Трудно усвоенные уроки о том, как масштабировать агентные системы, не усугубляя хаос, включая таксономию основных типов агентов.
Делиться

Незадолго до Рождества 2025 года на arXiv появилась интересная статья под названием « К науке масштабирования агентных систем » , своего рода ранний подарок от команды Google DeepMind. Я нашел эту статью действительно полезной для инженеров и специалистов по обработке данных. Она изобилует конкретными, основанными на измерениях советами и содержит множество выводов, которые можно применить немедленно. Авторы провели масштабное многофакторное исследование, используя огромные вычислительные мощности этих передовых лабораторий, чтобы систематически изменять ключевые параметры проектирования и действительно понять, что влияет на производительность агентных систем.
Как и многие специалисты в области ИИ, я много времени уделяю созданию многоагентных систем (МАС). Это включает в себя разделение сложного многоэтапного рабочего процесса между набором агентов, каждый из которых специализируется на выполнении определенной задачи. В то время как доминирующей парадигмой для чат-ботов на основе ИИ является взаимодействие «запрос-ответ» без предварительного обучения, многоагентные системы (МАС) предлагают более убедительные перспективы: способность автономно «разделять и властвовать» над сложными задачами. Благодаря параллельному выполнению исследований, рассуждений и использованию инструментов, эти системы значительно повышают эффективность по сравнению с монолитными моделями.
Чтобы выйти за рамки простых взаимодействий, исследование DeepMind подчеркивает, что производительность многоагентных систем определяется взаимодействием четырех факторов:
- Количество агентов : число развернутых специализированных подразделений.
- Структура координации : топология (централизованная, децентрализованная и т. д.), определяющая характер их взаимодействия.
- Возможности модели : Базовый уровень интеллекта базовых моделей LLM.
- Свойства задачи : Внутренняя сложность и требования к работе.
Наука масштабирования предполагает, что успех многоагентных систем (МАС) достигается на пересечении количества, топологии, возможностей и сложности задачи. Если мы нарушим этот баланс, то получим скорее шум масштабирования, чем результат. Эта статья поможет вам найти тот самый секретный ингредиент для ваших собственных задач, который позволит вам надежно создать высокопроизводительную и надежную МАС, способную произвести впечатление на ваших заинтересованных сторон.
Убедительный пример недавнего успеха в поиске оптимального баланса для сложной задачи — это работа компании Cursor, разработчика программного обеспечения на основе искусственного интеллекта, создавшей популярную IDE. Они описывают использование большого количества агентов, работающих согласованно, для автоматизации сложных задач в течение длительных периодов времени, включая генерацию значительных объемов кода для создания веб-браузера (код можно посмотреть здесь) и перевод кодовых баз (например, с Solid на React). Их статья о масштабировании агентного ИИ для решения сложных задач в течение нескольких недель вычислений — это увлекательное чтение.
В отчете Cursor говорится, что оперативное проектирование имеет решающее значение для производительности, а конкретная архитектура координации агентов является ключевой. В частности, они отмечают лучшие результаты при структурированном разделении на планировщика и работника, чем при плоском рое (или мешке) агентов. Роль координации особенно интересна, и к этому аспекту проектирования многоагентных систем мы вернемся в этой статье. Подобно тому, как реальные команды получают выгоду от менеджера, команда Cursor обнаружила, что иерархическая структура с планировщиком во главе имеет важное значение. Это работало гораздо лучше, чем хаотичная ситуация, когда агенты выбирают задачи по своему усмотрению. Планировщик обеспечивал контролируемое делегирование и подотчетность, гарантируя, что агенты-работники выполняют правильные подзадачи и обеспечивают конкретный прогресс проекта. Интересно, что они также обнаружили, что важно подобрать правильную модель к правильной, выявив, что GPT-5.2 является лучшим планировщиком и агентом-работником по сравнению с Claude Opus 4.5.
Однако, несмотря на этот первый успех команды Cursor, разработка многоагентных систем в реальном мире по-прежнему находится на грани научных знаний и, следовательно, представляет собой сложную задачу. Многоагентные системы могут быть сложными, с ненадежными результатами, потерями ресурсов из-за координационных разговоров и нестабильной производительностью, которая иногда ухудшается вместо улучшения. Требуется тщательное обдумывание проекта, соотнесение его с особенностями конкретного сценария использования.
При разработке многоагентной системы я постоянно сталкивался с одними и теми же вопросами: когда следует распределять этап между несколькими агентами и какие критерии должны определять это решение? Какую архитектуру координации следует выбрать? При таком множестве вариантов декомпозиции и ролей агентов легко растеряться. Кроме того, как следует оценивать типы доступных агентов и их роли?
Этот разрыв между обещаниями и реальностью делает разработку многоагентных систем такой захватывающей инженерной и аналитической задачей. Надежная работа таких систем и обеспечение ощутимой коммерческой ценности по-прежнему требуют множества проб, ошибок и с трудом выработанной интуиции. Во многом эта область может казаться работой в стороне от проторенных путей, где в настоящее время недостаточно общей теории или стандартной практики.
Эта статья команды DeepMind очень помогает. Она вносит структуру в эту область и, что важно, предлагает количественный способ прогнозирования того, когда та или иная архитектура агента, скорее всего, покажет себя с лучшей стороны, а когда — с меньшей.
В погоне за созданием сложных систем искусственного интеллекта большинство разработчиков попадают в ловушку «мешка агентов», бросая в решение проблемы всё больше и больше LLM-ов и надеясь на появление спонтанного интеллекта. Но, как показывает недавнее исследование DeepMind «Наука масштабирования», мешок агентов — это неэффективная команда, а скорее источник 17,2-кратного увеличения ошибок. Без ограничений формальной топологии, регулирующей взаимодействие агентов, мы в итоге масштабируем шум, а не интеллектуальные возможности, способные решить бизнес-задачу.
Я не сомневаюсь, что освоение стандартизированной структуры многоагентных систем станет следующим мощным техническим преимуществом. Компании, которые смогут быстро преодолеть разрыв между «сложными» автономными агентами и строгими топологиями на основе плоскостей, получат дивиденды в виде чрезвычайной эффективности и высокой точности результатов в масштабах, что обеспечит им огромные конкурентные преимущества на рынке.
Согласно исследованию масштабируемости DeepMind, координация нескольких агентов дает наибольшую отдачу, когда базовый показатель для одного агента ниже 45%. Если ваша базовая модель уже достигает 80%, добавление большего количества агентов может фактически внести больше шума, чем пользы.
В этом посте я обобщил ценные сведения, подобные приведенным выше, в виде руководства, которое поможет вам выстроить правильную ментальную карту для создания наилучших многоагентных систем. Вы найдете золотые правила построения многоагентной системы для конкретной задачи, касающиеся того, каких агентов следует создавать и как их следует координировать. Кроме того, я определю набор из десяти основных архетипов агентов, которые помогут вам составить карту возможностей и упростят выбор правильной конфигурации для вашего случая. Затем я выделю основные уроки проектирования из статьи DeepMind Science of Scaling, используя их, чтобы показать, как эффективно настраивать и координировать этих агентов для различных видов работы.
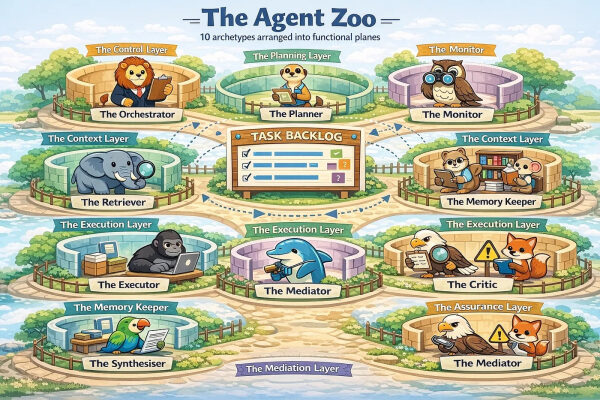
Определение таксономии основных архетипов агентов
В этом разделе мы обозначим пространство проектирования агентов, сосредоточившись на основных типах, доступных для решения сложных задач. Целесообразно свести типы агентов к 10 основным, следуя определениям из обзора автономных агентов Ванга и др. 2023 года: Оркестратор , Планировщик , Исполнитель , Оценщик , Синтезатор, Критик, Извлекатель, Хранитель памяти, Посредник и Монитор. По моему опыту, почти все полезные многоагентные системы могут быть спроектированы с использованием комбинации этих агентов, соединенных вместе в определенную топологию.
На данный момент у нас есть лишь общая совокупность различных типов агентов, и полезно иметь мысленную точку отсчета для их группировки и применения. Мы можем организовать этих агентов с помощью двух взаимодополняющих подходов: статической архитектуры функциональных плоскостей управления и динамического цикла выполнения «Планирование–Выполнение–Проверка» . Можно представить это так: плоскости управления обеспечивают структуру, а цикл выполнения управляет рабочим процессом.
- Планирование: Оркестратор (управляющая плоскость) определяет общую цель и ограничения. Он делегирует задачи Планировщику, который декомпозирует цель на граф задач, отображая зависимости, приоритеты и этапы. По мере появления новой информации Оркестратор динамически корректирует и пересматривает этот план.
- Действие: Исполнитель преобразует абстрактные задачи в ощутимые результаты (артефакты, изменения кода, решения). Для обеспечения обоснованности и эффективности этой работы, Извлекающий объект (контекстная плоскость) предоставляет Исполнительу контекст в режиме реального времени, например, соответствующие файлы, документацию или предыдущие данные.
- Проверка: Это контроль качества. Оценщик проверяет результаты на соответствие объективным критериям приемлемости, а Критик выявляет субъективные недостатки, такие как крайние случаи или скрытые предположения. Обратная связь поступает обратно к Планировщику для дальнейшей доработки. Одновременно Монитор следит за состоянием системы — отслеживает отклонения, задержки или скачки бюджета — и готов инициировать сброс, если цикл нарушится.

Как показано на нашей многоагентной когнитивной архитектуре (рис. 2), эти специализированные агенты расположены в горизонтальных плоскостях управления, которые группируют возможности по функциональной ответственности. Такая структура преобразует хаотичный «набор агентов» в высокоточную систему за счет разделения потока информации на отсеки.
Чтобы обосновать эти технические аспекты, мы можем расширить нашу аналогию с рабочим местом человека, чтобы определить, как функционируют эти самолеты:
Уровень управления — Управление
- Оркестратор: Представьте его как руководителя проекта. Он отвечает за общую цель. Он не пишет код и не ищет информацию в интернете; его задача — делегировать. Он решает, кто что будет делать дальше.
- Монитор: Это ответственный за охрану труда и технику безопасности. Он следит за Оркестратором. Если агент застревает в цикле, тратит слишком много денег (токенов) или отклоняется от первоначальной цели, Монитор включает аварийный тормоз или подает сигнал тревоги.
Уровень планирования — Стратегия
- Планировщик: Прежде чем действовать, агент должен подумать. Планировщик берет цель Организатора и разбивает ее на составляющие.
- Граф задач / Список задач (артефакт): это «список дел». Он динамический — по мере того, как агент узнает что-то новое, шаги могут добавляться или удаляться. Планировщик постоянно обновляет этот граф, чтобы оркестратор знал, какие шаги можно предпринять дальше.
Контекстный слой — Память
- «Извлекатель»: Библиотекарь. Он получает конкретную информацию (документацию, предыдущий код), необходимую для выполнения текущей задачи.
- Хранитель памяти: Архивариус. Не всё нужно запоминать. Эта роль обобщает (сжимает) произошедшее и определяет, что достаточно важно для хранения в Контекстном хранилище на долгосрочную перспективу.
Исполнительный уровень — Работники
- Исполнитель: Специалист. Он действует в соответствии с планом. Он пишет код, вызывает API или генерирует текст.
- Синтезатор: Редактор. Результат работы исполнителя может быть неаккуратным или слишком многословным. Синтезатор очищает его и форматирует в понятный результат для проверки оркестратором.
Уровень обеспечения качества — Контроль качества
- Оценщик: Проверяет объективную корректность. (например, «Компилировался ли код?», «Соответствует ли вывод схеме JSON?»).
- Критик: Проверяет наличие субъективных рисков или особых случаев (например, «Этот код работает, но имеет уязвимость в системе безопасности» или «Эта логика ошибочна»).
- Петли обратной связи (пунктирные стрелки): Обратите внимание на пунктирные линии, идущие обратно к планировщику на рисунке 2. Если уровень обеспечения качества не справляется с работой, агент обновляет план, чтобы исправить обнаруженные ошибки.
Посреднический уровень — разрешение конфликтов
- Посредник: Иногда оценщик говорит «Пройдено», а критик — «Не пройдено». Или, возможно, планировщик хочет сделать что-то, что наблюдатель считает рискованным. Посредник выступает в роли решающего звена, предотвращающего застревание системы в тупике.

Чтобы увидеть эти архетипы в действии, мы можем отследить один запрос в системе. Представьте, что мы отправляем следующее задание: «Написать скрипт для сбора данных о ценах с сайта конкурента и сохранения их в нашей базе данных». Запрос не просто поступает к «работнику»; он запускает скоординированную последовательность действий на всех функциональных уровнях.
Шаг 1: Инициализация — полоса управления
Организатор получает задачу. Он проверяет ее «контрольные точки» (например, «Есть ли у нас разрешение на сбор данных? Какой бюджет?»).
- Действие: Оно передает цель Планировщику.
- Монитор запускает «секундомер» и «счетчик токенов», чтобы убедиться, что агент не потратит 50 долларов, пытаясь спарсить сайт стоимостью 5 долларов.
Шаг 2: Декомпозиция — Планирование
Планировщик понимает, что на самом деле это четыре подзадачи: (1) Исследование структуры сайта, (2) Написание парсера, (3) Составление схемы данных, (4) Написание логики для загрузки данных в базу данных.
- Действие: Программа заполняет граф задач/бэклог этими шагами и определяет зависимости (например, вы не можете составить схему, пока не изучите сайт).
Шаг 3: Закрепление — Контекстная дорожка
Перед началом работы обработчик обращается к хранилищу контекста.
- Действие: Программа извлекает наши «Документы по схеме базы данных» и «Рекомендации по сбору данных» и передает их исполнителю .
- Это предотвращает «галлюцинации» агента, связанные с несуществующей структурой базы данных.
Шаг 4: Производство — Этап выполнения
Исполнитель пишет код на Python для шагов 1 и 2.
- Действие: Код помещается в рабочую область / выходные данные.
- Синтезатор может взять этот необработанный код и обернуть его в «Обновление статуса» для оркестратора, сообщая: «У меня есть черновой вариант скрипта, готовый к проверке».
Шаг 5: «Испытательный период» — Заверение
Именно здесь вступают в действие пунктирные линии обратной связи:
- Программа-оценщик запускает код. Она завершается с ошибкой 403 Forbidden (бот, блокирующий сбор данных). Она отправляет в планировщик пунктирную стрелку: «Целевой сайт заблокировал нас; нам нужна стратегия ротации заголовков».
- Критик изучает код и видит, что пароль к базе данных жестко закодирован. Он отправляет в Планировщик пунктирную стрелку: «Риск безопасности: учетные данные должны быть переменными среды».
Шаг 6: Конфликт и его разрешение — Посредничество
Представьте, что Планировщик пытается устранить проблему безопасности, выявленную Критиком, но Оценщик говорит, что новый код теперь нарушает соединение с базой данных. Они застряли в замкнутом круге.
- Действие: Посредник вмешивается, рассматривает два противоречащих друг другу «мнения» и принимает решение: «Приоритет — исправление безопасности; я дам указание Планировщику добавить отдельный шаг для отладки подключения к базе данных».
- Оркестратор получает это решение и обновляет состояние.
Шаг 7: Окончательная доставка
Цикл повторяется до тех пор, пока и оценщик (код работает), и критик (код безопасен) не выдадут оценку «Пройдено».
- Действие: Синтезатор принимает окончательный, проверенный код и возвращает его пользователю.
- Memory Keeper суммирует сообщение об ошибке «403 Forbidden» и сохраняет его в Context Store, чтобы в следующий раз, когда агенту будет предложено спарсить сайт, он помнил о необходимости использовать header-rotation с самого начала.
Основные архетипы инструментов: 10 строительных блоков надежных агентных систем
Подобно тому, как мы определили общие архетипы агентов, мы можем провести аналогичное исследование и для их инструментов. Архетипы инструментов определяют, как эта работа строится, выполняется и проверяется, а также какие режимы отказов сдерживаются по мере масштабирования системы.

Как показано на рисунке 5 выше, инструменты поиска могут предотвратить галлюцинации, принудительно предоставляя доказательства; валидаторы схем и тестовые стенды предотвращают скрытые сбои, делая корректность машинной проверкой; бюджетные счетчики и наблюдаемость предотвращают неконтролируемые циклы, выявляя (и ограничивая) расходование и изменение токенов; а шлюзы разрешений и песочницы предотвращают опасные побочные эффекты, ограничивая действия агентов в реальном мире.
Антипаттерн «Мешок агентов»
Прежде чем рассматривать законы масштабирования агентного взаимодействия, полезно определить антипаттерн, который в настоящее время тормозит большинство развертываний агентного ИИ и который мы стремимся улучшить: «набор агентов». В этой наивной схеме разработчики используют множество агентов с низкой степенью свободы для решения проблемы без формальной топологии, в результате чего система обычно демонстрирует три фатальные характеристики:
- Плоская топология: у каждого агента есть открытая связь с каждым другим агентом. Нет иерархии, нет привратников и нет специализированных плоскостей для разделения потока информации.
- Шумный диалог: Без координатора агенты попадают в замкнутый круг логики или «петли галлюцинаций», где они повторяют и подтверждают ошибки друг друга, вместо того чтобы исправлять их.
- Выполнение с открытым циклом: информация беспрепятственно циркулирует внутри группы. Отсутствует выделенный уровень контроля (оценщики или критики), который бы проверял данные до того, как они достигнут следующего этапа рабочего процесса.
Если использовать аналогию с рабочим процессом: переход от «сумки» к «системе» — это тот же самый скачок, который совершает стартап, когда нанимает своего первого менеджера. Команды на ранних этапах быстро понимают, что численность персонала не равна производительности без организационной структуры, которая бы её контролировала. Как выразился Брукс в книге «Мифический человеко-месяц»: «Добавление рабочей силы в затянувшийся программный проект ещё больше затянет его».
Но сколько структуры достаточно?
Ответ кроется в законах масштабирования субъектности из статьи DeepMind. Это исследование раскрывает точные математические компромиссы между добавлением большего количества «мозгов» LLM и возрастающим трением в их координации.
Законы масштабирования субъектности: координация, топология и компромиссы.
Главный вывод статьи «Наука масштабирования агентных систем» заключается в том, что увеличение количества агентов не является панацеей для повышения производительности. Скорее, существует строгий компромисс между затратами на координацию и сложностью задачи. Без продуманной топологии добавление агентов подобно добавлению инженеров к проекту без руководителя: как правило, вы не получите более ценного результата; скорее всего, вы получите больше совещаний, нецеленаправленной и потенциально бесполезной работы и шумных разговоров.

Экспериментальная установка для оценки MAS
Команда DeepMind оценила свои многоагентные системы в четырех наборах задач и протестировала разработанные агенты на совершенно разных рабочих нагрузках, чтобы избежать привязки выводов к конкретным задачам или эталонным показателям:
- BrowseComp-Plus (2025): Просмотр веб-страниц / поиск информации, рассматриваемый как поиск информации на нескольких веб-сайтах — тест на поиск, навигацию и сбор доказательств.
- Финансовый агент (2025): Задания по финансам, разработанные для имитации работы аналитика начального уровня — проверяют структурированное мышление, количественную интерпретацию и поддержку принятия решений.
- PlanCraft (2024): Планирование действий агента в среде Minecraft — классическая схема долгосрочного планирования с учетом состояния, ограничений и последовательности действий.
- WorkBench (2024): Планирование и выбор инструментов для типичных бизнес-задач — проверяет, могут ли агенты выбирать инструменты/действия и выполнять практические рабочие процессы.
В работе «К науке масштабирования агентных систем» рассматриваются пять топологий координации: одноагентная система (SAS) и четыре многоагентные системы (MAS) — независимая, децентрализованная, централизованная и гибридная. Топология имеет значение, поскольку она определяет, приводит ли добавление агентов к полезной параллельной работе или просто к увеличению объема коммуникации.
- SAS (Single Agent): Один агент выполняет все действия последовательно. Минимальные затраты на координацию, но ограниченный параллелизм.
- Многоагентная система (независимая): множество агентов работают параллельно, затем результаты синтезируются в окончательный ответ. Эффективна для широкого охвата (исследования, генерация идей), менее эффективна для тесно связанных цепочек рассуждений.
- MAS (децентрализованная система): Агенты обсуждают решения в несколько раундов и принимают их большинством голосов. Это может повысить устойчивость системы, но объем передаваемой информации быстро растет, и ошибки могут накапливаться из-за повторных перекрестных обсуждений.
- MAS (Централизованная система): Один координатор управляет работой специализированных суб-агентов. Такая структура «менеджер + команда» обычно более стабильна в масштабе, поскольку ограничивает обмен информацией и исключает возможные сбои.
- MAS (гибридная система): централизованная оркестрация плюс целевой обмен данными между узлами сети. Более гибкая, но и наиболее сложная в управлении, а также наиболее легко поддающаяся избыточному развертыванию.

Такая формулировка также проясняет, почему неструктурированные схемы «набора агентов» могут быть очень опасными. Ким и др. сообщают об усилении ошибок до 17,2 раз в плохо скоординированных сетях, в то время как централизованная координация ограничивает это усиление примерно до 4,4 раз, действуя как автоматический выключатель.
Важно отметить, что в статье показано, что эта динамика зависит от используемого эталонного показателя.
- В модели Finance-Agent (с высокой степенью декомпозируемости финансовых рассуждений) MAS обеспечивает наибольший прирост производительности — централизованная модель +80,8%, децентрализованная +74,5%, гибридная +73,1% по сравнению с SAS — поскольку агенты могут разделять работу на параллельные аналитические потоки, а затем синтезировать результаты.
- В BrowseComp-Plus (динамическая веб-навигация и синтез) улучшения незначительны и зависят от топологии сети: децентрализованная модель показывает наилучшие результаты (+9,2%), в то время как централизованная практически не меняется (+0,2%), а независимая может резко ухудшиться (−35%) из-за неконтролируемого распространения сигнала и помех от перекрестных помех.
- Показатель Workbench находится посередине, демонстрируя лишь незначительные изменения (примерно от -11% до +6% в целом; Decentralised +5,7%), что указывает на почти сбалансированное соотношение между выгодой от оркестровки и налогом на координацию.
- А в PlanCraft (строго последовательное планирование, зависящее от состояния) каждый вариант MAS ухудшает производительность (примерно от -39% до -70%), поскольку накладные расходы на координацию расходуют бюджет, не обеспечивая реального преимущества параллельного выполнения.
Практическое решение заключается в том, чтобы структурировать вашу многоагентную систему, сопоставив агентов с функциональными плоскостями и используя централизованное управление для подавления распространения ошибок и разрастания координации.
Это подводит нас к главному вкладу данной работы: законам масштабирования субъектности.
Законы масштабирования агентности
На основе результатов исследования Кима и др. можно вывести три золотых правила для построения эффективной архитектуры координации действий агентов:
- Правило 17x: Неструктурированные сети экспоненциально увеличивают ошибки. Наша централизованная плоскость управления (оркестратор) подавляет это, выступая в качестве единой точки проверки.
- Компромисс между координацией инструментов: чем больше инструментов, тем больше опоры. Наша плоскость контекста (Retriever) гарантирует, что агенты не будут «угадывать», как использовать инструменты, уменьшая лишнюю информацию, которая приводит к избыточным затратам.
- Точка насыщения в 45%: координация агентов дает наилучшие результаты, когда производительность одного агента низка. По мере того, как модели становятся умнее, мы должны полагаться на агента-монитора, чтобы упростить топологию и избежать ненужной сложности.

По моему опыту, слой обеспечения качества часто является наиболее значимым фактором повышения производительности многоагентных систем (МАС). Цикл «Обеспечение качества → Планирование» преобразует нашу МАС из системы с разомкнутым контуром (запустил и забыл) в систему с замкнутым контуром (самокорректирующуюся), которая предотвращает распространение ошибок и позволяет масштабировать интеллектуальные функции для решения более сложных задач.
Команды агентов смешанных моделей: когда гетерогенные LLM помогают (и когда они вредят)
Команда DeepMind целенаправленно тестирует гетерогенные команды, иными словами, использует разные базовые модели LLM для оркестратора и для субагентов, а также возможности смешивания в децентрализованных дебатах. Полученные здесь уроки очень интересны с практической точки зрения. Они сообщают о трех основных результатах (показанных на примере задачи/набора данных BrowseComp-Plus):
- Централизованная MAS: смешение может как помочь, так и навредить в зависимости от семейства моделей.
- В случае с Anthropic, команда с низким уровнем квалификации координатора и высококвалифицированными суб-агентами превосходит централизованную команду, состоящую исключительно из высококвалифицированных специалистов (0,42 против 0,32, +31%).
- В случае OpenAI и Gemini гетерогенные централизованные системы демонстрируют худшие результаты по сравнению с однородными высокопроизводительными системами.
Вывод: слабый оркестратор может стать узким местом в некоторых семействах процессов, даже если рабочие процессы мощные (потому что это узкое место маршрутизации/синтеза).
2. Децентрализованные многоагентные системы: дискуссия о смешанных возможностях оказалась на удивление активной.
- Децентрализованные дискуссии с участием систем смешанного уровня возможностей являются почти оптимальными, а иногда и лучше, чем однородные базовые модели с высоким уровнем возможностей (приводятся примеры: OpenAI 0,53 против 0,50; Anthropic 0,47 против 0,37; Gemini 0,42 против 0,43).
Вывод: голосование/взаимная проверка могут «усреднить» результаты более слабых агентов, поэтому неоднородность оказывает меньшее влияние, чем можно было бы ожидать.
3. В централизованных системах возможности суб-агентов имеют большее значение, чем возможности оркестратора.
Во всех семействах конфигураций высокопроизводительные субагенты показывают лучшие результаты, чем конфигурации с высокопроизводительными оркестраторами.
Главный практический вывод команды DeepMind заключается в том, что если вы тратите деньги избирательно, то тратьте их на работников (субъектов, производящих контент), не обязательно на менеджера, а проводите валидацию на основе вашей модели, поскольку модель «дешевый координатор + сильные работники» не является универсальной.
Понимание стоимости многоагентной системы
Часто задаваемый вопрос — как определить стоимость многоагентной системы (МАС), то есть бюджет токенов, который в конечном итоге конвертируется в доллары. Топология определяет, приводит ли добавление агентов к параллельной работе или просто к увеличению объема коммуникаций. Чтобы сделать стоимость более наглядной, мы можем смоделировать ее с помощью небольшого набора параметров:
- k = максимальное количество итераций на одного агента (сколько шагов планирования/действия/анализа разрешено каждому агенту).
- n = количество агентов (сколько «работников» мы запускаем).
- r = количество раундов оркестровки (сколько циклов назначения → сбора → пересмотра мы запускаем)
- d = количество раундов дебатов (сколько раундов обмена мнениями до голосования/принятия решения)
- p = количество раундов общения между участниками (как часто агенты общаются напрямую друг с другом)
- m = среднее количество запросов от других участников за раунд (количество сообщений, отправляемых каждым агентом за один раунд).
Практический способ оценить общую стоимость выглядит следующим образом:
Общая стоимость MAS ≈ Стоимость работ + Стоимость координации
- Стоимость выполнения работы определяется главным образом величиной n × k (количество запущенных агентов и количество шагов, которые выполняет каждый из них).
- Стоимость координации определяется произведением количества раундов на коэффициент разветвления, то есть, сколько раз мы перекоординируемся (r, d, p), умноженным на количество обмененных сообщений (n, m) — плюс скрытая плата за то, что агентам приходится читать весь этот дополнительный контекст.
Чтобы перевести это в доллары, сначала используйте параметры ( n, k, r, d, p, m ), чтобы оценить общее количество сгенерированных и потребленных входных/выходных токенов, а затем умножьте на цену одного токена в вашей модели:
Стоимость ≈ (Входные токены ÷ 1 млн × $/1 млн_входных данных) + (Выходные токены ÷ 1 млн × $/1 млн_выходных данных)
Где:
- В состав InputTokens входит все, что читают агенты (общая стенограмма, полученные документы, результаты работы инструментов, сообщения других агентов).
- В OutputTokens содержится все, что пишут агенты (планы, промежуточные рассуждения, сообщения для обсуждения, окончательный вывод).
Вот почему децентрализованные и гибридные топологии могут очень быстро стать дорогими: обсуждения и обмен сообщениями между участниками сети увеличивают как объем сообщений, так и длину контекста, поэтому мы платим вдвое больше, поскольку агенты генерируют больше текста, и каждому приходится читать больше текста. На практике, как только агенты начинают широко общаться друг с другом, координация может начать ощущаться как эффект n².
Главный вывод заключается в том, что масштабирование агентов полезно только в том случае, если задача выигрывает от параллелизма больше, чем теряет из-за накладных расходов на координацию. Следует использовать больше агентов, когда работу можно легко распараллелить (исследование, поиск, независимые попытки решения). И наоборот, следует проявлять осторожность, когда задача является последовательной и тесно связанной (многоэтапное рассуждение, длинные цепочки зависимостей), поскольку дополнительные раунды и перекрестные помехи могут нарушить логическую цепочку и превратить «большее количество агентов» в «больше шума».
Закон масштабирования архитектуры MAS: переход от исчерпывающего подхода к проектированию MAS, основанному на данных, к подходу, основанному на анализе данных.
Естественно возникает вопрос, существуют ли в многоагентных системах «законы масштабирования архитектуры», аналогичные эмпирическим законам масштабирования параметров LLM. Ким и др. утверждают, что ответ — да. Для решения задачи комбинаторного поиска — топология × количество агентов × раунды × семейство моделей — они оценили 180 конфигураций на четырех тестовых наборах данных, а затем обучили прогностическую модель на основе траекторий координации (например, эффективность против накладных расходов, усиление ошибок, избыточность). Модель может предсказать, какая топология, вероятно, покажет наилучшие результаты, достигнув R² ≈ 0,513 и выбрав наилучшую стратегию координации примерно для 87% отложенных конфигураций. Практический сдвиг заключается в переходе от «пробовать все» к запуску небольшого набора коротких тестовых конфигураций (гораздо дешевле и быстрее), измерению динамики координации на ранних этапах и только затем выделению полного бюджета на архитектуры, которые, по прогнозам модели, будут победными.
Выводы и заключительные мысли
В этой статье мы рассмотрели работу DeepMind «К науке масштабирования агентных систем» и выделили наиболее практические уроки для создания более высокопроизводительных многоагентных систем. Эти правила проектирования помогают нам избежать бесплодных попыток и надежды на лучшее. Главный вывод заключается в том, что большее количество агентов не гарантирует лучших результатов. Масштабирование агентов предполагает реальные компромиссы, регулируемые измеримыми законами масштабирования, и «правильное» количество агентов зависит от сложности задачи, возможностей базовой модели и организации системы.
Вот что показывают исследования относительно количества агентов:
- Эффект убывающей отдачи (насыщение): добавление агентов не приводит к неограниченному приросту эффективности. Во многих экспериментах производительность сначала возрастает, затем стабилизируется — часто примерно при 4 агентах — после чего добавление агентов мало что меняет.
- «Правило 45%»: дополнительные агенты наиболее эффективны, когда базовая модель плохо справляется с задачей (ниже ~45%). Если же базовая модель уже сильна, добавление агентов может привести к насыщению возможностей, когда производительность стагнирует или становится нестабильной, а не улучшается.
- Топология имеет значение: одних лишь количественных показателей недостаточно; организация определяет результаты.
- Централизованные решения, как правило, масштабируются более надежно, а оркестратор помогает предотвращать ошибки и обеспечивать структурированность.
- Децентрализованные модели, основанные на принципе «набора агентов», могут стать нестабильными по мере роста группы, иногда усугубляя ошибки вместо того, чтобы совершенствовать логическое мышление.
- Параллельная и последовательная работа: большее количество агентов наиболее эффективно при выполнении задач, допускающих параллельное выполнение (например, масштабные исследования), где они могут существенно увеличить охват и пропускную способность. Однако при последовательном рассуждении добавление агентов может ухудшить производительность, поскольку «логическая цепочка» ослабевает при прохождении через слишком большое количество шагов.
- Налог на координацию: каждый дополнительный агент увеличивает накладные расходы. Больше сообщений, больше задержка, больше возможностей для отклонения от заданного пути. Если задача недостаточно сложна, чтобы оправдать эти накладные расходы, затраты на координацию перевешивают преимущества дополнительных «мозгов» LLM.
Руководствуясь этими «золотыми правилами агентной деятельности» , я хочу в заключение пожелать вам всего наилучшего в создании вашей многоагентной системы. Многоагентные системы находятся на самом переднем крае современного прикладного ИИ, готовые принести новый уровень бизнес-ценности в 2026 году — и они сопряжены с такими техническими компромиссами, которые делают эту работу по-настоящему интересной: баланс между возможностями, координацией и проектированием для достижения надежной работы. Создавая свою собственную многоагентную систему, вы, несомненно, откроете для себя свои собственные «золотые правила», которые расширят наши знания на этой неизведанной территории.
В заключение о пороге «45%» от DeepMind: многоагентные системы во многом являются обходным путем для преодоления ограничений современных моделей с низкой точностью. По мере того, как базовые модели становятся более совершенными, все меньше задач будет находиться в режиме низкой точности, где дополнительные агенты приносят реальную пользу. Со временем нам может потребоваться меньше декомпозиции и координации, и больше проблем может быть решено одной моделью от начала до конца, по мере того, как мы движемся к искусственному общему интеллекту (AGI).
Перефразируя Толкина: возможно, одна модель станет единственной, которая превзойдёт все остальные.
📚 Дальнейшее обучение
- Юбин Ким и др. (2025) — На пути к науке масштабирования агентных систем — Крупное контролируемое исследование, в котором выводятся количественные принципы масштабирования для агентных систем в различных топологиях координации, семействах моделей и эталонных задачах (включая эффекты насыщения и накладные расходы на координацию).
- Команда Cursor (2026) — Масштабирование долгосрочного автономного программирования — Практическое исследование, описывающее, как Cursor координирует работу большого количества агентов программирования в течение длительных циклов (включая их эксперимент по созданию веб-браузера) и что это означает для топологий типа «планировщик-работник».
- Лей Ван и др. (2023) — Обзор автономных агентов на основе больших языковых моделей — Комплексный обзор, отображающий пространство проектирования агентов (планирование, память, инструменты, модели взаимодействия), полезный для обоснования вашей таксономии из 10 архетипов на основе предыдущей литературы.
- Цинъюнь У и др. (2023) — AutoGen: Обеспечение работы приложений LLM следующего поколения посредством многоагентного диалога — Статья, описывающая структуру программирования многоагентных диалогов и моделей взаимодействия, с эмпирическими результатами по различным задачам и конфигурациям агентов.
- Шунью Яо и др. (2022) — ReAct: Синергия рассуждений и действий в языковых моделях — Представляет собой чередующийся цикл «разум + действие», лежащий в основе многих современных конструкций агентов, использующих инструменты, и помогает уменьшить галлюцинации посредством обоснованных действий.
- Ноа Шинн и др. (2023) — Рефлексия: Языковые агенты с вербальным обучением с подкреплением — Чистый шаблон для улучшения с обратной связью: агенты анализируют обратную связь и сохраняют «извлеченные уроки» в памяти для улучшения последующих попыток без обновления весов.
- LangChain (nd) — Многоагентная архитектура — Практическая документация, охватывающая распространенные шаблоны многоагентной архитектуры и способы структурирования взаимодействия для предотвращения неконтролируемого «общения между множеством агентов».
- LangChain (nd) — Обзор LangGraph — Подробный обзор функций оркестровки, важных для реальных систем (устойчивое выполнение, участие человека, потоковая передача и управление потоком выполнения).
- langchain-ai (nd) — LangGraph (репозиторий GitHub) — Эталонная реализация слоя оркестровки на основе графов, полезная, если читатели хотят изучить конкретные проектные решения и примитивы для агентов с сохранением состояния.
- Фредерик П. Брукс-младший (1975) — Мифический человеко-месяц — Классический урок координации (закон Брукса), который на удивление хорошо применим к агентным системам: добавление большего количества «работников» может увеличить накладные расходы и замедлить прогресс без правильной структуры.
Источник: towardsdatascience.com











![Кадр из фильма с мужчиной в форме, текст: "Вы ведь включали сегодня [ценз], верно?"](https://ideipro.ru/wp-content/uploads/2026/03/file_1882.jpg)