
Агрегации — одна из самых мощных функций Power BI. Узнайте, как использовать эту функцию для повышения производительности вашего решения Power BI.
Делиться

Если вы когда-либо использовали функцию «Композитная модель» в Power BI, вы, возможно, уже слышали о другой чрезвычайно важной и мощной концепции — агрегации! Дело в том, что во многих сценариях, особенно в моделях корпоративного масштаба, агрегации являются естественным «ингредиентом» композитной модели.
Однако, поскольку возможности составных моделей можно использовать и без использования агрегаций, я посчитал, что имеет смысл объяснить концепцию агрегаций в отдельной статье.
Прежде чем объяснить, как работают агрегаты в Power BI, и рассмотреть некоторые конкретные варианты их использования, давайте сначала ответим на следующие вопросы:
Зачем вообще нужны агрегации? В чём преимущество наличия двух таблиц с идентичными данными в модели?
Прежде чем прояснить эти два момента, важно помнить, что в Power BI существует два разных типа агрегаций.
- До недавнего времени пользовательские агрегации были единственным типом агрегации в Power BI. Здесь вы отвечаете за определение и управление агрегациями, хотя Power BI впоследствии автоматически идентифицирует их при выполнении запроса.
- Автоматические агрегации — одна из новейших функций Power BI. Включив эту функцию, вы можете выпить чашечку кофе, расслабиться и посмотреть, как алгоритмы машинного обучения соберут данные о наиболее часто выполняемых запросах в ваших отчётах и автоматически построят агрегации для их поддержки.
Важное различие между этими двумя типами, помимо того, что при использовании автоматических агрегаций вам не нужно ничего делать, кроме включения этой функции в вашем клиенте, заключается в лицензионных ограничениях. Пользовательские агрегации будут работать как с Premium, так и с Pro, а для автоматических агрегаций на данный момент требуется лицензия Premium.
С этого момента мы будем говорить только о пользовательских агрегациях, просто помните об этом.
Итак, вот краткое объяснение агрегаций и того, как они работают в Power BI. Допустим, у вас есть большая, очень большая таблица фактов, которая может содержать сотни миллионов, а то и миллиарды строк. Как же обрабатывать аналитические запросы к такому огромному объёму данных?

Вы просто создаёте агрегированные таблицы! На самом деле, это очень редкая ситуация, или, скажем так, скорее исключение, чем правило, когда аналитические требования заключаются в том, чтобы рассматривать отдельную транзакцию или отдельную запись как самый низкий уровень детализации. В большинстве случаев вам нужно выполнить анализ обобщённых данных: например, какой доход был у нас в определённый день? Или какова была общая сумма продаж товара X? И далее, сколько в общей сложности потратил клиент X?
Кроме того, вы можете агрегировать данные по нескольким атрибутам, что обычно и происходит, и суммировать показатели по конкретной дате, клиенту и продукту.

Если вам интересно, в чем смысл агрегации данных… Ну, конечная цель — сократить количество строк и, следовательно, уменьшить общий размер модели данных за счет предварительной подготовки данных.
Таким образом, если мне нужно узнать общую сумму продаж, потраченную клиентом X на продукт Y в первом квартале года, я могу воспользоваться тем, что эти данные уже обобщены заранее.
Ключевой «ингредиент» — сделайте так, чтобы Power BI «знал» об агрегациях!
Хорошо, это одна сторона медали. Теперь начинается самое интересное. Для ускорения отчётов Power BI одного лишь создания агрегатов недостаточно — необходимо, чтобы Power BI учитывал их!
Прежде чем мы продолжим, одно замечание: агрегация будет работать только в том случае, если исходная таблица фактов использует режим хранения DirectQuery. Скоро мы объясним, как проектировать и управлять агрегациями, а также как настроить правильный режим хранения таблиц. Пока просто помните, что исходная таблица фактов должна использовать режим хранения DirectQuery.
Давайте начнем строить наши агрегаты!

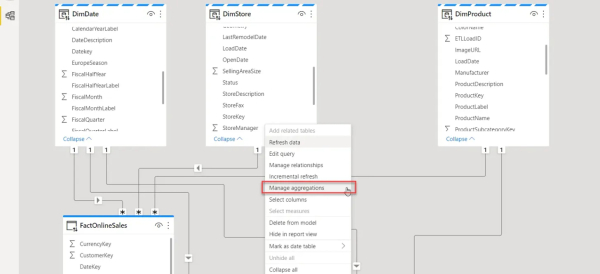
Как видно на иллюстрации выше, наша модель довольно проста: она состоит из одной таблицы фактов (FactOnlineSales) и трёх измерений (DimDate, DimStore и DimProduct). Все таблицы в настоящее время используют режим хранения DirectQuery.
Давайте создадим две дополнительные таблицы, которые будем использовать как агрегированные: первая будет группировать данные по дате и продукту, а другая будет использовать для группировки дату и магазин:
/*Таблица 1: Агрегированные данные по дате и продукту */ SELECT DateKey ,ProductKey ,SUM(SalesAmount) AS SalesAmount ,SUM(SalesQuantity) AS SalesQuantity FROM FactOnlineSales GROUP BY DateKey ,ProductKey /*Таблица 2: Агрегированные данные по дате и магазину */ SELECT DateKey ,StoreKey ,SUM(SalesAmount) AS SalesAmount ,SUM(SalesQuantity) AS SalesQuantity FROM FactOnlineSales GROUP BY DateKey ,StoreKey

Я переименовал эти запросы в Sales Product Agg и Sales Store Agg соответственно и закрыл редактор Power Query.
Поскольку мы хотим добиться максимально возможной производительности для большинства наших запросов (запросов, которые извлекают данные, обобщенные по дате и/или продукту/магазину), я изменю режим хранения вновь созданных агрегированных таблиц с DirectQuery на Import:

Теперь эти таблицы загружены в кэш-память, но они всё ещё не связаны с нашими существующими таблицами измерений. Давайте создадим связи между измерениями и агрегированными таблицами:

Прежде чем мы продолжим, позвольте мне на мгновение остановиться и объяснить, что произошло при создании связей. Если вы помните нашу предыдущую статью, я упоминал, что в Power BI существует два типа связей: обычные и ограниченные. Это важно: любая связь между таблицами из разных исходных групп (режим импорта — одна исходная группа, DirectQuery — другая) будет ограниченной! Со всеми присущими ей ограничениями.
Но у меня для вас хорошие новости! Если я переключу режим хранения моих таблиц измерений на Dual, это означает, что они также будут загружены в кэш-память, и в зависимости от того, какая таблица фактов предоставляет данные во время запроса, таблица измерений будет вести себя либо как в режиме импорта (если запрос обращается к таблицам фактов в режиме импорта), либо как в DirectQuery (если запрос извлекает данные из исходной таблицы фактов в DirectQuery):

Как вы могли заметить, больше нет никаких ограниченных отношений, и это здорово!
Итак, подведем итоги. Наша модель настроена следующим образом:
- Исходная таблица FactOnlineSales (со всеми подробными данными) – DirectQuery
- Таблицы измерений (DimDate, DimProduct, DimStore) – Двойные
- Агрегированные таблицы (Продажи Продукт Аггрег и Продажи Магазин Аггрег) – Импорт
Отлично! Теперь у нас есть агрегированные таблицы, и запросы должны выполняться быстрее, верно? Пип! Неправильно!

Визуальная таблица содержит именно те столбцы, которые мы предварительно агрегировали в нашей таблице Sales Product Agg. Так почему же Power BI выполняет DirectQuery вместо того, чтобы получить данные из импортированной таблицы? Вполне резонный вопрос!
Помните, я говорил вам в начале, что нам нужно предоставить Power BI информацию об агрегированной таблице, чтобы ее можно было использовать в запросах?
Давайте вернемся в Power BI Desktop и сделаем следующее:

Щелкните правой кнопкой мыши таблицу Sales Product Agg и выберите опцию Manage aggregations:

Несколько важных замечаний: для корректной работы агрегации типы данных в столбцах исходной таблицы фактов и агрегированной таблицы должны совпадать! В моём случае мне пришлось изменить тип данных столбца SalesAmount в агрегированной таблице с «Десятичное число» на «Фиксированное десятичное число».
Кроме того, вы видите сообщение, написанное красным: это означает, что после создания агрегированной таблицы она будет скрыта от конечного пользователя! Я применил точно такие же действия для своей второй агрегированной таблицы (Store), и теперь эти таблицы скрыты:

Давайте вернемся и обновим страницу нашего отчета, чтобы посмотреть, изменилось ли что-нибудь:

Отлично! На этот раз без DirectQuery, и вместо почти двух секунд, необходимых для отрисовки этого изображения, на этот раз потребовалось всего 58 миллисекунд! Более того, если я возьму запрос и перейду в DAX Studio, чтобы проверить, что происходит…

Как видите, исходный запрос был сопоставлен с агрегированной таблицей из режима импорта, и сообщение «Найдено совпадение» ясно указывает на то, что данные для визуализации взяты из таблицы Sales Product Agg! Хотя наш пользователь даже не подозревает о существовании этой таблицы в модели!
Разница в производительности, даже на этом относительно небольшом наборе данных, колоссальна!
Несколько агрегированных таблиц
Теперь вы, вероятно, задаетесь вопросом, зачем я создал две разные агрегированные таблицы. Допустим, у меня есть запрос, который отображает данные по разным магазинам, также сгруппированные по дате. Вместо того, чтобы сканировать 12,6 миллиона строк в режиме DirectQuery, движок может легко выдать данные из кэша, из таблицы, содержащей всего несколько тысяч строк!
По сути, вы можете создать несколько агрегированных таблиц в модели данных — не просто объединяя два группирующих атрибута (как в случае с Date+Product или Date+Store), но и включая дополнительные атрибуты (например, включая Date, Product и Store в одну агрегированную таблицу). Таким образом, вы увеличите степень детализации таблицы, но если вашей визуализации потребуется отображать данные и по Product, и по Store, вы сможете извлечь результаты только из кэша!
В нашем примере, поскольку у меня нет предварительно агрегированных данных на уровне, включающем как продукт, так и магазин, если я включу магазин в таблицу, я потеряю преимущество наличия агрегированных таблиц:

Таким образом, чтобы использовать агрегации, вам необходимо определить их на том же уровне зернистости, который требуется для визуального представления!
Приоритет агрегации
При работе с агрегатами важно понимать ещё одно важное свойство — приоритет! В диалоговом окне «Управление агрегатами» можно задать приоритет агрегации:

Это значение «указывает» Power BI, какую агрегированную таблицу использовать, если запрос может быть выполнен с помощью нескольких различных агрегаций! По умолчанию оно равно 0, но вы можете изменить это значение. Чем больше число, тем выше приоритет данной агрегации.
Почему это важно? Представьте себе ситуацию: у вас есть основная таблица фактов с миллиардом строк. И вы создаёте несколько агрегированных таблиц с разной степенью детализации:
- Агрегированная таблица 1: группирует данные по дате – содержит ~ 2000 строк (5 лет дат)
- Агрегированная таблица 2: группирует данные по дате и уровню продукта – содержит ~ 100 000 строк (5 лет дат x 50 продуктов)
- Агрегированная таблица 3: группирует данные по дате, продукту и уровню магазина – содержит ~ 5 000 000 строк (100 000 из предыдущего зерна x 50 магазинов)
Теперь предположим, что в отчёте отображаются агрегированные данные только на уровне даты. Как вы думаете, какую таблицу лучше сканировать: Таблицу 1 (2000 строк) или Таблицу 3 (5 миллионов строк)? Думаю, вы знаете ответ 🙂 Теоретически запрос можно выполнить из обеих таблиц, так зачем же полагаться на произвольный выбор Power BI?!
Вместо этого при создании нескольких агрегированных таблиц с разным уровнем детализации обязательно задайте значение приоритета таким образом, чтобы таблицы с более низким уровнем детализации получали приоритет!
Заключение
Агрегации — одна из самых мощных функций Power BI, особенно в сценариях с большими наборами данных! Несмотря на то, что и составные модели, и агрегации можно использовать независимо друг от друга, обычно они используются совместно, обеспечивая оптимальный баланс между производительностью и доступностью всех деталей данных!
Спасибо за прочтение!
Источник: towardsdatascience.com

 18")























