воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Мы представляем новый алгоритм генерации синтетических данных, обеспечивающий сохранение конфиденциальности и позволяющий автоматически сопоставлять распределения по темам, что делает его доступным даже для приложений искусственного интеллекта с ограниченными ресурсами.
Быстрые ссылки
- Бумага
- Делиться
Создание крупномасштабных синтетических данных с дифференциальной приватностью (DP) представляет собой сложную задачу из-за фундаментального компромисса между приватностью, вычислительными ресурсами и полезностью, где надежные гарантии приватности могут либо ухудшить качество синтетических данных, либо потребовать больших вычислительных затрат. Популярным решением является приватная тонкая настройка большой языковой модели (LLM) размером в миллиард символов на «приватных данных» (стандартный термин, обозначающий набор данных, для которого планируется предоставлять гарантии приватности), а затем выборка из тонкой модели для генерации синтетических данных. Этот подход является вычислительно затратным и, следовательно, недоступен для приложений с ограниченными ресурсами. Поэтому недавно предложенные алгоритмы Aug-PE и Pre-Text исследовали возможность генерации синтетических данных, требующих только доступа к API LLM. Однако они обычно сильно зависят от ручных запросов для генерации исходного набора данных и неэффективны в использовании приватной информации в своем итеративном процессе выбора данных.
В докладе «Синтез текстовых данных с сохранением конфиденциальности посредством тонкой настройки без тонкой настройки многомиллиардных LLM-моделей», представленном на ICML 2025, мы предлагаем CTCL (Data Synthesis with ConTrollability and CLustering) — новую структуру для генерации синтетических данных с сохранением конфиденциальности без тонкой настройки многомиллиардных LLM-моделей или проектирования подсказок, специфичных для конкретной предметной области. CTCL использует облегченную модель с 140 миллионами параметров, что делает ее практичной для приложений с ограниченными ресурсами. Благодаря обусловливанию на основе информации о теме, сгенерированные синтетические данные могут соответствовать распределению тем из закрытой предметной области. Наконец, в отличие от алгоритма Aug-PE, CTCL позволяет генерировать неограниченное количество образцов синтетических данных без дополнительных затрат на обеспечение конфиденциальности. Мы оценили CTCL на различных наборах данных, продемонстрировав, что он неизменно превосходит базовые модели, особенно при наличии строгих гарантий конфиденциальности. Исследования методом абляции подтвердили решающее влияние предварительного обучения и обусловливания на основе ключевых слов, а эксперименты также показали улучшенную масштабируемость CTCL по сравнению с алгоритмом Aug-PE.
Создание структуры для синтеза данных
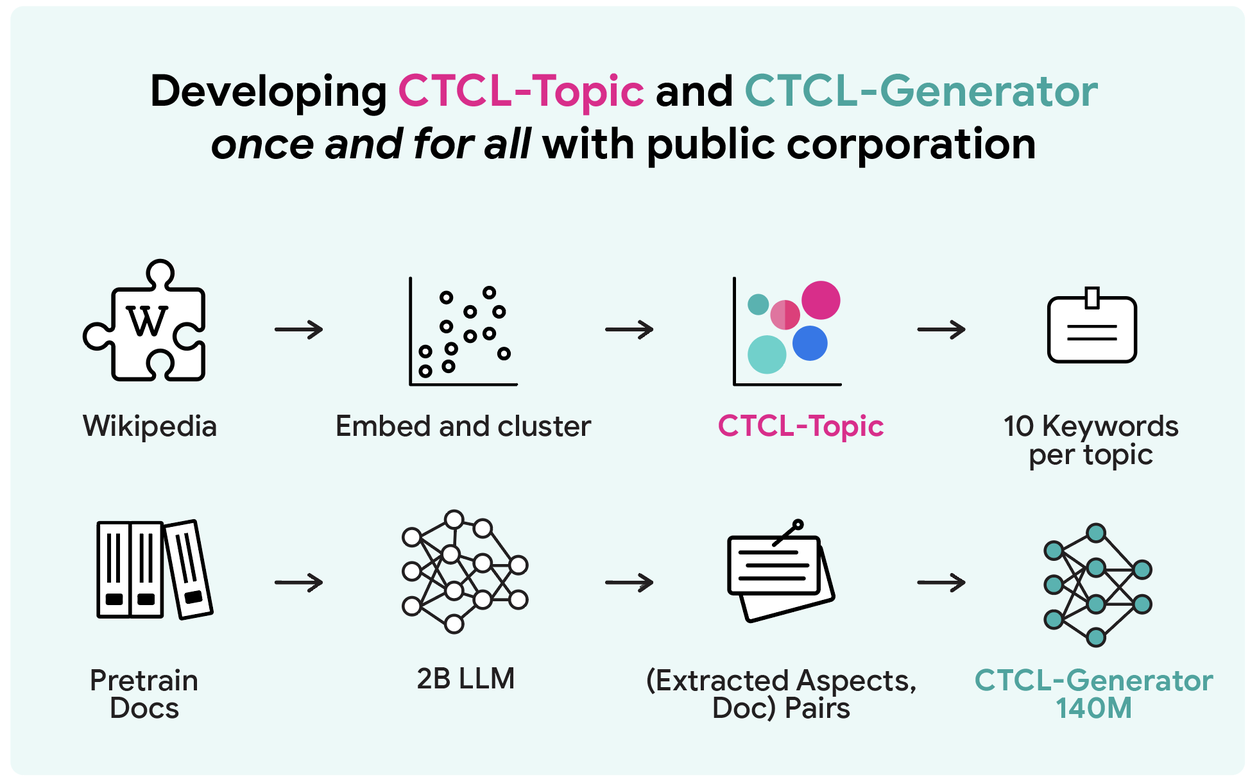
Фреймворк CTCL предназначен для генерации высококачественных синтетических данных из закрытых наборов данных с сохранением конфиденциальности. Это достигается за счет разделения процесса на три основных этапа. Прежде чем углубиться в детали, важно понять два основных компонента, обеспечивающих работу этого фреймворка: CTCL-Topic и CTCL-Generator. CTCL-Topic — это универсальная тематическая модель, которая отражает основные темы набора данных, а CTCL-Generator — это мощная языковая модель, способная создавать документы на основе конкретных ключевых слов. Эти два компонента, разработанные с использованием больших общедоступных корпусов, являются основой для изучения различных закрытых доменов и генерации синтетических данных на их основе.
Шаг 1: Разработка темы CTCL и генератора CTCL.
Оба компонента разрабатываются только один раз с использованием крупномасштабных общедоступных корпусов и могут быть использованы позже для обучения в различных частных областях. CTCL-Topic — это тематическая модель, извлеченная из Википедии, разнообразного корпуса, содержащего около 6 миллионов документов. Мы используем BERTopic для встраивания каждого документа, кластеризации их примерно в 1000 кластеров (т.е. 1000 тем) и представления каждого кластера 10 ключевыми словами.
CTCL-Generator — это облегченная (140 миллионов параметров) условная языковая модель, которая принимает в качестве входных данных описания документов в свободной форме (например, тип документа, ключевые слова и т. д.) и генерирует документы, удовлетворяющие входным условиям. Для создания данных для предварительного обучения для каждого документа в SlimPajama мы задаем Gemma-2-2B команду «Опишите документ с разных сторон». В результате получается набор данных, содержащий 430 миллионов пар «описание-документ». Затем мы используем этот набор данных для непрерывного предварительного обучения на основе BART-base (языковой модели с 140 миллионами параметров), в результате чего получаем CTCL-Generator.

Шаг 1: С использованием крупномасштабных общедоступных корпусов данных разработаны универсальная тематическая модель CTCL-Topic и облегченный генератор CTCL-Generator с 140 миллионами параметров, обладающий высокой степенью управляемости.
Шаг 2: Изучение частной области
Затем мы используем CTCL-Topic для сбора высокоуровневой информации о распределении данных по всему частному корпусу. Это делается путем построения частной гистограммы, представляющей распределение данных по темам, то есть процентное содержание каждой темы в частных данных. Эта тематическая гистограмма будет использована позже на шаге 3 для выборки.
При сборе тематической гистограммы каждому документу в частном наборе данных была присвоена определенная тема. Затем мы преобразуем частный набор данных в набор данных пар ключевых слов и документов; 10 ключевых слов для каждого документа получены из соответствующей темы в CTCL-Topic. После этого мы дорабатываем CTCL-Generator с помощью динамического программирования на этом наборе данных.

Шаг 2: Чтобы изучить частный домен, мы собираем гистограмму тем DP из частных данных и дорабатываем CTCL-Generator с использованием DP на этих частных данных.
Шаг 3: Создание синтетических данных
Генератор CTCL, оптимизированный для DP, пропорционально отбирает данные для каждой темы в соответствии с гистограммой тем DP. В частности, зная желаемый размер синтетического набора данных (например, N ) и гистограмму тем DP (например, x % для темы 1, y % для темы 2 и т. д.), мы знаем количество целевых выборок для каждой темы (т. е., x %*N для темы 1, y %* N для темы 2 и т. д.). Для каждой темы мы используем соответствующие 10 ключевых слов в качестве входных данных для оптимизированного для DP генератора CTCL для генерации данных. Генератор CTCL может генерировать произвольное количество синтетических данных без дополнительных затрат на обеспечение конфиденциальности, благодаря свойству постобработки DP.

Шаг 3: На основе тематической гистограммы DP и оптимизированного с помощью DP генератора CTCL генерируются синтетические данные, обеспечивающие конфиденциальность.
Эксперименты
Мы провели эксперименты на четырех наборах данных, три из которых соответствуют задачам генерации, а один — задаче классификации. Задачи генерации, как правило, сложнее задач классификации. Это связано с тем, что в задачах генерации точность прогнозирования следующего токена оценивается, что требует от синтетических данных сохранения детальной текстовой информации из исходных данных. В отличие от этого, задачи классификации требуют лишь сохранения закономерностей совместной встречаемости меток и слов в исходных данных.
Для описания трех задач генерации были выбраны три варианта, охватывающие разнообразные практические сценарии: PubMed (аннотации медицинских статей), Chatbot Arena (взаимодействие человека с машиной) и Multi-Session Chat (повседневные диалоги между людьми). Для оценки качества сгенерированных синтетических данных мы использовали алгоритм Aug-PE для обучения небольшой языковой модели на синтетических данных, а затем вычислили точность прогнозирования следующего токена на реальных тестовых данных.
Задача классификации выполняется на наборе данных OpenReview (обзоры научных статей). Для оценки качества сгенерированных синтетических данных мы обучаем последующий классификатор на этих синтетических данных и вычисляем точность классификации на реальных тестовых данных.
Чтобы развеять опасения по поводу искажения данных, мы тщательно проанализировали выбранные нами наборы данных. Наш анализ показал отсутствие совпадений между данными, полученными до обучения, и последующими наборами данных.
Результаты
CTCL неизменно превосходит другие базовые алгоритмы, особенно в условиях строгой гарантии конфиденциальности. На графике ниже сравниваются CTCL и следующие базовые алгоритмы: Downstream DPFT (т.е., прямая тонкая настройка модели DP на основе закрытых данных без использования синтетических данных), Aug-PE (расширенная версия алгоритма Private Evolution), тонкая настройка модели LLM аналогичного размера, что и CTCL, с последующей перевыборкой после генерации. График ниже иллюстрирует улучшенную производительность CTCL, особенно в более сложных условиях, удовлетворяющих более строгой гарантии конфиденциальности (т.е., меньшее значение ε ). Это демонстрирует высокую способность CTCL эффективно извлекать полезную информацию из закрытых данных, сохраняя при этом конфиденциальность.

CTCL демонстрирует улучшенные показатели по сравнению с другими базовыми моделями на всех четырех наборах данных, особенно в сложном режиме с более надежными гарантиями конфиденциальности (что подтверждается меньшим значением ε).
Кроме того, по сравнению с Aug-PE, CTCL обладает лучшей масштабируемостью как с точки зрения бюджета конфиденциальности, так и размера синтетических данных. Как показано на левом графике ниже, CTCL улучшается с увеличением бюджета конфиденциальности, в то время как Aug-PE этого не делает. Это ограничение может быть связано с ограниченной способностью Aug-PE (т.е., только через ближайших соседей) эффективно собирать информацию из конфиденциальных данных. На правом графике показано, что точность увеличивается по мере того, как модель получает доступ к большему количеству сгенерированных CTCL образцов, в то время как производительность Aug-PE насыщается примерно при 10 000 примерах. Эти результаты согласуются с интуицией, согласно которой методы, основанные на тонкой настройке (например, CTCL), могут лучше собирать детальную статистику, чем методы, основанные на подсказках (например, Aug-PE).

CTCL обладает лучшей масштабируемостью, чем Aug-PE, с точки зрения бюджета конфиденциальности ( слева ) и продолжает улучшаться по мере обучения последующих задач на большем количестве синтетических данных ( справа ).
И наконец, исследования методом абляции подтверждают важность двух ключевых компонентов в нашей структуре: 1) предварительное обучение CTCL-Generator на общедоступном корпусе и 2) включение условий на основе ключевых слов в процессе тонкой настройки DP. В частности, начиная со стандартной тонкой настройки DP, мы последовательно вводим эти компоненты и измеряем потери на тестовом наборе данных модели. При фиксированном бюджете конфиденциальности наши результаты показывают, что включение ключевых слов в процессе тонкой настройки DP снижает потери на тестовом наборе данных на 50%, а добавление предварительного обучения дает еще 50% снижение. Это демонстрирует, что оба компонента имеют решающее значение в нашей конструкции.
Дальнейшая работа
В наших экспериментах по синтезу данных с использованием алгоритмов ConTrollability и CLustering (CTCL) применяется генератор всего со 140 миллионами параметров. Однако ключевая идея CTCL, а именно использование информации о кластеризации или метаданных, извлеченных из LLM, в качестве входных инструкций, может быть легко распространена на модели большего размера. Мы активно работаем над изучением этой идеи, чтобы помочь улучшить реальные приложения.
Благодарности
Эта работа была выполнена главным образом Боуэном Таном во время его стажировки в Google Research под руководством Шаньшань У и Чжэн Сюй. Мы благодарим Дэниела Рамаджа и Брендана Макмахана за поддержку в руководстве, внешних академических партнеров Эрика Синга и Чжитина Ху за полезные отзывы о статье ICML, Закари Гарретта и Майкла Райли за рецензирование раннего черновика, Тейлора Монтгомери за проверку использования набора данных, Марка Симборга и Кимберли Шведе за помощь в редактировании сообщения в блоге и графики. Мы благодарны рецензентам ICML за их ценное время и содержательные комментарии к нашей статье.
Источник: research.google