
Практическое руководство по сравнению нескольких стратегий RAG — Keyword, FAISS и Chroma
Делиться

Ранее в своём блоге я рассказывал, как создать многоагентный SQL-помощник с использованием CrewAI и Streamlit. Пользователь мог выполнять запросы к базе данных SQLite на естественном языке. Агенты ИИ генерировали SQL-запрос на основе пользовательского ввода, проверяли его и проверяли на соответствие требованиям, прежде чем запустить его в базе данных для получения результатов. Я также реализовал контрольную точку с участием человека для контроля и отображал затраты LLM, связанные с каждым запросом, для прозрачности и контроля затрат. Хотя прототип был отличным и давал хорошие результаты для моей небольшой демонстрационной базы данных, я понимал, что для реальных баз данных этого будет недостаточно. В предыдущей настройке я отправлял всю схему базы данных в качестве контекста вместе с пользовательским вводом. По мере роста размера схем баз данных передача полной схемы в LLM увеличивает использование токенов, замедляет время отклика и повышает вероятность галлюцинаций. Мне нужен был способ передавать в LLM только релевантные фрагменты схемы. Здесь на помощь приходит RAG (Retrieval Augmented Generation) .
В этой записи блога я создаю менеджер RAG и добавляю несколько стратегий RAG в свой SQL-помощник, чтобы сравнить их производительность по таким показателям, как время отклика и использование токенов. Теперь помощник поддерживает четыре стратегии RAG:
- Нет RAG: соответствует полной схеме (базовый уровень для сравнения)
- RAG по ключевым словам: использует сопоставление ключевых слов, специфичных для домена, для выбора релевантных таблиц.
- FAISS RAG: использует семантическую векторную схожесть через FAISS с встраиванием всех MiniLM-L6-v2
- Chroma RAG: решение для постоянного хранения векторных данных на базе ChromaDB для масштабируемого поиска промышленного уровня
В этом проекте я сосредоточился только на практичных, лёгких и экономичных (бесплатных) методах RAG. Вы можете добавить любое количество реализаций и выбрать наиболее подходящую для вашего случая. Для упрощения экспериментов и анализа я создал интерактивный инструмент сравнения производительности, который оценивает сокращение количества токенов, количество таблиц, время ответа и точность запросов для всех четырёх стратегий.

Создание RAG-менеджера
Файл rag_manager.py содержит полную реализацию менеджера RAG. Сначала я создал класс BaseRAG — шаблон, который я использую для всех своих стратегий RAG. Он гарантирует, что каждый подход RAG будет следовать единой структуре. Любая новая стратегия будет включать два элемента: метод для получения соответствующей схемы на основе запроса пользователя и метод, поясняющий суть подхода. Используя абстрактный базовый класс (ABC), я сохраняю код чистым, модульным и легко расширяемым в дальнейшем.
из ввода import Dict, List, Any, Optional from abc import ABC, abstractmethod class BaseRAG(ABC): «»»Базовый класс для всех реализаций RAG.»»» def __init__(self, db_path: str = DB_PATH): self.db_path = db_path self.name = self.__class__.__name__ @abstractmethod def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str: «»»Получить соответствующую схему для запроса пользователя.»»» pass @abstractmethod def get_approach_info(self) -> Dict[str, Any]: «»»Получить информацию об этом подходе RAG.»»» pass
Стратегия «Нет RAG»
По сути, это тот же подход, который я использовал ранее, когда я передавал всю схему базы данных в качестве контекста в LLM без какой-либо фильтрации или оптимизации. Этот подход лучше всего подходит для очень небольших схем (предпочтительно менее 10 таблиц).
class NoRAG(BaseRAG): «»»Без RAG — возвращает полную схему.»»» def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str: return get_structured_schema(self.db_path) def get_approach_info(self) -> Dict[str, Any]: return { «name»: «Без RAG (полная схема)», «description»: «Использует полную схему базы данных», «pros»: [«Простой», «Всегда полный», «Не требует настройки»], «cons»: [«Высокое использование токенов», «Медленнее для больших схем»], «best_for»: «Небольшие схемы (< 10 таблиц)" }
Стратегия ключевых слов RAG
В подходе RAG по ключевым словам я использую набор предопределённых ключевых слов, сопоставленных с каждой таблицей в схеме. Когда пользователь задаёт вопрос, система проверяет соответствие ключевых слов в запросе и выбирает только наиболее релевантные таблицы. Таким образом, я не отправляю всю схему в LLM, что экономит токены и ускоряет процесс. Этот подход хорошо работает, когда ваша схема знакома, а запросы связаны с бизнесом или следуют распространённым шаблонам.
Метод _build_table_keywords(self) лежит в основе работы логики сопоставления ключевых слов. Он содержит жёстко заданное сопоставление ключевых слов для каждой таблицы в схеме. Он помогает связать термины пользовательского запроса (например, «продажи», «бренд», «клиент») с наиболее релевантными таблицами.
class KeywordRAG(BaseRAG): «»»RAG на основе ключевых слов с использованием сопоставления бизнес-контекста.»»» def __init__(self, db_path: str = DB_PATH): super().__init__(db_path) self.table_keywords = self._build_table_keywords() def _build_table_keywords(self) -> Dict[str, List[str]]: «»»Создать сопоставления ключевых слов для каждой таблицы.»»» return { 'products': ['product', 'item', 'catalog', 'price', 'category', 'brand', 'sales', 'sold'], 'product_variants': ['variant', 'product', 'sku', 'color', 'size', 'brand', 'sales', 'sold'], 'customers': ['клиент', 'пользователь', 'клиент', 'покупатель', 'лицо', 'электронная почта', 'имя'], 'заказы': ['заказ', 'покупка', 'транзакция', 'продажа', 'купить', 'итого', 'сумма', 'продажи'], 'элементы_заказа': ['элемент', 'товар', 'количество', 'строка', 'деталь', 'продажи', 'продано', 'бренд'], 'платежи': ['платеж', 'оплата', 'деньги', 'выручка', 'сумма'], 'инвентарь': ['инвентарь', 'запас', 'количество', 'склад', 'доступно'], 'отзывы': ['отзыв', 'рейтинг', 'отзыв', 'комментарий', 'мнение'], 'поставщики': ['поставщик', 'продавец', 'закупка', 'закупка'], 'категории': ['категория', 'тип', 'классификация', 'группа'], 'бренды': ['бренд', 'производитель', 'компания', 'продажи', 'продано', 'количество', 'итого'], 'адреса': ['адрес', 'местоположение', 'доставка', 'выставление счетов'], 'отгрузки': ['отгрузка', 'доставка', 'доставка', 'отслеживание'], 'скидки': ['скидка', 'купон', 'акция', 'предложение'], 'склады': ['склад', 'объект', 'location', 'storage'], 'employees': ['employee', 'staff', 'worker', 'person'], 'departments': ['department', 'divise', 'team'], 'product_images': ['image', 'photo', 'picture', 'media'], 'purchase_orders': ['purchase', 'procurement', 'supplier', 'order'], 'purchase_order_items': ['purchase', 'procurement', 'supplier', 'item'], 'order_discounts': ['discount', 'coupon', 'promotion', 'order'], 'shipment_items': ['shipment', 'delivery', 'item', 'tracking'] } def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str: import re # Оценка таблиц по релевантности ключевых слов query_words = set(re.findall(r'bw+b', user_query.lower())) table_scores = {} for table_name, keywords in self.table_keywords.items(): score = 0 # Подсчет совпадений ключевых слов for keyword in keywords: if keyword in query_words: score += 3 # Частичные совпадения for query_word in query_words: if keyword in query_words or query_word in keyword: score += 1 # Бонус за точное совпадение имени таблицы if table_name.lower() in query_words: score += 10 table_scores[table_name] = score # Получение таблиц с наивысшими оценками sorted_tables = sorted(table_scores.items(), key=lambda x: x[1], reverse=True) relevant_tables = [table for table, score in sorted_tables[:max_tables] if score > 0] # Возврат к таблицам по умолчанию, если совпадений нет if not relevant_tables: relevant_tables = self._get_default_tables(user_query)[:max_tables] # Построить схему для выбранных таблиц return self._build_schema(relevant_tables) def _get_default_tables(self, user_query: str) -> List[str]: «»»Получить таблицы по умолчанию на основе шаблонов запросов.»»» query_lower = user_query.lower() # Запросы по продажам/доходу if any(word in query_lower for word in ['revenue', 'sales', 'total', 'amount', 'brand']): return ['orders', 'order_items', 'product_variants', 'products', 'brands'] # Запросы по продуктам if any(word in query_lower for word in ['product', 'item', 'catalog']): return ['products', 'product_variants', 'categories', 'brands'] # Запросы клиентов if any(word in query_lower for word in ['customer', 'user', 'buyer']): return ['customers', 'orders', 'addresses'] # Значение по умолчанию return ['products', 'customers', 'orders', 'order_items'] def _build_schema(self, table_names: List[str]) -> str: «»»Строка построения схемы для указанных таблиц.»»» if not table_names: return get_structured_schema(self.db_path) conn = sqlite3.connect(self.db_path) cursor = conn.cursor() schema_lines = [«Доступные таблицы и columns:»] try: for table_name in table_names: cursor.execute(f»PRAGMA table_info({table_name});») columns = cursor.fetchall() if columns: col_names = [col[1] for col in columns] schema_lines.append(f»- {table_name}: {', '.join(col_names)}») Finally: conn.close() return 'n'.join(schema_lines) def get_approach_info(self) -> Dict[str, Any]: return { «name»: «Ключевое слово RAG», «description»: «Использует ключевые слова бизнес-контекста для сопоставления релевантных таблиц», «pros»: [«Быстро», «Нет внешних зависимостей», «Подходит для бизнес-запросов»], «cons»: [«Ограничено предопределенными ключевыми словами», «Может пропускать сложные связи»], «best_for»: «Бизнес-запросы с четкими терминами предметной области» }
Подход FAISS RAG
Стратегия FAISS RAG — это то, где всё становится умнее. Вместо того, чтобы выгружать всю схему целиком, я встраиваю метаданные каждой таблицы (столбцы, связи, бизнес-контекст) в векторы с помощью преобразователя предложений. Когда пользователь задаёт вопрос, он также встраивается в этот запрос и использует FAISS для семантического поиска по «значению», а не только по ключевым словам. Это идеально подходит для запросов, где пользователи не слишком конкретны, или когда в таблицах есть связанные термины. Мне нравится FAISS, потому что он бесплатный, работает локально и даёт довольно точные результаты, экономя токены.
Единственная загвоздка в том, что настройка требует дополнительных шагов и потребляет больше памяти, чем базовые подходы. Магистры уровня магистра права (LLM) и модели встраивания не понимают, что означают ваши таблицы, пока вы им это не объясните. В методе _get_business_context() нам нужно вручную написать краткое описание того, что каждая таблица представляет в бизнесе.
В методе _extract_table_info() я извлекаю имена таблиц, имена столбцов и связи по внешнему ключу из запросов PRAGMA SQLite для создания словаря со структурированной информацией о каждой таблице. Наконец, в методе _create_table_description() создаются подробные описания для каждой таблицы, которые затем встраиваются с помощью SentenceTransformer.
class FAISSVectorRAG(BaseRAG): «»»Векторный RAG на основе FAISS с использованием преобразователей предложений.»»» def __init__(self, db_path: str = DB_PATH): super().__init__(db_path) self.model = None self.index = None self.table_info = {} self.table_names = [] self._initialize() def _initialize(self): «»»Инициализация хранилища векторов FAISS и встраиваний.»»» try: from sentence_transformers import SentenceTransformer import faiss import numpy as np print(«🔄 Инициализация векторного RAG FAISS…») # Загрузка модели встраивания self.model = SentenceTransformer('all-MiniLM-L6-v2') print(«✅ Загруженная модель встраивания: all-MiniLM-L6-v2″) # Извлечение информации о таблице и создаем вложения self.table_info = self._extract_table_info() # Создаем вложения для каждой таблицы table_descriptions = [] self.table_names = [] for table_name, info in self.table_info.items(): description = self._create_table_description(table_name, info) table_descriptions.append(description) self.table_names.append(table_name) # Сгенерируем вложения print(f»🔄 Generating embeddings for {len(table_descriptions)} tables…») embeddings = self.model.encode(table_descriptions) # Создаем индекс FAISS dimension = embeddings.shape[1] self.index = faiss.IndexFlatIP(dimension) # Внутреннее произведение для косинусного сходства # Нормализуем вложения для косинусного сходства faiss.normalize_L2(embeddings) self.index.add(embeddings.astype('float32')) print(f»✅ Вектор FAISS RAG инициализирован с помощью {len(table_descriptions)} таблиц») except Exception as e: print(f»❌ Ошибка инициализации Вектор FAISS RAG: {e}») self.model = None self.index = None def _extract_table_info(self) -> Dict[str, Dict]: «»»Извлечь подробную информацию о каждой таблице.»»» conn = sqlite3.connect(self.db_path) cursor = conn.cursor() table_info = {} try: # Получить все имена таблиц cursor.execute(«SELECT name FROM sqlite_master WHERE type='table';») tables = cursor.fetchall() for (table_name,) in tables: info = { 'columns': [], 'foreign_keys': [], 'business_context': self._get_business_context(table_name) } # Получить информацию о столбце cursor.execute(f»PRAGMA table_info({table_name});») columns = cursor.fetchall() for col in columns: info['columns'].append({ 'name': col[1], 'type': col[2], 'primary_key': bool(col[5]) }) # Получить информацию о внешнем ключе cursor.execute(f»PRAGMA foreign_key_list({table_name});») fks = cursor.fetchall() for fk in fks: info['foreign_keys'].append({ 'column': fk[3], 'references_table': fk[2], 'references_column': fk[4] }) table_info[table_name] = info Finally: conn.close() return table_info def _get_business_context(self, table_name: str) -> str: «»»Получить описание бизнес-контекста для таблиц.»»» contexts = { 'products': 'Каталог товаров с товарами, ценами, категориями и информацией о бренде. Основные данные о запасах.', 'product_variants': 'Вариации товаров, такие как цвета, размеры, артикулы. Связывает товары с конкретными продаваемыми товарами.', 'customers': 'Профили клиентов с личной информацией, контактными данными и статусом счета.', 'orders': 'Транзакции покупок с итоговыми суммами, датами, статусом и отношениями с клиентами.', 'order_items': 'Отдельные позиции в заказах. Содержит количество, цены и артикулы продуктов.', 'payments': 'Записи об обработке платежей с указанием методов, сумм и статуса транзакции.', 'inventory': 'Уровни запасов и количество на складе для вариантов продукта.', 'reviews': 'Отзывы клиентов, рейтинги и обзоры продуктов.', 'suppliers': 'Информация о поставщиках для управления закупками и цепочками поставок.', 'categories': 'Иерархия категоризации продуктов для организации каталога.', 'brands': 'Информация о бренде для целей продуктов и маркетинга.', 'addresses': 'Информация об адресе доставки и выставлении счетов клиенту.', 'shipments': 'Информация об отслеживании доставки и статусе доставки.', 'discounts': 'Промокоды, купоны и дисконтные кампании.', 'warehouses': 'Местоположение складских помещений и управление складом.', 'employees': 'Информация о персонале и организационная структура.', 'departments': 'Организационные подразделения и структура команды.', 'product_images': 'Фотографии продукции и медиаресурсы.', 'purchase_orders': 'Заказы на закупку от поставщиков.', 'purchase_order_items': 'Позиции заказов на закупку у поставщиков.', 'order_discounts': 'Примененные скидки и акции к заказам.', 'shipment_items': 'Отдельные товары в упаковках отгрузки.' } return contexts.get(table_name, f'Таблица базы данных для операций, связанных с {table_name}.') def _create_table_description(self, table_name: str, info: Dict) -> str: «»»Создать полное описание для встраивания.»»» description = f»Таблица: {table_name}n» description += f»Цель: {info['business_context']}n» # Добавить информацию о столбцах description += «Столбцы: » col_names = [col['name'] for col in info['columns']] description += «, «.join(col_names) + «n» # Добавить информацию о связях if info['foreign_keys']: description += «Связи: » relationships = [] for fk in info['foreign_keys']: relationships.append(f»ссылки на {fk['references_table']} через {fk['column']}») description += «; «.join(relationships) + «n» # Добавить общие варианты использования на основе типа таблицы use_cases = self._get_use_cases(table_name) if use_cases: description += f»Common requests: {use_cases}» return description def _get_use_cases(self, table_name: str) -> str: «»»Получите общие варианты использования для каждой таблицы.»»» use_cases = { 'products': 'поиск продуктов, листинги каталогов, запросы цен, проверки запасов', 'customers': 'поиск клиентов, анализ регистрации, географическое распределение', 'orders': 'анализ продаж, отслеживание доходов, история заказов, мониторинг статуса', 'order_items': 'эффективность продаж продуктов, доход по продуктам, состав заказа', 'payments': 'обработка платежей, сверка доходов, анализ способов оплаты', 'brands': 'эффективность бренда, продажи по бренду, сравнение брендов', 'категории': 'анализ категорий, организация продукта, структура каталога' } return use_cases.get(table_name, 'общие запросы данных и анализ') def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str: «»»Получите релевантную схему с помощью поиска по векторному сходству.»»» if self.model is None or self.index is None: print(«⚠️ FAISS не инициализирован, возвращаемся к полной схеме») return get_structured_schema(self.db_path) try: import faiss import numpy as np # Сгенерировать встраивание запроса query_embedding = self.model.encode([user_query]) faiss.normalize_L2(query_embedding) # Поиск похожих таблиц scores, indexes = self.index.search(query_embedding.astype('float32'), max_tables) # Получить соответствующие имена таблиц relevant_tables = [] for i, (score, idx) in enumerate(zip(scores[0], indexs[0])): if idx < len(self.table_names) and score > 0.1: # Минимальный порог схожести relevant_tables.append(self.table_names[idx]) # Откат, если соответствующие таблицы не найдены if not relevant_tables: print(«⚠️ Соответствующие таблицы не найдены, используются значения по умолчанию») relevant_tables = self._get_default_tables(user_query)[:max_tables] # Построить схему для выбранных таблиц return self._build_schema(relevant_tables) except Exception as e: print(f»⚠️ Не удалось выполнить поиск вектора: {e}, возвращаемся к полной схеме») return get_structured_schema(self.db_path) def _get_default_tables(self, user_query: str) -> List[str]: «»»Получить таблицы по умолчанию на основе шаблонов запросов.»»» query_lower = user_query.lower() if any(word in query_lower for word in ['revenue', 'sales', 'total', 'amount', 'brand']): return ['orders', 'order_items', 'product_variants', 'products', 'brands'] elif any(word in query_lower for word in ['product', 'item', 'catalog']): return ['products', 'product_variants', 'categories', 'brands'] elif any(word in query_lower for word in ['customer', 'user', 'buyer']): return ['customers', 'orders', 'addresses'] else: return ['products', 'customers', 'orders', 'order_items'] def _build_schema(self, table_names: List[str]) -> str: «»»Построить строку схемы для указанных таблиц.»»» if not table_names: return get_structured_schema(self.db_path) conn = sqlite3.connect(self.db_path) cursor = conn.cursor() schema_lines = [«Доступные таблицы и столбцы:»] try: for table_name in table_names: cursor.execute(f»PRAGMA table_info({table_name});») columns = cursor.fetchall() if columns: col_names = [col[1] for col in columns] schema_lines.append(f»- {table_name}: {', '.join(col_names)}») наконец: conn.close() return 'n'.join(schema_lines) def get_approach_info(self) -> Dict[str, Any]: return { «name»: «FAISS Vector RAG», «description»: «Использует семантические вложения и поиск по сходству векторов», «pros»: [«Семантическое понимание», «Обрабатывает сложные запросы», «Без затрат на API»], «cons»: [«Требуется загрузка модели», «Больше памяти», «Сложность настройки»], «best_for»: «Сложные запросы, большие схемы, семантические связи» }
Стратегия Chroma RAG
Chroma RAG — более удобная для продакшена версия FAISS, поскольку предлагает постоянное хранилище. Chroma хранит вложения локально, поэтому даже при перезапуске приложения индекс вектора сохраняется. Как и в FAISS, мне всё равно нужно вручную описывать назначение каждой таблицы в бизнес-терминах (в _get_business_context()). Я встраиваю описания схем и сохраняю их в ChromaDB. При инициализации загружается преобразователь предложений (MiniLM). Если вектор уже существует, он загружается. Если нет, я извлекаю информацию и описания и вызываю _populate_collection() для генерации и сохранения векторов. Этот процесс нужно выполнять только один раз или при изменении схемы.
Он быстрый, работает согласованно между сеансами и прост в настройке. Я выбрал его, потому что он бесплатный, не требует внешних сервисов и хорошо подходит для реальных сценариев, где требуется масштабирование без беспокойства о потере индекса вектора или необходимости каждый раз перерабатывать всё заново.
class ChromaVectorRAG(BaseRAG): «»»Векторный RAG на основе цветности с использованием преобразователей предложений с постоянным хранилищем.»»» def __init__(self, db_path: str = DB_PATH): super().__init__(db_path) self.model = None self.chroma_client = None self.collection = None self.table_info = {} self.table_names = [] self._initialize() def _initialize(self): «»»Инициализация хранилища векторов цветности и встраиваний.»»» try: import chromadb from sentence_transformers import SentenceTransformer print(«🔄 Инициализация RAG вектора цветности…») # Загрузка модели встраивания self.model = SentenceTransformer('all-MiniLM-L6-v2') print(«✅ Загруженная модель встраивания: all-MiniLM-L6-v2″) # Инициализация клиента Chroma (постоянное хранилище) self.chroma_client = chromadb.PersistentClient(path=»./data/chroma_db») # Получение или создание коллекции collection_name = «schema_tables» try: self.collection = self.chroma_client.get_collection(collection_name) print(«✅ Загружена существующая коллекция Chroma») except: # Создание новой коллекции, если она не существует self.collection = self.chroma_client.create_collection( name=collection_name, metadata={«description»: «Внедрения таблицы схемы базы данных»} ) print(«✅ Создана новая коллекция Chroma») # Извлечение информации о таблице и создание встраиваний self.table_info = self._extract_table_info() self._populate_collection() # Загрузка имен таблиц для справки self._load_table_names() print(f»✅ Вектор цветности RAG инициализирован с помощью {len(self.table_names)} таблиц») except Exception as e: print(f»❌ Ошибка инициализации Вектора цветности RAG: {e}») self.model = None self.chroma_client = None self.collection = None def _extract_table_info(self) -> Dict[str, Dict]: «»»Извлечь подробную информацию о каждой таблице.»»» conn = sqlite3.connect(self.db_path) cursor = conn.cursor() table_info = {} try: # Получить все имена таблиц cursor.execute(«SELECT name FROM sqlite_master WHERE type='table';») tables = cursor.fetchall() for (table_name,) in tables: info = { 'columns': [], 'foreign_keys': [], 'business_context': self._get_business_context(table_name) } # Получить информацию о столбце cursor.execute(f»PRAGMA table_info({table_name});») columns = cursor.fetchall() for col in columns: info['columns'].append({ 'name': col[1], 'type': col[2], 'primary_key': bool(col[5]) }) # Получить информацию о внешнем ключе cursor.execute(f»PRAGMA foreign_key_list({table_name});») fks = cursor.fetchall() for fk in fks: info['foreign_keys'].append({ 'column': fk[3], 'references_table': fk[2], 'references_column': fk[4] }) table_info[table_name] = info Finally: conn.close() return table_info def _get_business_context(self, table_name: str) -> str: «»»Получить описание бизнес-контекста для таблиц.»»» contexts = { 'products': 'Каталог товаров с товарами, ценами, категориями и информацией о бренде. Основные данные о запасах.', 'product_variants': 'Вариации товаров, такие как цвета, размеры, артикулы. Связывает товары с конкретными продаваемыми товарами.', 'customers': 'Профили клиентов с личной информацией, контактными данными и статусом счета.', 'orders': 'Транзакции покупок с итоговыми суммами, датами, статусом и отношениями с клиентами.', 'order_items': 'Отдельные позиции в заказах. Содержит количество, цены и артикулы продуктов.', 'payments': 'Записи об обработке платежей с указанием методов, сумм и статуса транзакции.', 'inventory': 'Уровни запасов и количество на складе для вариантов продукта.', 'reviews': 'Отзывы клиентов, рейтинги и обзоры продуктов.', 'suppliers': 'Информация о поставщиках для управления закупками и цепочками поставок.', 'categories': 'Иерархия категоризации продуктов для организации каталога.', 'brands': 'Информация о бренде для целей продуктов и маркетинга.', 'addresses': 'Информация об адресе доставки и выставлении счетов клиенту.', 'shipments': 'Информация об отслеживании доставки и статусе доставки.', 'discounts': 'Промокоды, купоны и дисконтные кампании.', 'warehouses': 'Местоположение складских помещений и управление складом.', 'employees': 'Информация о персонале и организационная структура.', 'departments': 'Организационные подразделения и структура команды.', 'product_images': 'Фотографии продукции и медиаресурсы.', 'purchase_orders': 'Заказы на закупку от поставщиков.', 'purchase_order_items': 'Позиции заказов на закупку у поставщиков.', 'order_discounts': 'Примененные скидки и акции к заказам.', 'shipment_items': 'Отдельные товары в упаковках отгрузки.' } return contexts.get(table_name, f'Таблица базы данных для операций, связанных с {table_name}.') def _populate_collection(self): «»»Заполнить коллекцию Chroma встраиванием таблиц.»»» if not self.collection or not self.table_info: return documents = [] metadatas = [] ids = [] for table_name, info in self.table_info.items(): # Создать полное описание description = self._create_table_description(table_name, info) documents.append(description) metadatas.append({ 'table_name': table_name, 'column_count': len(info['columns']), 'has_foreign_keys': len(info['foreign_keys']) > 0, 'business_context': info['business_context'] }) ids.append(f»table_{table_name}») # Добавить в коллекцию self.collection.add( documents=documents, metadatas=metadatas, ids=ids ) print(f»✅ Добавлено {len(documents)} встраиваний таблиц в коллекцию Chroma») def _create_table_description(self, table_name: str, info: Dict) -> str: «»»Создать полное описание для встраивания.»»» description = f»Таблица: {table_name}n» description += f»Цель: {info['business_context']}n» # Добавить информацию о столбцах description += «Столбцы: » col_names = [col['name'] for col in info['columns']] description += «, «.join(col_names) + «n» # Добавить информацию о связях if info['foreign_keys']: description += «Связи: » relationships = [] for fk in info['foreign_keys']: relationships.append(f»links to {fk['references_table']} via {fk['column']}») description += «; «.join(relationships) + «n» # Добавить общие варианты использования use_cases = self._get_use_cases(table_name) if use_cases: description += f»Общие запросы: {use_cases}» return description def _get_use_cases(self, table_name: str) -> str: «»»Получить общие варианты использования для каждой таблицы.»»» use_cases = { 'products': 'поиск продуктов, листинги каталогов, запросы цен, проверки инвентаря', 'customers': 'поиск клиентов, анализ регистрации, географическое распределение', 'orders': 'анализ продаж, отслеживание доходов, история заказов, мониторинг статуса', 'order_items': 'эффективность продаж продуктов, доход по продуктам, состав заказа', 'payments': 'обработка платежей, сверка доходов, анализ способов оплаты', 'brands': 'эффективность бренда, продажи по брендам, сравнение брендов', 'categories': 'анализ категорий, организация продуктов, структура каталога' } return use_cases.get(table_name, 'общие запросы к данным и анализ') def _load_table_names(self): «»»Загрузить имена таблиц из коллекции.»»» if not self.collection: return try: # Получить все элементы из коллекции results = self.collection.get() self.table_names = [metadata['table_name'] for metadata in results['metadatas']] except Exception as e: print(f»⚠️ Не удалось загрузить имена таблиц из Chroma: {e}») self.table_names = [] def get_relevant_schema(self, user_query: str, max_tables: int = 5) -> str: «»»Получите соответствующую схему с помощью поиска по сходству векторов Chroma.»»» if not self.collection: print(«⚠️ Chroma не инициализирована, возвращаемся к полной схеме») return get_structured_schema(self.db_path) try: # Поиск похожих таблиц results = self.collection.query( query_texts=[user_query], n_results=max_tables ) # Извлеките имена соответствующих таблиц relevant_tables = [] if results['metadatas'] and len(results['metadatas']) > 0: for metadata in results['metadatas'][0]: relevant_tables.append(metadata['table_name']) # Резервный вариант, если соответствующие таблицы не найдены if not relevant_tables: print(«⚠️ Соответствующие таблицы не найдены, используются значения по умолчанию») relevant_tables = self._get_default_tables(user_query)[:max_tables] # Построить схему для выбранных таблиц return self._build_schema(relevant_tables) except Exception as e: print(f»⚠️ Поиск Chroma не удался: {e}, возвращаемся к полной схеме») return get_structured_schema(self.db_path) def _get_default_tables(self, user_query: str) -> List[str]: «»»Получить таблицы по умолчанию на основе шаблонов запросов.»»» query_lower = user_query.lower() if any(word in query_lower for word in ['revenue', 'sales', 'total', 'amount', 'brand']): return ['orders', 'order_items', 'product_variants', 'products', 'brands'] elif any(word in query_lower for word in ['product', 'item', 'catalog']): return ['products', 'product_variants', 'categories', 'brands'] elif any(word in query_lower for word in ['customer', 'user', 'buyer']): return ['customers', 'orders', 'addresses'] else: return ['products', 'customers', 'orders', 'order_items'] def _build_schema(self, table_names: List[str]) -> str: «»»Построить строку схемы для указанных таблиц.»»» if not table_names: return get_structured_schema(self.db_path) conn = sqlite3.connect(self.db_path) cursor = conn.cursor() schema_lines = [«Доступные таблицы и столбцы:»] try: for table_name in table_names: cursor.execute(f»PRAGMA table_info({table_name});») columns = cursor.fetchall() if columns: col_names = [col[1] for col in columns] schema_lines.append(f»- {table_name}: {', '.join(col_names)}») Finally: conn.close() return 'n'.join(schema_lines) def get_approach_info(self) -> Dict[str, Any]: return { «name»: «Chroma Vector RAG», «description»: «Использует Chroma DB для постоянного хранения векторных данных с семантическим поиском», «pros»: [«Постоянное хранение», «Быстрые запросы», «Масштабируемость», «Простое управление»], «cons»: [«Требуется место на диске», «Время начальной настройки», «Дополнительные зависимости»], «best_for»: «Производственные среды, постоянные рабочие процессы, совместная работа в команде» }
Сравнение различных стратегий RAG
Этот класс RAGManager — центр управления переключением между различными стратегиями RAG. В зависимости от запроса пользователя он выбирает оптимальный подход, извлекает наиболее релевантную часть схемы и отслеживает производительность, такую как время отклика, экономия токенов и количество таблиц. Он также имеет функцию сравнения для параллельного сравнения всех RAG и сохраняет исторические метрики, чтобы можно было анализировать работу каждой из них с течением времени. Это очень удобно для тестирования наиболее эффективных стратегий и поддержания оптимизации.
Все различные классы стратегий RAG инициализируются и хранятся в self.approaches. Каждый подход RAG — это класс, наследующий от BaseRAG, поэтому все они имеют согласованный интерфейс (get_relevant_schema() и get_approach_info()). Это означает, что вы можете легко подключить новую стратегию (например, Pinecone или Weaviate), если она расширяет BaseRAG.
Метод get_relevant_schema() возвращает схему, соответствующую данному запросу, на основе выбранной стратегии. Если передана недопустимая стратегия или по какой-либо причине происходит сбой, метод автоматически возвращается к стратегии «Keyword RAG».
Метод compare_approaches() выполняет тот же запрос по всем стратегиям RAG. Он измеряет:
- Длина полученной схемы
- % сокращение токенов по сравнению с полной схемой
- Время отклика
- Количество возвращенных таблиц
Это действительно полезно для параллельного сравнения стратегий и выбора той, которая лучше всего подходит для вашего варианта использования.
class RAGManager: «»»Менеджер для нескольких подходов RAG.»»» def __init__(self, db_path: str = DB_PATH): self.db_path = db_path self.approaches = { 'no_rag': NoRAG(db_path), 'keyword': KeywordRAG(db_path), 'faiss': FAISSVectorRAG(db_path), 'chroma': ChromaVectorRAG(db_path) } self.performance_metrics = {} def get_available_approaches(self) -> Dict[str, Dict[str, Any]]: «»»Получить информацию обо всех доступных подходах RAG.»»» return { approach_id: approach.get_approach_info() for approach_id, approach in self.approaches.items() } def get_relevant_schema(self, user_query: str, подход: str = 'keyword', max_tables: int = 5) -> str: «»»Получите соответствующую схему, используя указанный подход.»»» если подход отсутствует в self.approaches: print(f»⚠️ Неизвестный подход '{approach}', возвращаемся к ключевому слову») подход = 'keyword' start_time = time.time() try: schema = self.approaches[approach].get_relevant_schema(user_query, max_tables) # Запись показателей производительности end_time = time.time() self._record_performance(approach, user_query, schema, end_time — start_time) return schema except Exception as e: print(f»⚠️ Ошибка с подходом {approach}: {e}») # Возврат к подходу с ключевым словом if approach != 'keyword': return self.get_relevant_schema(user_query, 'keyword', max_tables) else: return get_structured_schema(self.db_path) def compare_approaches(self, user_query: str, max_tables: int = 5) -> Dict[str, Any]: «»»Сравнить все подходы для заданного запроса.»»» results = {} full_schema = get_structured_schema(self.db_path) full_schema_length = len(full_schema) for approach_id, approach in self.approaches.items(): start_time = time.time() try: schema = approach.get_relevant_schema(user_query, max_tables) end_time = time.time() results[approach_id] = { 'schema': schema, 'schema_length': len(schema), 'token_reduction': ((full_schema_length — len(schema)) / full_schema_length) * 100, 'response_time': end_time — start_time, 'table_count': len([line for line in schema.split('n') if line.startswith('- ')]), 'success': True } except Exception as e: results[approach_id] = { 'schema': '', 'schema_length': 0, 'token_reduction': 0, 'response_time': 0, 'table_count': 0, 'success': False, 'error': str(e) } return results def _record_performance(self, approach: str, query: str, schema: str, response_time: float): «»»Запись показателей производительности для анализа.»»» if approach not in self.performance_metrics: self.performance_metrics[approach] = [] full_schema_length = len(get_structured_schema(self.db_path)) schema_length = len(schema) metrics = { 'query': query, 'schema_length': schema_length, 'token_reduction': ((full_schema_length — schema_length) / full_schema_length) * 100, 'response_time': response_time, 'table_count': len([line for line in schema.split('n') if line.startswith('- ')]), 'timestamp': time.time() } self.performance_metrics[approach].append(metrics) def get_performance_summary(self) -> Dict[str, Any]: «»»Получите сводку производительности для всех подходов.»»» summary = {} for approach, metrics_list in self.performance_metrics.items(): if not metrics_list: continue avg_token_reduction = sum(m['token_reduction'] for m in metrics_list) / len(metrics_list) avg_response_time = sum(m['response_time'] for m in metrics_list) / len(metrics_list) avg_table_count = sum(m['table_count'] for m in metrics_list) / len(metrics_list) summary[approach] = { 'queries_processed': len(metrics_list), 'avg_token_reduction': round(avg_token_reduction, 1), 'avg_response_time': round(avg_response_time, 3), 'avg_table_count': round(avg_table_count, 1) } return summary # Удобные функции для обратной совместимости def get_rag_enhanced_schema(user_query: str, db_path: str = DB_PATH, approach: str = 'keyword') -> str: «»»Получить расширенную RAG схему с использованием указанного подхода.»»» manager = RAGManager(db_path) return manager.get_relevant_schema(user_query, approach) # Глобальный кэшированный экземпляр _rag_manager_instance = None def get_cached_rag_manager(db_path: str = DB_PATH) -> RAGManager: «»»Получить кэшированный экземпляр менеджера RAG.»»» global _rag_manager_instance if _rag_manager_instance is None: _rag_manager_instance = RAGManager(db_path) return _rag_manager_instance
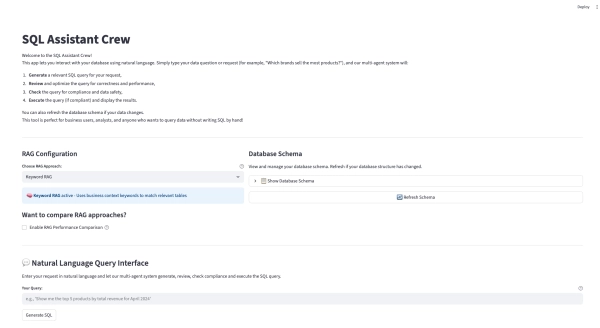
Приложение Streamlit полностью интегрировано с этим менеджером, поэтому пользователи могут выбирать нужную стратегию и видеть результаты в режиме реального времени. Полный код можно посмотреть на GitHub здесь. Вот рабочая демонстрация нового приложения:

Заключительные мысли
Это ещё не всё; многое ещё предстоит улучшить. Мне нужно провести стресс-тестирование на устойчивость к различным атакам и усилить защитные барьеры, чтобы уменьшить количество галлюцинаций и обеспечить безопасность данных. Было бы неплохо создать систему доступа на основе ролей для управления данными. Возможно, замена Streamlit на фронтенд-фреймворк, например, React, сделает приложение более масштабируемым для реальных развёртываний. Всё это в следующий раз.
Источник: towardsdatascience.com

























