

Исследователи из Tencent AI Lab в Сиэтле и Университета Мэриленда представили метод обучения с подкреплением, который помогает большим языковым моделям (LLM) эффективнее использовать масштабирование на этапе инференса при решении сложных задач рассуждения.
Дисклеймер: это вольная адаптация статьи издания MIT News. Перевод подготовила редакция «Технократии». Чтобы не пропустить анонс новых материалов подпишитесь на «Голос Технократии» — мы регулярно рассказываем о новостях про AI, а также делимся полезными мастридами и актуальными событиями.
Если у вас стоит задача интеграции ИИ в бизнес-процессы, то напишите нам.
Метод Parallel-R1 опирается на специальный пайплайн генерации данных и многоступенчатый процесс обучения. Он позволяет моделям параллельно развивать несколько линий рассуждений при формировании ответа, что в итоге приводит к более устойчивым и точным выводам.
Параллельное мышление, которое уже применяется в некоторых closed-source моделях, открывает возможность повысить способность к рассуждениям у существующих систем за счет эффективного масштабирования на этапе использования — без необходимости в дорогих и трудоемких размеченных наборах данных.
Трудности параллельного мышления
Идея одновременного исследования нескольких линий рассуждений уже доказала свою ценность: Google недавно связал успех своей модели Gemini Deep Think на Международной математической олимпиаде во многом благодаря этой способности.
Первые попытки внедрить параллельное мышление в модели строились на грубой силе: модель генерировала несколько независимых ответов с нуля и выбирала наиболее согласованный вариант — такой подход часто называют «best of N».
Позднее появились более изощренные методы, например, Monte Carlo Tree Search или Tree of Thoughts, которые позволяют тоньше управлять ходом рассуждений и выбором окончательного ответа. Но у этих подходов есть минус — они опираются на заранее прописанные правила и внешние механизмы, что ограничивает их гибкость.
Недавние исследования сосредоточились на том, чтобы обучить модели этому навыку напрямую. Однако здесь возникают серьезные трудности. Обучение через supervised fine-tuning (SFT), где модель учится на заранее подготовленных примерах, полностью зависит от качества этих данных. А высококачественные корпуса, показывающие параллельные рассуждения в сложных реальных задачах, крайне редки и дорого обходятся в создании. В итоге модели чаще имитируют отдельные шаблоны из датасета, чем формируют настоящую, способность к параллельному мышлению.
Обучение с подкреплением (RL), при котором модель учится методом проб и ошибок, предлагает более масштабируемый путь. Однако у этого подхода тоже есть сложности. Большие языковые модели изначально не обучены думать параллельно, поэтому они не формируют исследовательские линии рассуждений, необходимые для эффективного обучения (классическая проблема «cold-start»).
Кроме того, разработка правильной функции вознаграждения — непростая задача. Если модель вознаграждается только за получение правильного финального ответа, она может начать использовать обходные пути и отказываться от более сложной стратегии параллельного мышления. С другой стороны, если её принуждать к параллельному мышлению, она может применять его там, где это не требуется, что снижает эффективность и качество работы.
Как работает Parallel-R1
Фреймворк Parallel-R1 разработан для того, чтобы преодолеть эти трудности. Исследователи описывают его как «первый фреймворк обучения с подкреплением (RL), который позволяет моделям проявлять параллельное мышление при решении сложных задач рассуждения в реальном мире».
«Ключевая идея нашего подхода — обойти необходимость в сложных пайплайнах генерации данных, которые обычно считаются необходимыми для подготовки обучающих наборов по сложным финальным задачам», — пишут исследователи.

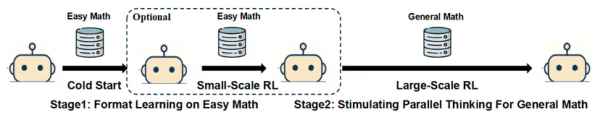
В основе подхода лежит формализация параллельного мышления в два этапа: «Исследование», когда модель запускает несколько независимых потоков рассуждений при обнаружении критического шага, и «Сводка», когда она агрегирует результаты этих потоков, формируя вывод, прежде чем продолжить основную линию рассуждений. Во время инференса модель генерирует текст до появления специального тега <Parallel>, после чего разветвляется на различные блоки <Path>. По завершении она создаёт <Summary> с итогами и продолжает основное рассуждение. Модель, обученная через Parallel-R1, может многократно повторять этот процесс разветвления и слияния при генерации ответа на запрос.
Для внедрения этой способности исследователи разработали трёхэтапный процесс обучения. Первый этап — «Cold-Start Stage», на котором модель дообучается на кастомном наборе данных с примерами параллельного мышления, сгенерированными ИИ. Этот шаг обучает модель базовому формату параллельного рассуждения.
Далее следует этап «RL on Easy Math», где фреймворк применяет обучение с подкреплением к тому же набору данных, чтобы закрепить новую стратегию поведения, используя двойную систему вознаграждений, стимулирующую как корректность, так и правильное использование параллельной структуры.
Наконец, этап «RL on General Math» предполагает обучение модели на новых, более сложных и разнообразных задачах по математике, чтобы модель могла применять навык параллельного мышления к более сложным сценариям.

Ключевое нововведение заключается в том, как создаются исходные данные для этапа «cold-start». Вместо того чтобы полагаться на сложные пайплайны генерации данных, команда обнаружила, что мощная LLM способна создавать высококачественные примеры параллельного рассуждения для простых задач с помощью прямых подсказок. В экспериментах исследователи использовали дистиллированную версию DeepSeek-R1, чтобы сгенерировать около 7 000 примеров параллельного мышления на основе датасета математических задач GSM8K. Важным моментом было стратегическое решение использовать эти данные «cold-start» не для обучения модели решать конечные целевые задачи, а именно для того, чтобы научить ее формату параллельного мышления.
Другой важной частью фреймворка является функция вознаграждения. Для решения задачи проектирования системы наград команда разработала чередующуюся стратегию вознаграждений, которая переключается между наградой за корректность финального ответа и за правильное использование структуры параллельного мышления.
Согласно статье, «такой подход обеспечивает оптимальный баланс между высокой производительностью и последовательным применением параллельного мышления по сравнению с использованием одного типа награды».

Исследователи протестировали свой фреймворк, обучив на Parallel-R1 открытую модель Qwen-3-4B-Base и оценив её на четырёх стандартных бенчмарках математического рассуждения, включая AIME, AMC и MATH. Результаты показали, что модель, обученная с использованием Parallel-R1, стабильно превосходила базовые подходы, включая модель, обученную стандартным методом RL.
На практике Parallel-R1 позволяет повысить способность к рассуждению у существующих ИИ-систем. Этот подход к масштабированию возможностей на этапе инференса, а не просто за счет увеличения размера модели, обеспечивает более эффективный и практичный метод внедрения продвинутых систем рассуждающего ИИ в корпоративные задачи.
Источник: habr.com

























