



При создании мощных языковых моделей важно не только обучать их с нуля или улучшать существующие, но и управлять процессом, делая его воспроизводимым и эффективным. DataFlow предлагает решение (https://arxiv.org/html/2512.16676v1), превращая подготовку данных для ИИ в инженерную задачу, аналогично тому, как PyTorch изменил мир нейросетей.
Основная проблема многих современных пайплайнов — это несоответствие и непредсказуемость. Проблема не только в грязных данных, но и в том, что пайплайны часто становятся «семантически нагруженными». То есть LLM уже не просто обрабатывают данные, они участвуют в генерации задач, переформулировке запросов, поиске несоответствий и создании синтетических корпусов данных.
Процесс уже не такой прямолинейный, как в классическом ETL, где все описывалось четкими правилами. Здесь нужно больше контроля качества и итеративности на каждом шаге. Вот тут и появляется DataFlow, который предлагает именно LLM-driven обработку данных.
Как устроен DataFlow
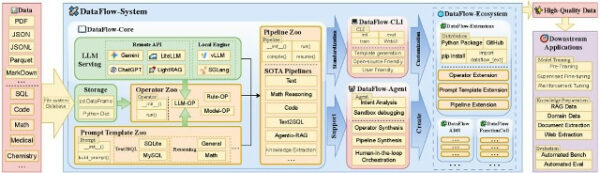
В центре DataFlow лежит идея, что каждый шаг в процессе подготовки данных должен быть оформлен как оператор. Это небольшой модуль, который читает данные, выполняет преобразования и записывает результат обратно в хранилище. Все шаги в системе управляются через глобальное хранилище, которое выступает как единый источник правды. Это позволяет легко переставлять и переиспользовать шаги, а также быстро отслеживать изменения.
Каждый оператор взаимодействует с данными через механизмы чтения-преобразования-записи, что делает процесс максимально прозрачным и удобным для отладки. В итоге, такие пайплайны можно настраивать и компилировать, что упрощает обнаружение ошибок и улучшает контроль над процессом.
Операторы, пайплайны и мощь модульности
Каждый шаг в DataFlow можно представить как операцию, выполняющую одну из четырёх ролей: генерация, оценка, фильтрация и улучшение. Модели проходят цикл generate ? evaluate ? filter ? refine, а в системе уже собрано почти 200 различных операторов для самых разных задач — от текста и кода до математических задач и извлечения знаний.
Что удивительно, этот процесс можно масштабировать и адаптировать под специфические задачи. Например, система помогает создавать Text-to-SQL пайплайны, где важно не только сгенерировать SQL-запрос, но и удостовериться в его исполнимости, сложности и пригодности для обучения.
Мультиагентная система: когда агент сам строит пайплайн
Особенность DataFlow заключается не только в автоматизации всех этих процессов, но и в использовании мультиагентной системы — DataFlow-Agent. Этот агент принимает запросы на естественном языке и превращает их в исполнимый DAG-пайплайн. Представьте, что вы говорите агенту: «Сделай мне данные для задачи на основе этого описания», а он уже сам подбирает нужные операторы, проверяет их совместимость и собирает пайплайн.
Система еще в стадии разработки, но DataFlow уже выглядит как серьёзная заявка. Интересно, что будет дальше, и как такие системы могут повлиять на стандарты подготовки данных в будущем.
Источник: arxiv.org
Источник: ai-news.ru

























