Предназначено для профессиональной работы
Сегодня мы выпускаем GPT-5.4 в ChatGPT (под названием GPT-5.4 Thinking), API и Codex. Это наша самая функциональная и эффективная модель для профессиональной работы. Мы также выпускаем GPT-5.4 Pro в ChatGPT и API для тех, кто хочет добиться максимальной производительности при решении сложных задач.
GPT-5.4 объединяет лучшие из наших последних достижений в области логического мышления, программирования и агентных рабочих процессов в единую передовую модель. Она включает в себя лучшие в отрасли возможности программирования GPT-5.3-Codex , одновременно улучшая работу модели с различными инструментами, программными средами и профессиональными задачами, связанными с электронными таблицами, презентациями и документами. В результате получается модель, которая позволяет точно, эффективно и результативно выполнять сложную реальную работу, предоставляя то, что вы запрашивали, с меньшим количеством переписок.
В ChatGPT функция GPT-5.4 Thinking теперь может заранее предлагать план своих действий, позволяя корректировать ход ответа в процессе работы и получать конечный результат, более точно соответствующий вашим потребностям, без дополнительных ходов. GPT-5.4 Thinking также улучшает поиск информации в глубокой сети, особенно для узкоспециализированных запросов, и лучше сохраняет контекст для вопросов, требующих более длительного обдумывания. В совокупности эти улучшения означают более качественные ответы, которые поступают быстрее и остаются актуальными для поставленной задачи.
В Codex и API GPT-5.4 — это первая универсальная модель, которую мы выпустили с собственными, передовыми возможностями использования компьютеров , позволяющая агентам управлять компьютерами и выполнять сложные рабочие процессы в различных приложениях. Она поддерживает до 1 миллиона контекстных токенов , позволяя агентам планировать, выполнять и проверять задачи в долгосрочной перспективе. GPT-5.4 также улучшает работу моделей в больших экосистемах инструментов и коннекторов благодаря поиску инструментов , помогая агентам более эффективно находить и использовать нужные инструменты без ущерба для интеллекта. Наконец, GPT-5.4 — это наша самая эффективная с точки зрения использования токенов модель рассуждений , использующая значительно меньше токенов для решения задач по сравнению с GPT-5.2, что приводит к сокращению использования токенов и повышению скорости.
Вместе с достижениями в области общего логического мышления, программирования и профессиональных знаний, GPT-5.4 обеспечивает более надежных агентов, ускорение рабочих процессов разработчиков и более высокое качество результатов в ChatGPT, API и Codex.
ГПТ-5.4 | GPT-5.3-Кодекс | ГПТ-5.2 | |
ВВПval (победы или ничьи) | 83,0% | 70,9% | 70,9% |
SWE-Bench Pro (публичная версия) | 57,7% | 56,8% | 55,6% |
Проверено OSWorld | 75,0% | 74,0%* | 47,3% |
Туатлон | 54,6% | 51,9% | 46,3% |
BrowseComp | 82,7% | 77,3% | 65,8% |
*Ранее сообщалось о показателе 64,7%. GPT-5.3-Codex достигает 74,0% благодаря новому параметру API, который сохраняет исходное разрешение изображения.
Работа с интеллектуальным трудом
Основываясь на общих возможностях логического мышления GPT-5.2, GPT-5.4 обеспечивает еще более стабильные и отточенные результаты при решении реальных задач, важных для профессионалов.
В тесте GDPval , который проверяет способность агентов выполнять четко определенную интеллектуальную работу в 44 профессиях, GPT-5.4 достигает нового уровня, сравнявшись или превзойдя результаты отраслевых специалистов в 83,0% случаев, по сравнению с 70,9% для GPT-5.2.
В GDPval модели пытаются выполнять четко определенные интеллектуальные задачи, охватывающие 44 профессии из 9 ведущих отраслей, вносящих наибольший вклад в ВВП США. Задания требуют создания реальных результатов работы, таких как презентации продаж, бухгалтерские таблицы, графики оказания неотложной помощи, производственные схемы или короткие видеоролики. Уровень сложности рассуждений был установлен на xhigh для GPT-5.4 и heavy для GPT-5.2 (немного ниже в ChatGPT).
«GPT-5.4 — лучшая модель из всех, что мы когда-либо пробовали. Сейчас она занимает первое место в нашем бенчмарке APEX-Agents, который измеряет производительность моделей для работы в сфере профессиональных услуг. Она превосходно справляется с созданием долгосрочных результатов, таких как презентации, финансовые модели и юридический анализ, обеспечивая высочайшую производительность при более высокой скорости и меньших затратах, чем конкурирующие модели».
— Брендан Фуди, генеральный директор Mercor
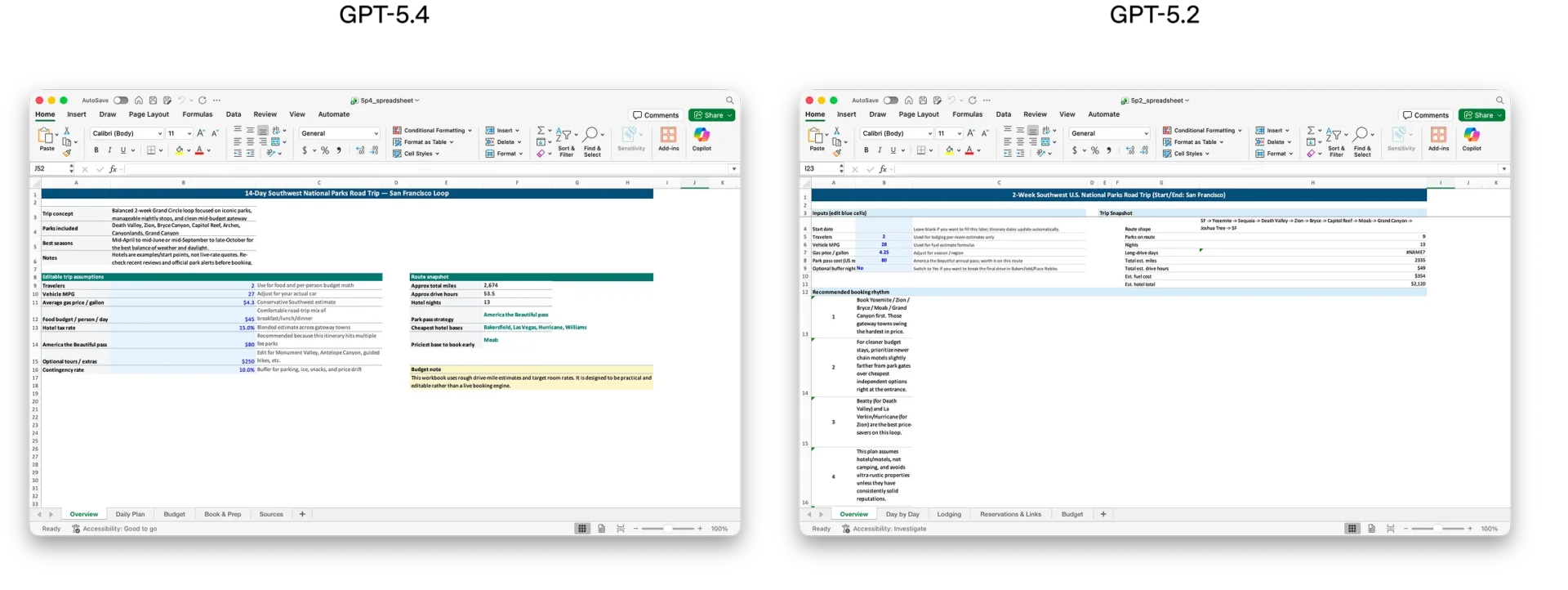
Мы уделили особое внимание улучшению возможностей GPT-5.4 по созданию и редактированию электронных таблиц, презентаций и документов. По результатам внутреннего теста задач моделирования в электронных таблицах, которые может выполнять младший аналитик инвестиционного банка, GPT-5.4 набирает в среднем 87,3% , по сравнению с 68,4% у GPT-5.2. В ходе оценки презентаций эксперты-оценщики в 68% случаев отдавали предпочтение презентациям, созданным в GPT-5.4, перед презентациями из GPT-5.2 из-за более высокой эстетики, большего визуального разнообразия и более эффективного использования генерации изображений.

Документы были сгенерированы с уровнем сложности рассуждений, установленным на «очень высокий».
Вы можете опробовать эти возможности в ChatGPT, используя GPT-5.4 Thinking или Pro. Если вы являетесь корпоративным клиентом, мы рекомендуем использовать нашу недавно выпущенную надстройку ChatGPT для Excel (открывается в новом окне) , которая также была запущена сегодня. Мы также обновили наши навыки работы с электронными таблицами (открывается в новом окне) и презентациями (открывается в новом окне), доступные в Codex и API.
Чтобы улучшить работу GPT-5.4 в реальных условиях, мы продолжили работу над снижением количества ложных утверждений и ошибок. GPT-5.4 — наша самая достоверная модель на сегодняшний день: на наборе обезличенных запросов, где пользователи указывали на фактические ошибки, вероятность ложности отдельных утверждений GPT-5.4 на 33% ниже, а вероятность наличия ошибок в полных ответах — на 18% ниже по сравнению с GPT-5.2.
«GPT-5.4 устанавливает новый стандарт для работы с большим объемом документов в юридической сфере. В нашей оценке BigLaw Bench он получил 91%. По сравнению с другими моделями, GPT-5.4 в настоящее время лучше справляется со структурированием сложного анализа транзакций, обеспечивает точность при работе с объемными контрактами и предоставляет высокий уровень детализации, необходимый юристам».
— Нико Групен, руководитель отдела прикладных исследований в компании Harvey.
Использование компьютеров и компьютерное зрение
GPT-5.4 — это наша первая универсальная модель с возможностями, изначально предназначенная для использования на компьютерах , и она знаменует собой значительный шаг вперед как для разработчиков, так и для агентов. Это лучшая из доступных на данный момент моделей для разработчиков, создающих агентов, выполняющих реальные задачи на веб-сайтах и в программных системах.
Мы разработали GPT-5.4 для обеспечения высокой производительности в широком диапазоне рабочих нагрузок на компьютерах. Он отлично подходит для написания кода, управляющего компьютерами с помощью таких библиотек, как Playwright, а также для выполнения команд мыши и клавиатуры в ответ на скриншоты. Его поведение можно регулировать с помощью сообщений для разработчиков, что позволяет настраивать поведение в соответствии с конкретными сценариями использования. Разработчики даже могут настраивать поведение модели в отношении безопасности в соответствии с различными уровнями допустимого риска, указывая пользовательские политики подтверждения.
Производительность и гибкость модели подтверждаются результатами тестов, оценивающих использование компьютера в различных условиях. В тесте OSWorld-Verified , который измеряет способность модели перемещаться по рабочему столу с помощью скриншотов и действий с клавиатурой/мышью, GPT-5.4 достигает передового показателя успешности в 75,0% , что значительно превосходит 47,3% у GPT-5.2 и превосходит показатели человека ( 72,4%) .
На WebArena-Verified , тестирующем использование браузеров, GPT-5.4 демонстрирует лидирующий показатель успешности в 67,3% при использовании как DOM-взаимодействия, так и взаимодействия на основе скриншотов, по сравнению с 65,4% у GPT-5.2 . На Online-Mind2Web , также тестирующем использование браузеров, GPT-5.4 достигает показателя успешности в 92,8% при использовании только наблюдений на основе скриншотов, превосходя показатель успешности в режиме агента ChatGPT Atlas, который составляет 70,9% .
Перезагрузка инструмента — это ситуация, когда ассистент уступает место в ожидании ответа инструмента. Если одновременно вызываются 3 инструмента, а затем еще 3 инструмента, то количество перезагрузок будет равно 2. Перезагрузки инструментов являются лучшим показателем задержки, чем вызовы инструментов, поскольку они отражают преимущества распараллеливания.
GPT-5.4 интерпретирует скриншоты интерфейса браузера и взаимодействует с элементами пользовательского интерфейса посредством щелчков по координатам для отправки электронных писем и планирования событий в календаре. Видео не ускоряется.
Улучшенная работа GPT-5.4 на компьютере основана на усовершенствованных общих возможностях визуального восприятия модели. В тесте MMMU-Pro , оценивающем визуальное понимание и рассуждения модели, GPT-5.4 достигает 81,2% успеха без использования инструментов, что является улучшением по сравнению с предыдущими версиями. GPT-5.2 показывает результат 79,5% . Улучшенное визуальное восприятие также приводит к улучшению возможностей анализа документов. На OmniDocBench GPT-5.4 без вычислительных усилий достигает средней ошибки (измеренной по нормализованному расстоянию редактирования между предсказанием модели и истинным значением) 0,109 , что лучше, чем у GPT-5.2 ( 0,140) .
Программа MMMUPro запускалась с параметром логического вывода xhigh. Программа OmniDocBench запускалась с параметром логического вывода none, что отражает низкую стоимость и низкую задержку при тестировании производительности.
Мы также улучшаем визуальное восприятие плотных изображений высокого разрешения, где важна полная детализация. Начиная с GPT-5.4, мы вводим уровень детализации исходного изображения (открывается в новом окне) , который поддерживает восприятие полной детализации до 10,24 млн пикселей или 6000 пикселей в зависимости от того, что меньше; уровень детализации высокого изображения теперь поддерживает до 2,56 млн пикселей или 2048 пикселей в качестве максимального размера. В ходе предварительного тестирования с пользователями API мы наблюдали значительное улучшение способности к локализации, понимания изображения и точности кликов при использовании исходного или высокого уровня детализации.
«В ходе наших оценок производительности использования компьютеров на примерно 30 000 порталах ТСЖ и налоговых деклараций, GPT-5.4 показал 95% успешность с первой попытки и 100% в течение трех попыток, по сравнению с 73–79% у предыдущих моделей CUA. Он также завершал сессии примерно в 3 раза быстрее, используя при этом примерно на 70% меньше токенов, что существенно повысило надежность и экономическую эффективность в масштабе».
— Дод Фрейзер, генеральный директор Mainstay
В API разработчики могут получить доступ к этим возможностям, используя обновленный инструмент для работы с компьютером . Рекомендации по передовым методам см. в нашей обновленной документации (откроется в новом окне) .
Программирование
GPT-5.4 сочетает в себе сильные стороны программирования GPT-5.3-Codex с передовыми возможностями обработки знаний и использования вычислительных ресурсов, что наиболее важно для длительных задач, где модель может использовать инструменты, итерации и продвигать работу дальше с меньшим ручным вмешательством. В SWE-Bench Pro он показывает результаты, сопоставимые или превосходящие GPT-5.3-Codex, при этом демонстрируя меньшую задержку при выполнении логических вычислений.
Мы оцениваем задержку, анализируя поведение наших моделей в производственной среде и моделируя это в автономном режиме. Оценка задержки учитывает длительность вызова инструмента (время выполнения кода), количество выбранных токенов и количество входных токенов. Реальная задержка может существенно варьироваться и зависит от многих факторов, не учтенных в нашем моделировании. Уровень сложности рассуждений был измерен от нуля до очень высокого.
При включении режима /fast в Codex скорость генерации токенов увеличивается до 1,5 раз с GPT-5.4. Это та же модель и тот же интеллект, только быстрее. Это означает, что пользователи могут выполнять задачи кодирования, итерации и отладку, оставаясь в рабочем потоке. Разработчики могут получить доступ к GPT-5.4 с той же высокой скоростью через API, используя приоритетную обработку (открывается в новом окне) .
В ходе оценки и внутреннего тестирования мы обнаружили, что GPT-5.4 превосходно справляется со сложными задачами фронтенда, демонстрируя заметно более эстетичные и функциональные результаты, чем любые модели, которые мы выпускали ранее.
В качестве демонстрации улучшенных возможностей модели по использованию компьютеров и программированию, работающих в тандеме, мы также выпускаем экспериментальный навык Codex под названием « Playwright (Interactive) (открывается в новом окне) ». Он позволяет Codex визуально отлаживать веб-приложения и приложения Electron; его даже можно использовать для тестирования разрабатываемого приложения в процессе его разработки.
Игра-симулятор тематического парка, созданная с помощью GPT-5.4 на основе одной кратко сформулированной задачи, с использованием Playwright Interactive для тестирования в браузере и генерации изображений для набора изометрических ресурсов. Симуляция включает в себя размещение путей на основе плиток, строительство аттракционов и декораций, поиск пути для посетителей, очереди и циклы аттракционов, в то время как показатели парка, такие как деньги, количество посетителей, удовлетворенность, чистота и рейтинг, повышаются или понижаются в зависимости от того, как работает планировка и как посетители на нее реагируют. Playwright использовался для автоматизации тестирования в браузере путем построения и расширения парка, размещения и удаления путей и аттракционов, проверки навигации камеры и подтверждения корректного обновления данных о посетителях, очередях, состояниях аттракционов и показателях пользовательского интерфейса в течение нескольких раундов игры.
Задание: Используйте $playwright-interactive и $imagegen. Создайте интерактивную изометрическую игру-симулятор тематического парка, которую я смогу создавать и перемещаться по ней в браузере. Используйте imagegen для определения общей визуальной концепции и генерации игровых ресурсов, включая аттракционы, дорожки, ландшафт, деревья, воду, киоски с едой, декорации, здания, иконки и иллюстрации пользовательского интерфейса. Мир должен выглядеть цельным, отполированным и визуально насыщенным, с высококачественным художественным оформлением, хорошо работающим с изометрической перспективы. Позвольте мне размещать и удалять дорожки, добавлять аттракционы, располагать декорации и плавно перемещаться по парку, отслеживая активность посетителей, статус аттракционов и рост парка. Включите правдоподобное перемещение посетителей, простые системы управления парком, такие как деньги, чистота, очереди и удовлетворенность, и сделайте игровой процесс игривым, понятным и завершенным, а не похожим на грубый прототип. Приоритет должен отдаваться очарованию, читаемости и сильному игровому ощущению, а не реализму.
При тестировании игры обязательно постройте и расширьте парк в нескольких игровых раундах, убедитесь, что размещение объектов и навигация работают плавно, подтвердите реакцию посетителей на планировку парка и аттракционы, а также убедитесь, что визуальное оформление, пользовательский интерфейс и взаимодействие ощущаются стабильными и согласованными.
«В настоящее время GPT-5.4 лидирует в наших внутренних тестах. Наши инженеры считают его более естественным и уверенным в себе, чем предыдущие модели. Он справляется с неоднозначными задачами, не сомневаясь в собственных решениях, и активно распараллеливает работу, чтобы поддерживать динамику процесса».
— Ли Робинсон, вице-президент по обучению разработчиков в компании Cursor
Использование инструментов
В GPT-5.4 мы значительно улучшили взаимодействие моделей с внешними инструментами. Теперь агенты могут работать в более широких экосистемах инструментов, более надежно выбирать нужные инструменты и выполнять многоэтапные рабочие процессы с меньшими затратами и задержкой.
Поиск инструментов
В API GPT-5.4 представлен поиск инструментов (открывается в новом окне) , который позволяет моделям эффективно работать при наличии множества инструментов.
Ранее, когда модели предоставлялись инструменты, все определения инструментов включались в запрос заранее. Для систем с большим количеством инструментов это могло добавлять тысячи — или даже десятки тысяч — токенов к каждому запросу, увеличивая стоимость, замедляя ответы и перегружая контекст информацией, которую модель, возможно, никогда не использовала.
В отличие от других инструментов, GPT-5.4 получает упрощенный список доступных инструментов вместе с возможностью поиска инструментов. Когда модели необходимо использовать тот или иной инструмент, она может найти его определение и добавить его в диалог в данный момент.
Такой подход значительно сокращает количество токенов, необходимых для ресурсоемких рабочих процессов, и сохраняет кэш, делая запросы быстрее и дешевле. Он также позволяет агентам надежно работать с гораздо более крупными экосистемами инструментов. Для серверов MCP, которые могут содержать десятки тысяч токенов определений инструментов, повышение эффективности может быть существенным.
Чтобы продемонстрировать повышение эффективности, мы оценили 250 задач из бенчмарка Scale MCP Atlas (открывается в новом окне) со всеми 36 серверами MCP, включенными в двух режимах: (1) с прямым доступом ко всем функциям MCP в контексте модели и (2) с размещением всех серверов MCP за поиском инструментов. Конфигурация с поиском инструментов позволила сократить общее использование токенов на 47% при сохранении той же точности.
Примеры количества токенов получены путем усреднения данных по 250 задачам из общедоступного набора данных MCP-Atlas.
Вызов агентского инструмента
GPT-5.4 также улучшает вызов инструментов , делая его более точным и эффективным при принятии решений о том, когда и как использовать инструменты во время рассуждений, особенно в API. По сравнению с GPT-5.2, он достигает более высокой точности за меньшее количество ходов в Toolathlon, бенчмарке, который проверяет, насколько хорошо агенты ИИ могут использовать реальные инструменты и API для выполнения многоэтапных задач. Например, агенту необходимо прочитать электронные письма, извлечь вложения к заданиям, загрузить их, оценить и записать результаты в электронную таблицу.
Перезагрузка инструмента — это ситуация, когда ассистент уступает место в ожидании ответа инструмента. Если одновременно вызываются 3 инструмента, а затем еще 3 инструмента, то количество перезагрузок будет равно 2. Перезагрузки инструментов являются лучшим показателем задержки, чем вызовы инструментов, поскольку они отражают преимущества распараллеливания.
Для сценариев использования, чувствительных к задержке и требующих нулевого уровня логического вывода, GPT-5.4 еще больше превосходит своих предшественников.
В τ2-bench (открывается в новом окне) модель должна использовать инструменты для выполнения задачи обслуживания клиентов, где может присутствовать смоделированный пользователь, который может общаться и действовать в отношении состояния мира. Уровень сложности рассуждений был установлен на «Нет».
Улучшен поиск в интернете
GPT-5.4 лучше справляется с веб-поиском, осуществляемым агентами. По показателю BrowseComp, оценивающему способность агентов ИИ постоянно просматривать веб-страницы для поиска труднодоступной информации, GPT-5.4 превосходит GPT-5.2 на 17% , а GPT-5.4 Pro устанавливает новый рекорд в 89,3%.
На практике это означает, что мышление по методике GPT-5.4 лучше справляется с ответами на вопросы, требующие объединения информации из множества источников в интернете. Оно может более настойчиво проводить поиск в несколько этапов, чтобы выявить наиболее релевантные источники, особенно для вопросов типа «иголка в стоге сена», и синтезировать их в ясный, хорошо обоснованный ответ.
В BrowseComp мы использовали список исключений, исключающий из оценки веб-сайты, содержащие результаты бенчмарка, чтобы предотвратить искажение данных и обеспечить справедливую оценку производительности. GPT-5.4 был протестирован позже, чем GPT-5.2, поэтому оценки отражают изменения в модели, нашей системе поиска и состоянии интернета. Тестирование GPT-5.4 проводилось с использованием более длинного и обновленного списка исключений. Модели используют инструмент поиска ChatGPT, который может немного отличаться от поиска по API.
«GPT-5.4 xhigh — это новый уровень совершенства в использовании многоэтапных инструментов. Zapier проводит одни из самых строгих тестов производительности инструментов в отрасли, проверяя модели на сотнях сложных реальных рабочих процессов. GPT-5.4 завершил работу там, где предыдущие модели сдались — это самая устойчивая модель на сегодняшний день».
— Уэйд, генеральный директор Zapier
Управляемость
Подобно тому, как Codex описывает свой подход в начале работы, GPT-5.4 Thinking in ChatGPT теперь будет описывать свою работу с помощью преамбулы для более длинных и сложных запросов. Вы также можете добавлять инструкции или корректировать направление в середине ответа. Это упрощает управление моделью для достижения желаемого результата без необходимости начинать все заново или выполнять несколько дополнительных действий. Эта функция уже доступна на chatgpt.com (открывается в новом окне) и в приложении для Android, а в скором времени появится и в приложении для iOS.
Модель также способна дольше обдумывать сложные задачи, сохраняя при этом более четкое понимание предыдущих этапов разговора. Это позволяет ей обрабатывать более длительные рабочие процессы и более сложные запросы, сохраняя при этом ответы последовательными и актуальными на протяжении всего процесса.
Видео ускорено для наглядности.
Безопасность
В последние месяцы мы продолжали совершенствовать меры защиты, введенные в GPT-5.3-Codex, одновременно готовя к развертыванию GPT-5.4. Аналогично GPT-5.3-Codex, мы рассматриваем GPT-5.4 как систему с высоким уровнем кибербезопасности в рамках нашей системы обеспечения готовности и развертываем ее с соответствующими мерами защиты, описанными в системной карте (открывается в новом окне) . К ним относятся расширенный комплекс мер кибербезопасности, включающий системы мониторинга, доверенные средства контроля доступа и асинхронную блокировку запросов повышенного риска для клиентов, использующих платформы с нулевым хранением данных (ZDR), а также постоянные инвестиции в более широкую экосистему безопасности.
Поскольку возможности кибербезопасности по своей природе имеют двойное назначение, мы придерживаемся осторожного подхода к развертыванию, продолжая при этом калибровать наши политики и классификаторы. Для некоторых клиентов, использующих платформы ZDR, блокировка на уровне запросов остается частью нашего комплекса мер по снижению киберрисков; поскольку классификаторы все еще совершенствуются, могут возникать ложные срабатывания по мере дальнейшего уточнения этих мер защиты. Эти обновления направлены на улучшение работы мер защиты на практике, включая сокращение ненужных отказов и чрезмерно подробных ответов, при сохранении надежной защиты от неправомерного использования.
Мы продолжили наши исследования в области безопасности, касающиеся мониторинга цепочки рассуждений (Chain- of-Thought, CoT), чтобы лучше понять, как модели рассуждают, и помочь выявить потенциальные нарушения. В рамках этой работы мы представляем новую оценку с открытым исходным кодом, контролируемость CoT , измеряющую, могут ли модели намеренно скрывать свои рассуждения, чтобы избежать мониторинга. Мы обнаружили, что способность GPT-5.4 Thinking контролировать свою CoT низка, что является положительным свойством для безопасности, предполагающим, что модель не способна скрывать свои рассуждения и что мониторинг CoT остается эффективным инструментом обеспечения безопасности.
Наличие и цены
Сегодня GPT-5.4 постепенно внедряется в ChatGPT и Codex. В API GPT-5.4 уже доступен как gpt-5.4 . GPT-5.4 Pro также доступен в API как gpt-5.4-pro для разработчиков, которым требуется максимальная производительность при решении самых сложных задач.
В ChatGPT с сегодняшнего дня пользователям ChatGPT Plus, Team и Pro доступна версия GPT-5.4 Thinking, заменяющая GPT-5.2 Thinking. GPT-5.2 Thinking останется доступной в течение трех месяцев для платных пользователей в меню выбора моделей в разделе «Устаревшие модели», после чего будет выведена из эксплуатации 5 июня 2026 года. Пользователи планов Enterprise и Edu могут включить ранний доступ через настройки администратора. GPT-5.4 Pro доступна для планов Pro и Enterprise. Контекстные окна (открываются в новом окне) в ChatGPT для GPT-5.4 Thinking остаются без изменений по сравнению с GPT-5.2 Thinking.
GPT-5.4 — это наша первая основная модель рассуждений, которая включает в себя возможности кодирования, реализованные в GPT-5.3-codex, и которая внедряется в ChatGPT, API и Codex. Мы называем её GPT-5.4, чтобы отразить этот скачок и упростить выбор между моделями при использовании Codex. Со временем наши модели мгновенного реагирования и модели мышления будут развиваться с разной скоростью.
В Codex GPT-5.4 включена экспериментальная поддержка контекстного окна размером 1 МБ. Разработчики могут попробовать это, настроив параметры model_context_window и model_auto_compact_token_limit . Запросы, превышающие стандартное контекстное окно в 272 КБ, учитываются в лимитах использования в 2 раза чаще, чем обычно.
В API цена GPT-5.4 за токен выше, чем у GPT-5.2, что отражает улучшенные возможности, а более высокая эффективность использования токенов помогает сократить общее количество токенов, необходимых для многих задач. Пакетная и гибкая обработка доступны по цене вдвое ниже стандартной цены API, а приоритетная обработка — по цене вдвое выше стандартной цены API.
модель API | Цена на вход | Кэшированная входная цена | Цена выпуска |
gpt-5.2 | 1,75 долл. США / млн токенов | 0,175 долл. США / токены M | 14 долларов США / млн токенов |
gpt-5.4 | 2,50 долл. США / жетоны M | 0,25 долл. США / млн токенов | 15 долларов США / токены |
gpt-5.2-pro | 21 доллар США / млн токенов | — | 168 долларов США / млн токенов |
gpt-5.4-pro | 30 долларов США / токены | — | 180 долларов США / токены M |
Оценки
Профессиональный
Оценка | ГПТ-5.4 | ГПТ-5.4 | GPT‑5.3-Кодекс | ГПТ-5.2 | ГПТ-5.2 |
ВВПвал | 83,0% | 82,0% | 70,9% | 70,9% | 74,1% |
FinanceAgent v1.1 | 56,0% | 61,5% | 54,0% | 59,5% | — |
Задачи моделирования в инвестиционном банкинге (внутренние) | 87,3% | 83,6% | 79,3% | 68,4% | 71,7% |
OfficeQA | 68,1% | — | 65,1% | 63,1% | — |
Программирование
Оценка | ГПТ-5.4 | ГПТ-5.4 | GPT‑5.3-Кодекс | ГПТ-5.2 | ГПТ-5.2 |
SWE-Bench Pro (публичная версия) | 57,7% | — | 56,8% | 55,6% | — |
Терминальный стенд 2.0 | 75,1% | — | 77,3% | 62,2% | — |
Использование компьютеров и компьютерное зрение
Оценка | ГПТ-5.4 | ГПТ-5.4 | GPT‑5.3-Кодекс | ГПТ-5.2 | ГПТ-5.2 |
Проверено OSWorld | 75,0% | — | 74,0% | 47,3% | — |
MMMU Pro (без инструментов) | 81,2% | — | — | 79,5% | — |
MMMU Pro (с инструментами) | 82,1% | — | — | 80,4% | — |
Использование инструментов
Оценка | ГПТ-5.4 | ГПТ-5.4 | GPT‑5.3-Кодекс | ГПТ-5.2 | ГПТ-5.2 |
BrowseComp | 82,7% | 89,3% | 77,3% | 65,8% | 77,9% |
Атлас MCP | 67,2% | — | — | 60,6% | — |
Туатлон | 54,6% | — | 51,9% | 45,7% | — |
Tau2-bench Telecom | 98,9% | — | — | 98,7% | — |
Академический
Оценка | ГПТ-5.4 | ГПТ-5.4 | GPT‑5.3-Кодекс | ГПТ-5.2 | ГПТ-5.2 |
Передовые научные исследования | 33,0% | 36,7% | — | 25,2% | — |
FrontierMath, уровни 1–3 | 47,6% | 50,0% | — | 40,7% | — |
FrontierMath Уровень 4 | 27,1% | 38,0% | — | 18,8% | 31,3% |
GPQA Diamond | 92,8% | 94,4% | 92,6% | 92,4% | 93,2% |
Последний экзамен человечества (без инструментов) | 39,8% | 42,7% | — | 34,5% | 36,6% |
Последний экзамен человечества (с инструментами) | 52,1% | 58,7% | — | 45,5% | 50,0% |
Длинный контекст
Оценка | ГПТ-5.4 | ГПТ-5.4 | GPT‑5.3-Кодекс | ГПТ-5.2 | ГПТ-5.2 |
Graphwalks BFS 0K–128K | 93,0% | — | — | 94,0% | — |
Graphwalks BFS 256K–1M | 21,4% | — | — | — | — |
Graphwalks parents 0–128K (точность) | 89,8% | — | — | 89,0% | — |
Родители Graphwalks 256K–1M (точность) | 32,4% | — | — | — | — |
OpenAI MRCR v2 8-игольный 4K–8K | 97,3% | — | — | 98,2% | — |
OpenAI MRCR v2 8-игольный 8K–16K | 91,4% | — | — | 89,3% | — |
OpenAI MRCR v2 8-игольный 16K–32K | 97,2% | — | — | 95,3% | — |
OpenAI MRCR v2 8-игольный 32K–64K | 90,5% | — | — | 92,0% | — |
OpenAI MRCR v2 8-игольный 64K–128K | 86,0% | — | — | 85,6% | — |
OpenAI MRCR v2 8-игольный 128K–256K | 79,3% | — | — | 77,0% | — |
OpenAI MRCR v2 8-игольный 256K–512K | 57,5% | — | — | — | — |
OpenAI MRCR v2 8-игольный 512K–1M | 36,6% | — | — | — | — |
Абстрактное рассуждение
Оценка | ГПТ-5.4 | ГПТ-5.4 | GPT‑5.3-Кодекс | ГПТ-5.2 | ГПТ-5.2 |
ARC-AGI-1 (проверено) | 93,7% | 94,5% | — | 86,2% | 90,5% |
ARC-AGI-2 (проверено) | 73,3% | 83,3% | — | 52,9% | 54,2% (высокий) |
Оценки без рассуждений
Оценка | ГПТ-5.4 | ГПТ-5.2 | ГПТ-4.1 |
OmniDocBench (нормализованное расстояние редактирования) | 0.109 | 0.140 | — |
Tau2-bench Telecom | 64,3% | 57,2% | 43,6% |
Оценка проводилась с уровнем сложности рассуждений xhigh, если не указано иное. Бенчмарки проводились в исследовательской среде, что в некоторых случаях может дать несколько иные результаты по сравнению с производственной версией ChatGPT.
Источник: openai.com