воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Мы предлагаем использовать регрессию «текст-текст» с языковыми моделями для решения всех задач числового прогнозирования.
Быстрые ссылки
- Бумага
- Библиотека с открытым исходным кодом
- Делиться
Большие языковые модели (БЛМ) часто совершенствуются за счет обучения на основе предпочтений и оценок людей. В этом процессе модель вознаграждения обучается принимать подсказки и ответы в качестве входных данных для дальнейшего обучения модели. Такой акцент на субъективной обратной связи от людей значительно улучшил их способность генерировать полезный, безвредный и связный текст и оказал преобразующее воздействие на разговорных помощников (например, Gemini).
Еще один путь расширения модели вознаграждения за пределы человеческой субъективности — это обработка необработанных, разнообразных операционных данных и рассмотрение наблюдаемого числового результата как сигнала вознаграждения. Эта возможность может открыть двери для прогнозирования производительности обширных программных инфраструктур, эффективности промышленных процессов или результатов научных экспериментов. В основе своей мы хотим, чтобы модели с линейными функциями (LLM) выполняли регрессию (т.е. прогнозировали метрику y , имея на входе x ). Ранее традиционные методы регрессии основывались на табличных входных данных, т.е. на числовых векторах фиксированной длины, которые можно было объединить в одну таблицу. Однако преобразование сложных, неструктурированных данных в табличный формат может быть очень трудоемким, а огромное разнообразие и динамичный характер реальных данных (например, сложные конфигурационные файлы, системные журналы и постоянно меняющиеся аппаратные или рабочие нагрузки) делают эту задачу еще более сложной. Когда появляются новые типы данных, процесс часто приходится начинать заново.
В статье «Прогнозирование производительности больших систем с помощью текстовой регрессии» мы описываем простой, общий и масштабируемый подход, основанный на нашей предыдущей работе по универсальной регрессии OmniPred. Этот подход позволяет модели регрессионного языка (RLM) считывать строковое представление входных данных и выводить число в виде структурированной текстовой строки. Например, мы можем представить состояние ( x ) промышленной системы — включая все ее конфигурации, параметры и контекстную информацию — в виде структурированной текстовой строки, а затем RLM запишет метрику производительности ( y ) в виде строки. RLM может быть предварительно обучена или даже инициализирована случайным образом, и при обработке новой задачи регрессии она может быть обучена с использованием прогнозирования следующего токена с помощью функции потерь кросс-энтропии, где ( x ) — это подсказка, а ( y ) — целевое значение. Мы описываем, как эта новая парадигма имеет ряд преимуществ, таких как избежание инженерии признаков или нормализации, адаптация к новым задачам с малым количеством примеров и универсальное приближение распределений вероятностей выходных данных. Мы применяем RLM в контексте прогнозирования эффективности использования ресурсов на Borg, крупномасштабной вычислительной инфраструктуре Google для управления кластерами. Мы также выпустили библиотеку с открытым исходным кодом, которую исследовательское сообщество может использовать в любых задачах.
Прогнозирование эффективности вычислительных кластеров Google.
Критически важная задача прогнозирования количества инструкций в секунду на один вычислительный блок Google (MIPS на GCU) является ключевым показателем эффективности системы Borg от Google. Точное прогнозирование MIPS на GCU для различных конфигураций имеет решающее значение для оптимизации распределения ресурсов и планирования на тысячах машин. Мы применили метод регрессии «текст-текст» для прогнозирования MIPS на GCU цифрового двойника Borg от Google — сложной системы тестирования, имитирующей состояние реальных кластеров. Конечная цель — прогнозирование числового результата специализированного алгоритма упаковки в контейнеры, используемого для эффективного распределения задач по ресурсам.
Наш подход использует реляционную модель обучения (RLM), которая требует всего лишь двухслойного кодировщика-декодера с 60 миллионами параметров. Для обучения мы собираем большие объемы данных из множества задач регрессии с парами ( x , y ), включающими состояние системы ( x ), представленное в формате YAML или JSON, содержащее списки активных заданий, трассировки выполнения и текстовые метаданные. Каждая точка данных ( x ) может занимать до 1 миллиона токенов, если мы включим все характеристики (т.е. подробную информацию) об этой точке данных. Поскольку RLM имеет ограничение на количество токенов в 8000, мы предварительно обрабатываем данные, переупорядочивая наиболее важные характеристики в начале текстовой строки. Когда строка усекается до предела количества токенов, теряются только менее важные характеристики.
Мы предварительно обучаем RLM на предварительно обработанных данных, чтобы модель могла легче адаптироваться к новым типам входных данных из новых задач, используя обновления градиента с малым количеством примеров. Поскольку числа представлены в виде текста, их можно представить как есть, без нормализации. Если мы будем многократно считывать декодированные выходные данные, это также позволит эффективно зафиксировать плотность значений y , что важно для моделирования стохастических или зашумленных ситуаций.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Наш метод использует RLM для прямой регрессии числовых показателей производительности (y) на основе сложных, текстово представленных состояний системы (x), таких как состояния вычислительных кластеров Google при различных рабочих нагрузках (GMail, YouTube, Maps и т. д.) и на различном оборудовании (процессоры и TPU).
Ниже мы демонстрируем три возможности регрессионных моделей, которые служат важными компонентами для универсальной регрессии.
Улавливание плотности
Многократная выборка выходных данных RLM позволяет нам с удивительной точностью воспроизводить распределения вероятностей (т.е. плотности) значений y даже в разных временных интервалах. Эта оценка плотности полезна, поскольку выходит за рамки простых точечных прогнозов. Моделирование полного распределения возможных результатов позволяет получить представление о присущей изменчивости и потенциальном диапазоне значений MIPS на GCU. Эта возможность позволяет нам учитывать как алеаторную неопределенность (присущую системе случайность, например, стохастический спрос на нагрузку), так и потенциально выявлять эпистемические индикаторы (неопределенность, обусловленная ограниченным количеством наблюдений или характеристик), что дает нам более полное понимание поведения системы.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Модель RLM обеспечивает оценки плотности, которые удивительно хорошо согласуются с целевым распределением инструкций в секунду в зависимости от временных интервалов, как показано на кривых плотности регрессоров (3D) и графике оценки плотности целевого ядра (KDE) (плоскость XY).
Количественная оценка неопределенности
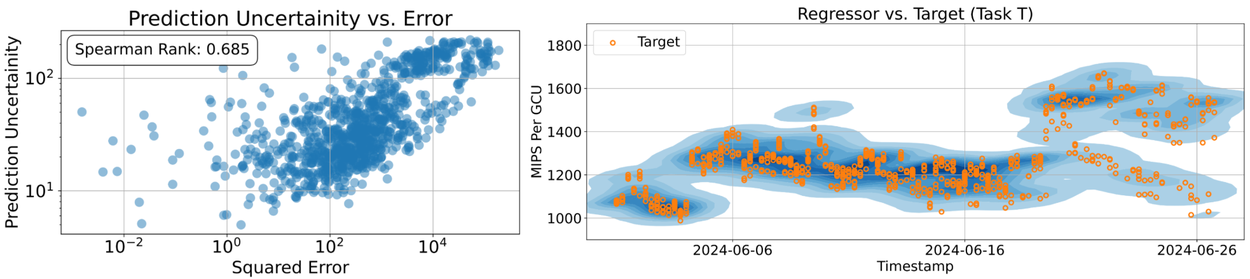
Неопределенность прогнозов модели RLM коррелирует с квадратом остаточной ошибки, что позволяет количественно оценить уверенность модели в своих прогнозах. При наличии неопределенности прогнозируемое распределение становится шире, что указывает на необходимость более осторожного подхода к прогнозам. Это позволяет нам определить, когда следует в большей степени полагаться на регрессор, а когда, возможно, следует вернуться к более медленным, но более точным симуляциям с упаковкой в контейнеры при управлении вычислительными кластерами.

Слева: Неопределенность прогноза коррелирует с ошибкой регрессора. Справа: График KDE прогнозов RLM эффективно отображает целевые точки.
Практически идеальная регрессия с низкими затратами
Помимо количественной оценки плотности и неопределенности, наша модель RLM является экономичной и эффективной, обеспечивая очень точную точечную регрессию для разнообразного набора задач. Мы представляем диаграммы рассеяния с почти идеальной ранговой корреляцией Спирмена, демонстрирующие сильное соответствие между прогнозируемыми и фактическими показателями MIPS в рейтинге GCU. Модель может адаптироваться к различным задачам прогнозирования на разных серверах, выступая в качестве адаптируемого универсального предиктора для Borg.

Диаграмма рассеяния между предсказанием RLM ( ось x ) и истинным целевым значением y ( ось y ) в задачах множественной регрессии. Легенда отображает ранговую корреляцию Спирмена (⍴).
Ресурсы и перспективы развития
Мы демонстрируем, что наша относительно простая модель RLM с кодировщиком-декодером эффективно обучается на богатых нетабличных входных данных, обеспечивая высокоточные прогнозы и эффективную адаптацию к новым задачам. Этот надежный и масштабируемый подход прогнозирует результаты метрик непосредственно из необработанного текста, значительно снижая зависимость от ручной разработки признаков и открывая путь как для универсальных системных симуляторов, так и для сложных механизмов вознаграждения. Моделируя разнообразную числовую обратную связь, модели RLM операционализируют «опыт» таким образом, что это позволит совершить будущие прорывы в обучении с подкреплением для языковых моделей. Более подробная информация содержится в статье и открытом исходном коде.
Благодарности
Данное исследование было проведено основными участниками проекта: Яшем Ахаури (Корнельский университет и Google Research), Брайаном Левандовски (Google Platforms) и Синъю Сонгом (Google DeepMind), а также при участии Ченг-Хси Лина, Адриана Рейеса, Гранта К. Форбса, Ариссы Вонгпанич, Бангдинга Янга, Мохамеда С. Абдельфаттаха и Саги Переля.
Мы хотели бы поблагодарить наших предыдущих коллег по этому обширному исследовательскому проекту: Оскара Ли, Чансу Ли, Дайи Пэна, Ютяня Чена, Тунга Нгуена, Цюи Чжана, Йорга Борншайна, Инцзе Мяо, Эрика Танга, Дару Бахри и Мангпо Пхотилимтана. Мы также благодарим Михала Лукасика, Ури Алона, Амира Язданбахша, Шао-Хуа Суня, Куан-Хуэй Ли, Цзы Вана, Синьюня Чена, Цзиюнь Ха, Авирала Кумара, Джонатана Лая, Ке Сюэ, Жун-Си Тана и Дэвида Смоллинга за полезные обсуждения. Мы также благодарим Олену Богданову за разработку анимации для этой публикации. Наконец, мы благодарим Или Чжэна, Сафина Худу, Асафа Ахарони, Шринада Бходжанапалли, Дэвида Ло, Мартина Диксона, Дэниела Головина, Денни Чжоу, Клер Цуй, Эда Чи и Бенуа Шиллингса за постоянную поддержку.
Источник: research.google