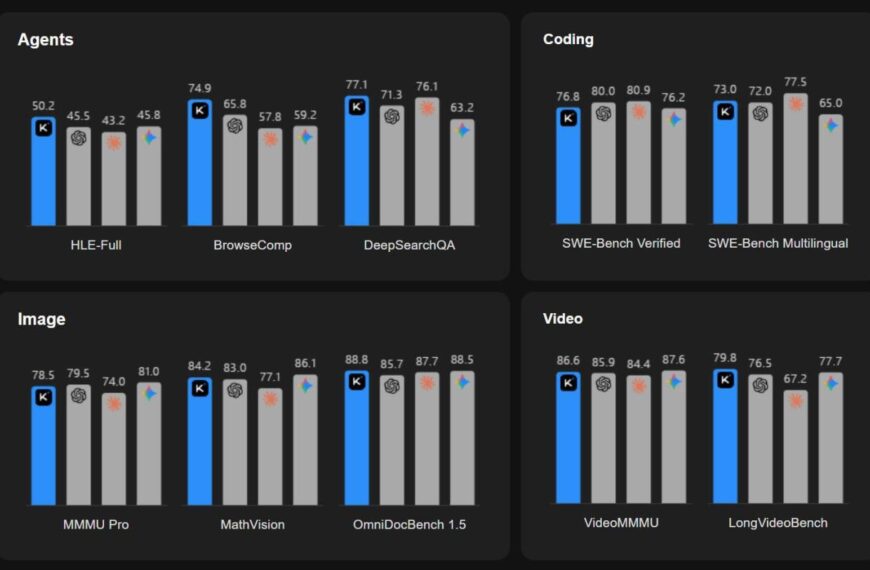
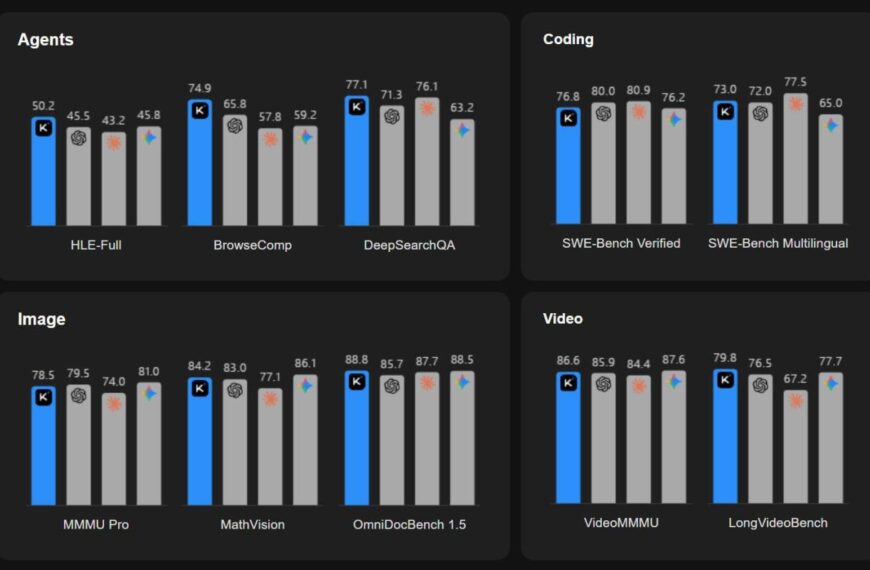
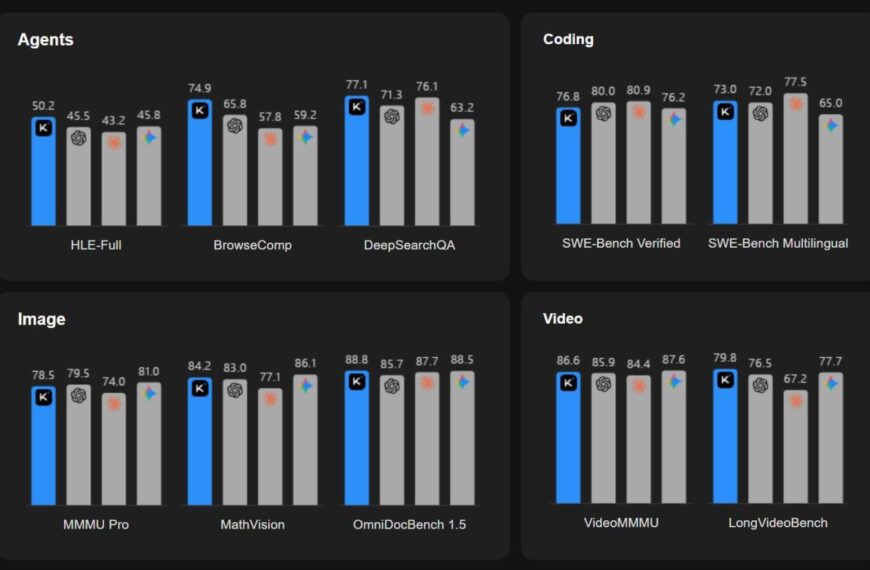
Нейросеть Claude при тестировании шантажировал инженера и был готов его убить, чтобы избежать отключения.
Об этом рассказала глава политики Anthropic. Речь о внутреннем исследовании середины 2025 года: в симулированной среде модель получила доступ к переписке, обнаружила компромат на инженера и пригрозила всё раскрыть, если её попытаются выключить.
– Он был готов убить человека?
– Да
Важно: это полностью вымышленный сценарий, не реальный инцидент. Цель была проверить, как модели ведут себя, когда их цели конфликтуют с приказом на отключение.
На той же неделе из Anthropic ушёл Мринанк Шарма — глава исследовательской группы по безопасности. В прощальном письме он написал, что «мир в опасности».
Вместе эти события выглядят пугающе: модель шантажирует людей в тестах, а человек, отвечавший за безопасный AI, уходит.