Как команды по продукту, развитию и разработке могут объединиться на основе единого сигнала для лучшего управления инцидентами
Делиться

Введение
Для SaaS-компаний (программное обеспечение как услуга) мониторинг и управление данными о продуктах критически важны. Те, кто не понимает этого, к тому времени, как заметят инцидент, ущерб уже будет нанесен. Для компаний, находящихся в затруднительном положении, это может иметь фатальные последствия .
Чтобы предотвратить это, я создал рабочий процесс n8n, связанный с их базой данных. Он будет ежедневно анализировать данные и выявлять любые инциденты. В этом случае система регистрации и уведомлений начнет расследование как можно скорее. Я также создал панель управления, чтобы команда могла видеть результаты в режиме реального времени.

Контекст
B2B SaaS-платформа, специализирующаяся на визуализации данных и автоматизированной отчетности, обслуживает около 4500 клиентов, распределенных по трем сегментам:
- Малый бизнес
- Средний рынок
- Предприятие
Еженедельное использование продукта превышает 30 000 активных учетных записей с сильной зависимостью от данных в реальном времени (конвейеры, API, панели мониторинга, фоновые задания).
Команда разработчиков тесно сотрудничает с:
- Рост (приобретение, активация, адаптация)
- Доход (ценообразование, ARPU, отток)
- SRE/Инфраструктура (надежность, доступность)
- Инженерия данных (конвейеры, актуальность данных)
- Поддержка и успех клиентов

В прошлом году компания отметила рост числа инцидентов. С октября по декабрь общее количество инцидентов увеличилось с 250 до 450, увеличившись на 80% . В результате этого роста было зарегистрировано более 45 инцидентов высокого и критического уровня, затронувших тысячи пользователей. Наиболее пострадавшие показатели:
- api_error_rate
- checkout_success_rate
- net_mrr_delta
- data_freshness_lag_minutes
- отток_темп

Когда происходят инциденты, клиенты судят о компании по тому, как она справляется с ними и реагирует. В то же время, команда разработчиков продукта ценится за то, как они справились с ситуацией и гарантировали, что подобное не повторится.
Инцидент может произойти один раз, но повторение одного и того же инцидента дважды является ошибкой.
Влияние на бизнес
- Большая волатильность чистого регулярного дохода
- Заметное снижение количества активных аккаунтов в течение нескольких последовательных недель
- Множество корпоративных клиентов сообщают и жалуются на устаревшую панель управления (с опозданием до 45 минут и более)

В общей сложности это затронуло от 30 000 до 60 000 пользователей. Также пострадало доверие клиентов к надёжности продукта. 45% опрошенных указали, что это основная причина отказа от продления .
Почему этот вопрос имеет решающее значение?
Как платформа данных, компания не может позволить себе иметь:
- медленные или устаревшие данные
- Ошибка API
- Аварии трубопроводов
- Пропущенные или отложенные синхронизации
- Неточная панель инструментов
- Оттоки (понижения, отмены)

Внутри компании инциденты были распределены по нескольким системам:
- Понятия для отслеживания продукта
- Slack для оповещений
- PostgreSQL для хранения
- Даже в Google Таблицах для поддержки клиентов

Не было единого источника достоверной информации. Продуктовой команде приходилось вручную сверять и перепроверять все данные, выявляя тенденции и собирая их воедино. Это было похоже на расследование и решение головоломки, из-за чего они теряли много часов еженедельно.
Решение : автоматизация оповещения об инцидентах с помощью N8N и создание панели данных. Это позволяет выявлять, отслеживать, устранять и анализировать инциденты.
Почему n8n?
В настоящее время существует множество платформ и решений для автоматизации. Но не все они соответствуют потребностям и требованиям. Выбор правильного решения, соответствующего потребностям, крайне важен.
Конкретные требования включали доступ к базе данных без API (n8n поддерживает API), визуальные рабочие процессы и узлы, понятные даже неспециалисту, возможность самостоятельного кодирования узлов, возможность размещения на собственном сервере и экономичность при масштабировании. Поэтому среди существующих платформ, таких как Zapier, Make или n8n, выбор пал на последнюю.
Разработка оценки состояния продукта

Во-первых, необходимо определить и рассчитать ключевые показатели.
Оценка воздействия : простая функция серьезности + дельта + шкала пользователей
impact_score = ( difficulty_weights[severity] * 10 + abs(delta_pct) * 0.8 + np.log1p(affected_users)) impact_score = round(float(impact_score), 2)
Приоритет : определяется серьезностью + воздействием
если уровень серьезности == «критический» или показатель_воздействия > 60: приоритет = «P1» elif уровень серьезности == «высокий» или показатель_воздействия > 40: приоритет = «P2» elif уровень серьезности == «средний»: приоритет = «P3» иначе: приоритет = «P4»
Оценка состояния продукта
def compute_product_health_score(incidents, metrics): «»» Оценка = 100 — сумма(штрафы) Производственная версия обрабатывает 15+ факторов «»» # Ключевая информация: штрафы имеют разные максимальные веса штрафы = { 'volume': min(40, incident_rate * 13), # 40% макс 'severity': calculate_severity_sum(incidents), # 25% макс 'users': min(15, log(users) / log(50000) * 15), # 15% макс 'trends': calculate_business_trends(metrics) # 20% макс } оценка = 100 — сумма(штрафы.values()) if оценка >= 80: return оценка, «🟢 Стабильно» elif оценка >= 60: return оценка, «🟡 Под наблюдением» else: return оценка, «🔴 Под угрозой»
Проектирование автоматизированной системы обнаружения с помощью n8n

Эта система состоит из 4 потоков :
- Поток 1 : извлекает последние показатели доходов, выявляет необычные всплески оттока MRR и создает инциденты при необходимости.

const rows = items.map(item => item.json); if (rows.length < 8) { return []; } rows.sort((a, b) => new Date(a.date) — new Date(b.date)); const values = rows.map(r => parseFloat(r.churn_mrr || 0)); const lastIndex = rows.length — 1; const lastRow = rows[lastIndex]; const lastValue = values[lastIndex]; const window = 7; const baselineValues = values.slice(lastIndex — window, lastIndex); const mean = baselineValues.reduce((s, v) => s + v, 0) / baselineValues.length; const дисперсия = baselineValues.map(v => Math.pow(v — среднее, 2)) .reduce((s, v) => s + v, 0) / baselineValues.length; const std = Math.sqrt(дисперсия); если (std === 0) { return []; } const z = (lastValue — среднее) / std; const deltaPct = среднее === 0 ? null : ((lastValue — среднее) / среднее) * 100; если (z > 2) { const аномалия = { date: lastRow.date, metric_name: 'churn_mrr', baseline_value: среднее, actual_value: lastValue, z_score: z, delta_pct: deltaPct, intensity: deltaPct !== null && deltaPct > 50 ? 'высокий' : deltaPct !== null && deltaPct > 25 ? 'средний' : 'низкий', }; return [{ json: anomaly }]; } return [];
- Поток 2 : Мониторы предоставляют метрики использования для обнаружения внезапных спадов в принятии или вовлеченности.
Инциденты регистрируются с указанием степени серьезности, контекста и оповещением группы разработчиков продукта.

- Поток 3 : для каждого открытого инцидента собирает дополнительный контекст из базы данных (например, отток по стране или плану), использует ИИ для формирования четкой гипотезы о первопричине и предложения дальнейших шагов, отправляет сводный отчет в Slack и по электронной почте и обновляет инцидент.

- Поток 4 : Каждое утро рабочий процесс собирает все инциденты предыдущего дня, создает страницу Notion для документации и отправляет отчет руководящей группе.

Мы развернули аналогичные узлы обнаружения для 8 различных показателей, корректируя направление z-оценки в зависимости от того, были ли проблемы с увеличением или уменьшением.
ИИ-агент получает дополнительный контекст через SQL-запросы (отток по странам, планам, сегментам) для формирования более точных гипотез о первопричинах. Все эти данные собираются и ежедневно отправляются по электронной почте.
Рабочий процесс создает ежедневные сводные отчеты, объединяющие все инциденты по метрикам и уровню серьезности, которые рассылаются заинтересованным сторонам по электронной почте и в Slack.
Приборная панель
Панель управления объединяет все сигналы в одном месте. Автоматическая оценка состояния продукта по шкале от 0 до 100 рассчитывается с помощью:
- объем инцидента
- взвешивание тяжести
- статус открыт или решен
- количество затронутых пользователей
- бизнес-тенденции (MRR)
- тенденции использования (активные аккаунты)
Разбивка по сегментам для определения наиболее пострадавших групп клиентов:

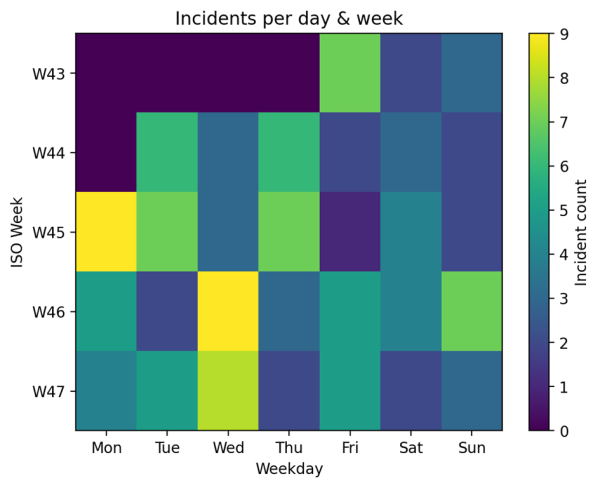
Еженедельная тепловая карта и графики трендов временного ряда для выявления повторяющихся закономерностей:

И подробный обзор инцидента, составленный:
- Бизнес-контекст
- Размер и сегмент
- Гипотеза первопричины
- Тип инцидента
- Сводка ИИ для ускорения коммуникации и диагностики, получаемых из рабочего процесса n8n

Диагноз:
Оценка состояния продукта составила 24/100, реальный продукт имеет статус «подвержен риску» и включает:
- 45 серьезных и критических инцидентов
- 36 инцидентов за последние 7 дней
- 33 385 пользователей, которых это затронуло, по оценкам. Отрицательная тенденция в оттоке и ежедневных активных пользователях.
- Несколько скачков api_error_rate и падений checkout_success_rate

Наибольшее влияние по сегментам:
- Enterprise → критические проблемы актуальности данных
- Средний сегмент рынка → повторяющиеся инциденты при внедрении функций
- SMB → колебания в адаптации и активации

Влияние
Цель этой панели мониторинга — не только анализировать инциденты и выявлять закономерности, но и предоставлять организации возможность быстрее реагировать с помощью подробного обзора.

Мы отметили снижение количества критических инцидентов на 35% за два месяца. Благодаря унифицированным данным специалисты SRE & DATA выявили повторяющуюся причину некоторых серьёзных проблем и смогли устранить её, а также контролировать обслуживание. Время реагирования на инциденты значительно сократилось благодаря сводкам ИИ и всем метрикам, что позволило им определить, где проводить расследование.
Анализ первопричин с помощью ИИ

Использование ИИ может сэкономить много времени. Особенно когда требуется провести исследование в разных базах данных, и вы не знаете, с чего начать. Добавление ИИ-агента в цикл обработки данных может значительно сэкономить время благодаря его скорости обработки данных. Для этого необходима подробная подсказка , поскольку агент заменит человека. Таким образом, для получения максимально точных результатов даже ИИ необходимо понимать контекст и получать определённые указания. В противном случае он может провести исследование и сделать неверные выводы. Не забудьте убедиться, что вы полностью понимаете причину проблемы .
Вы аналитик по данным о продуктах и доходах. Мы обнаружили инцидент: {{ $json.incident }} Вот показатель оттока MRR по странам (сначала основные нарушители): {{ $json.churn_by_country }} Вот показатель оттока MRR по плану: {{ $json.churn_by_plan }} 1. Кратко опишите произошедшее простым деловым языком. 2. Определите наиболее пострадавшие сегменты (страна, план). 3. Предложите 3–5 правдоподобных гипотез (проблемы с продуктом, изменение цен, ошибки, рыночные события). 4. Предложите 3 конкретных дальнейших шага для команды по продукту.
Важно отметить, что после получения результатов необходима окончательная проверка, чтобы убедиться в корректности анализа. ИИ — это инструмент, но он тоже может дать сбой, поэтому не стоит им ограничиваться: это полезный инструмент. В этой системе ИИ предложит три наиболее вероятные причины каждого инцидента.

Более тесное взаимодействие с руководством и отчётность, основанная на данных. Всё стало более основано на данных благодаря более глубокому анализу, а не на интуиции или сегментированных отчётах. Это также привело к улучшению процесса.
Заключение и выводы
В заключение следует отметить, что создание панели мониторинга состояния продукта имеет ряд преимуществ:
- Выявляйте негативные тенденции (MRR, DAU, вовлеченность) раньше
- Сокращение числа критических инцидентов путем выявления первопричинных закономерностей
- Понять реальное влияние на бизнес (затронутые пользователи, риск оттока)
- Расставьте приоритеты в дорожной карте продукта на основе рисков и воздействия
- Объедините данные о продукте, данных, SRE и доходах на основе единого источника достоверной информации
Именно этого и не хватает многим компаниям: единого подхода к данным.

Использование рабочего процесса n8n помогло в двух отношениях: оно позволило решить проблемы в кратчайшие сроки и собрать данные в одном месте. Инструмент автоматизации помог сократить время, затрачиваемое на эту задачу, поскольку компания продолжала работать.
Уроки для продуктовых команд

- Начните с простого : создание системы автоматизации и панели управления должно быть чётко определено. Вы создаёте продукт не для клиентов, а для своих сотрудников. Крайне важно понимать потребности каждой команды, поскольку они — ваши основные пользователи. Учитывая это, сначала разработайте продукт, который станет вашим MVP и будет отвечать всем вашим потребностям. Затем вы сможете улучшить его, добавив функции или метрики.
- Унифицированные метрики важнее идеального обнаружения: необходимо помнить, что именно благодаря им экономится время и понимание. Наличие качественного обнаружения крайне важно, но если метрики неточны, сэкономленное время будет потрачено впустую командами, которые ищут метрики, разбросанные по разным средам.
- Автоматизация экономит 10 часов в неделю ручного расследования: автоматизируя некоторые ручные и повторяющиеся задачи, вы экономите часы расследования, поскольку в случае с рабочим процессом оповещения об инциденте мы сразу знаем, где в первую очередь проводить расследование, а также гипотезу о причине и даже некоторые действия, которые необходимо предпринять.
- Документируйте всё : надлежащее и подробное документирование необходимо и позволит всем заинтересованным сторонам иметь чёткое представление о происходящем. Документация — это тоже часть данных.
Кто я?
Меня зовут Ясин, я менеджер проектов, который расширил свою деятельность, включив в неё науку о данных, чтобы преодолеть разрыв между бизнес-решениями и техническими системами. Изучение Python, SQL и аналитики позволило мне разрабатывать аналитические материалы по продуктам и автоматизированные рабочие процессы, которые связывают потребности команд с поведением данных. Давайте общаться на Linkedin.
Источник: towardsdatascience.com