
Повышение эффективности и производительности через инновационные стратегии маршрутизации.

Что такое LLM Routing?
В стремительно развивающемся мире искусственного интеллекта большие языковые модели (LLM) стали мощными инструментами, способными понимать и генерировать текст, близкий к человеческому.
По мере роста их сложности и масштабов всё более критичной становится необходимость эффективного управления путями обработки данных внутри модели.
Маршрутизация LLM (LLM routing) — это стратегическое распределение и оптимизация вычислительных ресурсов внутри LLM. Этот процесс определяет, каким образом входные данные проходят через различные внутренние пути модели, чтобы обеспечить максимально точные и релевантные выходные результаты.
Благодаря интеллектуальному направлению промптов и балансировке вычислительных нагрузок, маршрутизация повышает эффективность, отзывчивость и общую производительность языковых моделей.
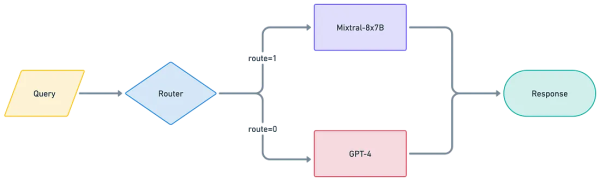
Как работает маршрутизация LLM?
Маршрутизатор направляет входящие промпты/задачи к наиболее подходящей модели или набору моделей в составе системы. В общем виде процесс выглядит так:
Анализ промпта. Маршрутизатор оценивает:
содержимое и намерение запроса;
требуемую экспертизу/доменные знания;
сложность задачи;
указанные предпочтения или ограничения пользователя.
Выбор модели. На основе анализа выбираются подходящие LLM с учётом:
возможностей и специализаций каждой модели;
метрик качества на похожих запросах в прошлом;
текущей загрузки и доступности моделей;
стоимости запуска разных моделей.
Проброс запроса. Промпт передаётся выбранной модели (или нескольким моделям) на обработку.
Агрегация ответа (если нужно). Если задействовано несколько моделей, маршрутизатор агрегирует и синтезирует их ответы.
Мониторинг качества. Маршрутизатор обычно отслеживает результаты своих решений, чтобы улучшать стратегию роутинга в будущем.

Рассмотрим пример RouteLLM, чтобы лучше понять концепцию
Контекст
По мере того как большие языковые модели (LLM), такие как GPT-4, становятся неотъемлемой частью множества приложений, организации сталкиваются с задачей нахождения баланса между производительностью и стоимостью.
Маршрутизация всех промптов в самые мощные модели обходится слишком дорого, тогда как использование более простых моделей может снижать качество ответов.
Обучение на наборе данных Arena
RouteLLM обучает свои маршрутизаторы в основном на данных предпочтений из датасета Chatbot Arena — система учится на сравнительных ответах разных моделей. Такой data-driven подход повышает эффективность техник маршрутизации.
Зачем нужна маршрутизация LLM
RouteLLM решает проблему, интеллектуально направляя промпты в зависимости от их сложности. Ключевые цели:
Снижение стоимости: простые промпты отправляются в более дешёвые модели, снижаются операционные расходы.
Сохранение качества: сложные промпты попадают в более сильные модели для высокого качества ответа.
Динамическая адаптация: система учится на данных и со временем улучшает решения по роутингу.
Используемые техники маршрутизации
RouteLLM применяет несколько подходов:
Similarity-Weighted (SW) Ranking: взвешенное по сходству ранжирование, вычисляющее, какая модель лучше под данный промпт.
Матричная факторизация: обучение скоринговой функции, оценивающей, насколько хорошо каждая модель ответит на промпт.
Классификатор на BERT: предсказывает, какая модель даст лучший ответ для входа.
Каузальный LLM-классификатор: аналогично BERT-классификатору, помогает выбрать лучшую модель под запрос.
Реализация
RouteLLM обучает эти маршрутизаторы на данных предпочтений, чтобы предсказывать оптимальную модель под каждый промпт. Для буста качества используется аугментация данных, что позволяет принимать более информированные решения при меньшем объёме исходных данных.
Результаты:
 обучены только на данных Arena; (справа) обучены на данных Arena, дополненных с помощью LLM-судьи. (Источник)")
Результаты работы на MT Bench: на графике показана производительность наших маршрутизаторов на MT Bench.
Производительность на датасете Arena (без аугментации):
Для маршрутизаторов, обученных только на датасете Arena, наблюдается высокая эффективность как у матричной факторизации, так и у SW-ранжирования (Similarity-Weighted).
Примечательно, что матричная факторизация достигает 95% уровня GPT-4, используя лишь 26% вызовов GPT-4, что примерно на 48% дешевле по сравнению со случайным бейзлайном.
Производительность с аугментацией данных:
Аугментация данных Arena с помощью LLM-судьи приводит к существенным улучшениям у всех маршрутизаторов.
На аугментированном датасете матричная факторизация остаётся лучшим маршрутизатором, требуя всего 14% вызовов для достижения 95% уровня GPT-4.
Это соответствует снижению затрат на 75% относительно случайного бейзлайна.
Проблемы маршрутизации LLM
Оценка сложности промпта.
Ключевой вызов — корректно определить сложность запроса. Простые вопросы вроде «Столица Франции?» можно отправлять в более лёгкие модели; сложные требуют более мощных. Ошибка в оценке ведёт либо к лишним расходам (перенаправили в слишком сильную модель), либо к низкому качеству ответа (отправили в слишком простую).Управление задержкой (latency).
Когда задействовано несколько моделей, важно быстро направить запрос в лучшую модель без потери качества. Более мощные модели обычно медленнее; батчинг снижает стоимость, но может увеличить время ответа. Это постоянный баланс.Баланс цена/качество.
Сильные модели (например, GPT-4) дают высокое качество, но дороги. Роутинг простых запросов в дешёвые модели сокращает расходы, но чреват просадкой качества на сложных кейсах. Нужен взвешенный компромисс.
Оценка маршрутизаторов LLM на бенчмарках
Часто используют несколько датасетов, чтобы получить комплексную картину:
GSM8K: проверяет математическое рассуждение на задачах со ступенчатым решением.
MTBench: универсальный бенчмарк по разным типам задач; измеряет, насколько хорошо маршрутизатор направляет запросы в подходящие модели.
MBPP: оценка генерации кода; позволяет понять, насколько эффективно маршрутизатор справляется с программными задачами, направляя их в нужные модели.
Отсутствие стандартного бенчмарка для оценки маршрутизаторов долго тормозило прогресс. Чтобы закрыть этот пробел, предложен новый фреймворк ROUTERBENCH — систематическая оценка эффективности систем маршрутизации LLM с датасетом из 405k+ результатов инференса от репрезентативных моделей.
ROUTERBENCH не только формализует и продвигает разработку маршрутизаторов LLM, но и задаёт стандарт их оценки. Теоретическая рамка и сравнительный анализ подходов, представленные в ROUTERBENCH, показывают их сильные и слабые стороны, прокладывая путь к более доступным и экономичным вариантам развертывания LLM.
Для детального изучения код и датасет ROUTERBENCH доступны здесь: GitHub.
Дополнительные публикации
Hybrid LLM: экономичная и чувствительная к качеству маршрутизация промптов
Большие языковые модели (LLM) показывают выдающуюся точность по большинству задач NLP, но их деплой требует дорогих облачных ресурсов. Напротив, более лёгкие модели, которые можно запускать на недорогих edge-устройствах, часто уступают по качеству ответов. Чтобы закрыть этот разрыв, предлагается гибридный инференс, сочетающий сильные стороны обоих классов моделей.
Подход использует маршрутизатор, который динамически направляет запросы либо в малую, либо в большую модель на основе предсказанной сложности промпта и требуемого уровня качества, причём целевой уровень качества можно менять на этапе инференса. Такая гибкость позволяет тонко балансировать между качеством и ценой под конкретный сценарий. Эксперименты показывают, что метод даёт до 40% меньше обращений к большой модели без ухудшения качества.Маршрутизация больших языковых моделей с опорой на бенчмарк-датасеты
С быстрым ростом числа open-source LLM и появлением множества бенчмарк-датасетов для их оценки стало очевидно, что ни одна отдельная модель не показывает наилучших результатов во всех задачах и сценариях использования. В данной работе рассматривается проблема выбора оптимальной LLM из пула доступных моделей для решения новых задач.
Предлагается переиспользовать бенчмарк-датасеты для обучения модели-маршрутизатора. Формулировка сводится к серии задач бинарной классификации. Результаты демонстрируют как полезность, так и ограничения обучения роутеров на разных бенчмарках, при этом подход стабильно превосходит стратегию «одна модель на все случаи».Синергия «множественных умов»: уроки маршрутизации LLM
С развитием LLM возникает вызов: эффективно направлять входные запросы в наиболее подходящую модель, особенно для задач сложного рассуждения.
Обширные эксперименты показывают, что маршрутизация LLM перспективна, но не универсальна. Таким образом, необходимы дальнейшие исследования и разработка более устойчивых и надежных методов, способных компенсировать текущие ограничения подхода.
Выводы
Маршрутизация LLM — ключевая стратегия оптимизации деплоймента больших языковых моделей, позволяющая сбалансировать стоимость и качество. Используя различные техники маршрутизации и бенчмарк-датасеты (например, ROUTERBENCH), исследователи могут системно оценивать и улучшать эффективность маршрутизации. Полученные инсайты улучшают выбор моделей и прокладывают путь к экономически целесообразным решениям на базе LLM в широком спектре приложений. По мере развития области критически важно продолжать исследования и доводить стратегии маршрутизации до максимальной отдачи в реальных сценариях.
Вдогонку к посту — самое полезное:
Люди больше не нужны? Профессии, которые уже заменил ИИ
MCP-серверы: зачем они нужны и почему о них скоро будут говорить все
Как AI-редактор Cursor меняет процесс разработки — и стоит ли ему доверять
Retrieval-Augmented Generation (RAG): глубокий технический обзор
Источник: habr.com

























