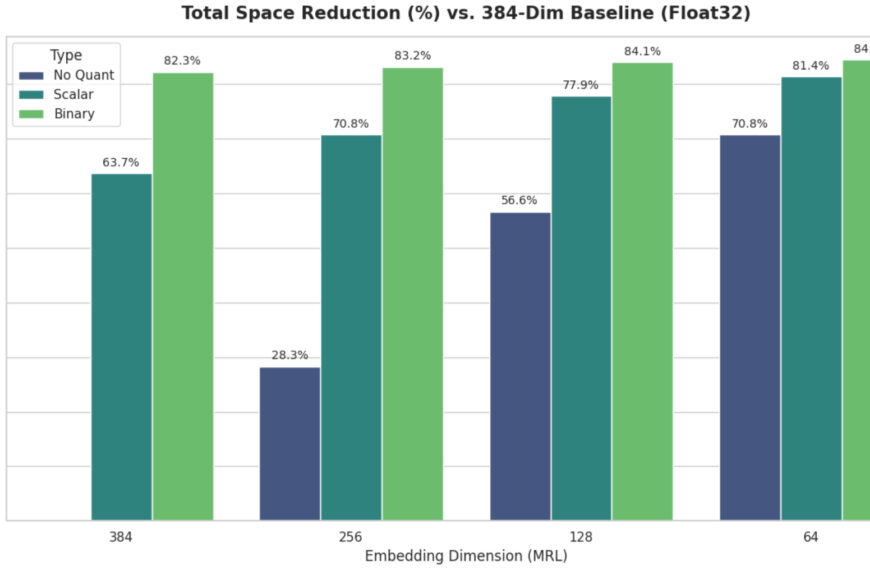
Рассмотрение реляционных таблиц как взаимосвязанных графов, основанное на достижениях в области обучения графов, позволяет обучать базовые модели, которые обобщаются на произвольные таблицы, признаки и задачи.
Быстрые ссылки
- Делиться
Реляционные базы данных составляют основную массу корпоративных форматов данных и лежат в основе многих сервисов прогнозирования в Google, а также других сервисов, используемых людьми ежедневно, таких как рекомендации контента или прогнозирование трафика. Большинство сложных приложений используют множество таблиц — на самом деле, некоторые сложные приложения в Google могут требовать поддержки сотен таблиц — и извлечение полезной информации из таких сетей таблиц представляет собой довольно сложную задачу. Традиционные методы машинного обучения (например, деревья решений) часто испытывают трудности с полным использованием структуры связей этих реляционных схем.
С другой стороны, последние достижения в области машинного обучения предлагают набор инструментов для построения графовых нейронных сетей (GNN), адаптированных для данных с графовой структурой, где задачи, актуальные для отрасли, могут быть сформулированы как классификация узлов (или регрессия) или прогнозирование на уровне графа. Однако большинство GNN привязаны к конкретному графу, на котором модель была обучена, и не могут обобщаться на новые графы с новыми узлами, типами ребер, признаками и метками узлов. Например, модель, обученная на большом графе цитирования с 100 миллионами узлов, не может быть повторно использована для вашего собственного графа (например, транзакций между пользователями и продуктами), поскольку пространства признаков и меток значительно различаются, поэтому вам придется переобучить ту же модель с нуля на ваших собственных данных. Хотя некоторые первоначальные попытки продемонстрировали жизнеспособность концепции в конкретных задачах прогнозирования связей и классификации узлов, до сих пор не существует универсальной модели, которая могла бы изучать осмысленные представления в реляционных данных и решать все задачи прогнозирования на уровне узлов, связей и графов.
Сегодня мы исследуем возможность создания единой модели, которая могла бы превосходно работать с взаимосвязанными реляционными таблицами и одновременно обобщаться на любой произвольный набор таблиц, признаков и задач без дополнительного обучения. Мы рады поделиться нашими последними достижениями в разработке таких моделей на основе графов (GFM), которые значительно расширяют границы обучения на графах и табличного машинного обучения, выходя далеко за рамки стандартных базовых моделей.
Реляционные таблицы в виде графов
Мы утверждаем, что использование структуры связей между таблицами является ключом к эффективным алгоритмам машинного обучения и повышению производительности на последующих этапах, даже когда табличные данные о характеристиках (например, цена, размер, категория) являются разреженными или зашумленными. Для этого единственным этапом подготовки данных является преобразование набора таблиц в единый гетерогенный граф.
Процесс довольно прост и может быть реализован в больших масштабах: каждая таблица становится уникальным типом узла, а каждая строка в таблице — узлом. Для каждой строки в таблице ее внешние ключи становятся типизированными ребрами к соответствующим узлам из других таблиц, в то время как остальные столбцы рассматриваются как характеристики узлов (как правило, с числовыми или категориальными значениями). При желании мы также можем сохранять временную информацию в качестве характеристик узлов или ребер.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Подготовка данных заключается в преобразовании таблиц в единый граф, где каждая строка таблицы становится узлом соответствующего типа, а столбцы внешних ключей — ребрами между узлами. Связи между пятью показанными таблицами становятся ребрами в результирующем графе.
Преобразование реляционных таблиц в графы для каждой целевой области приводит к созданию отдельных графов с различным количеством типов узлов, типов ребер, характеристик узлов и меток узлов. Следующая задача — создать единую обобщаемую модель машинного обучения, которую можно обучить на одном графе (наборе таблиц) и которая сможет выполнять вывод на любом неизвестном графе, несмотря на различия в структуре и схеме.
модели на основе графов
Типичный подход к построению базовых моделей заключается в использовании высокопроизводительной нейронной сети (например, трансформера), обученной на больших объемах разнообразных данных. Уникальной проблемой базовых моделей является отсутствие общего механизма токенизации для графов. В отличие от этого, при применении трансформера к языковым и компьютерным моделям каждая возможная строка может быть представлена токенами из подготовленного словаря, а изображения и видео могут быть закодированы с помощью фрагментов изображений соответственно.
Применительно к гетерогенным графам, построенным на основе реляционных данных, это требует переносимых методов кодирования произвольных схем баз данных — независимо от количества типов узлов (классов) и ребер между ними — и обработки характеристик узлов. Это включает в себя получение представления фиксированного размера для узлов, содержащих, например, три непрерывных параметра типа float или тридцать категориальных характеристик. Поскольку нам нужна единая модель, способная обобщаться на произвольные таблицы и типы узлов — например, обучение на графах цитирования и выполнение вывода на графах продуктов — мы не можем полагаться на жестко закодированные таблицы встраивания типов узлов. Аналогично, для характеристик узлов нам нужна модель, способная обобщаться от обучения на таких характеристиках, как «длина» и «сезон», к произвольным параметрам типа float и категориальным характеристикам, таким как «цена» и «размер».
Наш главный вывод заключается в том, что модели, обученные на «абсолютных» признаках набора данных, то есть на жестко закодированных таблицах встраивания или проекциях, специфичных для заданного распределения признаков, не обладают обобщающей способностью, в то время как учет взаимодействия признаков друг с другом в различных задачах приводит к лучшей обобщающей способности.
воспроизведение видео без звука зацикливание пауза видео без звука зацикливание включение звука видео выключение звука
Подобно моделям обработки естественного языка и зрения, таким как Gemini, GFM представляет собой единую модель, которая обучается переносимым представлениям графов, способным обобщаться на любой новый, ранее не встречавшийся граф, включая его схему, структуру и характеристики.
Результаты
Работа в масштабах Google подразумевает обработку графов, состоящих из миллиардов узлов и ребер, где наша среда JAX и масштабируемая инфраструктура TPU особенно эффективны. Такие объемы данных подходят для обучения универсальных моделей, поэтому мы протестировали нашу модель GFM на нескольких внутренних задачах классификации, таких как обнаружение спама в рекламе, что включает в себя десятки больших и связанных между собой реляционных таблиц. Типичные табличные базовые модели, хотя и масштабируемые, не учитывают связи между строками разных таблиц и, следовательно, упускают контекст, который может быть полезен для точных прогнозов. Наши эксперименты наглядно демонстрируют этот пробел.
Мы наблюдаем значительное повышение производительности по сравнению с лучшими базовыми моделями на основе одной таблицы. В зависимости от решаемой задачи, GFM обеспечивает прирост средней точности в 3–40 раз, что указывает на то, что структура графа в реляционных таблицах предоставляет важный сигнал, который могут использовать модели машинного обучения.

Выводы
Использование структуры данных для улучшения моделей машинного обучения — область, приобретающая все большее значение и имеющая широкое применение в искусственном интеллекте. Мы обнаружили, что адаптация подхода, основанного на базовой модели, к обучению на графах открывает новые возможности для повторного использования моделей и существенно улучшает обобщение при нулевом и малом количестве примеров. Эти результаты могут быть дополнительно улучшены за счет масштабирования и сбора разнообразных обучающих данных, а также более глубокого теоретического понимания обобщения.
Благодарности
В этой работе приняли участие следующие исследователи: Майкл Галкин, Брэндон Майер, Хамед Садеги, Матье Гийом-Берт, Арджун Гопалан, Саурабх Нагреча, Прамод Догупарти, Брайан Пероцци, Джонатан Халкроу, Сильвио Латтанци, Вахаб Миррокни и команда Google Research Graph Mining . Мы также хотели бы поблагодарить Кимберли Шведе за создание иллюстраций в этом посте.
Источник: research.google