
Мы представляем LSM-2 с адаптивным и наследуемым маскированием (AIM), новый подход к самообучению, который обучается непосредственно на неполных данных с носимых датчиков, демонстрируя высокую производительность в задачах классификации, регрессии и генерации без явного заполнения пропущенных данных.
Быстрые ссылки
- Бумага
- Делиться
Носимые устройства произвели революцию в мониторинге здоровья, предоставляя непрерывные, многомодальные физиологические и поведенческие данные — от сигналов сердца и режима сна до уровня активности и показателей стресса. Благодаря достижениям в сенсорных технологиях становится все более возможным сбор больших объемов данных, но стоимость разметки остается высокой, требуя аннотирования пользователями в режиме реального времени или трудоемких клинических исследований. Самообучение (SSL) решает эту проблему, напрямую используя неразмеченные данные для изучения базовых структур, таких как тонкие физиологические взаимосвязи. При применении в больших масштабах SSL позволяет создавать базовые модели, которые обеспечивают богатые и обобщаемые представления, полезные для широкого спектра задач в области здравоохранения.
Однако при применении SSL к носимым устройствам существует критическое ограничение: современные методы SSL предполагают полные, непрерывные данные — редкость в реальных потоках данных с носимых датчиков, где неизбежно возникают пробелы из-за извлечения устройства, зарядки, периодического ослабления крепления, артефактов движения, режимов энергосбережения или шума окружающей среды, которые мы количественно оцениваем как «пропущенные данные». Фактически, мы обнаружили, что ни один образец из наших 1,6 миллиона окон длительностью в сутки не имел 0% пропущенных данных . Исторически сложилось так, что проблема фрагментированных данных заставляла исследователей полагаться либо на методы импутации для заполнения пропущенных сегментов, либо на агрессивную фильтрацию для удаления случаев с неполными данными. Ни один из этих методов не является оптимальным решением, поскольку первый может вносить непреднамеренные искажения, а второй отбрасывает ценные данные.

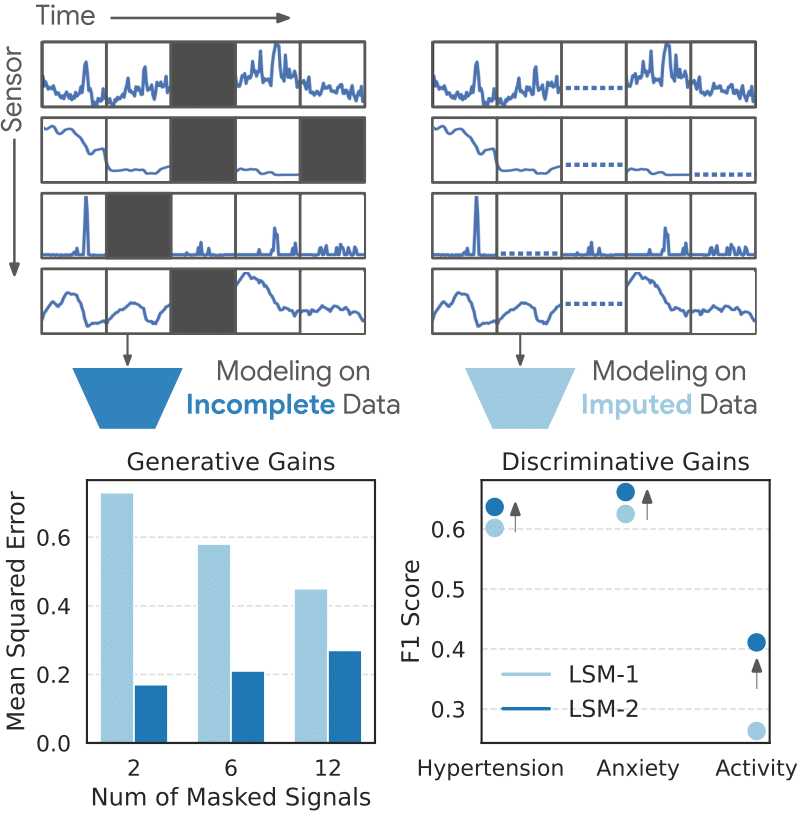
Пропущенные данные повсеместно встречаются в записях с носимых датчиков. Типичные виды пропущенных данных показаны выше на примере выборки данных с многомодальных носимых датчиков за целый день. Мы отмечаем, что ни в одной из наших выборок из 1,6 миллиона окон, охватывающих целый день, не наблюдается 0% пропущенных данных.
В статье «LSM-2: Обучение на основе неполных данных с носимых датчиков» мы представляем адаптивное и наследуемое маскирование (AIM), новую структуру обучения SSL, которая обучается непосредственно на неполных данных. Вместо того чтобы рассматривать пробелы в данных как ошибочные измерения, которые необходимо заполнить, AIM обучается непосредственно на неполных записях, рассматривая отсутствие данных как естественный артефакт реальных данных. Используя AIM, мы разрабатываем модель больших датчиков (LSM-2), которая улучшает нашу предыдущую базовую модель для данных с носимых датчиков (LSM-1, представленную на ICLR '25). Мы демонстрируем, что LSM-2 показывает высокую производительность даже при отказах датчиков или удалении временных окон, демонстрируя значительно меньшее ухудшение, чем модели, обученные на данных с заполненными пропущенными значениями.
Применение AIM с адаптивной наследуемой маскировкой
В основе инноваций AIM лежит уникальный подход к обработке неизбежных пробелов в реальных данных с датчиков. В отличие от традиционных методов SSL, которые либо отбрасывают неполные данные, либо пытаются заполнить пропущенные значения, AIM рассматривает эти пробелы как естественные особенности данных носимых устройств. Как расширение структуры предварительного обучения маскированного автокодировщика (MAE), AIM изучает базовую структуру данных с датчиков путем восстановления маскированных входных образцов.
Однако, в то время как традиционные методы MAE полагаются на фиксированное соотношение маскирования для эффективного удаления замаскированных токенов (т.е. фиксированное количество замаскированных токенов не проходит через кодировщик, что снижает вычислительную сложность), фрагментация в данных датчика непредсказуема, что приводит к переменному количеству замаскированных токенов. AIM решает эту фундаментальную проблему данных носимых устройств, сочетая удаление токенов с маскированием внимания. Во время предварительного обучения набор токенов для маскирования состоит из тех, которые унаследованы от данных носимого датчика и присущи им, плюс те, которые были намеренно замаскированы для цели обучения реконструкции.
Сначала AIM применяет механизм Dropout к фиксированному числу замаскированных токенов, повышая вычислительную эффективность предварительного обучения за счет уменьшения длины последовательности, обрабатываемой кодировщиком. Затем AIM адаптивно обрабатывает любые оставшиеся замаскированные токены — будь то отсутствующие естественным образом или являющиеся частью задачи реконструкции — с помощью механизма маскирования внимания в блоке преобразования кодировщика. Во время тонкой настройки и оценки дискриминативной задачи, где замаскированные токены состоят исключительно из естественных пробелов в данных, AIM применяет механизм маскирования внимания ко всем замаскированным токенам. Благодаря этому двойному подходу к маскированию и рассматривая естественные и искусственно замаскированные токены как эквивалентные, AIM обучает модель работать с переменной фрагментацией, присущей носимым датчикам.

Предварительное обучение ( A ) и оценка ( B ) AIM для LSM-2. На этапе предварительного обучения AIM использует искусственную маску для обучения реконструкции и унаследованную маску для моделирования реальных пропусков данных. Затем, на этапе оценки, мы можем использовать встраивание с учетом пропусков данных для прогнозирования показателей здоровья, таких как гипертония, непосредственно из изначально фрагментированных данных датчиков.
Обучение и оценка
Мы используем набор данных, содержащий 40 миллионов часов данных с носимых устройств, полученных от более чем 60 000 участников в период с марта по май 2024 года. Набор данных был тщательно анонимизирован или обезличен, чтобы гарантировать удаление информации об участниках и сохранение конфиденциальности. Участники носили различные смарт-часы и трекеры Fitbit и Google Pixel и дали согласие на использование своих данных для исследований и разработки новых продуктов и услуг в области здоровья и благополучия. Участников попросили самостоятельно указать пол, возраст и вес.
Для предварительного обучения LSM-2 мы используем технику AIM SSL, представленную в предыдущем разделе. AIM реализует целевую функцию обучения с использованием маскированной реконструкции и учится понимать данные, которые естественным образом отсутствуют, и заполнять данные, которые искусственно замаскированы. Эта унифицированная структура позволяет LSM-2 изучать базовую структуру (включая отсутствие данных), присущую данным носимых датчиков.
Мы подготовили набор задач для оценки предварительно обученной модели, используя метаданные, собранные вместе с сигналами датчиков в целях исследований и разработок. К ним относятся аннотированные пользователями действия из 20 различных категорий (таких как бег, катание на лыжах, гребля на байдарках и игра в гольф), а также самостоятельно сообщенные диагнозы гипертонии и тревожности. Эти данные были разделены на наборы для тонкой настройки и оценки, где данные от каждого отдельного пользователя присутствовали только в наборе для настройки или в наборе для оценки, но не в обоих одновременно. Данные от пользователей, использованные на этапе предварительного обучения, также не были включены в этапы тонкой настройки или оценки.
Генеративные возможности LSM-2 оцениваются на основе задач случайной импутации, временной интерполяции, временной экстраполяции (прогнозирования) и импутации данных с датчиков, описанных в нашей работе по LSM-1.
Полезность эмбеддингов LSM-2 оценивается с помощью линейного зондирования на ряде дискриминативных задач. В частности, мы оцениваем применимость эмбеддингов LSM-2 к задачам бинарной классификации гипертонии, бинарной классификации тревожности и распознавания активности по 20 классам. Мы оцениваем способность LSM-2 моделировать физиологию с помощью задач регрессии возраста и ИМТ.
Ключевые результаты
Модель LSM-2, основанная на алгоритме AIM, демонстрирует замечательную универсальность, превосходя своего предшественника, LSM-1, в трех ключевых областях: классификация состояний здоровья и видов деятельности (таких как гипертония, тревожность и распознавание активности по 20 классам), восстановление недостающих данных (например, восстановление отсутствующих сигналов датчиков) и прогнозирование непрерывных показателей здоровья (таких как ИМТ с улучшенной корреляцией). Дополнительные сравнения с контролируемыми и предварительно обученными базовыми моделями можно найти в нашей статье.

Модель LSM-2 моделирует реальные пропущенные данные без импутации, что позволяет ей достигать меньшей ошибки реконструкции ( слева ) и более высоких показателей классификации ( справа ) по сравнению с LSM-1 .
LSM-2 превосходно проявляет себя в реалистичных сценариях, когда датчики выходят из строя или данные неполны. На рисунке ниже смоделированы ситуации, когда могут отсутствовать полные потоки данных с датчиков или данные за целые периоды дня. Это отражает реальность, в которой разные носимые устройства могут иметь различное количество датчиков, или когда человек носит свое устройство только часть дня. Здесь мы видим, что LSM-2 на основе AIM оказывается более устойчивым к таким сбоям по сравнению с LSM-1.

LSM-2 более устойчив к отсутствующим данным, чем LSM-1, демонстрируя меньшее ухудшение характеристик по сравнению с предшественником ( пунктирная линия ) при исключении целых потоков данных с датчиков или периодов дня.
Наконец, LSM-2 демонстрирует улучшенную масштабируемость по количеству пользователей, объему данных, вычислительным ресурсам и размеру модели по сравнению с LSM-1. В то время как его предшественник демонстрирует признаки стагнации, LSM-2 продолжает улучшаться с увеличением объема данных и еще не достиг насыщения.

LSM-2 демонстрирует улучшенную масштабируемость по сравнению с LSM-1 в отношении испытуемых, данных, вычислительных ресурсов и размера модели.
Заключение
Базовая модель LSM-2, предварительно обученная с помощью AIM, представляет собой шаг вперед к созданию более полезных и удобных в использовании носимых медицинских технологий. В основе AIM лежит обучение LSM-2 пониманию и использованию естественных пробелов в реальных потоках данных с датчиков для получения надежных результатов из неполных данных. Это нововведение означает, что носимый ИИ наконец-то сможет учитывать сложную реальность данных с датчиков, сохраняя целостность данных и используя всю доступную информацию.
Благодарности
Описанное здесь исследование является результатом совместной работы Google Research, Google Health, Google DeepMind и партнерских команд. В этой работе приняли участие следующие исследователи: Максвелл А. Сюй, Гириш Нараянсвами, Кумар Аюш, Димитрис Спатис, Шун Ляо, Шьям Тейлор, Ахмед Метвалли, А. Али Хейдари, Ювэй Чжан, Джейк Гаррисон, Сами Абдель-Гаффар, Сюйхай Сюй, Кен Гу, Джейкоб Саншайн, Мин-Жер По, Юн Лю, Тим Альтхофф, Шрикант Нараянан, Пушмит Коли, Марк Малхотра, Шветак Патель, Ючже Ян, Джеймс М. Рег, Синь Лю и Дэниел Макдафф. Мы также хотели бы поблагодарить участников, предоставивших свои данные для этого исследования.
Источник: research.google