
Преодоление «обрыва производительности»: как сочетание MRL с int8 и бинарным квантованием позволяет сбалансировать затраты на инфраструктуру и точность поиска.
Делиться

Векторный поиск лежит в основе инфраструктуры ИИ, обеспечивая работу множества функций ИИ, от генерации с расширенным поиском (RAG) до навыков агентов и долговременной памяти. В результате спрос на индексирование больших наборов данных быстро растет. Для инженерных команд переход от небольшого прототипа к полномасштабному производственному решению становится серьезной проблемой, связанной с необходимым хранилищем и соответствующими затратами на инфраструктуру векторных баз данных. Именно тогда возникает необходимость в оптимизации.
В этой статье я рассматриваю основные подходы к оптимизации хранения векторных баз данных: квантование и обучение представлению в виде матрешки (MRL) , а также анализирую, как эти методы могут использоваться по отдельности или в сочетании для снижения затрат на инфраструктуру при сохранении высокого качества результатов поиска.
Глубокое погружение
Анатомия затрат на хранение векторных данных
Чтобы понять, как оптимизировать индекс, сначала нужно взглянуть на исходные данные. Почему векторные базы данных вообще становятся такими дорогими?
Объём памяти, занимаемый векторной базой данных, определяется двумя основными факторами: точностью и размерностью .
- Точность: Вектор встраивания обычно представляется в виде массива 32-битных чисел с плавающей запятой (Float32). Это означает, что каждое отдельное число внутри вектора занимает 4 байта памяти.
- Размерность: Чем выше размерность, тем больше «пространства» у модели для размещения семантических деталей исходных данных. Современные модели встраивания обычно выдают векторы с 768 или 1024 измерениями.
Давайте произведем расчеты для стандартного 1024-мерного векторного представления в производственной среде:
- Размер базового вектора: 1024 измерения * 4 байта = 4 КБ на вектор.
- Высокая доступность: Для обеспечения надежности в производственных векторных базах данных используется репликация (обычно в 3 раза). Это позволяет сократить объем памяти, необходимый для индексации каждого вектора, до 12 КБ .
Хотя 12 КБ кажутся незначительным объемом данных, при переходе от небольшого экспериментального проекта к производственному приложению, обрабатывающему миллионы документов, требования к инфраструктуре резко возрастают:
- 1 миллион векторов: ~12 ГБ оперативной памяти
- 100 миллионов векторов: ~1,2 ТБ оперативной памяти
Если предположить, что стоимость облачного хранилища составляет около 5 долларов США за ГБ в месяц, то индекс из 100 миллионов векторов будет стоить примерно 6000 долларов США в месяц. Важно отметить, что это только для самих векторов. Фактическая структура данных индекса (например, HNSW) добавляет значительные накладные расходы на память для хранения иерархических связей графа, что делает реальную стоимость еще выше.
Для оптимизации хранения и, следовательно, минимизации затрат, существуют два основных метода:
- Квантование
- MRL (Matryoshka Representation Learning)
Квантование
Квантование — это метод уменьшения объема памяти (ОЗУ или диска), необходимого для хранения вектора, за счет снижения точности его базовых чисел. В то время как стандартная модель встраивания выдает высокоточные 32-битные числа с плавающей запятой (float32), хранение векторов с такой точностью обходится дорого, особенно для больших индексов. Снижение точности позволяет значительно сократить затраты на хранение.
В векторных базах данных используются три основных типа квантования:
Скалярное квантование — это наиболее распространенный тип, используемый в производственных системах. Он уменьшает точность числа вектора с float32 (4 байта) до int8 (1 байт), что обеспечивает до 4 раз меньшее потребление памяти при минимальном влиянии на качество извлечения данных. Кроме того, уменьшенная точность ускоряет вычисления расстояний при сравнении векторов, что также немного снижает задержку.
Бинарный квантование — это крайний случай уменьшения точности. Он преобразует числа типа float32 в один бит (например, 1, если число > 0, и 0, если <= 0). Это обеспечивает колоссальное 32-кратное сокращение объема памяти. Однако это часто приводит к резкому снижению качества поиска, поскольку такое бинарное представление не обеспечивает достаточной точности для описания сложных характеристик и, по сути, размывает их.
Квантование произведения — В отличие от скалярного и бинарного квантования, которые работают с отдельными числами, квантование произведения делит вектор на фрагменты, выполняет кластеризацию этих фрагментов для поиска «центроидов» и сохраняет только короткий идентификатор ближайшего центроида. Хотя квантование произведения может обеспечить чрезвычайно высокую степень сжатия, оно сильно зависит от распределения базового набора данных и вносит вычислительные затраты на аппроксимацию расстояний во время поиска.
Примечание: Поскольку результаты квантования произведения сильно зависят от набора данных, мы сосредоточим наши эмпирические эксперименты на скалярном и бинарном квантовании.
Обучение представлению в виде матрёшки (MRL)
Метод обучения представлению в виде матрёшки (MRL) подходит к проблеме хранения совершенно с другой стороны. Вместо уменьшения точности отдельных чисел внутри вектора, MRL уменьшает общую размерность самого вектора.
Модели встраивания, поддерживающие MRL, обучаются таким образом, чтобы наиболее важная семантическая информация размещалась в самых ранних измерениях вектора. Подобно русским матрешкам, в честь которых названа эта техника, меньшее, но высокоэффективное представление вкладывается в большее. Это уникальное обучение позволяет инженерам просто усечь (отрезать) хвостовую часть вектора, значительно уменьшив его размерность с минимальным снижением показателей поиска. Например, стандартный 1024-мерный вектор может быть аккуратно усечен до 256, 128 или даже 64 измерений, сохраняя при этом основное семантическое значение. В результате, только эта техника может уменьшить необходимый объем памяти до 16 раз (при переходе от 1024 к 64 измерениям), что напрямую приводит к снижению затрат на инфраструктуру.
Эксперимент
Примечание: Полный, воспроизводимый код для этого эксперимента доступен в репозитории GitHub.
Как MRL, так и квантизация — мощные методы для поиска оптимального баланса между показателями поиска и затратами на инфраструктуру, позволяющие поддерживать прибыльность функций продукта, одновременно обеспечивая высокое качество результатов для пользователей. Чтобы понять точные компромиссы этих методов — и увидеть, что происходит, когда мы расширяем границы их возможностей, комбинируя их, — мы провели эксперимент.
Вот архитектура нашей тестовой среды:
- Векторная база данных: FAISS, в частности, с использованием индекса HNSW (Hierarchical Navigable Small World). HNSW — это алгоритм приближенного поиска ближайших соседей (ANN) на основе графов, широко используемый в векторных базах данных. Хотя он значительно ускоряет поиск, он вносит вычислительные и дисковые затраты для поддержания связей между векторами в графе, что делает оптимизацию больших индексов еще более важной.
- Набор данных: Мы использовали набор данных mteb/hotpotQA (лицензия cc-by-sa-4.0) (доступен через Hugging Face). Это обширная коллекция пар «вопрос/ответ», что делает ее идеальной для измерения показателей поиска в реальных условиях.
- Размер индекса: Чтобы обеспечить легкую воспроизводимость этого эксперимента, размер индекса был ограничен 100 000 документами. Исходная размерность встраивания составляет 384, что обеспечивает отличную базовую величину для демонстрации компромиссов различных подходов.
- Модель встраивания: mixedbread-ai/mxbai-embed-xsmall-v1. Это высокоэффективная, компактная модель с встроенной поддержкой MRL, обеспечивающая отличный баланс между точностью и скоростью поиска.
Результаты оптимизации хранилища

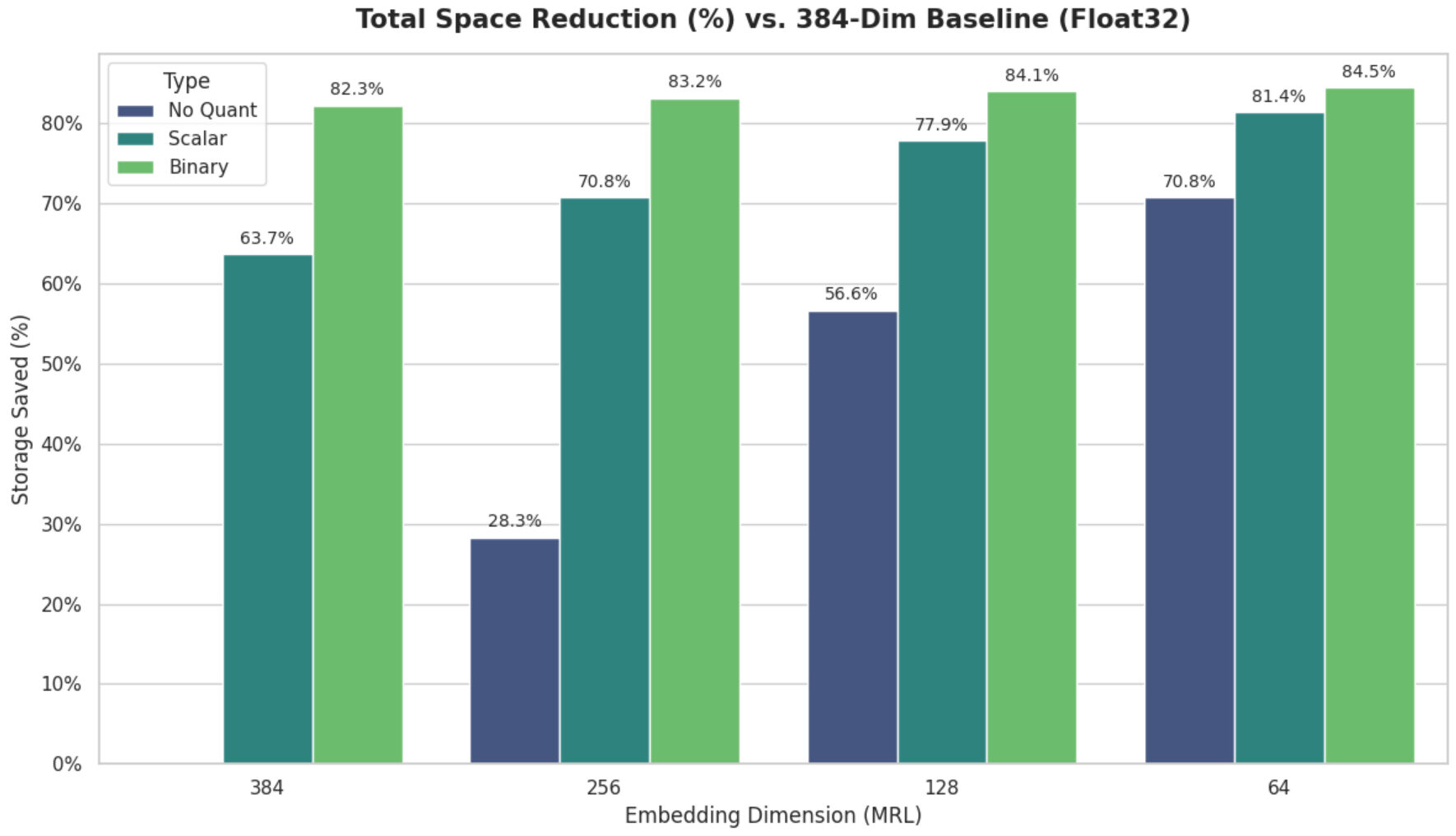
Для сравнения описанных выше подходов мы измерили объем памяти, необходимый для хранения данных, при различных размерностях и методах квантования.
Наш базовый показатель для индекса размером 100 тыс. ячеек (384-мерный, Float32) составлял 172,44 МБ . Сочетание обоих методов позволило добиться значительного сокращения:
| Методы размерности/квантования «матрешки» | Без квантования (f32) | Скаляр (int8) | Двоичное (1-битное) |
| 384 (Оригинал) | 172,44 МБ (ссылка) | 62,58 МБ ( сэкономлено 63,7% ) | 30,54 МБ ( сэкономлено 82,3% ) |
| 256 (MRL) | 123,62 МБ (сэкономлено 28,3%) | 50,38 МБ ( сэкономлено 70,8% ) | 29,01 МБ ( сэкономлено 83,2% ) |
| 128 (MRL) | 74,79 МБ (сэкономлено 56,6%) | 38,17 МБ ( сэкономлено 77,9% ) | 27,49 МБ ( сэкономлено 84,1% ) |
| 64 (MRL) | 50,37 МБ (сэкономлено 70,8%) | 32,06 МБ ( сэкономлено 81,4% ) | 26,72 МБ ( сэкономлено 84,5% ) |
Наши данные показывают, что, хотя каждый метод сам по себе весьма эффективен, их совместное применение приводит к накопительному эффекту в повышении эффективности инфраструктуры:
- Квантование: Переход от Float32 к Scalar (Int8) с исходными 384 размерами мгновенно сокращает объем занимаемого места на 63,7% (с 172,44 МБ до 62,58 МБ) с минимальными усилиями.
- MRL: Использование MRL для усечения векторов до 128 измерений — даже без квантования — обеспечивает существенное сокращение объема занимаемой памяти на 56,6%.
- Совокупный эффект: Применение скалярного квантования к 128-мерному вектору MRL приводит к колоссальному снижению объема на 77,9% (индекс уменьшается до 38,17 МБ). Это означает почти 4,5-кратное увеличение плотности данных при практически нулевых архитектурных изменениях в системе в целом.
Компромисс в отношении точности: сколько мы теряем?

Оптимизация хранилища в конечном итоге представляет собой компромисс. Чтобы понять «стоимость» этих оптимизаций, мы оценили индекс из 100 000 документов, используя тестовый набор из 1000 запросов из набора данных HospotQA. Мы сосредоточились на двух основных метриках для системы поиска:
- Recall@10: Измеряет способность системы включать релевантный документ в любую из 10 лучших результатов. Это критически важный показатель для конвейеров RAG, где LLM выступает в качестве окончательного арбитра.
- Средний обратный ранг (MRR@10): Измеряет качество ранжирования, учитывая позицию релевантного документа. Более высокий MRR указывает на то, что «золотой» документ постоянно находится в самом верху результатов.
| Измерение | Тип | Recall@10 | MRR@10 |
| 384 | Без квантования (f32) | 0,481 | 0,367 |
| Скаляр (int8) | 0,474 | 0,357 | |
| Двоичное (1-битное) | 0,391 | 0,291 | |
| 256 | Без квантования (f32) | 0,467 | 0,362 |
| Скаляр (int8) | 0,459 | 0.350 | |
| Двоичное (1-битное) | 0,359 | 0,253 | |
| 128 | Без квантования (f32) | 0,415 | 0.308 |
| Скаляр (int8) | 0.410 | 0.303 | |
| Двоичное (1-битное) | 0,242 | 0.150 | |
| 64 | Без квантования (f32) | 0,296 | 0,199 |
| Скаляр (int8) | 0.300 | 0,205 | |
| Двоичное (1-битное) | 0.102 | 0,054 |
Как мы видим, разница между Scalar (int8) и No Quantization удивительно мала. При базовом значении в 384 измерения снижение показателя Recall составляет всего 1,46% (с 0,481 до 0,474), а показатель MRR остается практически неизменным, снизившись всего на 2,72% (с 0,367 до 0,357).
В отличие от этого, бинарное квантование (1-битное) представляет собой «резкий спад производительности». При базовом значении в 384 измерения бинарный поиск уже отстает от скалярного более чем на 17% по показателю полноты и на 18,4% по показателю MRR. По мере дальнейшего снижения размерности до 64 точность бинарного поиска падает до незначительного значения 0,102 по показателю полноты, в то время как скалярный поиск сохраняет значение 0,300, что делает его почти в 3 раза эффективнее.
Заключение
Хотя масштабирование векторной базы данных до миллиардов векторов становится все проще, при таком масштабе затраты на инфраструктуру быстро становятся серьезным узким местом. В этой статье я рассмотрел два основных метода снижения затрат — квантование и MRL — для количественной оценки потенциальной экономии и соответствующих компромиссов.
На основе эксперимента установлено, что хранение данных в формате Float32 практически не приносит пользы при использовании многомерных векторов. Как мы видели, применение скалярного квантования приводит к немедленному сокращению объема памяти на 63,7%. Это значительно снижает общие затраты на инфраструктуру при незначительном влиянии на качество поиска — снижение показателя Recall@10 составляет всего 1,46%, а MRR@10 — 2,72%, что демонстрирует, что скалярное квантование является самым простым и эффективным способом оптимизации инфраструктуры, который следует применять практически во всех сценариях использования RAG.
Другой подход заключается в сочетании MRL и квантования. Как показано в эксперименте, комбинация 256-мерного MRL со скалярным квантованием позволяет нам еще больше снизить затраты на инфраструктуру — на 70,8%. В нашем первоначальном примере с 100-миллионным 1024-мерным векторным индексом это может снизить затраты до 50 000 долларов в год, сохраняя при этом высокое качество результатов поиска (снижение показателя Recall@10 всего на 4,6% и MRR@10 на 4,4% по сравнению с базовым вариантом).
Наконец, бинарное квантование: как и ожидалось, оно обеспечивает наиболее значительное сокращение занимаемого пространства, но страдает от резкого падения показателей поиска. В результате гораздо выгоднее применять MRL плюс скалярное квантование для достижения сопоставимого сокращения занимаемого пространства с минимальным снижением точности. На основе эксперимента, использование меньшей размерности (128d) со скалярным квантованием — дающее сокращение занимаемого пространства на 77,9% — является гораздо более предпочтительным, чем использование бинарного квантования на несокращенном 384-мерном индексе, поскольку первый вариант демонстрирует значительно более высокое качество поиска.
| Стратегия | Сохранено хранилище | Recall@10 Retention | MRR@10 Удержание | Идеальный вариант использования |
| 384d + Скаляр (int8) | 63,7% | 98,5% | 97,1% | Критически важная задача RAG, где результат Top 1 должен быть абсолютно точным. |
| 256d + Скаляр (int8) | 70,8% | 95,4% | 95,6% | Наилучшая окупаемость инвестиций: оптимальный баланс для крупномасштабных производственных приложений. |
| 128d + Скаляр (int8) | 77,9% | 85,2% | 82,5% | Поиск с учетом стоимости или двухэтапный поиск (с переранжированием). |
Общие рекомендации по применению в производственной среде:
- Для сбалансированного решения используйте MRL + скалярное квантование . Это обеспечивает значительное сокращение объема оперативной памяти и дискового пространства при сохранении высокого качества результатов поиска.
- Бинарное квантование следует строго использовать в экстремальных ситуациях, когда сокращение объема оперативной памяти/дискового пространства имеет решающее значение, а возникающее при этом низкое качество поиска можно компенсировать увеличением параметра top_k и применением кросс-кодировщика для переранжирования результатов.
Ссылки
[1] Полный код эксперимента : https://github.com/otereshin/matryoshka-quantization-analysis
[2] Модель https://huggingface.co/mixedbread-ai/mxbai-embed-xsmall-v1
[3] Набор данных mteb/hotpotqa https://huggingface.co/datasets/mteb/hotpotqa
[4] FAISS https://ai.meta.com/tools/faiss/
[5] Обучение представлению «матрешки» (MRL): Кусупати, А., Бхатт, Г., Реге, А., Уоллингфорд, М., Синха, А., Рамануджан, В., … и Фархади, А. (2022). Обучение представлению «матрешки».
Олег Терешин Посмотреть все от Олега Терешина
Источник: towardsdatascience.com




















