователю.

Эта поисковая система делает больше, чем просто поиск по ключевым словам, поскольку она находит похожие совпадения, а не только точные. Например, если кто-то спрашивает о шрифтах, поиск по сходству может вернуть документы по типографике.
Многие скажут, что RAG — довольно простая для понимания концепция, но то, как вы храните информацию, как вы ее извлекаете и какие модели встраивания вы используете, по-прежнему имеет большое значение.
Если вам интересно узнать больше о внедрении и извлечении, я писал об этом здесь.
Сегодня люди пошли дальше и работают в основном с агентскими системами.
В агентских системах LLM может решать, где и как ему следует извлекать информацию, а не просто загружать контент в свой контекст перед генерацией ответа.

Важно помнить, что существование более продвинутых инструментов не означает, что вы всегда должны их использовать. Вы хотите сохранить интуитивность системы и свести вызовы API к минимуму.
В агентских системах число вызовов API увеличится, поскольку для генерации ответа необходимо как минимум вызвать один инструмент, а затем сделать еще один вызов.
Тем не менее, мне очень нравится пользовательский опыт бота, который «куда-то идет» — к инструменту — чтобы что-то поискать. Наблюдение за этим потоком в Slack помогает пользователю понять, что происходит.
Но обращение к агенту или использование полного фреймворка не обязательно является лучшим выбором. Я расскажу об этом подробнее по мере продолжения.
Технический стек
Существует множество вариантов фреймворков агентов, векторных баз данных и вариантов развертывания, поэтому я рассмотрю некоторые из них.
Что касается варианта развертывания , поскольку мы работаем с веб-перехватчиками Slack, мы имеем дело с архитектурой, управляемой событиями, где код запускается только при наличии вопроса в Slack.
Чтобы свести затраты к минимуму, мы можем использовать бессерверные функции . Выбор заключается в том, чтобы использовать AWS Lambda или выбрать нового поставщика.

Такие платформы, как Modal, технически созданы для обслуживания моделей LLM, но они хорошо подходят для длительных процессов ETL и для приложений LLM в целом.
Modal не был так тщательно проверен в боевых условиях, и вы заметите это по задержкам, но он очень плавный и предлагает очень низкую цену на процессор.
Однако следует отметить, что при настройке Modal на бесплатном уровне у меня возникло несколько ошибок 500, но это можно было ожидать.
Что касается того, как выбрать агентский фреймворк , это совершенно необязательно. Несколько недель назад я сделал сравнительную статью по агентским фреймворкам с открытым исходным кодом, которую вы можете найти здесь, и я упустил LlamaIndex .
Поэтому я решил попробовать здесь.
Последнее, что вам нужно выбрать, это векторная база данных или база данных, которая поддерживает векторный поиск. Здесь мы храним вложения и другие метаданные, чтобы мы могли выполнять поиск по сходству, когда поступает запрос пользователя.
Существует множество вариантов, но я думаю, что наибольший потенциал имеют Weaviate, Milvus, pgvector, Redis и Qdrant.

У Qdrant и Milvus довольно щедрые бесплатные уровни для своих облачных опций. Qdrant, я знаю, позволяет нам хранить как плотные, так и разреженные векторы. Llamaindex, как и большинство фреймворков агентов, поддерживает множество различных баз данных векторов, так что любая может работать.
В будущем я попробую еще Milvus, чтобы сравнить производительность и задержку, но на данный момент Qdrant работает хорошо.
Redis также является надежным выбором, как и любое векторное расширение вашей существующей базы данных.
Стоимость и время строительства
С точки зрения времени и стоимости вам придется учитывать часы разработки, облако, внедрение и большую языковую модель. (LLM) расходы.
Не так уж много времени требуется, чтобы загрузить фреймворк для запуска чего-то минимального. Время требуется на то, чтобы правильно подключить контент, вызвать систему, проанализировать выходные данные и убедиться, что все работает достаточно быстро.
Но если обратиться к накладным расходам, то затраты на облако для работы агентской системы минимальны для всего лишь одного бота для одной компании, использующей бессерверные функции, как вы видели в таблице в предыдущем разделе.
Однако для векторных баз данных это будет стоить дороже, чем больше данных вы храните.
И Zilliz, и Qdrant Cloud предлагают хороший объем бесплатного уровня для ваших первых 1–5 ГБ данных, поэтому, если вы не превысите объем в несколько тысяч фрагментов, вы, возможно, вообще ни за что не заплатите.

Однако платить вы начнете, как только превысите отметку в несколько тысяч, при этом Weaviate — самый дорогой из перечисленных выше поставщиков.
Что касается встраивания, то оно, как правило, очень дёшево.
Ниже вы можете увидеть таблицу по использованию text-embedding-3-small OpenAI с фрагментами разного размера после внедрения от 1 до 10 миллионов текстов.

Когда люди начинают оптимизировать для встраивания и хранения, они обычно выходят за рамки встраивания миллионов текстов.
Единственное, что имеет наибольшее значение , это то, какую большую языковую модель (LLM) вы используете . Вам нужно подумать о ценах API, поскольку система агентов обычно вызывает LLM два-четыре раза за запуск.

Для этой системы я использую GPT-4o-mini или Gemini Flash 2.0, которые являются самыми дешевыми вариантами.
Допустим, компания использует бота несколько сотен раз в день, и каждый запуск обходится нам в 2–4 вызова API. В итоге мы можем получить менее доллара в день и около 10–50 долларов в месяц.
Вы можете видеть, что переход на более дорогую модель увеличит ежемесячный счет в 10-100 раз. Использование ChatGPT в основном субсидируется для бесплатных пользователей, но когда вы создаете свои собственные приложения, вы будете его финансировать.
В будущем появятся более умные и дешевые модели, поэтому все, что вы построите сейчас, со временем, скорее всего, улучшится. Но начните с малого, потому что затраты накапливаются, и для таких простых систем, как эта, вам не нужно, чтобы они были исключительными.
В следующем разделе мы рассмотрим, как построить эту систему.
Архитектура (обработка документов)
Система состоит из двух частей. Первая — это то, как мы разделяем документы — то, что мы называем фрагментацией — и встраиваем их. Эта первая часть очень важна, так как она будет определять, как агент будет отвечать позже.

Поэтому, чтобы убедиться, что вы правильно подготавливаете все источники, вам нужно тщательно продумать, как их разбить на части.
Если вы посмотрите на документ выше, то увидите, что мы можем упустить контекст, если разделим документ по заголовкам, а также по количеству символов, когда абзацы, присоединенные к первому заголовку, разделены из-за своей длины.

Вам нужно быть умным, чтобы обеспечить каждому фрагменту достаточно контекста (но не слишком много). Вам также нужно убедиться, что фрагмент прикреплен к метаданным, чтобы было легко отследить, где он был найден.

Именно на это вы потратите больше всего времени, и, честно говоря, я думаю, что должны быть более совершенные инструменты, позволяющие делать это разумно.
В итоге я использовал Docling для PDF-файлов, построив его для присоединения элементов на основе заголовков и размеров абзацев. Для веб-страниц я создал краулер, который просматривал элементы страницы, чтобы решить, следует ли разбивать на части на основе якорных тегов, заголовков или общего контента.
Помните, если бот должен ссылаться на источники, каждый фрагмент должен быть прикреплен к URL-адресам, тегам привязки, номерам страниц, идентификаторам блоков, постоянным ссылкам, чтобы система могла правильно находить используемую информацию.
Поскольку большая часть контента, с которым вы работаете, разрозненна и часто низкого качества, я также решил резюмировать тексты с помощью LLM. Этим резюмированиям были присвоены различные метки с более высоким авторитетом, что означало, что они были приоритетными во время поиска.

Также есть возможность вставлять сводки в свои собственные инструменты и хранить информацию о глубоком погружении отдельно. Позволяя агенту решать, какой из них использовать, но это будет выглядеть странно для пользователей, поскольку это не интуитивное поведение.
Тем не менее, я должен подчеркнуть, что если качество исходной информации низкое, то сложно заставить систему работать хорошо.
Например, если пользователь спрашивает, как следует выполнить запрос API, а четыре разные веб-страницы дают разные ответы, бот не будет знать, какая из них наиболее релевантна.
Чтобы продемонстрировать это, мне пришлось провести ручной обзор. Я также заставил ИИ провести более глубокое исследование компании, чтобы помочь заполнить пробелы, а затем я внедрил и это.
В будущем я думаю создать что-то лучшее для приема документов — возможно, с помощью языковой модели.
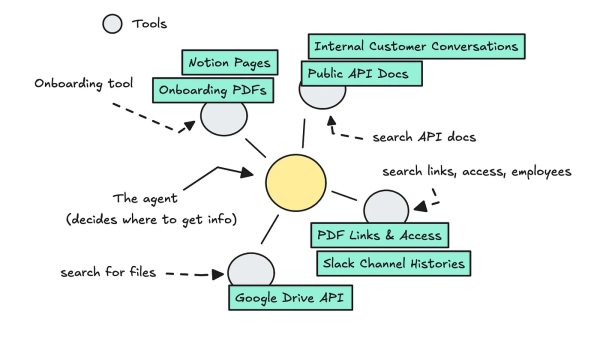
Архитектура (агент)
Для второй части, где мы подключаемся к этим данным, нам необходимо создать систему, в которой агент может подключаться к различным инструментам, содержащим различные объемы данных из нашей векторной базы данных.
Мы придерживаемся только одного агента, чтобы сделать его достаточно простым для контроля. Этот агент может решить, какая информация ему нужна, основываясь на вопросе пользователя.

Лучше не усложнять ситуацию и не использовать слишком много агентов, иначе возникнут проблемы, особенно с этими небольшими моделями.
Хотя это может противоречить моим собственным рекомендациям, я создал первую функцию LLM, которая решает, нужно ли нам вообще запускать агент.

Это было сделано в первую очередь для удобства пользователя, поскольку загрузка агента занимает несколько дополнительных секунд (даже при запуске его в качестве фоновой задачи при запуске контейнера).
Что касается того, как построить самого агента, это просто, так как LlamaIndex делает большую часть работы за нас. Для этого можно использовать FunctionAgent, передавая различные инструменты при его настройке.
# Запускается только в том случае, если первый LLM считает это необходимым access_links_tool = get_access_links_tool() public_docs_tool = get_public_docs_tool() onboarding_tool = get_onboarding_information_tool() general_info_tool = get_general_info_tool() formatted_system_prompt = get_system_prompt(team_name) agent = FunctionAgent( tools=[onboarding_tool, public_docs_tool, access_links_tool, general_info_tool], llm=global_llm, system_prompt=formatted_system_prompt )
Инструменты имеют доступ к различным данным из векторной базы данных, и они являются обертками вокруг CitationQueryEngine. Этот движок помогает цитировать исходные узлы в тексте. Мы можем получить доступ к исходным узлам в конце запуска агента, который вы можете прикрепить к сообщению и в нижнем колонтитуле.
Чтобы обеспечить удобство использования, вы можете подключиться к ленте событий и отправлять обновления обратно в Slack.
обработчик = agent.run(user_msg=full_msg, ctx=ctx, memory=memory) асинхронный для события в handler.stream_events(): if isinstance(event, ToolCall): display_tool_name = format_tool_name(event.tool_name) message = f»✅ Проверка {display_tool_name}» post_thinking(message) if isinstance(event, ToolCallResult): post_thinking(f»✅ Проверка завершена…») final_output = await обработчик final_text = final_output блоки = build_slack_blocks(final_text, mention) post_to_slack(channel_id=channel_id, blocks=blocks, timestamp=initial_message_ts, client=client )
Обязательно правильно форматируйте сообщения и блоки Slack, а также усовершенствуйте системные подсказки для агента, чтобы он правильно форматировал сообщения на основе информации, которую будут возвращать инструменты.
Архитектура должна быть достаточно простой для понимания, но нам все еще следует изучить некоторые методы поиска.
Методы, которые вы можете попробовать
Многие люди будут подчеркивать определенные методы при построении систем RAG, и они частично правы. Вам следует использовать гибридный поиск вместе с каким-то переранжированием.

Первое, о чем я расскажу, — это гибридный поиск, когда мы выполняем извлечение.
Я уже упоминал, что мы используем семантическое сходство для извлечения фрагментов данных в различных инструментах, но необходимо также учитывать случаи, когда требуется точный поиск по ключевым словам.
Представьте себе пользователя, который запрашивает конкретное имя сертификата, например, CAT-00568. В этом случае системе необходимо найти как точные, так и нечеткие совпадения.
При гибридном поиске, поддерживаемом как Qdrant, так и LlamaIndex, мы используем как плотные, так и разреженные векторы.
# при настройке векторного хранилища (как для встраивания, так и для извлечения) vector_store = QdrantVectorStore( client=client, aclient=async_client, collection_name=»knowledge_bases», enable_hybrid=True, fastembed_sparse_model=»Qdrant/bm25″ )
Разреженный поиск отлично подходит для точных ключевых слов, но не учитывает синонимы, тогда как плотный поиск отлично подходит для «нечетких» совпадений («политика льгот» соответствует «льготы для сотрудников»), но он может пропускать буквальные строки, такие как CAT-00568.
После получения результатов полезно применить дедупликацию и повторное ранжирование, чтобы отфильтровать ненужные фрагменты, прежде чем отправлять их в LLM для цитирования и синтеза.
переранжировщик = LLMRerank(llm=OpenAI(model=»gpt-3.5-turbo»), top_n=5) дедупликация = SimilarityPostprocessor(similarity_cutoff=0.9) движок = CitationQueryEngine( извлекатель=извлекатель, node_postprocessors=[дедупликация, переранжировщик], metadata_mode=MetadataMode.ALL, )
Эта часть не была бы нужна, если бы ваши данные были исключительно чистыми, поэтому она не должна быть вашим основным фокусом. Она добавляет накладные расходы и еще один вызов API.
Также не обязательно использовать большую модель для повторного ранжирования, но вам придется провести собственное исследование, чтобы определить свои варианты.
Эти методы просты в понимании и быстро настраиваются, поэтому вам не придется тратить на них большую часть времени.
На что вы на самом деле потратите время
Большинство вещей, на которые вы будете тратить время, не такие уж и крутые. Это подсказки, сокращение задержек и правильная разбивка документов на части.
Прежде чем начать, вам следует изучить различные шаблоны подсказок из разных фреймворков, чтобы увидеть, как они подсказывают модели. Вы потратите немало времени, чтобы убедиться, что системная подсказка хорошо продумана для выбранной вами степени магистра права.
Второе, на что вы потратите большую часть своего времени, — это ускорение . Я изучил внутренние инструменты технологических компаний, создающих агентов знаний ИИ, и обнаружил, что они обычно отвечают примерно через 8–13 секунд.
Итак, вам нужно что-то в этом диапазоне.
Использование провайдера serverless может быть проблемой из-за холодных стартов. Поставщики LLM также вносят свою собственную задержку, которую трудно контролировать.

Тем не менее, вы можете рассмотреть возможность развертывания ресурсов до их использования , перехода на модели с меньшей задержкой , пропуска фреймворков для снижения накладных расходов и в целом уменьшения количества вызовов API за один запуск.
Последнее, что требует огромного объема работы и о чем я уже упоминал ранее, — это разбиение документов на части .
Если у вас исключительно чистые данные с четкими заголовками и разделителями, эта часть будет легкой. Но чаще всего вы будете иметь дело с плохо структурированными HTML, PDF, необработанными текстовыми файлами, досками Notion и заметками Confluence — часто разбросанными и отформатированными непоследовательно.
Задача состоит в том, чтобы выяснить, как программно обработать эти документы, чтобы система получила полную информацию, необходимую для ответа на вопрос.
Например, при работе с PDF-файлами вам потребуется правильно извлекать таблицы и изображения, разделять разделы по номерам страниц или элементам макета и отслеживать каждый источник до нужной страницы.
Вам нужно достаточно контекста, но не слишком большие фрагменты, иначе впоследствии будет сложнее извлечь нужную информацию.
Такие вещи не очень хорошо обобщаются. Вы не можете просто впихнуть это и ожидать, что система поймет это — вы должны продумать это, прежде чем создавать.
Как его развивать дальше
На данный момент он хорошо справляется со своими задачами, но есть несколько моментов, которые я должен осветить (иначе люди подумают, что я слишком упрощаю). Вам нужно будет реализовать кэширование, способ обновления данных и долговременную память.
Кэширование не является обязательным, но вы можете по крайней мере кэшировать встраивание запроса в более крупные системы, чтобы ускорить извлечение и сохранить последние исходные результаты для последующих вопросов. Я не думаю, что LlamaIndex здесь сильно поможет, но вы должны быть в состоянии перехватить QueryTool самостоятельно.
Вам также понадобится способ непрерывного обновления информации в векторных базах данных. Это самая большая головная боль — трудно узнать, когда что-то изменилось, поэтому вам нужен какой-то метод обнаружения изменений вместе с идентификатором для каждого фрагмента.
Вы можете просто использовать стратегии периодического повторного встраивания, при которых вы обновляете фрагмент с помощью других метатегов (это мой предпочтительный подход, потому что я ленивый).
Последнее, о чем я хочу упомянуть, — это долговременная память для агента, чтобы он мог понимать ваши прошлые разговоры. Для этого я реализовал некоторое состояние, извлекая историю из API Slack. Это позволяет агенту видеть около 3–6 предыдущих сообщений при ответе.
Мы не хотим вставлять слишком много истории, поскольку при этом увеличивается контекстное окно, что не только увеличивает стоимость, но и может запутать агента.
Тем не менее, есть лучшие способы управления долговременной памятью с использованием внешних инструментов. Я с удовольствием напишу об этом подробнее в будущем.
Уроки и т.д.
Поработав так некоторое время, я хочу поделиться несколькими заметками о работе с фреймворками и о том, как их упростить (лично я не всегда им следую).
Вы многому учитесь, используя фреймворк, особенно тому, как правильно подсказывать и как структурировать код. Но в какой-то момент работа в обход фреймворка добавляет накладные расходы.
Например, в этой системе я немного обхожу фреймворк, добавляя начальный вызов API, который решает, следует ли переходить к агенту, и быстро отвечает пользователю.
Если бы я создавал это без фреймворка, я думаю, я бы лучше справился с такой логикой, когда первая модель сразу решает, какой инструмент вызвать.

Я не пробовал, но предполагаю, что так будет чище.
Кроме того, LlamaIndex оптимизирует пользовательский запрос, как и положено, перед извлечением.
Но иногда это слишком сильно сокращает запрос, и мне нужно зайти и исправить это. Синтезатор цитат не имеет доступа к истории разговоров, поэтому с этим чрезмерно упрощенным запросом он не всегда отвечает хорошо.

При использовании фреймворка также сложно отследить, откуда в рабочем процессе возникают задержки, поскольку не всегда можно увидеть все, даже с помощью инструментов наблюдения.
Большинство разработчиков рекомендуют использовать фреймворки для быстрого прототипирования или начальной загрузки, а затем переписывать основную логику с помощью прямых вызовов в продакшне.
Это не потому, что фреймворки бесполезны, а потому, что в какой-то момент лучше написать что-то, что вы полностью понимаете и что делает только то, что вам нужно.
Общая рекомендация — максимально упрощать все и сводить к минимуму требования LLM (чего я сам здесь в полной мере не делаю).
Но если вам нужен только RAG, а не агент, то придерживайтесь этого варианта.
Вы можете создать простой вызов LLM, который устанавливает правильные параметры в векторной базе данных. С точки зрения пользователя это все равно будет выглядеть так, как будто система «смотрит в базу данных» и возвращает соответствующую информацию.
Если вы идете по тому же пути, надеюсь, эта статья была вам полезна.
Но есть еще кое-что. Вам нужно будет реализовать какую-то оценку, ограждения и мониторинг (я использовал Phoenix здесь).
Однако по завершении результат будет выглядеть так:

Если вы следите за моими публикациями, вы можете найти меня здесь, на моем сайте или на LinkedIn.
Летом я постараюсь глубже погрузиться в агентную память, оценки и подсказки.
❤
Источник: towardsdatascience.com

























