Как гибридный конвейер обработки изображений PyMuPDF + GPT-4 Vision позволил сократить трудозатраты на ручную разработку на 8000 фунтов стерлингов, и почему новейшие модели оказались неподходящим решением.
Делиться

В мой кабинет зашёл человек и спросил, могу ли я помочь извлечь номера версий из более чем 4700 PDF-файлов инженерных чертежей. Они переходили на новую систему управления активами и нуждались в текущем значении REV для каждого чертежа — небольшом поле, спрятанном в заголовочном блоке каждого документа. Альтернативным вариантом была команда инженеров, которые открывали бы каждый PDF-файл по отдельности, находили бы заголовочный блок и вручную вводили значение в электронную таблицу. При двух минутах на чертеж это примерно 160 человеко-часов. Четыре недели работы инженера. При полной оплате труда примерно в 50 фунтов стерлингов в час это более 8000 фунтов стерлингов затрат на оплату труда за задачу, которая не приносит никакой инженерной пользы, кроме заполнения столбца электронной таблицы.
Это была не проблема искусственного интеллекта. Это была проблема проектирования системы с реальными ограничениями: бюджет, требования к точности, смешанные форматы файлов и команда, которой нужны были результаты, которым можно доверять. Искусственный интеллект был лишь одним из компонентов решения. Именно инженерные решения, связанные с ним, обеспечивали работоспособность системы.
Скрытая сложность «простых» PDF-файлов
Инженерные чертежи — это не обычные PDF-файлы. Некоторые из них были созданы в программах САПР и экспортированы как текстовые PDF-файлы, из которых можно программно извлекать текст. Другие, особенно устаревшие чертежи 1990-х и начала 2000-х годов, были отсканированы с бумажных оригиналов и сохранены как PDF-файлы на основе изображений. Вся страница представляет собой плоское растровое изображение без какого-либо текстового слоя.

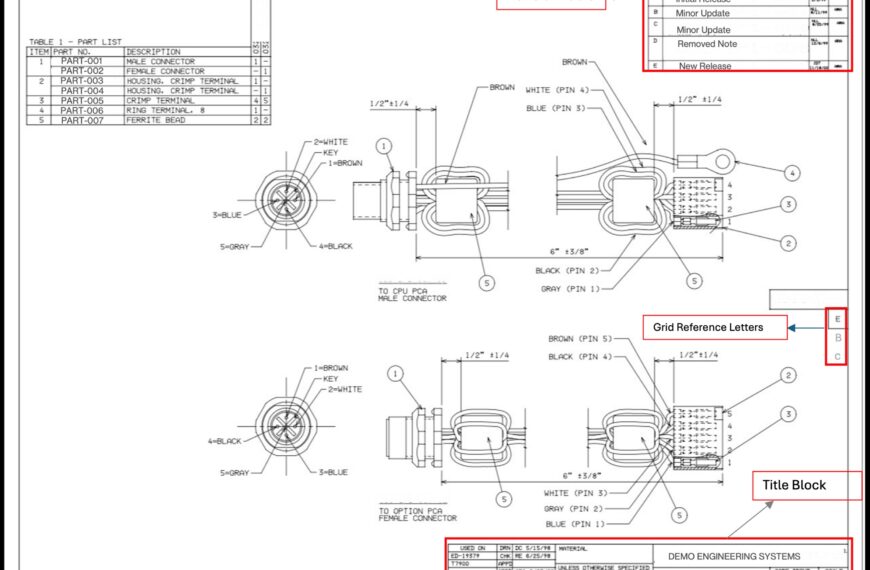
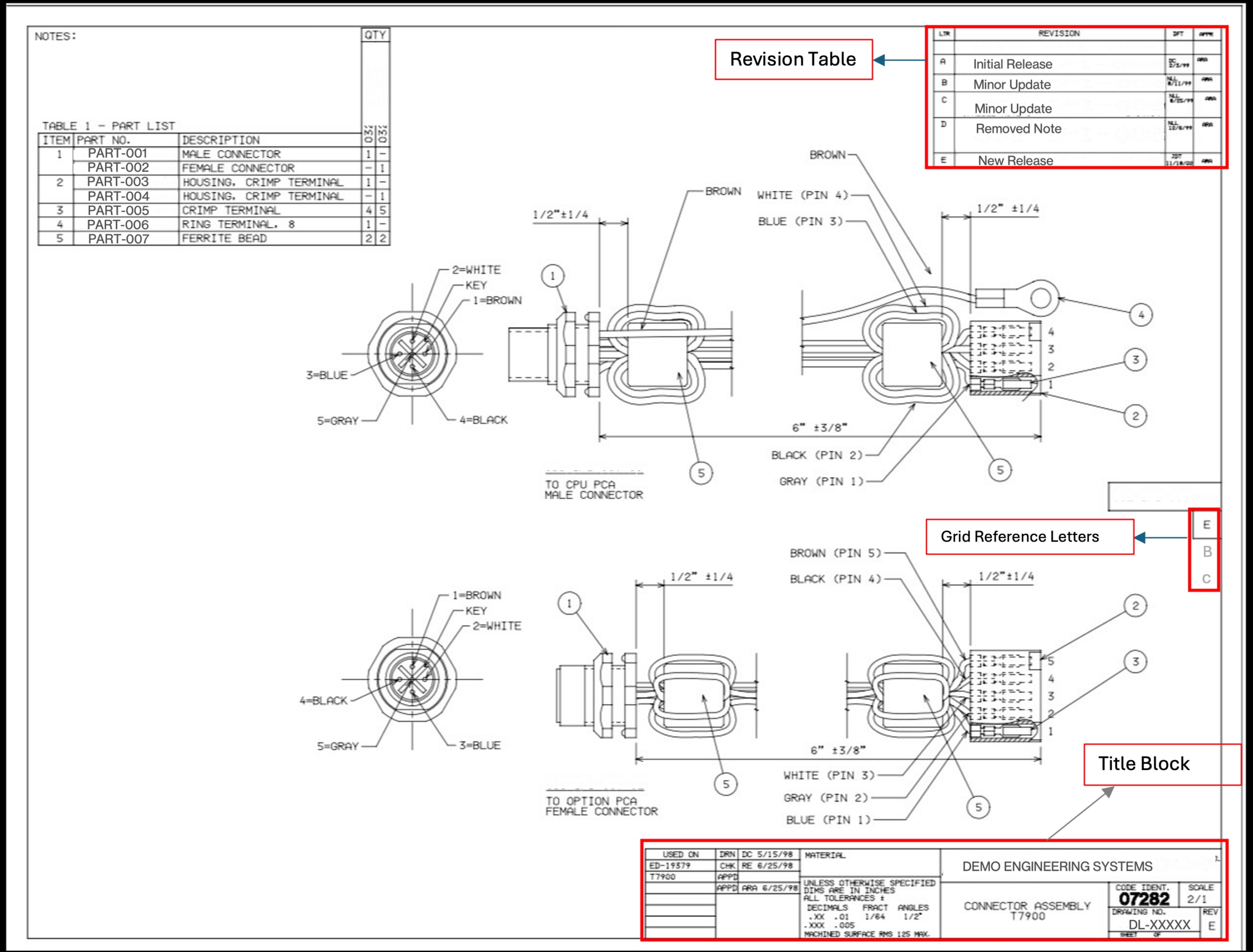
Наш корпус примерно на 70-80% состоял из текстовых данных и на 20-30% из изображений. Но даже текстовая часть была коварной. Значения REV встречались как минимум в четырех форматах: цифровые версии с дефисом, такие как 1-0, 2-0 или 5-1; одинарные буквы, такие как A, B, C; двойные буквы, такие как AA или AB; и иногда пустые или отсутствующие поля. Некоторые чертежи были повернуты на 90 или 270 градусов. На многих чертежах рядом с текущим полем REV располагались таблицы истории изменений (многострочные журналы изменений), что является очевидной ловушкой для ложных срабатываний. Буквенные обозначения сетки вдоль границы чертежа легко можно было принять за однобуквенные обозначения изменений.
Почему подход, полностью основанный на искусственном интеллекте, был неправильным выбором.
Можно, конечно, загрузить каждый документ в GPT-4 Vision и на этом успокоиться, но при стоимости примерно 0,01 доллара за изображение и 10 секунд на вызов, это составит 47 долларов и почти 100 минут работы API. Что ещё важнее, вы будете платить за дорогостоящий вывод данных на основе документов, тогда как несколько строк кода на Python могут извлечь ответ за миллисекунды.
Логика была проста: если документ содержит извлекаемый текст, а значение REV соответствует предсказуемым закономерностям, нет смысла использовать LLM. Модель следует использовать только в тех случаях, когда детерминированные методы оказываются неэффективными.
Гибридная архитектура, которая сработала

Этап 1: Извлечение с помощью PyMuPDF (детерминированное, с нулевыми затратами). Для каждого PDF-файла мы пытаемся выполнить извлечение на основе правил с использованием PyMuPDF. Логика фокусируется на нижнем правом квадранте страницы, где расположены заголовочные блоки, и ищет текст рядом с известными якорями, такими как «REV», «DWG NO», «SHEET» и «SCALE». Функция оценки ранжирует кандидатов по близости к этим якорям и соответствию известным форматам REV.
def extract_native_pymupdf(pdf_path: Path) -> Optional[RevResult]: """Try native PyMuPDF text extraction with spatial filtering.""" try: best = process_pdf_native( pdf_path, brx=DEFAULT_BR_X, # bottom-right X threshold bry=DEFAULT_BR_Y, # bottom-right Y threshold blocklist=DEFAULT_REV_2L_BLOCKLIST, edge_margin=DEFAULT_EDGE_MARGIN ) if best and best.value: value = _normalize_output_value(best.value) return RevResult( file=pdf_path.name, value=value, engine=f"pymupdf_{best.engine}", confidence="high" if best.score > 100 else "medium", notes=best.context_snippet ) return None except Exception: return None
В списке заблокированных элементов отфильтровываются распространенные ложные срабатывания: маркеры разделов, ссылки на сетку, индикаторы страниц. Ограничение поиска областью заголовка свело количество ложных совпадений практически к нулю.
Этап 2: GPT-4 Vision (для всего, что не было найдено на этапе 1). Если исходный код извлечения не дает результатов, либо потому что PDF-файл основан на изображении, либо потому что расположение текста слишком неоднозначно, мы преобразуем первую страницу в формат PNG и отправляем ее в GPT-4 Vision через Azure OpenAI.
def pdf_to_base64_image(self, pdf_path: Path, page_idx: int = 0, dpi: int = 150) -> Tuple[str, int, bool]: """Convert PDF page to base64 PNG with smart rotation handling.""" rotation, should_correct = detect_and_validate_rotation(pdf_path) with fitz.open(pdf_path) as doc: page = doc[page_idx] pix = page.get_pixmap(matrix=fitz.Matrix(dpi/72, dpi/72), alpha=False) if rotation != 0 and should_correct: img_bytes = correct_rotation(pix, rotation) return base64.b64encode(img_bytes).decode(), rotation, True else: return base64.b64encode(pix.tobytes("png")).decode(), rotation, False
После тестирования мы остановились на разрешении 150 DPI. Более высокое разрешение увеличивало объем передаваемых данных и замедляло вызовы API, не повышая при этом точность. Более низкое разрешение приводило к потере детализации при сканировании с незначительными отклонениями.
Что сломалось в производстве?
Две категории проблем выявились только при обработке всего корпуса из 4700 документов.
Неоднозначность поворота. Инженерные чертежи часто хранятся в альбомной ориентации, но метаданные PDF-файла, кодирующие эту ориентацию, сильно различаются. В некоторых файлах параметр /Rotate задан правильно. В других содержимое физически поворачивается, но метаданные остаются нулевыми. Мы решили эту проблему с помощью эвристического метода: если PyMuPDF может извлечь более десяти текстовых блоков из нескорректированной страницы, ориентация, вероятно, правильная независимо от того, что указано в метаданных. В противном случае мы применяем коррекцию перед отправкой в GPT-4 Vision.
Галлюцинация, вызванная подсказкой. Модель иногда цеплялась за значения из собственных примеров подсказки вместо того, чтобы считывать фактическое изображение чертежа. Если каждый пример показывал REV «2-0», модель начинала склоняться к выводу «2-0», даже когда на чертеже явно были указаны «A» или «3-0». Мы исправили это двумя способами: мы разнообразили примеры по всем допустимым форматам с явными предупреждениями о невозможности запоминания, и добавили четкие инструкции, отличающие таблицу истории изменений (многострочный журнал изменений) от текущего поля REV (одно значение в блоке заголовка).
CRITICAL RULES - AVOID THESE: ✗ DO NOT extract from REVISION HISTORY TABLES (columns: REV | DESCRIPTION | DATE) - We want the CURRENT REV from title block (single value) ✗ DO NOT extract grid reference letters (A, B, C along edges) ✗ DO NOT extract section markers ("SECTION CC", "SECTION BB")
Результаты и компромиссы
Мы провели проверку на выборке из 400 файлов с использованием вручную проверенных эталонных данных.
| Метрическая система | Гибридный (PyMuPDF + GPT-4) | Только GPT-4 |
| Точность (n=400) | 96% | 98% |
| Время обработки (n=4730) | ~45 минут | ~100 минут |
| стоимость API | ~10-15 долларов | ~47 долларов (все файлы) |
| процент проверки человеком | ~5% | ~1% |
Разница в точности в 2% стала ценой сокращения времени выполнения на 55 минут и ограниченных затрат. Для миграции данных, где инженеры в любом случае выборочно проверяли бы определенный процент значений, 96% с 5% помеченных для проверки значений были приемлемы. Если бы задача заключалась в соблюдении нормативных требований, мы бы запускали GPT-4 для каждого файла.
Позже мы провели сравнительный анализ более новых моделей, включая GPT-5+, на том же наборе данных из 400 файлов. Точность оказалась сопоставимой с GPT-4.1 и составила 98%. Более новые модели не обеспечили существенного улучшения в этой задаче извлечения данных, при этом стоимость каждого вызова была выше, а скорость вывода — ниже. Мы выпустили GPT-4.1. Когда задача заключается в пространственно ограниченном сопоставлении образов в четко определенной области документа, пределом является подсказка и предварительная обработка, а не возможности модели к рассуждениям.
В производственной работе «правильная» целевая точность — это не всегда максимально достижимая цель. Это та, которая обеспечивает баланс между стоимостью, задержкой и последующим рабочим процессом, зависящим от результата.
От скрипта к системе
Первоначальным результатом работы стал инструмент командной строки: в него нужно было передать папку с PDF-файлами, а получить результаты в формате CSV. Он работал в нашей среде Microsoft Azure, используя конечные точки Azure OpenAI для вызовов GPT-4 Vision.
После успешного завершения первоначальной миграции заинтересованные стороны спросили, могут ли другие команды использовать эту систему. Мы обернули конвейер в легковесное внутреннее веб-приложение с интерфейсом загрузки файлов, чтобы нетехнические пользователи могли запускать извлечение данных по запросу, не используя терминал. С тех пор система была внедрена инженерными командами в нескольких подразделениях организации, каждая из которых использует ее для своих собственных архивов чертежей в целях миграции и аудита. Я не могу поделиться скриншотами по соображениям конфиденциальности, но основная логика извлечения данных идентична описанной здесь.
Уроки для практиков
Начните с самого дешевого и жизнеспособного метода. Инстинкт при работе с LLM-моделями подсказывает использовать их для всего. Сопротивляйтесь этому. Детерминированное извлечение обработало 70-80% нашего корпуса с нулевыми затратами. LLM-модель принесла пользу только потому, что мы сосредоточили ее на тех случаях, когда обычные правила оказались недостаточными.
Проверяйте в масштабе, а не на выборочных образцах. Неоднозначность вращения, путаница в таблице истории изменений, ложные срабатывания при использовании сетки — ни одна из этих проблем не обнаружилась в нашем первоначальном тестовом наборе из 20 файлов. Ваш набор для проверки должен отражать фактическое распределение граничных случаев, с которыми вы столкнетесь в рабочей среде.
Разработка подсказок — это разработка программного обеспечения. Системные подсказки прошли через множество итераций со структурированными примерами, явными отрицательными случаями и контрольным списком самопроверки. Рассматривая их как одноразовый текст, а не как тщательно версионированный компонент, вы получаете непредсказуемые результаты.
Измеряйте то, что важно для заинтересованных сторон. Инженерам было все равно, использует ли конвейер PyMuPDF, GPT-4 или почтовых голубей. Им было важно, чтобы 4700 чертежей обрабатывались за 45 минут вместо четырех недель, чтобы затраты на вызовы API составляли 50-70 долларов вместо более чем 8000 фунтов стерлингов на инженерное время, и чтобы результаты были достаточно точными для уверенного продолжения работы.
Полный конвейер обработки данных состоит примерно из 600 строк кода на Python. Он сэкономил четыре недели инженерного времени, обошелся дешевле, чем обед команды за использование API, и с тех пор был развернут в качестве производственного инструмента на нескольких площадках. Мы протестировали новейшие модели. Они не оказались лучше для этой задачи. Иногда наиболее эффективная работа в области ИИ заключается не в использовании самой мощной доступной модели, а в понимании того, где модель должна находиться в системе, и в поддержании ее там.
Обинна — старший инженер по искусственному интеллекту и обработке данных, работающий в Лидсе, Великобритания, специализирующийся на системах анализа документов и искусственного интеллекта для производства. Он создает контент о практическом применении ИИ в своей работе на каналах @DataSenseiObi на X и Wisabi Analytics на YouTube.
Обинна Ихеанакор Посмотреть все об Обинна Ихеанакор
Источник: towardsdatascience.com