
Мы представляем MUVERA, современный алгоритм поиска, который сводит сложный поиск по нескольким векторам к поиску максимального скалярного произведения по одному вектору.
Быстрые ссылки
- Бумага
- GitHub
- Делиться
Нейронные модели встраивания стали краеугольным камнем современного информационного поиска (ИР). При наличии запроса от пользователя (например, «Какова высота горы Эверест?»), цель ИР — найти информацию, релевантную запросу, в очень большом массиве данных (например, миллиардах документов, изображений или видео в Интернете). Модели встраивания преобразуют каждую точку данных в одновекторное «встраивание», так что семантически похожие точки данных преобразуются в математически похожие векторы. Встраивания обычно сравниваются с помощью сходства скалярного произведения, что обеспечивает эффективный поиск с помощью оптимизированных алгоритмов поиска максимального скалярного произведения (MIPS). Однако недавние достижения, в частности, внедрение многовекторных моделей, таких как ColBERT, продемонстрировали значительно улучшенную производительность в задачах ИР.
В отличие от одновекторных эмбеддингов, многовекторные модели представляют каждую точку данных набором эмбеддингов и используют более сложные функции сходства, которые могут улавливать более сложные взаимосвязи между точками данных. Например, популярная мера сходства Чамфера, используемая в современных многовекторных моделях, определяет, когда информация из одного многовекторного эмбеддинга содержится в другом многовекторном эмбеддинге. Хотя такой многовекторный подход повышает точность и позволяет находить более релевантные документы, он создает существенные вычислительные проблемы. В частности, увеличение количества эмбеддингов и сложность оценки многовекторного сходства делают поиск значительно более затратным.
В статье «MUVERA: Многовекторный поиск с использованием кодировок фиксированной размерности» мы представляем новый алгоритм многовекторного поиска, разработанный для преодоления разрыва в эффективности между одно- и многовекторным поиском. Мы упрощаем задачу многовекторного поиска, создавая кодировки фиксированной размерности (FDE) запросов и документов, которые представляют собой отдельные векторы, скалярное произведение которых аппроксимирует многовекторное сходство, тем самым сводя сложный многовекторный поиск к поиску максимального скалярного произведения одного вектора (MIPS). Этот новый подход позволяет нам использовать высокооптимизированные алгоритмы MIPS для поиска начального набора кандидатов, которые затем могут быть переранжированы с использованием точного многовекторного сходства, что обеспечивает эффективный многовекторный поиск без потери точности. Мы предоставили реализацию нашего алгоритма построения FDE с открытым исходным кодом на GitHub.
Проблема многовекторного поиска
Многовекторные модели генерируют несколько векторных представлений для каждого запроса или документа, часто одно векторное представление на токен. Как правило, сходство между запросом и документом вычисляется с помощью сопоставления по Чамферу, которое измеряет максимальное сходство между каждым векторным представлением запроса и ближайшим векторным представлением документа, а затем суммирует эти сходства по всем векторам запроса (стандартный метод вычисления многовекторного сходства). Таким образом, сходство по Чамферу обеспечивает «целостную» меру того, как каждая часть запроса связана с некоторой частью документа.
Хотя многовекторные представления обладают такими преимуществами, как улучшенная интерпретируемость и обобщаемость, они создают значительные проблемы при поиске информации:
- Увеличение объема эмбеддингов : генерация эмбеддингов для каждого токена значительно увеличивает количество обрабатываемых эмбеддингов.
- Сложный и ресурсоемкий процесс оценки сходства : сопоставление по Чамферу — это нелинейная операция, требующая матричного произведения, что дороже, чем скалярное произведение одного вектора.
- Отсутствие эффективных методов поиска с сублинейной сложностью : Поиск по одному вектору выигрывает от использования высокооптимизированных алгоритмов (например, основанных на разбиении пространства), которые одновременно обеспечивают высокую точность и сублинейное время поиска, избегая исчерпывающих сравнений. Сложная природа многовекторного сходства препятствует прямому применению этих быстрых геометрических методов, что затрудняет эффективный поиск в больших масштабах.
К сожалению, традиционные одновекторные алгоритмы MIPS не могут быть напрямую применены к многовекторному поиску — например, документ может содержать токен с высокой степенью сходства с одним из токенов запроса, но в целом документ может быть не очень релевантным. Эта проблема требует более сложных и ресурсоемких методов поиска.
MUVERA: Решение с кодированием фиксированной размерности.
MUVERA предлагает элегантное решение, сводя поиск по сходству многовекторных данных к одновекторному MIPS, что значительно ускоряет поиск по сложным многовекторным данным. Представьте, что у вас есть большой набор данных «многовекторных множеств» (т.е. наборов векторов), где каждое множество описывает некоторую точку данных, но поиск по каждому из этих множеств медленный. Хитрость MUVERA заключается в том, чтобы взять всю эту группу многовекторных данных и сжать их в один, более удобный для обработки вектор, который мы называем кодированием фиксированной размерности (FDE). Ключевой момент заключается в том, что при сравнении этих упрощенных FDE их сравнение очень точно совпадает с тем, что вы получили бы при сравнении исходных, более сложных многовекторных множеств. Это позволяет нам использовать гораздо более быстрые методы поиска, разработанные для отдельных векторов.
Вот упрощенное объяснение принципа работы MUVERA:
- Генерация FDE : MUVERA использует сопоставления для преобразования многовекторных наборов запросов и документов в FDE. Эти сопоставления предназначены для того, чтобы зафиксировать основную информацию о сходстве в векторе фиксированной длины.
- Поиск на основе MIPS : FDE документов индексируются с использованием стандартного решателя MIPS. По заданному запросу вычисляется его FDE, и решатель MIPS эффективно извлекает FDE наиболее похожих документов.
- Переранжирование : Первоначальные кандидаты, полученные с помощью MIPS, переранжируются с использованием исходного коэффициента сходства Чамфера для повышения точности.
Ключевое преимущество MUVERA заключается в том, что преобразование FDE не зависит от конкретных данных. Это означает, что оно не зависит от конкретного набора данных, что делает его устойчивым к изменениям в распределении данных и подходящим для потоковых приложений. Кроме того, в отличие от отдельных векторов, создаваемых моделью, FDE гарантированно аппроксимируют истинное сходство по Чамферу с точностью до заданной погрешности. Таким образом, после этапа переранжирования MUVERA гарантированно найдет наиболее похожие многовекторные представления.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
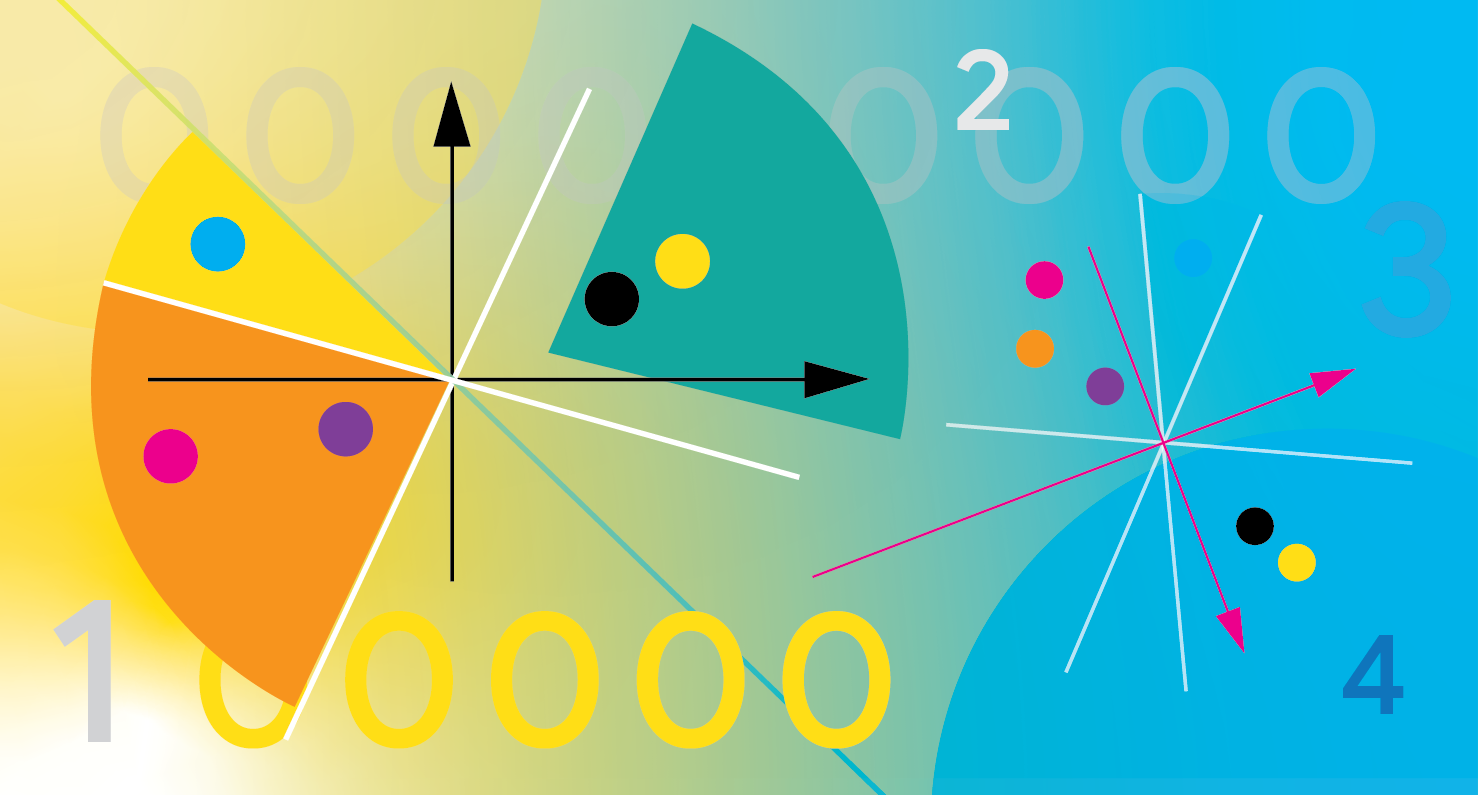
Иллюстрация построения запросов FDE. Каждый токен (в этом примере показан как слово) отображается на многомерный вектор (в примере для простоты — двумерный). Многомерное пространство случайным образом разбивается на гиперплоскости. Каждому участку пространства присваивается блок координат в выходном FDE, который равен сумме координат векторов запроса, попавших в этот участок.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Иллюстрация построения FDE-объектов документа. Построение аналогично построению запроса, за исключением того, что векторы, попадающие в заданную часть разделенного пространства, усредняются, а не суммируются, что точно отражает асимметричный характер сходства по Чамферу.
Теоретические основы
Наш подход вдохновлен методами, используемыми в вероятностных встраиваниях деревьев — мощном инструменте в теории геометрических алгоритмов. Однако мы адаптируем эти методы для работы со скалярными произведениями и сходством Чемфера.
Основная идея генерации FDE заключается в разделении пространства встраивания на секции (иллюстрировано на рисунке выше). Если похожие векторы из запроса и документа попадают в одну и ту же секцию, мы можем эффективно аппроксимировать их сходство. Однако, поскольку оптимальное соответствие между векторами запроса и документа заранее неизвестно, мы используем случайную схему разделения.
Мы также предоставляем теоретические гарантии для MUVERA, доказывая, что FDE обеспечивают сильное приближение подобия Чемфера (подробнее можно прочитать в статье). Это важный результат, поскольку он предоставляет принципиальный способ выполнения многовекторного поиска с использованием одновекторных аппроксимаций с доказуемой точностью.
Результаты эксперимента
Мы оценили MUVERA на нескольких наборах данных для поиска информации из бенчмарков BEIR. Наши эксперименты показывают, что MUVERA стабильно обеспечивает высокую точность поиска со значительно меньшей задержкой по сравнению с предыдущим передовым методом, известным как PLAID.
Наши основные выводы включают в себя:
Улучшенная полнота поиска: MUVERA превосходит эвристику с одним вектором, распространенный подход, используемый в многовекторном поиске (который также применяется в PLAID), достигая лучшей полноты поиска при значительно меньшем количестве документов-кандидатов (показано на рисунке ниже). Например, FDE находит в 5–20 раз меньше кандидатов для достижения фиксированной полноты поиска.

Вспомним кодировки с фиксированной размерностью (FDE) различной размерности по сравнению с эвристикой на основе одного вектора (SV). Обратите внимание, что FDE с размерностью 10240 имеют почти тот же размер представления, что и исходное представление MV (используемое в эвристике SV), при этом требуя значительно меньшего количества сравнений при поиске (это верно даже для FDE с размерностью 20k).
Сниженная задержка: по сравнению с PLAID, высокооптимизированной многовекторной системой поиска, основанной на одновекторной эвристике, MUVERA обеспечивает в среднем на 10% более высокую полноту поиска с замечательным снижением задержки на 90% по всем наборам данных BEIR (показано на рисунке ниже).

Сравнение MUVERA и PLAID на основе показателей BEIR.
Кроме того, мы обнаружили, что FDE в MUVERA можно эффективно сжимать с помощью квантования произведения, уменьшая объем занимаемой памяти в 32 раза с минимальным влиянием на качество извлечения данных.
Эти результаты подчеркивают потенциал MUVERA в значительном ускорении многовекторного поиска, что делает его более практичным для реальных приложений.
Заключение
Мы представили MUVERA — новый и эффективный алгоритм поиска по нескольким векторам, обладающий доказуемыми гарантиями качества аппроксимации и хорошими практическими характеристиками. Сводя поиск по нескольким векторам к поиску по одному вектору в секунду (MIPS), MUVERA использует существующие оптимизированные методы поиска и достигает самых современных результатов со значительно улучшенной эффективностью. Заинтересованные читатели могут найти реализацию нашего алгоритма построения FDE с открытым исходным кодом на GitHub.
Наша работа открывает новые возможности для эффективного многовекторного поиска, что имеет решающее значение для различных приложений, включая поисковые системы, рекомендательные системы и обработку естественного языка. Мы считаем, что дальнейшие исследования и оптимизация MUVERA приведут к еще большему повышению производительности и более широкому внедрению методов многовекторного поиска.
Благодарности
Работа, кратко изложенная в этом посте, была выполнена в сотрудничестве с Маджидом Хадианом, Джейсоном Ли и Вахабом Миррокни. В заключение мы благодарим Кимберли Шведе за ценную помощь в создании анимации для этого поста.
Источник: research.google