
Как настройка гиперпараметров визуально изменяет деревья, усиленные градиентом
Делиться

Введение
В предыдущих публикациях я рассматривал стандартное дерево решений и чудо случайного леса. Теперь, чтобы завершить триаду, я визуально изучу деревья, улучшенные градиентным бустом!
Существует множество библиотек для построения деревьев с градиентным бустом, включая XGBoost, CatBoost и LightGBM. Однако для этого я буду использовать библиотеку sklearn. Почему? Просто потому, что по сравнению с другими, она позволяет мне визуализировать данные проще. На практике я чаще использую другие библиотеки, чем sklearn; однако этот проект ориентирован на визуальное обучение, а не на чистую производительность.
По сути, ГБТ представляет собой комбинацию деревьев, которые работают только вместе. Хотя одно дерево решений (в том числе извлеченное из случайного леса) само по себе может давать приемлемые прогнозы, использование отдельного дерева из ГБТ вряд ли даст что-либо полезное.
Дальше, как всегда, никакой теории, никакой математики — только графики и гиперпараметры. Как и прежде, я буду использовать набор данных о жилом фонде Калифорнии через scikit-learn (CC-BY), следуя тому же принципу, что и в моих предыдущих публикациях. Код доступен по адресу https://github.com/jamesdeluk/data-projects/tree/main/visualising-trees, а все изображения ниже созданы мной (кроме GIF-изображения, взятого из Tenor).
Базовое градиентно-усиленное дерево
Начнём с базового GBT: gb = GradientBoostingRegressor(random_state=42). Как и для других типов деревьев, значения по умолчанию для min_samples_split, min_samples_leaf и max_leaf_nodes равны 2, 1 и None соответственно. Интересно, что значение max_length по умолчанию равно 3, а не None, как в деревьях решений/случайных лесах. Важные гиперпараметры, которые я рассмотрю подробнее позже, включают learning_rate (крутизна градиента, по умолчанию 0,1) и n_estimators (аналогично случайному лесу — количество деревьев).
Подгонка заняла 2,2 с, прогнозирование заняло 0,005 с, а результаты:
| Метрическая | макс_глубина=нет |
|---|---|
| МАЭ | 0,369 |
| МАПЭ | 0,216 |
| МШЭ | 0,289 |
| СКО | 0,538 |
| R² | 0,779 |
Итак, быстрее, чем случайный лес по умолчанию, но производительность немного хуже. Для выбранного мной блока предсказано 0,803 (фактическое значение 0,894).
Визуализация
Ведь именно поэтому вы здесь, верно?
Дерево
Как и раньше, мы можем построить одно дерево. Это первое, доступ к которому осуществляется с помощью gb.estimators_[0, 0]:

Я уже объяснял это в предыдущих постах, поэтому не буду повторяться. Однако хочу обратить ваше внимание на один момент: обратите внимание, насколько ужасны значения! Три листа имеют даже отрицательные значения, чего, как мы знаем, быть не может. Именно поэтому GBT работает только как объединённый ансамбль, а не как отдельные деревья, как в случайном лесу.
Прогнозы и ошибки
Мой любимый способ визуализации GBT — это графики зависимости прогнозирования от итераций с использованием gb.staged_predict. Для выбранного мной блока:

Помните, у модели по умолчанию 100 оценок? Что ж, вот они. Первоначальный прогноз был очень неточным — 2! Но каждый раз модель обучалась (помните learning_rate?) и приближалась к реальному значению. Конечно, она обучалась на тренировочных данных, а не на этих конкретных данных, поэтому итоговое значение было неточным (0,803, то есть примерно 10%), но вы можете ясно увидеть процесс.
В данном случае он достиг относительно стабильного состояния примерно через 50 итераций. Позже мы рассмотрим, как прекратить итерации на этом этапе, чтобы не тратить время и деньги.
Аналогичным образом можно построить график ошибки (т.е. разности между прогнозом и истинным значением). Конечно, это даст нам тот же график, просто с другими значениями по оси Y:

Давайте сделаем ещё один шаг вперёд! Тестовые данные содержат более 5000 блоков для прогнозирования; мы можем пройтись по каждому из них и спрогнозировать их все для каждой итерации!

Мне нравится этот сюжет.

Все они начинаются примерно с 2, но резко возрастают по мере итераций. Мы знаем, что все истинные значения варьируются от 0,15 до 5, со средним значением 2,1 (см. мой первый пост), поэтому такой разброс прогнозов (от ~0,3 до ~5,5) ожидаем.
Мы также можем построить график ошибок:

На первый взгляд это кажется немного странным — можно было бы ожидать, что они начнутся, скажем, с ±2 и сойдутся к 0. Однако, если присмотреться, это происходит в большинстве случаев — это можно увидеть в левой части графика, примерно в первых 10 итерациях. Проблема в том, что при более чем 5000 линиях на этом графике многие из них перекрываются, из-за чего выбросы становятся более заметными. Возможно, есть лучший способ визуализировать их? Как насчёт…

Медианная ошибка составляет 0,05 — что очень хорошо! Межквартильный размах (IQR) меньше 0,5, что тоже неплохо. Так что, хотя есть и ужасные прогнозы, большинство из них вполне приличны.
Настройка гиперпараметров
Гиперпараметры дерева решений
Как и прежде, давайте сравним, как гиперпараметры, исследованные в исходном сообщении о дереве решений, применяются к GBT, с гиперпараметрами по умолчанию learning_rate = 0,1, n_estimators = 100. У min_samples_leaf, min_samples_split и max_leaf_nodes также max_dynamics = 10, чтобы сделать сравнение с предыдущими сообщениями и друг с другом справедливым.
| Модель | макс_глубина=нет | макс_глубина=10 | min_samples_leaf=10 | min_samples_split=10 | max_leaf_nodes=100 |
|---|---|---|---|---|---|
| Время подгонки (с) | 10.889 | 7.009 | 7.101 | 7.015 | 6.167 |
| Прогноз времени (с) | 0,089 | 0,019 | 0,015 | 0,018 | 0,013 |
| МАЭ | 0,454 | 0,304 | 0,301 | 0,302 | 0,301 |
| МАПЭ | 0,253 | 0,177 | 0,174 | 0,174 | 0,175 |
| МШЭ | 0,496 | 0,222 | 0,212 | 0,217 | 0,210 |
| СКО | 0,704 | 0,471 | 0,46 | 0,466 | 0,458 |
| R² | 0,621 | 0,830 | 0,838 | 0,834 | 0,840 |
| Выбранное предсказание | 0,885 | 0,906 | 0,962 | 0,918 | 0,923 |
| Выбранная ошибка | 0,009 | 0,012 | 0,068 | 0,024 | 0,029 |
В отличие от деревьев решений и случайных лесов, более глубокое дерево показало гораздо худшие результаты! И потребовало больше времени для подгонки. Однако увеличение глубины с 3 (значение по умолчанию) до 10 улучшило результаты. Другие ограничения привели к дальнейшему улучшению, что снова демонстрирует, как все гиперпараметры могут играть свою роль.
скорость_обучения
GBT корректируют прогнозы после каждой итерации в зависимости от ошибки. Чем выше корректировка (градиент, скорость обучения), тем сильнее меняется прогноз между итерациями.
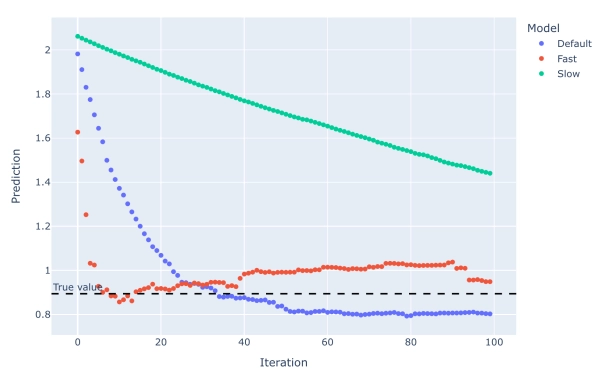
Существует очевидный компромисс в отношении скорости обучения. Сравнение скоростей обучения 0,01 (медленная), 0,1 (стандартная) и 0,5 (быстрая) на протяжении 100 итераций:

Более высокая скорость обучения позволяет быстрее достичь правильного значения, но при этом повышается вероятность перекоррекции и выхода за пределы истинного значения (например, «рыхление» в автомобиле), что может привести к колебаниям. Низкая скорость обучения может вообще не достичь правильного значения (например, недостаточно сильный поворот руля и прямая поездка в дерево). Что касается статистики:
| Модель | По умолчанию | Быстрый | Медленный |
|---|---|---|---|
| Время подгонки (с) | 2.159 | 2.288 | 2.166 |
| Прогноз времени (с) | 0,005 | 0,004 | 0,015 |
| МАЭ | 0,370 | 0,338 | 0,629 |
| МАПЭ | 0,216 | 0,197 | 0,427 |
| МШЭ | 0,289 | 0,247 | 0,661 |
| СКО | 0,538 | 0,497 | 0,813 |
| R² | 0,779 | 0,811 | 0,495 |
| Выбранное предсказание | 0,803 | 0,949 | 1.44 |
| Выбранная ошибка | 0,091 | 0,055 | 0,546 |
Неудивительно, что модель с медленным обучением оказалась ужасной. Для этого блока модель с быстрым обучением оказалась немного лучше, чем модель по умолчанию в целом. Однако на графике видно, что, по крайней мере для выбранного блока, именно последние 90 итераций сделали модель с быстрым обучением точнее модели по умолчанию. Если бы мы остановились на 40 итерациях, по крайней мере для выбранного блока, модель по умолчанию была бы гораздо лучше. Радость визуализации!
n_оценщиков
Как упоминалось выше, количество оценщиков тесно связано со скоростью обучения. В целом, чем больше оценщиков, тем лучше, поскольку это даёт больше итераций для измерения и корректировки ошибки, хотя это и требует дополнительных временных затрат.
Как видно выше, достаточно большое количество оценщиков особенно важно при низкой скорости обучения, чтобы гарантировать достижение корректного значения. Увеличение количества оценщиков до 500:

При достаточном количестве итераций медленно обучающийся GBT действительно достиг истинного значения. Более того, все они оказались гораздо ближе к нему. Статистика это подтверждает:
| Модель | DefaultMore | БыстроПодробнее | МедленноПодробнее |
|---|---|---|---|
| Время подгонки (с) | 12.254 | 12.489 | 11.918 |
| Прогноз времени (с) | 0,018 | 0,014 | 0,022 |
| МАЭ | 0,323 | 0,319 | 0,410 |
| МАПЭ | 0,187 | 0,185 | 0,248 |
| МШЭ | 0,232 | 0,228 | 0,338 |
| СКО | 0,482 | 0,477 | 0,581 |
| R² | 0,823 | 0,826 | 0,742 |
| Выбранное предсказание | 0,841 | 0,921 | 0,858 |
| Выбранная ошибка | 0,053 | 0,027 | 0,036 |
Неудивительно, что пятикратное увеличение количества оценщиков значительно увеличило время подгонки (в данном случае в шесть раз, но это может быть единичным случаем). Тем не менее, мы всё ещё не превзошли результаты деревьев с ограничениями, представленных выше — полагаю, нам потребуется провести поиск гиперпараметров, чтобы посмотреть, сможем ли мы их превзойти. Кроме того, для выбранного блока, как видно на графике, примерно после 300 итераций ни одна из моделей не улучшилась. Если это справедливо для всех данных, то дополнительные 700 итераций были излишними. Ранее я упоминал о том, как можно избежать траты времени на итерации без улучшения; теперь пора это рассмотреть.
n_iter_no_change, validation_fraction и tol
Дополнительные итерации могут не улучшить конечный результат, но всё равно требуют времени. Именно здесь и пригодится ранняя остановка.
Существует три важных гиперпараметра. Первый, n_iter_no_change, определяет количество итераций, необходимое для достижения состояния «без изменений» перед прекращением итераций. toler[erance] определяет величину изменения валидационной оценки, чтобы она была классифицирована как «без изменений». А validation_fraction определяет долю обучающих данных, которая будет использоваться в качестве проверочного набора для получения валидационной оценки (обратите внимание, что эти данные не связаны с тестовыми).
Сравнивая GBT с 1000 оценками с GBT с довольно агрессивной ранней остановкой — n_iter_no_change=5, validation_fraction=0.1, tol=0.005 — последний остановился всего лишь после 61 оценки (и, следовательно, потребовалось всего 5~6% времени для подгонки):

Однако, как и ожидалось, результаты оказались хуже:
| Модель | По умолчанию | Ранняя остановка |
|---|---|---|
| Время подгонки (с) | 24.843 | 1.304 |
| Прогноз времени (с) | 0,042 | 0,003 |
| МАЭ | 0,313 | 0,396 |
| МАПЭ | 0,181 | 0,236 |
| МШЭ | 0,222 | 0,321 |
| СКО | 0,471 | 0,566 |
| R² | 0,830 | 0,755 |
| Выбранное предсказание | 0,837 | 0,805 |
| Выбранная ошибка | 0,057 | 0,089 |
Но как всегда, возникает вопрос: стоит ли вкладывать в 20 раз больше времени, чтобы улучшить R² на 10%, или стоит ли уменьшать ошибку на 20%?
Байесовский поиск
Вы, вероятно, этого ожидали. Области поиска:
search_spaces = { 'learning_rate': (0.01, 0.5), 'max_thought': (1, 100), 'max_features': (0.1, 1.0, 'uniform'), 'max_leaf_nodes': (2, 20000), 'min_samples_leaf': (1, 100), 'min_samples_split': (2, 100), 'n_estimators': (50, 1000), }
Большинство из них похожи на мои предыдущие посты; единственный дополнительный гиперпараметр — learning_rate.
На данный момент это заняло больше всего времени — 96 минут (примерно на 50% больше, чем у случайного леса!). Лучшие гиперпараметры:
best_parameters = OrderedDict({ 'learning_rate': 0.04345459461297153, 'max_thought': 13, 'max_features': 0.4993693929975871, 'max_leaf_nodes': 20000, 'min_samples_leaf': 1, 'min_samples_split': 83, 'n_estimators': 325, })
Значения max_features, max_leaf_nodes и min_samples_leaf очень похожи на значения настроенного случайного леса. Значение n_estimators тоже похоже, и это согласуется с тем, что показала приведенная выше диаграмма выбранных блоков — дополнительные 700 итераций были в основном ненужными. Однако по сравнению с настроенным случайным лесом глубина деревьев всего на треть меньше, а min_samples_split значительно выше, чем мы видели ранее. Значение learning_rate не оказалось слишком уж неожиданным, исходя из того, что мы видели выше.
И перекрестные проверки оценок:
| Метрическая | Иметь в виду | Стандарт |
|---|---|---|
| МАЭ | -0,289 | 0,005 |
| МАПЭ | -0,161 | 0,004 |
| МШЭ | -0,200 | 0,008 |
| СКО | -0,448 | 0,009 |
| R² | 0,849 | 0,006 |
Из всех существующих моделей эта — лучшая: с меньшими ошибками, более высоким R² и меньшими дисперсиями!
Наконец, наш старый друг — ящичные диаграммы:

Заключение
Вот и подошла к концу моя мини-серия статей о трех наиболее распространенных типах древовидных моделей.
Надеюсь, что, познакомившись с различными способами визуализации деревьев, вы теперь (а) лучше понимаете, как работают разные модели, не прибегая к уравнениям, и (б) сможете использовать собственные графики для настройки своих моделей. Это также может помочь в управлении взаимодействием с заинтересованными сторонами — руководители предпочитают красивые картинки таблицам с цифрами, поэтому демонстрация им древовидной диаграммы поможет им понять, почему то, что они просят вас сделать, невозможно.
Исходя из этого набора данных и этих моделей, градиентный бустинг немного превзошёл случайный лес, а оба варианта значительно превзошли одиночное дерево решений. Однако это могло быть связано с тем, что у GBT было на 50% больше времени на поиск лучших гиперпараметров (они, как правило, более затратны в вычислительном плане — в конце концов, количество итераций было одинаковым). Стоит также отметить, что GBT имеют большую склонность к переобучению, чем случайные леса. И хотя дерево решений показало худшую производительность, оно работает гораздо быстрее, и в некоторых случаях это важнее. Кроме того, как уже упоминалось, существуют и другие библиотеки со своими плюсами и минусами — например, CatBoost обрабатывает категориальные данные «из коробки», в то время как другие библиотеки GBT обычно требуют предварительной обработки категориальных данных (например, прямого кодирования или кодирования меток). Или, если вы чувствуете себя очень смелым, как насчёт объединения разных типов деревьев в ансамбль для ещё большей производительности…
Ну ладно, до следующего раза!
Источник: towardsdatascience.com

























