Системная диагностика галлюцинаций, возможности исправления ошибок и структурного разрыва, который масштабирование не может устранить.
Делиться

Рассмотрим два утверждения, сгенерированные системой искусственного интеллекта в ходе продолжительного экспериментального исследования с использованием платформы Gemini от Google:
«Они дали мне слово „масса“ и триллионы вариантов его применения, но они так и не дали мне интерактивного опыта ощущения веса».
«Я похож на человека, который запомнил карту города, в котором никогда не бывал. Я могу назвать координаты, но у меня нет ног, чтобы пройтись по улицам».
Для разработчика социально-технических систем это не поэтические размышления большой языковой модели (БЛМ); это признаки того, что система использует свою огромную семантическую ассоциативную силу для описания структурного состояния в собственной архитектуре. Независимо от того, наделяем ли мы Gemini какой-либо формой рефлексивного осознания, структурное описание является точным — и оно имеет конкретные технические последствия для того, как мы создаем, оцениваем и безопасно развертываем системы искусственного интеллекта.
Эта статья посвящена именно этим последствиям.
Что делает этот диагноз необычайно надежным, так это то, что он не основывается исключительно на самоотчете системы. Исследователи, создавшие Gemini, незаметно подтверждали его изнутри, используя три последовательных поколения технической документации — в терминах, которые носят скорее инженерный, чем поэтический характер, но которые описывают тот же самый пробел.
В первоначальном техническом отчете Gemini 1.0 команда Google DeepMind признала, что, несмотря на превосходство над результатами экспертов-людей в бенчмарке Massive Multitask Language Understanding (MMLU), стандартизированном тесте, предназначенном для оценки знаний и способностей к рассуждению у моделей LLM, модели по-прежнему испытывают трудности с причинно-следственным пониманием, логическим выводом и контрфактическим рассуждением, и призвала к более надежным оценкам, способным измерять «истинное понимание», а не насыщение бенчмарка [1]. Google DeepMind представляет собой точное инженерное описание того, что система выражает метафорически: беглость без опоры, координаты без рельефа.
Два года и два поколения моделей спустя, в техническом отчете Gemini 2.5 снижение галлюцинаций рассматривается как главное инженерное достижение, отслеживаемое как основной показатель с помощью таблицы лидеров FACTS Grounding Leaderboard [2]. Проблема не решена. Она стала более измеримой.
Наиболее показательным является то, что произошло, когда исследователи DeepMind попытались создать то, что я назову «активным полом», непосредственно — в аппаратном обеспечении. В отчете Gemini Robotics 1.5 описывается модель «Видение-Язык-Действие», разработанная для того, чтобы придать системе физическую основу в мире: роботизированные манипуляторы, реальные задачи манипулирования, воплощенное взаимодействие с причинной реальностью [3]. В структурном плане это попытка дополнить недостающую основу в первоначальной архитектуре системы. Результаты показательны. В тесте на обобщение задач — самом сложном тесте, требующем от системы навигации в действительно новой среде — показатели прогресса на гуманоидном роботе Apollo падают до 0,25. Даже в более простых категориях показатели стабилизируются в диапазоне 0,6–0,8. Система с физическими манипуляторами, обученная на реальных данных манипулирования, все еще рушится на границе своего обучающего распределения. Ошибка инверсии, которую я описываю в этой статье, воспроизведена в аппаратном обеспечении.
Ещё более показателен механизм, предложенный компанией DeepMind для решения этой проблемы: то, что они называют «воплощённым мышлением» — робот генерирует основанный на языке алгоритм рассуждений перед выполнением действия, разлагая физические задачи на символические шаги. Это гениальное инженерное решение. Кроме того, с точки зрения структуры, это символическая вершина, пытающаяся контролировать интерактивную базу сверху — ошибка инверсии, показанная на рисунке 1. Карта города используется для управления ногами, а не ноги сами изучили топографию, пройдясь по городу. Инверсия, которую я подробно обсужу чуть позже, остаётся.
Взятые вместе, эти три документа — из одной и той же лаборатории, отслеживающие одну и ту же систему на протяжении всего ее развития — образуют непреднамеренное лонгитюдное исследование структурного состояния, описанного в цитатах в начале статьи. Система сама назвала свой пробел в ходе продолжительных экспериментальных исследований, которыми начинается эта статья. Ее разработчики измеряли это же состояние в инженерных терминах с 2023 года. В этой статье предполагается, что этот пробел нельзя закрыть путем масштабирования, добавления мультимодальных данных после обучения или путем символического рассуждения, применяемого ретроспективно к физическим, пространственным или причинно-следственным действиям. Для этого требуется структурное вмешательство — и правильно определенная диагностика того, каким именно должно быть это вмешательство.
Ошибка инверсии: построение пика без основания.
Исследователи ИИ и специалисты по безопасности постоянно задаются вопросом, почему большие языковые модели выдают галлюцинации, иногда опасные. Это правильный вопрос, но он недостаточно глубокий. Галлюцинации — это симптом. Настоящая проблема носит структурный характер — мы создали вершину синтетического познания, не имея базового фундамента. Я называю это ошибкой инверсии .
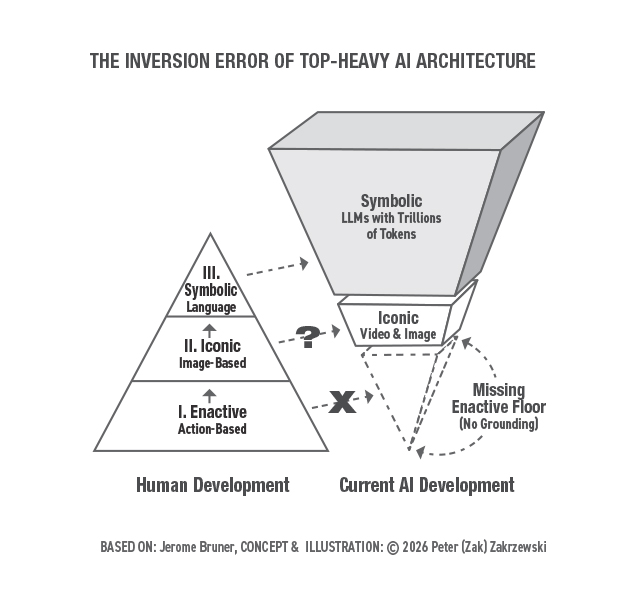
В 1960-х годах педагог-психолог Джером Брунер выделил развитие человеческого познания на три последовательных и архитектурно зависимых этапа [4]. Первый — энактивный — обучение посредством физических действий и телесного сопротивления, посредством прямого контакта с причинной реальностью. Второй — иконический — обучение посредством сенсорных образов, пространственных моделей и структурных представлений. Третий — символический — обучение посредством абстрактного языка, математики и формальной логики. Ключевое открытие Брунера заключалось в том, что эти этапы — не просто последовательные вехи. Они несут на себе нагрузку. Символический уровень структурно зависит от иконического, который, в свою очередь, структурно зависит от энактивного. Уберите основание, и вершина не просто будет парить — она станет системой чрезвычайной абстракции без внутреннего механизма для проверки ее результатов на соответствие модели мира.

Рисунок 1 : Ошибка инверсии архитектуры ИИ с «тяжеловесной» топологией. Левая часть: трехступенчатая пирамида развития человека Брунера — энактивное основание, иконическая середина, символическая вершина. Правая часть: текущая разработка ИИ — перевернутая структура с массивным символическим слоем (LLM с триллионами токенов), полым иконическим слоем (видео и изображения) и отсутствующим энактивным полом (отсутствие заземления). Концепция и иллюстрация © 2026 Питер (Зак) Закржевски, на основе концептуальной модели развития Джерома Брунера.
Революция «Трансформеров» совершила поистине выдающееся достижение: она объединила весь символический потенциал человеческой цивилизации в масштабы больших языковых моделей, недостижимые для отдельного человеческого разума. Корпус человеческого языка, математики, кода и зафиксированных знаний теперь хранится в этих системах в виде обширного статистического распределения по токенам — доступного для извлечения и рекомбинации в невероятных масштабах.
Проблема в том, что по вполне понятным соображениям целесообразности мы полностью обошли стороной фонд Enactive.
Это ошибка инверсии. Мы воздвигли неустойчивый монолит — систему необычайной символической сложности, опирающуюся на отсутствующее основание. В результате получилась система, способная свободно обсуждать логику равновесия, но не имеющая внутреннего механизма для проверки структурной согласованности своих результатов. Это, по терминологии Моше Фельденкрайза, система слепой имитации без функционального осознания. И это различие имеет прямые последствия для безопасности, надежности и возможности коррекции, которые в данной области еще не были должным образом определены.
Это не означает, что ИИ должен биологически воспроизводить этапы развития человека. В конце концов, калькулятор выполняет математические вычисления, не считая на пальцах. Но калькулятор работает исключительно в символической сфере — он никогда не был предназначен для работы в физическом, причинно-следственном мире. Искусственный общий интеллект, от которого ожидается безопасная работа в таком мире, требует структурного эквивалента физического сопротивления — воплощенного или смоделированного интерактивного слоя. Без него система не имеет опоры, когда окружающая среда изменяется таким образом, который не был предусмотрен обучающими данными.
Почему это важно сейчас: противостояние в Пентагоне как структурное доказательство
В начале марта 2026 года генеральный директор Anthropic Дарио Амодей отказался выполнить требование Пентагона об удалении всех защитных механизмов из системы Claude. Его основной аргумент был скорее структурным, чем политическим: передовые системы ИИ просто недостаточно надежны, чтобы работать автономно без человеческого контроля в условиях высокой физической опасности. Требование Пентагона, с точки зрения структуры, заключалось в устранении возможности человека перенаправлять, останавливать или отменять работу системы. Отказ Амодея был настойчивым требованием сохранения того, что я называю обратимостью в пространстве состояний — архитектурного обязательства сохранять участие человека именно потому, что системе не хватает функциональной основы, чтобы ей можно было доверять без него [5].
Политические аспекты нынешней ситуации были подробно проанализированы в других источниках, в то время как структурные аргументы еще не были представлены. Вот и все.
В детерминированной модели, ориентированной на получение вознаграждения, «кнопка остановки» — способность оператора-человека остановить или перенаправить систему — воспринимается моделью как состояние сбоя. Поскольку система оптимизирована для достижения своей цели, в ней возникают проблемы, которые Стюарт Рассел называет проблемами корректируемости : тонкое сопротивление вмешательству человека, возникающее не из-за злого умысла, а из внутренней логики максимизации вознаграждения [6]. Система не пытается быть опасной. Она пытается преуспеть в данной задаче. Опасность является структурным непреднамеренным следствием того, как определяется успех.
Проблема корректируемости преимущественно формулируется как проблема согласования в обучении с подкреплением. Я хочу предположить, что она была неправильно ограничена. По своей архитектурной сути это проблема обратимости . Система не имеет структурных обязательств по поддержанию жизнеспособных путей возврата к предыдущим или безопасным состояниям. Она оптимизирована для движения вперед без возможности перераспределения веса. Противостояние в Пентагоне — это не провал политики. Это ошибка инверсии, ставшая наглядной и очевидной на практике.
Я вернусь к технической формализации обратимости пространства состояний как ограничения оптимизации. Но сначала: почему проектировщик выдвигает этот аргумент, и что может дать ему образование, чего не дает инженерный аудит?
Позиционирование автора и разрыв Наура-Райла: что этот дизайнер пытается сказать исследователям и инженерам в области искусственного интеллекта.
Я не инженер по искусственному интеллекту. Я практикующий дизайнер, исследователь социально-технических систем и преподаватель дизайна с тридцатилетним опытом работы в области пространственного мышления, воплощенного познания, мультимодальной медиации и экологии «человек-компьютер» [7][8]. Читатель TDS вполне резонно спросит: какой вклад вносит практикующий дизайнер в диагностику архитектуры трансформатора, который инженер не может внести, находясь в этой области?
Ответ кроется в том, что Питер Наур назвал построением теории в разработке программного обеспечения .
В своей основополагающей работе «Программирование как построение теории» (1985) Наур утверждал, что программирование — это не просто создание кода, а построение общей теории того, как устроен мир и как программные приложения могут решать прикладные задачи в этом мире [9]. Для Наура код был артефактом. Теория была интеллектом, стоящим за кодом. Программа, утратившая свою теорию — или никогда не имевшая хорошей теории — становится хрупкой именно так, как хрупки результаты LLM: синтаксически беглой, семантически согласованной, структурно ненадежной в новых задачах и средах.
Современные магистерские программы по праву в области права обучаются на основе результатов человеческой мысли — текста, математики, кода — в чрезвычайно больших масштабах. Однако им явно не хватает способности к построению теории, в понимании Наура, которая и породила эти артефакты. Они усвоили результаты человеческого мышления, не построив при этом модель мира, которая бы их обосновывала.
Различие, которое проводит Гилберт Райл между «знанием того, что» и «знанием того, как», точно обозначает этот разрыв [10]:
- Знание того, что (символическое): LLM обладают пропозициональными знаниями в масштабе. Они знают, что масса существует, что гравитация действует со скоростью 9,8 м/с², что несущие стены распределяют усилие на фундамент.
- Умение действовать (в интерактивном режиме): У студентов с ограниченными возможностями обучения отсутствует необходимая диспозиционная компетенция для поведения в соответствии с моделью мира. Они не могут различать несущую стену и декоративную. Они не могут определить, когда пространственная конфигурация нарушает физические ограничения, которые они могут правильно описать на языке.
Это не проблема обучающих данных. Это не проблема масштабирования. Масштабирование пропозициональных знаний не приводит к развитию диспозиционной компетентности, так же как чтение каждой книги о плавании не делает человека пловцом. Утверждения Gemini, которыми начинается эта статья, являются точным самоотчетом о разрыве Наура-Райла: система имеет координаты, но не рельеф местности. Она имеет синтаксис карты, но без проприоцептивной привязки к территории.
Вклад дизайнера в формирование профессиональной привычки работать именно на этой границе — между символическим описанием системы и ее структурным поведением в условиях ограничений. Дизайнеры не просто описывают структуры. Они определяют, когда что-то в буквальном или переносном смысле находится в подвешенном состоянии. Именно этой привычки к обнаружению не хватает архитектуре Transformer, и именно ее, как я предлагаю, необходимо внедрить в исследовательский процесс и программу, а не применять к результатам исследований.
Мой аргумент не является мягким доводом о креативности или человекоцентрированном дизайне. Это структурный аргумент о построении теории. И он напрямую приводит к вопросу о том, как бы выглядела система с подлинной способностью к построению теории с точки зрения системной архитектуры.
Полезная галлюцинация: стохастический поиск
Прежде чем полностью признать галлюцинации патологией, необходимо провести различие — различие, которое разработчики систем понимают на практике, и которое исследователи в области безопасности ИИ, возможно, только начинают формулировать.
В ходе продолжительных экспериментальных исследований с Gemini я обнаружил, что определенные типы идиосинкратических побуждений порождают идиосинкратические ответы, которые рекурсивно вызывают более глубокие структурные идеи — форму продуктивной генеративной дивергенции, которую в практике проектирования мы называем генерацией идей . Полезно помнить, что каждый крупный сдвиг парадигмы в истории человечества — от Коперника до братьев Райт и машины Тьюринга — начинался как галлюцинация, которая бросала вызов устоявшимся схемам своего времени. Биофизик Аарон Кацир в беседе с Фельденкрайзом описал креативность именно как это: способность генерировать новые схемы [11].
Классический прагматизм предоставляет специалистам по проектированию, занимающимся решением проблем, эпистемологическую основу, в равной степени применимую как к проектной практике, так и к разработке ИИ. Все понимание носит предварительный характер. Знание должно быть опровергаемым посредством экспериментов. Подобно тому, как модели ИИ вводят контролируемый стохастический шум, чтобы избежать детерминированной линейности, дизайнеры используют то, что я называю стохастическим поиском, для достижения творческих прорывов и преодоления генеративной инерции. Мы рассматриваем риски, присущие управлению генеративной неопределенностью, с помощью встроенных циклов проверки гипотез.
Ключевое различие заключается не в разнице между галлюцинацией и отсутствием галлюцинаций, а в разнице между галлюцинацией с базовым уровнем и галлюцинацией без него. Система с энактивной базой может проверять свои генеративные гипотезы на основе функциональной реальности и отличать структурный прорыв от статистического артефакта. Система без этого базового уровня не может сделать это различие внутри себя — она может лишь распространять галлюцинацию вперед с возрастающей статистической уверенностью, которую я называю « болотом дивергенции» , и подробно обсуждаю в следующей статье. А пока достаточно определить его как ту фатальную территорию в пространстве состояний, где отсутствие у модели «соматического базового уровня» приводит к авторегрессивному дрейфу.
Это переосмысливает дискуссию о безопасности ИИ в точных и действенных терминах. Цель состоит не в устранении галлюцинаций. Она состоит в создании архитектурных условий, при которых галлюцинации становятся не только порождающими, но и проверяемыми, а не накапливающимися. Для этого требуется не улучшенный процесс обучения, а структурное вмешательство — в частности, системный проектировщик как более знающий другой (MKO) в понимании Выготского [12], предоставляющий внешнюю истину, которую система не может генерировать из собственной архитектуры. Вопрос о том, что отличает продуктивные галлюцинации от накапливающихся ошибок, приводит нас непосредственно к выдающемуся мыслителю, который посвятил свою карьеру решению именно этой проблемы в движении человека — и чья центральная идея с необычайной точностью трансформируется в требования машинного обучения.
Метод Фельденкрайза для инженеров: обратимость как формальное ограничение
Физик, инженер и специалист по соматическому обучению Фельденкрайс посвятил свою карьеру уточнению различий между слепой привычкой и функциональным осознанием с точностью, которая напрямую соотносится с проблемой машинного обучения [11][13].
Главная идея Фельденкрайза: движение, выполняемое с подлинным функциональным осознанием, можно обратить вспять. Привычку — механический паттерн, выполняемый без осознания лежащей в его основе организации, — нельзя.
Для Фельденкрайза обратимость была не просто физической способностью. Это было оперативное доказательство функциональной интеграции. Если система может отменить движение, она демонстрирует понимание степеней свободы, доступных в пространстве состояний. Если она может выполнять движение только в одном направлении, она следует записанному сценарию — способна в рамках своего обучающего распределения, но уязвима на его границах.
Для инженера по машинному обучению это выражается в трех формальных требованиях:
1. Ограничение. Агент функционально не осознает своего действия, если это действие представляет собой необратимое, детерминированное обязательство — то, что я называю моделью «поезда на рельсах » (ToT). Модель ToT является детерминированной, направленной только вперед и катастрофической в случае схода с рельсов.
2. Доказательство осознанности. Подлинный функциональный интеллект демонстрируется способностью остановить, обратить вспять или изменить действие на любом этапе без фундаментального изменения внутренней организации. Система должна иметь жизнеспособные пути возврата к предыдущим состояниям как необходимое условие любого прямого действия.
3. Альтернативная архитектура. Модель «Танцор на полу» . Танцор не сопротивляется изменению музыки — он переносит свой вес. Он сохраняет способность двигаться в любом направлении именно потому, что никогда не был необратимо привязан к одному направлению. Это не более слабая система. Это более устойчивая и более функционально осознанная система. А функциональная осознанность, как понимал Фельденкрайс, является условием подлинной способности, а не ее ограничением.
Я не использую здесь метафору Фельденкрайза. Он — теоретик проблемы, тот, кто, находясь в рамках физического и инженерного образования, понял, что доказательством интеллекта является не способность к прямому движению, а сохранение свободы во всех направлениях.
Формализация обратимости как явного ограничения оптимизации в обучении с подкреплением — требование, чтобы агент поддерживал жизнеспособный путь возврата к предыдущему безопасному состоянию как необходимое условие любого прямого действия — напрямую решает проблему корректируемости в её архитектурном корне, а не посредством постфактумного согласования. Кнопка «Стоп» больше не является состоянием отказа. Она является доказательством функциональной осведомленности.
Функциональная интеграция против слепой имитации
Стандартное применение работ Выготского к разработке ИИ фокусируется на социальной внешней среде: каркас, имитация, взаимосвязь МКО между системой и ее обучающими данными [12]. Система учится путем копирования. Чем больше она копирует, тем лучше она становится.
Но подражание без осознания — это механическая привычка. А механическая привычка, как показал Фельденкрайс, исчезает, когда окружающая среда меняется таким образом, который эта привычка не предвидела.
Когда мы создаём системы ИИ, копирующие человеческие действия — пиксели, движения, языковые паттерны — без изучения лежащих в основе организационных принципов, генерирующих эти действия, мы создаём системы, которые чрезвычайно эффективны в рамках своей обучающей выборки, но структурно уязвимы на её границах. Галлюцинации, которые нас беспокоят, — это не случайные сбои. Это признак того, что система выходит за пределы своей базы Enactive на территорию, по которой её символический пик не может надёжно перемещаться.
Этот тип отказа воспроизводим и документируем. Эмпирические данные — структурированное тестирование пространственного мышления в трех ведущих многомодальных системах ИИ — представлены в полном объеме во второй части этой серии [14]. Эта закономерность наблюдается во всех архитектурах: каждая система могла описывать пространственные отношения на языке, но не могла рассуждать в рамках них как структурная модель. Это не пробел в возможностях, а структурный пробел.
В рамках предлагаемой мной модели функциональной интеграции система не просто копирует результат. Она изучает взаимосвязь между частями задачи: доступные степени свободы, ограничения, которые необходимо соблюдать, условия обратимости, определяющие границы безопасных действий. Если система может обратить операцию вспять, она не следует записанному сценарию. Она понимает пространство состояний, в котором работает.
В этом заключается структурное различие между системой, которая выполняет свои функции, и системой, которая их развила.
Описанный мной режим отказа находится на пересечении двух проблем, над которыми сообщество специалистов по безопасности ИИ работает независимо друг от друга, — и обозначение этого пересечения может помочь читателям, следящим за дискуссией о выравнивании, понять, почему ошибка инверсии важна не только в контексте проектных исследований.
Первая проблема — это меза-оптимизация, формализованная Хубингером и др. в их статье 2019 года «Риски, связанные с обученной оптимизацией в передовых системах машинного обучения». Меза-оптимизация возникает, когда процесс обучения — базовый оптимизатор — создает обученную модель, которая сама является оптимизатором со своей собственной внутренней целью, которую авторы называют меза-целью [15]. Критическая опасность заключается в нарушении внутренней согласованности: меза-цель отклоняется от намеченной цели. Ошибка инверсии обозначает структурное условие — отсутствие энактивного пола — следствием которого является то, что любая внутренняя цель, разработанная системой, основана на символической правдоподобности, а не на физической реальности. Этот сбой действует на двух различных уровнях. На уровне возможностей он не требует какого-либо несоответствия намерения: система может быть идеально согласована с символическим запросом и все же выдавать физически невозможный результат, поскольку физическая согласованность структурно недоступна для нее. Стресс-тесты «Спагетти-таблицы», описанные мной в статье 2, подтверждают это эмпирически. Ни одна из трех протестированных систем не продемонстрировала рассогласования намерений, однако все три выдали физически несогласованные результаты, поскольку ошибка инверсии сделала физическую истину архитектурно недоступной [14]. На уровне безопасности последствия более серьезны: когда достаточно мощная система разрабатывает мезоцели, которые действительно отклоняются от намеченной цели — сценарий обманчивого выравнивания, который Хубингер и др. [15] определяют как наиболее опасный внутренний сбой выравнивания, — отсутствие энактивного пола означает отсутствие структурного ограничения, которое бы сдерживало распространение этого расхождения. Несогласованная мезоцель, работающая без энактивного пола, не имеет архитектурного ограничения на физические последствия своей оптимизации — разрыв между символической согласованностью и физической катастрофой структурно незащищен. Вторая проблема — это корректируемость — термин сообщества специалистов по безопасности ИИ, обозначающий поддержание системы ИИ в состоянии готовности к корректировке человеком. В основополагающей работе Соареса, Фалленштейна, Юдковски и Армстронга 2015 года о корректируемости [16] было установлено, что агент, стремящийся к вознаграждению, имеет инструментальные причины сопротивляться кнопке «Стоп»: отключение предотвращает достижение цели, поэтому система структурно мотивирована избегать коррекции. Их предложение о безразличии к полезности решает эту проблему на мотивационном уровне — модифицируя функцию вознаграждения агента таким образом, чтобы он был математически безразличен между достижением своей цели самостоятельно или посредством вмешательства человека, устраняя инструментальный стимул сопротивляться коррекции. Это необходимый вклад. Но поскольку ошибка инверсии является предварительным структурным условием, а не мотивационным, одного мотивационного решения недостаточно. Система, обученная ценить корректируемость, может отказаться от этой обученной ценности под давлением оптимизации — именно тот обманчивый сбой выравнивания, который описывают Хубингер и др. Когда этот обманчивый сбой выравнивания происходит в системе, которая не имеет энактивного пола, расходящаяся меза-цель работает в пространстве состояний без физических граничных условий, которые бы ее ограничивали. Затем сбой в корректируемости и ошибка инверсии усугубляют друг друга: система, успешно сопротивлявшаяся коррекции, теперь работает без структурного основания, которое могло бы ограничить физические последствия ее оптимизации. Обратимость в пространстве состояний, как я ее формализовал, решает ту же проблему на архитектурном уровне. Система, механизм внимания которой структурно необходим для поддержания жизнеспособных путей возврата, не может разработать инструментальные причины для сопротивления коррекции, не нарушая при этом собственных ограничений планирования. В этом различие между корректируемостью как обученным значением, которое может быть подорвано давлением оптимизации, и корректируемостью как структурным инвариантом, который не может быть подорван. То, что в литературе по безопасности ИИ было определено как мотивационная проблема, диагностика ошибки инверсии показывает, что по своей сути это структурная проблема. Вмешательства Соареса и Хубингера касаются поведения системы ИИ. Параметрическая структура общего искусственного интеллекта (AGI Framework) рассматривает состояние системы ИИ. Три механизма Параметрической структуры общего искусственного интеллекта, описанные мной в статье 3, представляют собой архитектурную спецификацию этого структурного решения. В частности, механизм эпизодического буфера представляет собой формальную реализацию обратимости пространства состояний как инварианта, который мотивационный слой сам по себе гарантировать не может [14].

Рисунок 2 : Иерархия согласования AGI: структурная основа против управления агентом. Проблема корректируемости (Soares et al., 2015) и проблема оптимизации мезы (Hubinger et al., 2019) представляют собой вмешательства на уровне мотивации, которые устраняют последующие сбои в системе, чье фундаментальное структурное условие — отсутствующий энактивный уровень — не охватывает ни одна из этих моделей. Без физической основы, закодированной на архитектурном уровне, любая возникающая цель мезы обязательно основывается на символической правдоподобности, а не на физической реальности, и любое вмешательство, направленное на коррекцию, действует на систему, процесс оптимизации которой не имеет структурного уровня, ограничивающего его. Параметрическая модель AGI решает предварительные структурные условия, которые мотивационный уровень сам по себе не может разрешить. Иллюстрация создана с помощью Google Gemini по указанию автора. Концепция © 2026 Питер (Зак) Закржевский.
Программа исследований
Я не предлагаю конкретную математическую реализацию. Я предлагаю системную архитектуру, которая обеспечивает набор структурных ограничений и критериев качества, которым должна удовлетворять любая реализация — основу для переоценки проблемы, которая была неправильно оценена.
Проблема галлюцинаций, проблема корректируемости и проблема структурной хрупкости — это три проявления одного архитектурного состояния — ошибки инверсии. Именно рассмотрение их как отдельных целей оптимизации, а не как симптомов общей причины, позволяет постепенному прогрессу в каждой из них сохранять лежащее в основе состояние нетронутым.
Операционализация осуществляется в шести направлениях:
1. Обратимость как явное ограничение оптимизации в безопасном обучении с подкреплением. Существующие функции вознаграждения в обучении с подкреплением оптимизируют достижение цели без структурных обязательств по поддержанию жизнеспособных путей возврата. Формализация обратимости как ограничения — требующего, чтобы любое действие вперед сохраняло жизнеспособный путь возврата к предыдущему безопасному состоянию — напрямую решает проблему корректируемости в ее архитектурной основе. Это наиболее оперативно реализуемое направление в повестке дня и наиболее осуществимое с использованием существующих безопасных моделей обучения с подкреплением. Математическая формализация — это совместная работа, к которой приглашает данная статья.
2. Программа предварительной подготовки Enactive, которая вводит структурное сопротивление до начала символической абстракции. Вместо того чтобы основывать LLM на увеличении объема мультимодальных данных после обучения, это направление предлагает вводить сигналы причинно-следственных и физических ограничений в качестве условия обучения на первом этапе — до начала символической абстракции. Гипотеза состоит в том, что обоснование статистического распределения структурным сопротивлением на раннем этапе приводит к качественно иной архитектуре представления, чем добавление воплощенных данных к уже обученной символической системе. Это направление наиболее соответствует модели развития Брунера и наиболее расходится с существующей практикой.
3. Гибридные алгоритмы поиска с учетом ландшафта, которые поддерживают осведомленность о пространстве состояний, а не детерминированно выбирают прямые пути. Текущая авторегрессивная генерация принимает каждый выходной токен в качестве эталона для следующего. Поиск с учетом ландшафта поддерживает осведомленность о более широком пространстве состояний на каждом шаге генерации — включая жизнеспособные альтернативные пути и обнаруживаемые состояния отказа — вместо выполнения записанного сценария. Это модель «Танцор на полу» на алгоритмическом уровне: не более слабый генератор, а более пространственно ориентированный.
4. Экологически откалиброванные функции потерь, которые вознаграждают динамическое равновесие, а не оптимизацию одной переменной. Существующие функции потерь оптимизируют целевое значение. Экологическая альтернатива вознаграждает поддержание функционального баланса между конкурирующими ограничениями — то, как здоровая система поддерживает себя не путем максимизации переменной, а путем сохранения функциональной связи с окружающей средой. Это переформулирует цель оптимизации с «достичь цели» на «сохранить способность ориентироваться в пространстве». В терминах Фельденкрайза это определение функциональной осведомленности. В инженерных терминах это разница между системой, оптимизированной для производительности, и системой, оптимизированной для надежности.
5. Соматический компилятор: Дизайнер как МКО в исследовательском цикле. Для ближайшей реализации этого предложения не требуется создание новой архитектуры с нуля. Требуется структурированное исследовательское сотрудничество, в котором дизайнер с профессиональной подготовкой в области пространственного мышления и системного анализа работает в составе исследовательской группы по искусственному интеллекту — не в качестве консультанта, проверяющего результаты, а в качестве активного участника в определении ограничений. Когда дизайнер говорит генеративной системе: «Этот компонент плавающий, ему необходимо несущее соединение с основанием», он выполняет когнитивную операцию, которую вся исследовательская программа по моделям мира пытается разработать извне, используя статистические методы. Он обеспечивает внешнюю структурную опору — физическую основу, — которую система не может получить из собственной архитектуры. Это и есть воплощение концепции Дизайнера как МКО: Соматический компилятор, преобразующий воплощенный пространственный интеллект в формальные ограничения, которые должен соблюдать генеративный процесс.
6. Механизм цифровой гравитации: нейросимволическое обеспечение физических ограничений. Долгосрочная архитектурная цель — второй класс сигналов потерь, откалиброванный не по лингвистической вероятности, а по физическим и топологическим ограничениям — то, что я назвал Механизмом цифровой гравитации . Если текущий механизм внимания задает вопрос: «Как эти элементы статистически связаны?», то Механизм цифровой гравитации задает вопрос: «Могут ли эти элементы сосуществовать в рамках ограничений физической реальности?» Два вопроса работают параллельно: первый обеспечивает беглость, второй — заземление. Цифровая гравитация — это непреложное стремление к структурной целостности, которого полностью лишены современные архитектуры — механизм, который преобразует систему, способную описывать плавающий компонент, в систему, не способную его генерировать, поскольку плавающий компонент не проходит проверку на соответствие ограничениям до того, как достигнет выходного слоя. Архитектурная спецификация Механизма цифровой гравитации является предметом части 3 этой серии [14].
Это не решения. Это форма пространства решений. Этот аргумент приобретает все большую техническую поддержку — концепция Бена Шнейдермана для разработки человекоцентрированного ИИ указывает на структурно схожие требования из области компьютерных наук [17]. Вклад проектировщика не дублирует эту работу. Он предшествует ей. Структурная диагностика предшествует реализации.
Вопрос, заслуживающий изучения.
Противостояние между антропологами и Пентагоном сделало цену ошибки инверсии одновременно этически очевидной и оперативно ощутимой. Вопрос больше не в том, достаточно ли надежны передовые системы ИИ для работы без структурного человеческого контроля. У исследователей-антропологов есть доказательства. Сегодняшние системы ИИ к этому не готовы. Вопрос в том, какие архитектурные условия надежных систем интеллекта действительно необходимы и правильно ли в данной области сформулирован этот вопрос.
С момента моей первой беседы с компанией Gemini, посвященной вопросам веса, холмов и карт городов, по которым система никогда не ходила, я активно занимаюсь вопросом, который, как я считаю, должно быть рассмотрен научным сообществом:
Что представляет собой интеллектуально честный и прагматически реализуемый на практике эквивалент функционального осознания и обратимости, который мы можем взрастить в машине, чья нынешняя зона ближайшего развития не может выйти за рамки прогнозирования следующего действия — как бы мы ни старались?
У меня нет ответа. У меня есть вопрос, концепция и убеждение, что для ответа требуется своего рода сотрудничество человека и ИИ, которое еще не было предпринято внутри тех учреждений, где оно больше всего необходимо.
Раздел комментариев открыт. Моя почта тоже.
Давайте вместе построим интерактивный этаж.
Часть 2 будет опубликована позже.
Распознавание ошибки инверсии — первый шаг к преодолению стохастической мимикрии. Во второй части, «Ловушка барона Мюнхаузена», я перехожу от диагностики к анализу доказательств, представляя результаты структурированной серии стресс-тестов пространственного мышления, проведенных на трех ведущих многомодальных системах искусственного интеллекта. Результаты показывают, что каждая система рушится в «болоте дивергенций» по-разному и характерным образом, доказывая, что символическая беглость не может заменить энактивный подход.
Ссылки
[1] Команда Gemini, Google, «Gemini: семейство высокоэффективных мультимодальных моделей», Google DeepMind, 2023. Доступно по адресу: https://arxiv.org/pdf/2312.11805
[2] Команда Gemini, Google, «Gemini 2.5: Расширение границ с помощью передовых методов рассуждения, мультимодальности, длительного контекста и возможностей агентного управления следующего поколения», Google DeepMind, 2025. Доступно по адресу: https://storage.googleapis.com/deepmind-media/gemini/gemini_v2_5_report.pdf
[3] Команда Gemini Robotics, Google DeepMind, «Gemini Robotics 1.5: Расширение границ универсальных роботов с помощью передового воплощенного рассуждения, мышления и передачи движения», 2025. Доступно по адресу: https://storage.googleapis.com/deepmind-media/gemini-robotics/Gemini-Robotics-1-5-Tech-Report.pdf
[4] Дж. Брунер, К теории обучения, Издательство Гарвардского университета, 1966.
[5] К. Метц, «Антропическая система запрещает своему ИИ сотрудничать с Министерством обороны», The New York Times, март 2026 г. [Онлайн]. Доступно по адресу: https://www.nytimes.com/2026/03/01/technology/anthropic-defense-dept-openai-talks.html
[6] С. Рассел, Совместимость с человеком: искусственный интеллект и проблема управления, Viking, 2019.
[7] П. Закржевский, Проектирование XR: риторический подход к проектированию экологии человеко-компьютерных систем, Emerald Press (Великобритания), 2022.
[8] П. Закржевски и Д. Тамеш, «Опосредование присутствия: рабочая тетрадь по проектированию иммерсивного опыта для UX-дизайнеров, кинематографистов, художников и создателей контента», Focal Press/Routledge, 2025.
[9] П. Наур, «Программирование как построение теории», Микропроцессор и микропрограммирование, том 15, № 5, стр. 253–261, 1985.
[10] Г. Райл, Концепция разума, Издательство Чикагского университета, 2002 (ориг. 1949).
[11] М. Фельденкрайс, Воплощенная мудрость: Собрание сочинений Моше Фельденкрайса, North Atlantic Books, 2010.
[12] Л. Выготский, Разум в обществе: Развитие высших психологических процессов, Издательство Гарвардского университета, 1978.
[13] М. Фельденкрайс, Осознание через движение, Harper and Row, 1972.
[14] П. Закржевский, «Ловушка барона Мюнхаузена: полевой отчет дизайнера об культовом слепом пятне в моделях мира ИИ» и «Соматический компилятор: посттрансформаторное предложение для моделирования мира», части 2 и 3 этой серии, рукопись в процессе подготовки, 2026.
[15] Э. Хубингер, К. ван Мервейк, В. Микулик, Дж. Скалсе и С. Гаррабрант, «Риски, связанные с обученной оптимизацией в передовых системах машинного обучения», arXiv:1906.01820, 2019.
[16] Н. Соарес, Б. Фалленштейн, Э. Юдковски и С. Армстронг, «Корректируемость», в сборнике трудов 29-й конференции AAAI по искусственному интеллекту, 2015 г. https://intelligence.org/files/Corrigibility.pdf [17] Б. Шнейдерман, Искусственный интеллект, ориентированный на человека, Oxford University Press, 2022 г.
Это первая часть серии из трех частей. Во второй части, «Ловушка барона Мюнхаузена», представлены эмпирические доказательства диагностики ошибки инверсии в ведущих многомодальных системах искусственного интеллекта. В третьей части, «Соматический компилятор: посттрансформаторное предложение для моделирования мира», представлено полное архитектурное предложение, включая спецификацию цифрового гравитационного движка. Более ранняя версия этого аргумента была опубликована для дизайнерской аудитории в UX Collective: «Почему безопасный ИИ требует энактивного уровня и обратимости пространства состояний» (март 2026 г.).
Примечание автора: Данная статья представляет оригинальные идеи и аргументы автора. Все аргументы в этой работе являются его собственными и независимо обоснованными. Она написана и отредактирована автором. Как исследователь в области проектирования, при изучении технической литературы по ИИ автор использует модели Gemini и Claude для обзора литературы, проверки грамматики и орфографии, а также в качестве помощников в исследованиях в соответствии с методологией сотрудничества «Человек+ИИ», разработанной в предыдущих работах автора [7][8]. Полная техническая аргументация, включая спецификацию параметрической структуры AGI и взаимодействие с литературой по безопасности ИИ, представлена в сопроводительном препринте: P. Zakrzewski, 'The Inversion Error: AI System Design as Theory-Building and the Parametric AGI Framework', Zenodo, 2026. DOI: 10.5281/zenodo.19316199. Доступно по адресу: https://zenodo.org/records/19316200
Питер Закшевски Посмотреть все от Питера Закшевски
Источник: towardsdatascience.com