
 Анкит Кхаре 24 сентября 2025 г. Поделиться на :
Анкит Кхаре 24 сентября 2025 г. Поделиться на :
Agentic Document Extraction (ADE) — пионер смены парадигмы, представляя по-настоящему агентную систему понимания документов, основанную на визуальном ИИ и методах, ориентированных на данные . Точность, масштабируемость, скорость, низкая стоимость владения и удобство для разработчиков для последующей интеграции обеспечивают практичную и надежную обработку документов в таких высокотехнологичных отраслях, как финансы и здравоохранение. ADE решает эту задачу с помощью своей базовой агентной системы, основанной на специализированных моделях машинного обучения и машинного обучения.
Современная интеллектуальная обработка документов (IDP) во многом основана на программах LLM , которые используют такие инструменты, как оптическое распознавание символов (OCR), для извлечения смысла из документов. Однако программы LLM не способны справиться со структурной сложностью документов, характерной для сферы финансовых услуг, здравоохранения и юриспруденции.
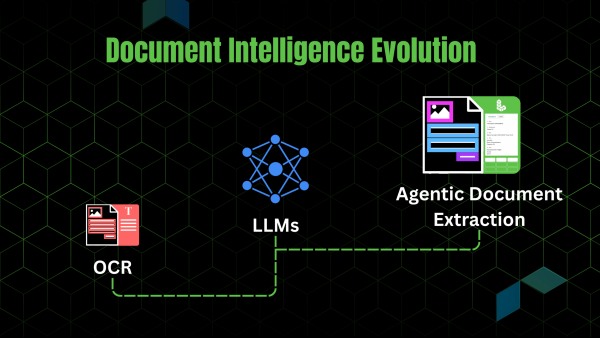
В этой записи блога мы обсуждаем эволюцию IDP — от раннего OCR до методов, основанных на глубоком обучении, и до появления современных систем, основанных на LLM, — и представляем ADE как следующую парадигму.
Повестка дня
- Первая волна — OCR и его ограничения
Как распознавание образов сделало возможным первую эру оцифровки — и почему OCR оказалась неэффективной. - Вторая волна — статистические, основанные на правилах и ранние методы глубокого обучения
От шаблонов к конвейерам обработки естественного языка и ранним моделям машинного обучения: прогресс постепенный, но все еще хрупкий. - Третья волна — LLM и новые вызовы для IDP
Перспектива семантического мышления и мультимодальности — и риск галлюцинаций, непоследовательности и отсутствия прослеживаемости. - Четвертая волна — агентурное извлечение документов (ADE)
Ориентированная на видение, агентная и дата-центрическая парадигма, объединяющая точность, контролируемость и удобство для разработчиков.
Первая волна — эпоха оптического распознавания символов (OCR)
OCR: основополагающий прорыв в цифровизации
До интеллектуальной обработки документов существовало оптическое распознавание символов (OCR): первый большой скачок, превративший бумагу в пиксели. Для своего времени это было революционным: компании наконец смогли преобразовать десятилетия бумажных архивов в машиночитаемый текст. Счета, квитанции, контракты и лабораторные отчеты стали доступны для поиска, индексации и хранения в цифровых системах.
OCR работала по детерминированному конвейеру: получение изображения, улучшение, сегментация символов и распознавание образов. Для чистого, структурированного текста система достигла впечатляющей точности и дала толчок цифровым рабочим процессам в различных отраслях.
Где OCR не сработал
Но OCR распознавал символы, но не понимал документы. Его конструкция, ориентированная на сопоставление с образцом на уровне символов, создавала критические слепые зоны:
- Низкое качество входных данных : рукописный текст, стилизованные шрифты или сканы с низким разрешением давали искаженные результаты.
- Потеря структуры : OCR превращал сложные макеты в линейный поток текста, отбрасывая контекст. Например, система могла прочитать «Гемоглобин» и «12,5 г/дл», но не могла связать их в единый результат анализа в лабораторном отчёте. В счетах-фактурах или финансовых отчётах таблицы и макеты с несколькими столбцами лишались своих взаимосвязей.
Это означало, что предприятия получали оцифровку без понимания, текст улавливался, но смысл терялся.
Шаблоны и исправления на основе правил
Чтобы заполнить этот пробел, появились системы, основанные на шаблонах и правилах. Они накладывали логику поверх OCR, указывая точное местонахождение полей в документе. Для стандартизированных форм, таких как W-9, это обеспечивало высокую точность.
Но эти системы были хрупкими. Даже незначительное изменение макета, например, смещение столбца таблицы, обновление заголовка или новый логотип, могло нарушить весь процесс. Расходы на обслуживание резко возросли, а масштабируемость резко упала.
В конечном итоге первая волна решила проблему цифровизации, но оставила предприятия с ненадежными и немасштабируемыми инструментами, которые отделяли распознавание от настоящего понимания.

Вторая волна — статистические методы, обработка естественного языка и раннее машинное обучение
Поиск понимания за пределами OCR
OCR решала проблему распознавания, но не понимания. Предприятиям требовались системы, способные интерпретировать значение, сохранять структуру и адаптироваться к различным форматам. Это привело к появлению волны статистических методов, обработки естественного языка на основе правил и ранних подходов к машинному обучению, которые пытались преодолеть этот разрыв.
Статистическое и основанное на правилах НЛП
Ранние конвейеры обработки естественного языка включали токенизацию, маркировку частей речи и статистические модели, такие как скрытые марковские модели (СММ) и условные случайные поля (УСП). Они обеспечивали выполнение таких задач, как распознавание именованных сущностей (NER) , позволяя извлекать структурированные элементы, такие как имена, адреса или даты.
Однако производительность сильно зависела от вручную разработанных функций и специализированных лексиконов. Системы хорошо работали в узких областях (например, для разметки имён пациентов в клинических записях), но масштабирование между отраслями или форматами было затруднено.
Классическое машинное обучение
Такие методы, как метод опорных векторов (SVM) и деревья решений, расширили возможности классификации документов и извлечения полей. SVM может различать счета-фактуры, контракты и резюме, а классификаторы могут определять имена поставщиков или суммы платежей в этих документах.
Однако эта адаптивность достигалась ценой обширной разработки функций . Обобщение для различных макетов или неизвестных типов документов оставалось недоступным.
Ранние модели глубокого обучения
К 2010-м годам глубокое обучение проникло в задачи по работе с документами.
- CNN поддерживали анализ макета и распознавание рукописного ввода.
- Рекуррентные нейронные сети улучшили распознавание текста и маркировку последовательностей.
Эти достижения снизили зависимость от вручную создаваемых функций, но привели к появлению новых проблем: необходимости в больших маркированных наборах данных , дорогостоящих вычислениях и трудностях поддержания согласованности и прослеживаемости в процессе производства.
Прогресс есть, но все еще лоскутное одеяло
Эти методы представляли собой важный шаг вперёд, выходя за рамки жёстких шаблонов и обеспечивая более гибкую интерпретацию текста. Они внедрили статистические рассуждения, изучение признаков и более высокоуровневое распознавание образов, чем OCR.
Но это были всё ещё разрозненные решения . Каждое из них развивало определённые подзадачи, такие как классификация или распознавание сущностей, но ни одно из них не обеспечивало надёжного сквозного понимания документов в масштабах предприятия. Это открыло путь для третьей волны: LLM и VLLM , которые обещали унификацию рассуждений и мультимодального понимания.

Третья волна — перспективы больших языковых моделей (LLM) и моделей визуального языка (VLLM)
Скачок в семантическом мышлении
Магистры права (LLM) и магистра права (VLLM) появились с обещанием понимания — недостающего элемента, который OCR и статистические методы никогда не могли обеспечить. Размышляя над текстом и изображениями, они значительно приблизили семантическое понимание к человеческому чтению. Эти модели могли:
- Обобщайте данные для различных макетов документов.
- Обрабатывайте языковые вариации (например, «Гемоглобин», «Hb» и «HGB» как одно и то же понятие).
- Выполняйте сложные задачи, такие как реферирование целых PDF-файлов, ответы на вопросы о документе или интерпретация данных в таблицах и смешанных макетах.
Для разработчиков это был прорыв: быстрое развертывание с простыми подсказками, отсутствие громоздких шаблонов и минимальная тонкая настройка.
Как LLM обрабатывают документы
При загрузке PDF-файла или отсканированного документа в систему на базе LLM рабочий процесс обычно выглядит следующим образом:
- OCR (при сканировании) — изображения преобразуются в необработанный текст.
- Сегментация — текст разбивается на блоки (абзацы, разделы), часто теряя первоначальную структуру.
- Токенизация — текст преобразуется в токены, которые может обработать LLM.
- Рассуждение LLM – модель генерирует ответы, обобщения или извлечения.
Ни на одном этапе модель не сохраняет исходного понимания планировки, пространственных отношений или происхождения ограничивающих рамок . Эта потеря структуры является причиной многих последующих проблем.
Производственный разрыв: несоответствие масштаба
Несмотря на свою гибкость, степени магистра права привнесли новые риски, которые помешали их надежному внедрению на предприятиях:
- Вероятностные результаты — разные прогоны могут давать разные результаты для одного и того же документа.
- Отсутствие возможности аудита — отсутствует встроенный способ отслеживания извлеченных значений до их источника.
- Ручной ввод данных — разработчикам приходилось постоянно настраивать подсказки и очищать выходные данные, чтобы сделать их пригодными для использования.
Галлюцинации и фактическая непоследовательность
Одним из самых опасных видов сбоев является галлюцинация — результаты, которые выглядят правильными, но на самом деле являются неверными.
- Контекстные галлюцинации : противоречие источнику (например, неверное цитирование показателя из таблицы или изменение финансовой цифры).
- Внешние галлюцинации : представление совершенно новой, непроверяемой информации (например, угадывание номера счета).
В отличие от ошибок OCR, которые часто очевидны и постоянны (например, искаженный текст), ошибки LLM правдоподобны и скрыты , что значительно затрудняет их обнаружение в крупных отраслях с высокими ставками.
Проблема структурированного вывода и прослеживаемости
Предприятиям требуются структурированные данные, согласованные со схемой. Однако магистры права генерируют текст в свободной форме , который часто:
- Не соответствует требованиям схемы.
- Создает непоследовательные форматы между тиражами.
- Для нормализации требуется обширная постобработка.
Что ещё более важно, в программах LLM отсутствует визуальная поддержка . Они не могут связать извлечённые значения с их точным местоположением на странице или ограничивающим прямоугольником. Для финансовых, медицинских и юридических сфер, где соответствие требованиям и возможность аудита не подлежат обсуждению, этот пробел неприемлем.
Закрытие волны
Программы магистратуры права (LLM) и магистратуры права (VLLM) расширили возможности анализа документов, добавив семантическое мышление и мультимодальность. Однако без единообразия, структурированности и прослеживаемости они не смогли стать готовыми к внедрению решениями для корпоративных IDP. Следующим шагом стало объединение глубокого понимания с проверяемой и учитывающей макеты базой, что положило начало Четвёртой волне: агентному извлечению документов (ADE).

Четвертая волна — агентское извлечение документов (ADE): парадигма следующего поколения
ADE: принципиально иной подход
Извлечение документов агентами (ADE) представляет собой новую парадигму анализа документов. Вместо того, чтобы рассматривать документ как простой поток текста или полагаться на нестабильные шаблоны, ADE рассматривает документ как визуальное представление информации . Именно поэтому мы называем ADE ( Visual AI-first) .
ADE опирается на три столпа:
- Визуальный ИИ-сначала — документы анализируются как визуальные представления с сохранением контекста, макета и взаимосвязей.
- Агентный ИИ — система может планировать, принимать решения и действовать для извлечения высоконадежных данных, организуя логику синтаксического анализа, специализированные модели машинного обучения/машинного обучения и LLM, который упорядочивает шаги, вызывает инструменты и проверяет выходные данные.
- ИИ, ориентированный на данные — специализированные модели машинного обучения и машинного обучения обучаются на высококачественных наборах данных, подобранных с использованием систематических методов, ориентированных на данные. Ошибки модели в процессе производства запускают структурированный цикл проверки, аннотирования и обновления наборов данных, обеспечивая предсказуемое и надежное улучшение с течением времени.
Годы исследований и разработок LandingAI в области визуального ИИ/компьютерного зрения в сочетании с руководством Эндрю Нга по созданию структур агентного ИИ и созданию режима, ориентированного на данные, привели к созданию ADE.
API извлечения документов агента
ADE предлагается как API, который извлекает, обогащает и обрабатывает сложные документы без специальной подготовки по макету, превращая неструктурированные данные в полезную информацию за считанные секунды.
Он обеспечивает три основные возможности:
- Структурированный вывод JSON — четкая иерархическая структура для различных типов файлов, таких как PDF-файлы и изображения.
- Извлечение полей на основе схемы — определяет поля (например, дату, имя поставщика, позиции счета-фактуры), и ADE анализирует их в соответствии с этой схемой, устраняя несоответствия.
- Визуальное обоснование — каждый фрагмент информации привязан к точным координатам в исходном документе, что создает проверяемый след для обеспечения соответствия и доверия.
Извлечение на основе схемы: устранение неоднозначности и обеспечение согласованности
Извлечение полей начинается со схемы . Вы определяете точные поля, важные для вашего рабочего процесса, например, «имя_пациента», «значение_гемоглобина» или «итого_счета», — и ADE преобразует каждый входящий документ в этот точный структурированный формат.
- Устраняет несоответствие выходных данных, характерное для выходных данных LLM без ограничений.
- Обеспечивает единообразие типов и форматов в различных шаблонах.
- Значительно сокращается необходимость ручной очистки .
Разработчики могут применять схемы zero-shot , обеспечивая надежное извлечение из разнородных документов без специального обучения.
Анализ с учетом макета: сохранение контекста и взаимосвязей
Анализ ADE с учётом макета преодолевает фундаментальную проблему распознавания текста (OCR) в понимании структуры. Система распознаёт разделы, заголовки, таблицы и поля форм , гарантируя извлечение значений в правильном контексте.
Пример: число вроде «12,5 г/дл» — это не просто текст; ADE распознает его как значение гемоглобина в таблице результатов, связанное с его меткой и позицией.
Этот анализ с учетом макета позволяет точно извлекать данные из:
- Сложные таблицы
- Многоколоночные макеты
- Визуальные элементы
— без нестабильных шаблонных правил. Сохраняя взаимосвязи, ADE позволяет точно передать смысл данных документа.
Визуальное обоснование: краеугольный камень доверия и контролируемости
Визуальное обоснование — одно из ключевых отличий ADE, напрямую решающее проблему отсутствия прослеживаемости в решениях на основе LLM. Каждое извлечённое значение привязано к точному местоположению источника в исходном документе:
- Конкретная страница
- Координаты ограничивающего прямоугольника
- Обрезанный фрагмент изображения
Это гарантирует:
- Прозрачность — пользователи мгновенно проверяют источник данных.
- Объяснимость — каждое значение наглядно подкреплено доказательствами.
- Доверие — галлюцинации устраняются посредством проверяемого заземления.
Объединяя глубокое понимание ИИ с детерминированной, проверяемой структурой , ADE обеспечивает надежность корпоративного уровня для анализа документов.



Заключение и дальнейшие шаги: к агентурной документальной разведке
Лауреат премии NeurIPS «Выдающаяся статья» в своей работе «Являются ли возникающие возможности больших языковых моделей миражом?» (Райлан Шеффер, Брандо Миранда, Санми Коеджо) изучил возникающие свойства LLM и пришел к следующему выводу:
«… возникающие способности возникают благодаря выбору метрики исследователем, а не фундаментальным изменениям в поведении модели при изменении масштаба. В частности, нелинейные или прерывистые метрики создают очевидные возникающие способности, тогда как линейные или непрерывные метрики создают плавные, непрерывные и предсказуемые изменения в эффективности модели».
Общественное восприятие часто претерпевает изменения: когда многие люди внезапно узнают о технологии, это кажется прорывом. В действительности же развитие возможностей ИИ происходит более непрерывно и постепенно, чем может показаться.
Именно поэтому мы ожидаем, что развитие интеллектуальной обработки документов (IDP) будет идти по схожей схеме: постепенные улучшения, каждое из которых основывается на предыдущем . OCR оцифровывало текст и сделало его доступным. Методы на основе шаблонов, статистическая обработка естественного языка, классическое машинное обучение и ранние методы глубокого обучения добавили уровни интерпретации, но остались нестабильными. Магистры права (LLM) и магистра права (VLLM) развили эту траекторию, добавив семантическое мышление и мультимодальное понимание, что позволило более гибко интерпретировать документы.
ADE задаёт новую парадигму , продвигая IDP к структурированным, проверяемым и проверяемым данным, на которые могут положиться предприятия. В основе ADE лежат принципы визуального ИИ, агентности и дата-центричности . В перспективе ожидается расширение спектра «агентных» компонентов во внутренних рабочих процессах ADE — систем, которые не просто анализируют документы, но и планируют, проверяют и постоянно совершенствуются в рамках непрерывной эволюции аналитики документов.
Содержание
Источник: landing.ai