Анализ и оптимизация производительности модели PyTorch — Часть 11
Делиться

Это одиннадцатая часть серии публикаций, посвящённой анализу и оптимизации моделей PyTorch. На протяжении всей серии мы выступали за использование PyTorch Profiler при разработке моделей ИИ и демонстрировали потенциальное влияние оптимизации производительности на скорость и стоимость выполнения рабочих нагрузок ИИ/МО. Одним из распространённых явлений, которые мы наблюдали, является то, как, казалось бы, безобидный код может снижать производительность во время выполнения. В этой публикации мы рассмотрим некоторые недостатки, связанные с наивным использованием тензоров переменной формы — тензоров, форма которых зависит от предыдущих вычислений и/или входных данных. Хотя это применимо не во всех ситуациях, существуют случаи, когда использования тензоров переменной формы можно избежать, хотя это может привести к дополнительным вычислительным ресурсам и/или объёму памяти. Мы продемонстрируем компромиссы этих альтернатив на примере тестовой реализации выборки данных в PyTorch.
Три недостатка тензоров переменной формы
Мы мотивируем обсуждение, представив три недостатка использования тензоров переменной формы:
События синхронизации хост-устройства
В идеальном сценарии центральный процессор (ЦП) и графический процессор (ГП) могут работать параллельно в асинхронном режиме: ЦП непрерывно подает на ГП входные данные, выделяет необходимую память ГП и загружает вычислительные ядра ГП, а ГП выполняет загруженные ядра на предоставленных входных данных, используя выделенную память. Наличие динамически формируемых тензоров затрудняет этот параллелизм. Чтобы выделить необходимый объем памяти, ЦП должен дождаться, пока ГП сообщит форму тензора, а затем ГП должен дождаться, пока ЦП выделит память и продолжит загрузку ядра. Накладные расходы, связанные с этим событием синхронизации, могут привести к снижению использования ГП и снижению производительности выполнения.
Мы видели пример этого в третьей части этой серии, когда изучали наивную реализацию распространённой функции потери кросс-энтропии, включающую вызовы torch.nonzero и torch.unique. Оба API возвращают тензоры с динамической формой, зависящей от содержимого входных данных. При запуске этих функций на графическом процессоре происходит событие синхронизации хост-устройства. В случае потери кросс-энтропии мы обнаружили неэффективность с помощью PyTorch Profiler и смогли легко преодолеть её с помощью альтернативной реализации, которая избегала использования тензоров переменной формы и демонстрировала значительно более высокую производительность выполнения.
Составление графика
В недавней публикации мы исследовали преимущества JIT-компиляции с помощью оператора torch.compile в плане производительности. Одним из наших наблюдений стало то, что компиляция графа давала гораздо лучшие результаты, когда граф был статичным. Наличие динамических фигур в графе ограничивает масштаб оптимизации посредством компиляции: в некоторых случаях она полностью не работает, в других — приводит к меньшему приросту производительности. Аналогичные выводы применимы и к другим формам компиляции графа, таким как XLA, ONNX, OpenVINO и TensorRT.
Пакетирование данных
Ещё один способ оптимизации, с которым мы столкнулись в нескольких наших публикациях (например, здесь), — это пакетирование выборок. Пакетирование повышает производительность двумя основными способами:
- Сокращение накладных расходов на загрузку ядра : вместо того, чтобы загружать ядра графического процессора, необходимые для конвейера вычислений, один раз для каждого входного образца, центральный процессор может загружать ядра один раз для каждого пакета.
- Максимизация распараллеливания вычислительных блоков : графические процессоры — это высокопараллельные вычислительные машины. Чем больше мы способны распараллеливать вычисления, тем выше загрузка графического процессора и его использование. Пакетирование потенциально может увеличить степень распараллеливания в разы, пропорционально размеру пакета.
Несмотря на недостатки, использование тензоров переменной формы часто неизбежно. Но иногда мы можем модифицировать реализацию нашей модели, чтобы обойти их. Иногда эти изменения будут простыми (как в примере с кросс-энтропийными потерями). В других случаях может потребоваться изобретательность для создания другой последовательности API PyTorch фиксированной формы, обеспечивающих тот же числовой результат. Зачастую эти усилия могут дать существенные преимущества с точки зрения времени выполнения и стоимости.
В следующих разделах мы рассмотрим использование тензоров переменной формы в контексте операции выборки данных. Начнём с тривиальной реализации и проанализируем её производительность. Затем предложим альтернативу, оптимизированную для GPU и позволяющую избежать использования тензоров переменной формы.
Для сравнения наших реализаций мы будем использовать Amazon EC2 g6e.xlarge с NVIDIA L40S, работающим под управлением AWS Deep Learning AMI (DLAMI) с PyTorch (2.8). Код, которым мы поделимся, предназначен для демонстрационных целей. Пожалуйста, не полагайтесь на его точность или оптимальность. Пожалуйста, не воспринимайте упоминание нами какого-либо фреймворка, библиотеки или платформы как одобрение их использования.
Выборка в рабочих нагрузках модели ИИ
В контексте данной публикации выборка означает выбор подмножества элементов из большого набора кандидатов в целях повышения вычислительной эффективности, балансировки типов данных или регуляризации. Выборка широко распространена во многих моделях искусственного интеллекта и машинного обучения, таких как системы обнаружения, ранжирования и контрастного обучения.
Мы определяем простую вариацию задачи выборки: дан список из N тензоров, каждый из которых имеет бинарную метку. Нам предлагается вернуть подмножество из K тензоров, содержащее как положительные, так и отрицательные примеры, расположенные в случайном порядке. Если входной список содержит достаточное количество образцов каждой метки (K/2), возвращаемое подмножество должно быть разделено поровну. Если в нём отсутствуют образцы одного типа, их следует заполнить случайными образцами второго типа.
Блок кода ниже содержит реализацию нашей функции выборки на PyTorch. Реализация вдохновлена популярной библиотекой Detectron2 (см., например, здесь и здесь). Для экспериментов в этой статье мы установим соотношение выборки 1:10.
import torch INPUT_SAMPLES = 10000 SUB_SAMPLE = INPUT_SAMPLES // 10 FEATURE_DIM = 16 def sample_data(input_array, labels): device = labels.device positive = torch.nonzero(labels == 1, as_tuple=True)[0] negative = torch.nonzero(labels == 0, as_tuple=True)[0] num_pos = min(positive.numel(), SUB_SAMPLE//2) num_neg = min(negative.numel(), SUB_SAMPLE//2) if num_neg < SUB_SAMPLE//2: num_pos = SUB_SAMPLE - num_neg elif num_pos < SUB_SAMPLE//2: num_neg = SUB_SAMPLE - num_pos # случайным образом выбрать положительные и отрицательные примеры perm1 = torch.randperm(положительный.numel(), устройство=устройство)[:num_pos] perm2 = torch.randperm(отрицательный.numel(), устройство=устройство)[:num_neg] pos_idxs = положительный[perm1] neg_idxs = отрицательный[perm2] sampled_idxs = torch.cat([pos_idxs, neg_idxs], dim=0) rand_perm = torch.randperm(SUB_SAMPLE, устройство=метки.устройство) sampled_idxs = sampled_idxs[rand_perm] return input_array[sampled_idxs], labels[sampled_idxs]
Анализ производительности с помощью PyTorch Profiler
Даже если это не очевидно, использование динамических фигур легко распознаётся в окне трассировки PyTorch Profiler. Для включения PyTorch Profiler мы используем следующую функцию:
def profile(fn, input, labels): def export_trace(p): p.export_chrome_trace(f»{fn.__name__}.json») with torch.profiler.profile( Activities=[torch.profiler.ProfilerActivity.CPU, torch.profiler.ProfilerActivity.CUDA], with_stack=True, schedule=torch.profiler.schedule(wait=0, warmup=10, active=5), on_trace_ready=export_trace ) as prof: for _ in range(20): fn(input, labels) torch.cuda.synchronize() # явная синхронизация для читаемости трассировки prof.step() # создание случайных входных данных input_samples = torch.randn((INPUT_SAMPLES, FEATURE_DIM), device='cuda') labels = torch.randint(0, 2, (INPUT_SAMPLES,), device='cuda', dtype=torch.int64) # запуск с профайлером profile(sample_data, input_samples, labels)
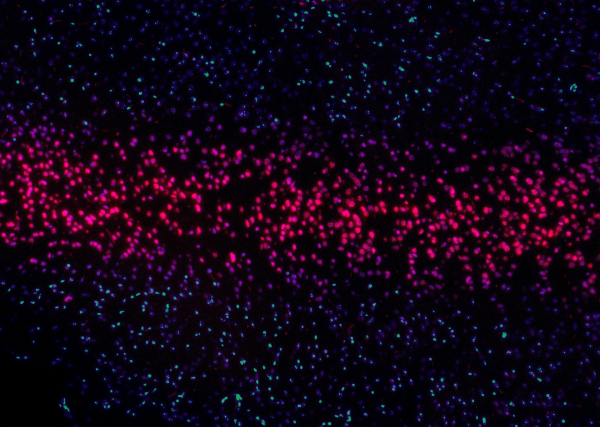
Изображение ниже было получено для десяти миллионов входных сэмплов. На нём отчётливо видно наличие событий синхронизации, возникающих при вызове torch.nonzero, а также соответствующее снижение загрузки графического процессора:

Использование torch.nonzero в нашей реализации не идеально, но можно ли его избежать?
Удобный для GPU сэмплер данных
Мы предлагаем альтернативную реализацию нашей функции выборки, которая заменяет динамическую функцию torch.nonzero креативной комбинацией статической функции torch.count_nonzero, torch.topk и других API:
def opt_sample_data(input, labels): pos_mask = labels == 1 neg_mask = labels == 0 num_pos_idxs = torch.count_nonzero(pos_mask, dim=-1) num_neg_idxs = torch.count_nonzero(neg_mask, dim=-1) half_samples = labels.new_full((), SUB_SAMPLE // 2) num_pos = torch.minimum(num_pos_idxs, half_samples) num_neg = torch.minimum(num_neg_idxs, half_samples) num_pos = torch.where( num_neg < SUB_SAMPLE // 2, SUB_SAMPLE - num_neg, num_pos ) num_neg = SUB_SAMPLE - num_pos # создать случайный порядок для положительных и отрицательных записей rand = torch.rand_like(labels, dtype=torch.float32) pos_rand = torch.where(pos_mask, rand, -1) neg_rand = torch.where(neg_mask, rand, -1) # выбрать верхние позиции и сделать остальные недействительными # поскольку процессор не знает num_pos, мы предполагаем максимум, чтобы избежать синхронизации top_pos_rand, top_pos_idx = torch.topk(pos_rand, k=SUB_SAMPLE) arange = torch.arange(SUB_SAMPLE, device=labels.device) если num_pos.numel() > 1: # распаковать для поддержки пакетного ввода arange = arange.unsqueeze(0) num_pos = num_pos.unsqueeze(-1) num_neg = num_neg.unsqueeze(-1) top_pos_rand = torch.where(arange >= num_pos, -1, top_pos_rand) # повторить для отрицательных записей top_neg_rand, top_neg_idx = torch.topk(neg_rand, k=SUB_SAMPLE) top_neg_rand = torch.where(arange >= num_neg, -1, top_neg_rand) # объединить и смешать вместе положительные и отрицательные idx cat_rand = torch.cat([top_pos_rand, top_neg_rand], dim=-1) cat_idx = torch.cat([top_pos_idx, top_neg_idx], dim=-1) topk_rand_idx = torch.topk(cat_rand, k=SUB_SAMPLE)[1] sampled_idxs = torch.gather(cat_idx, dim=-1, index=topk_rand_idx) sampled_input = torch.gather(input, dim=-2, индекс = sampled_idxs. расжать (-1)) sampled_labels = torch. собрать (метки, размер = -1, индекс = sampled_idxs) вернуть sampled_input, sampled_labels
Очевидно, что эта функция требует больше памяти и операций, чем наша первая реализация. Вопрос в следующем: перевешивают ли преимущества статической реализации без синхронизации дополнительные затраты памяти и вычислительных ресурсов?
Для оценки компромиссов между двумя реализациями мы представляем следующую утилиту для сравнительного анализа:
def benchmark(fn, input, labels): # разминка for _ in range(20): _ = fn(input, labels) iters = 100 start = torch.cuda.Event(enable_timing=True) end = torch.cuda.Event(enable_timing=True) torch.cuda.synchronize() start.record() for _ in range(iters): _ = fn(input, labels) end.record() torch.cuda.synchronize() avg_time = start.elapsed_time(end) / iters print(f»{fn.__name__} среднее время шага: {(avg_time):.4f} мс») benchmark(sample_data, input_samples, labels) benchmark(opt_sample_data, input_samples, labels)
В следующей таблице сравнивается среднее время выполнения каждой из реализаций для различных размеров входной выборки:

Для большинства размеров входной выборки накладные расходы на синхронизацию хоста и устройства либо сопоставимы, либо ниже, чем дополнительные вычислительные ресурсы статической реализации. К сожалению, мы видим существенное преимущество безсинхронизационной альтернативы только при размере входной выборки, достигающем десяти миллионов. Такие большие размеры выборки редко встречаются в системах искусственного интеллекта/машинного обучения. Но мы не склонны так легко сдаваться. Как отмечалось выше, статическая реализация позволяет оптимизировать другие параметры, такие как компиляция графа и пакетная обработка входных данных.
Составление графика
В отличие от исходной функции, которая не компилируется, наша статическая реализация полностью совместима с torch.compile:
бенчмарк(torch.compile(opt_sample_data), input_samples, labels)
В следующей таблице приведены времена выполнения нашей скомпилированной функции:

Результаты значительно лучше — прирост производительности по сравнению с исходной реализацией сэмплера в диапазоне от 1 до 10 тысяч составляет 70–75%. Но у нас в запасе есть ещё один вариант оптимизации.
Максимизация производительности с помощью пакетного ввода
Поскольку исходная реализация содержит операции с переменной формой, она не может обрабатывать пакетные входные данные напрямую. Чтобы обработать пакет, нам остаётся только применять его к каждому входному потоку по отдельности в цикле Python:
BATCH_SIZE = 32 def batched_sample_data(входные данные, метки): sampled_inputs = [] sampled_labels = [] for i in range(inputs.size(0)): inp, lab = sample_data(входные данные[i], метки[i]) sampled_inputs.append(входные данные) sampled_labels.append(лаборатория) return torch.stack(сэмплированные_входные данные), torch.stack(сэмплированные_метки)
Напротив, наша оптимизированная функция поддерживает пакетные входные данные как есть — никаких изменений не требуется.
input_batch = torch.randn((BATCH_SIZE, INPUT_SAMPLES, FEATURE_DIM), device='cuda') labels = torch.randint(0, 2, (BATCH_SIZE, INPUT_SAMPLES), device='cuda', dtype=torch.int64) benchmark(batched_sample_data, input_batch, labels) benchmark(opt_sample_data, input_batch, labels) benchmark(torch.compile(opt_sample_data), input_batch, labels)
В таблице ниже сравнивается время выполнения шагов наших функций выборки для партии размером 32:

Теперь результаты окончательны: используя статическую реализацию выборки данных, мы можем повысить производительность в 2–52 раза (!!) по сравнению с вариантом переменной формы, в зависимости от размера входной выборки.
Обратите внимание, что, хотя наши эксперименты проводились на графическом процессоре, компиляция модели и оптимизация пакетирования входных данных также применимы к среде центрального процессора. Таким образом, исключение переменных форм может повлиять на производительность моделей ИИ/МО и на центральном процессоре.
Краткое содержание
Процесс оптимизации, продемонстрированный нами в этой статье, выходит за рамки конкретного случая выборки данных:
- Обнаружение с помощью профилирования производительности: с помощью PyTorch Profiler нам удалось выявить падения в использовании графического процессора и обнаружить их источник: наличие тензоров переменной формы, возникающих в результате операции torch.nonzero.
- Альтернативная реализация: Результаты профилирования позволили нам разработать альтернативную реализацию, которая достигла той же цели, избежав использования тензоров переменной формы. Однако этот шаг был достигнут за счёт дополнительных вычислительных затрат и затрат памяти. Как показали наши первоначальные тесты, альтернатива без синхронизации продемонстрировала худшую производительность на входных данных стандартных размеров.
- Раскрытие дальнейшего потенциала оптимизации: настоящий прорыв произошел благодаря тому, что реализация со статическим шейпом была удобной для компиляции и поддерживала пакетную обработку. Эти оптимизации обеспечили прирост производительности, значительно превзошедший первоначальные накладные расходы, что привело к ускорению в 2–52 раза по сравнению с исходной реализацией.
Конечно, не все истории заканчиваются так же благополучно, как наша. Во многих случаях мы можем столкнуться с кодом PyTorch, который плохо работает на GPU, но не имеет альтернативной реализации, или же у него может быть реализация, требующая значительно больше вычислительных ресурсов. Однако, учитывая потенциал значительного повышения производительности и снижения стоимости, процесс выявления неэффективности выполнения и исследования альтернативных реализаций является неотъемлемой частью разработки ИИ/МО.
Источник: towardsdatascience.com