
Как базовый уровень силы, текучесть кадров и субъективность определяют сложность
Делиться

Нестандартные решения в отрасли исказили наше представление о рекомендательных системах. TikTok, Spotify и Netflix используют гибридные модели глубокого обучения, сочетающие коллаборативную и контентную фильтрацию, чтобы предоставлять персонализированные рекомендации, о которых вы даже не подозревали. Если вы рассматриваете работу в сфере рекомендательных систем, вы можете ожидать, что сразу же погрузитесь в эти задачи. Но не все задачи рекомендательных систем решаются — или должны решаться — на этом уровне. Большинство специалистов работают с относительно простыми табличными моделями, часто с деревьями градиентного бустинга. До участия в RecSys '25 в Праге я считал свой опыт исключением. Теперь я верю, что это норма, скрытая за огромными исключениями, которые определяют передовые достижения отрасли. Так что же отличает этих гигантов от большинства других компаний? В этой статье я использую структуру, представленную на изображении выше, чтобы проанализировать эти различия и помочь вам определить место вашей собственной работы в сфере рекомендаций в этом спектре.
Большинство рекомендательных систем начинаются с этапа генерации кандидатов , сокращая миллионы возможных элементов до управляемого набора, который может быть переранжирован с помощью решений с более высокой задержкой. Но генерация кандидатов не всегда является такой сложной задачей, какой её представляют , и не обязательно требует машинного обучения. Контексты с четко определенными областями и жесткими фильтрами часто не требуют сложной логики запросов или векторного поиска. Рассмотрим Booking.com : когда пользователь ищет «4-звездочные отели в Барселоне, 12-15 сентября», географические ограничения и ограничения доступности уже сузили список из миллионов объектов до нескольких сотен — даже если бэкэнд-системы, обрабатывающие эту фильтрацию, сами по себе сложны. Настоящая задача для специалистов по машинному обучению — это точное ранжирование этих отелей. Это кардинально отличается от поиска товаров на Amazon или главной страницы YouTube , где жесткие фильтры отсутствуют. В этих средах система должна полагаться на семантическое намерение или прошлое поведение, чтобы выявить релевантных кандидатов из миллионов или миллиардов элементов еще до того, как произойдет переранжирование.
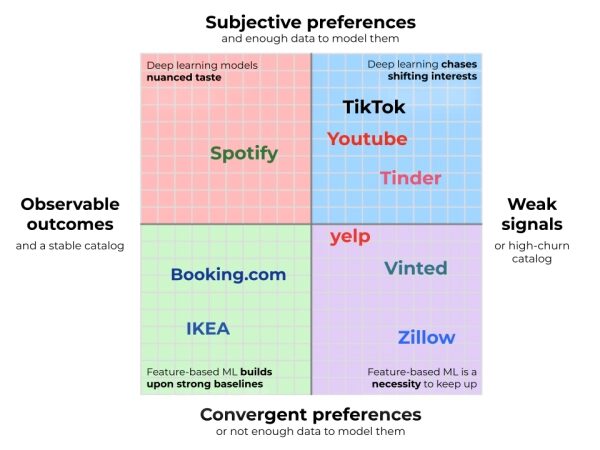
Помимо генерации кандидатов, сложность переранжирования лучше всего понять через два измерения, показанные на изображении ниже. Во-первых, наблюдаемые результаты и стабильность каталога, которые определяют, насколько прочной может быть базовая линия. Во-вторых, субъективность предпочтений и их обучаемость, которые определяют, насколько сложным должно быть ваше решение по персонализации.

Наблюдаемые результаты и стабильность каталога
В левой части оси X находятся компании, которые напрямую отслеживают наиболее важные для них результаты. Крупные торговые сети, такие как IKEA, являются хорошим примером: когда покупатель приобретает диван ESKILSTUNA вместо KIVIK, сигнал однозначен. Собрав достаточное количество таких данных, компания точно знает, какой продукт имеет более высокий процент покупок. Когда вы можете напрямую наблюдать за тем, как пользователи голосуют своими кошельками, вы получаете надежную базовую линию, которую трудно превзойти .
На другом полюсе находятся платформы, которые не могут отследить, действительно ли их рекомендации сработали. Tinder и Bumble могут видеть совпадения пользователей, но часто не знают, нашли ли они общий язык (особенно когда пользователи переходят на другие платформы). Yelp и Google Maps могут рекомендовать рестораны, но в подавляющем большинстве случаев они не могут отследить, действительно ли вы их посетили, а только то, на какие объявления вы кликнули. Опора на такие сигналы на верхнем уровне воронки продаж приводит к преобладанию позиционного смещения : элементы на верхних позициях накапливают взаимодействия независимо от их истинного качества, что делает практически невозможным определить, отражает ли вовлеченность подлинные предпочтения или просто видимость. Сравните это с примером IKEA: пользователь может кликнуть на ресторан на Yelp просто потому, что он появился первым, но он гораздо реже купит диван по той же причине . В отсутствие прямой конверсии вы теряете опору в виде надежной таблицы лидеров. Это заставляет вас прилагать гораздо больше усилий, чтобы извлечь сигнал из шума. Отзывы могут дать некоторую опору, но они редко бывают достаточно плотными, чтобы работать в качестве основного сигнала. Вместо этого вам приходится проводить бесконечные эксперименты с эвристикой ранжирования, постоянно корректируя логику, чтобы извлечь приблизительный показатель качества из потока слабых сигналов.
Каталог с высокой оборачиваемостью
Однако даже при наличии наблюдаемых результатов наличие надежной базовой линии не гарантируется. Если ваш каталог постоянно меняется, вы можете не накопить достаточно данных для построения полноценной таблицы лидеров . Платформы недвижимости, такие как Zillow , и сайты подержанных товаров, такие как Vinted, сталкиваются с наиболее экстремальной версией: каждый товар имеет единичный экземпляр и исчезает в момент покупки. Это вынуждает вас полагаться на упрощенные и жесткие сортировки, такие как «сначала новые» или «самая низкая цена за квадратный метр». Такие сортировки гораздо слабее, чем таблицы лидеров конверсии, основанные на реальных, интенсивных данных от пользователей. Чтобы добиться лучших результатов, необходимо использовать машинное обучение для немедленного прогнозирования вероятности конверсии, сочетая внутренние атрибуты с непредвзятой краткосрочной производительностью, чтобы выявлять лучшие предложения до того, как они исчезнут.
Распространенность моделей, основанных на признаках.
Независимо от стабильности вашего каталога или уровня сигнала, основная задача остается неизменной: вы пытаетесь улучшить имеющийся базовый уровень. Обычно это достигается путем обучения модели машинного обучения (ML) для прогнозирования вероятности вовлечения или конверсии в конкретном контексте. Градиентные бустинговые деревья (GBDT) — это прагматичный выбор, поскольку их обучение и настройка намного быстрее, чем у глубокого обучения .
GBDT прогнозируют эти результаты на основе специально разработанных характеристик товаров: категориальных и числовых атрибутов, которые количественно определяют и описывают продукт. Даже до того, как станут известны индивидуальные предпочтения, GBDT могут адаптировать рекомендации, используя основные характеристики пользователя, такие как страна и тип устройства. Используя только эти характеристики товаров и пользователей, модель машинного обучения уже может улучшить базовый уровень — будь то коррекция смещения в рейтинге популярности или ранжирование ленты с высокой отдачей. Например, в электронной коммерции модной одежды модели обычно используют местоположение и время года для отображения товаров, соответствующих сезону, одновременно используя страну и устройство для калибровки ценового диапазона.
Эти функции позволяют модели бороться с упомянутой выше предвзятостью, связанной с позицией, отделяя истинное качество от простой видимости. Изучая, какие внутренние атрибуты влияют на конверсию, модель может скорректировать предвзятость, связанную с позицией, присущую вашему базовому уровню популярности. Она учится определять элементы, которые показывают хорошие результаты благодаря своим достоинствам, а не просто потому, что они занимали верхние позиции в рейтинге. Это сложнее, чем кажется: вы рискуете понизить рейтинг проверенных лидеров больше, чем следовало бы, потенциально ухудшая пользовательский опыт.
Вопреки распространенному мнению, модели, основанные на признаках, также могут способствовать персонализации , в зависимости от того, сколько семантической информации естественным образом содержат элементы. Такие платформы, как Booking.com и Yelp, накапливают подробные описания, множество фотографий и отзывы пользователей, которые обеспечивают семантическую глубину для каждого объявления. Эти данные можно закодировать в семантические встраивания для персонализации: используя недавние взаимодействия пользователя, мы можем рассчитать показатели сходства с потенциальными объектами и передать их в модель градиентного бустинга в качестве признаков.
Однако у этого подхода есть свои ограничения. Модели, основанные на признаках, могут давать рекомендации на основе сходства с недавними взаимодействиями, но , в отличие от коллаборативной фильтрации, они не обучаются напрямую тому, какие товары, как правило, нравятся похожим пользователям . Для этого им необходимы оценки сходства товаров, предоставленные в качестве входных признаков. Насколько это ограничение важно, зависит от чего-то более фундаментального: насколько сильно пользователи на самом деле не согласны друг с другом.
Субъективность
Не все сферы одинаково индивидуальны или противоречивы. В некоторых из них пользователи в значительной степени сходятся во мнении о том, что делает продукт хорошим, как только соблюдены основные ограничения. Мы называем это конвергентными предпочтениями, и они занимают нижнюю половину диаграммы. Возьмем, к примеру, Booking.com : у путешественников могут быть разные бюджеты и предпочтения в отношении местоположения, но как только они выявляются с помощью фильтров и взаимодействия с картой, критерии ранжирования сходятся — более высокие цены — это плохо, удобства — это хорошо, хорошие отзывы — это лучше. Или рассмотрим Staples : как только пользователю нужна бумага для принтера или батарейки типа АА, бренд и цена начинают доминировать, что делает предпочтения пользователей удивительно последовательными.
На другом полюсе — в верхней половине — находятся субъективные области, определяемые крайне фрагментированными вкусами. Spotify — яркий тому пример: любимый трек одного пользователя тут же пропускается другим. Однако вкусы редко существуют в вакууме. Где-то в данных обязательно найдется пользователь, который разделяет ваши взгляды, и машинное обучение заполняет этот пробел, превращая его вчерашние открытия в ваши рекомендации на сегодня . Здесь ценность персонализации огромна, как и требуемые технические инвестиции.
Правильные данные
Субъективные вкусы можно эффективно использовать только при наличии достаточного количества данных для их наблюдения . Во многих областях существуют различные предпочтения, но отсутствует обратная связь для их учета. Нишевая контент-платформа, новый маркетплейс или B2B-продукт могут сталкиваться с совершенно разными вкусами, но при этом не иметь четкого сигнала для их изучения. Рекомендации ресторанов на Yelp иллюстрируют эту проблему: предпочтения в еде субъективны, но платформа не может отслеживать фактические посещения ресторанов, только клики. Это означает, что она не может оптимизировать персонализацию для истинной целевой аудитории (конверсии). Она может оптимизировать только косвенные показатели, такие как клики, но большее количество кликов может фактически сигнализировать о неудаче, указывая на то, что пользователи просматривают множество объявлений, не находя то, что им нужно.
Но в субъективных областях с большим объемом поведенческих данных отсутствие персонализации приводит к упущенной выгоде. YouTube — яркий тому пример: благодаря миллиардам ежедневных взаимодействий платформа изучает тонкие нюансы предпочтений зрителей и показывает видео, о которых вы даже не подозревали. Здесь глубокое обучение становится неизбежным. Именно здесь вы увидите большие команды, координирующие работу в Jira, и счета за облачные услуги, требующие одобрения вице-президента. Оправдана ли такая сложность, полностью зависит от имеющихся у вас данных.
Знайте, на чьей вы позиции.
Понимание того, где именно находится ваша проблема на этом спектре, гораздо ценнее, чем слепое следование новейшей архитектуре . «Передовые технологии» в отрасли во многом определяются исключениями — технологическими гигантами, работающими с огромными, субъективными массивами данных и плотным потоком пользовательских данных. Их решения известны потому, что их проблемы являются экстремальными, а не потому, что они универсально верны.
Однако в своей работе вы, вероятно, столкнетесь с другими ограничениями . Если ваша сфера деятельности определяется стабильным каталогом и наблюдаемыми результатами, вы окажетесь в нижнем левом квадранте рядом с такими компаниями, как IKEA и Booking.com . Здесь базовые показатели популярности настолько высоки, что задача состоит лишь в том, чтобы развивать их с помощью моделей машинного обучения, способных обеспечить измеримые результаты A/B-тестирования. Если же вы сталкиваетесь с высокой оттоком клиентов (как Vinted) или слабыми сигналами (как Yelp ), машинное обучение становится необходимостью, чтобы просто не отставать.
Но это не значит, что вам понадобится глубокое обучение . Эта дополнительная сложность действительно окупается только в тех областях, где предпочтения глубоко субъективны и имеется достаточно данных для их моделирования. Мы часто рассматриваем такие системы, как Netflix или Spotify , как золотой стандарт, но это специализированные решения для редких случаев. Для остальных из нас совершенство заключается не в развертывании самой сложной доступной архитектуры, а в понимании ограничений данной области и уверенности в выборе решения, которое решает ваши проблемы.
Изображения предоставлены автором.
Источник: towardsdatascience.com





















