
Анализ производительности различных конвейеров обработки данных.
Делиться

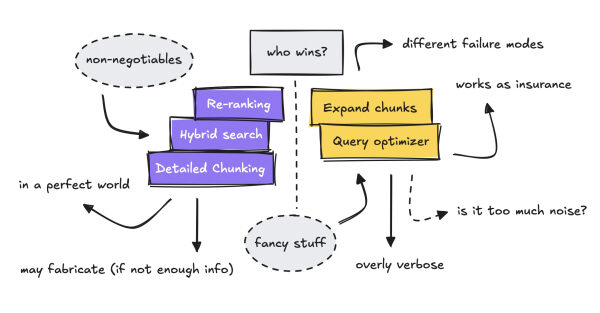
В прошлом году я написал статью об избыточном усложнении системы RAG, добавлении таких сложных вещей, как оптимизация запросов, детальное разбиение на блоки с использованием соседей и ключей, а также расширение контекста.
Аргумент против такого рода работ заключается в том, что за некоторые из этих дополнений вы все равно в итоге платите на 40–50% больше за счет увеличения задержки и стоимости.
Поэтому я решил протестировать оба конвейера : один с оптимизацией запросов и расширением соседних элементов , а другой — без них .
Первый тест, который я провел, использовал простые вопросы из корпуса, сгенерированные непосредственно из документации, и результаты были неутешительными. Но затем я продолжил тестирование на более сложных вопросах и на случайных вопросах из реальной жизни, и это показало нечто другое.
Именно об этом мы и поговорим здесь: где такие функции, как расширение списка соседей, могут быть полезны, а где затраты могут оказаться неоправданными.
Мы рассмотрим подготовку, дизайн эксперимента, три различных этапа оценки с разными наборами данных, как интерпретировать результаты и соотношение затрат и выгод.
Обратите внимание, что в этом эксперименте используются метрики без привязки к конкретному объекту и судьи уровня LLM, к чему всегда следует относиться с осторожностью. Полную разбивку результатов вы можете увидеть в этом документе Excel.
Если у вас возникнут вопросы, то перед этой статьей есть две другие, здесь и здесь, хотя эта статья вполне самодостаточна.
Вступление
Люди продолжают усложнять свои RAG-конвейеры, и на это есть причина. Общая конструкция имеет недостатки, поэтому мы постоянно вносим исправления, чтобы сделать систему более надежной.
Большинство пользователей внедрили в свои RAG-системы гибридный поиск, BM25 и семантический поиск, а также средства переранжирования. Это стало стандартной практикой. Но можно добавить и более сложные функции.

В тестируемом нами конвейере обработки данных добавлены две новые функции: оптимизация запросов и расширение списка соседних узлов, и проверена их эффективность.
Мы используем экспертов из LLM и различные наборы данных для оценки автоматизированных показателей, таких как достоверность, а также A/B-тесты качества, чтобы увидеть, как изменяются эти показатели.
Вводная часть будет посвящена подготовке и планированию эксперимента.
Настройка
Давайте сначала кратко рассмотрим настройку, подробно разберем разбиение на блоки и расширение соседей, а также то, что я определяю как сложный и наивный подход в рамках этой статьи.
В используемом мной здесь конвейере обработки данных применяются очень подробные методы разбиения на блоки, если вы читали мою предыдущую статью.
Это означает корректный анализ PDF-файлов, соблюдение структуры документа, использование интеллектуальной логики слияния, интеллектуальное определение границ, обработку числовых фрагментов и контекст на уровне документа (т.е. применение заголовков к каждому фрагменту).
Я решил не отступать от этой части, хотя это, очевидно, самая сложная часть построения конвейера извлечения данных.
В процессе обработки он также разделяет разделы, а затем ссылается на соседние фрагменты в метаданных. Это позволяет нам расширить содержимое, чтобы LLM мог увидеть, откуда оно взялось.
Для этого теста мы используем те же фрагменты данных, но удаляем оптимизацию запросов и расширение контекста для простого конвейера обработки, чтобы проверить, действительно ли эти дополнительные функции приносят какую-либо пользу.

Следует также отметить, что в качестве примера использования этого подхода рассматривались научные статьи RAG. Это довольно сложный случай, и поэтому для более простых задач он может быть неприменим (но об этом мы поговорим позже).
Здесь вы можете ознакомиться с документами, обработанными этим конвейером, а здесь прочитать о вариантах его использования.
В заключение: в данной конфигурации используется тот же алгоритм разбиения на блоки, тот же алгоритм переранжирования и тот же алгоритм LLM. Единственное отличие заключается в оптимизации запросов и расширении блоков до соседних элементов.
План эксперимента
У нас есть три разных набора данных, которые были обработаны с помощью нескольких автоматизированных метрик, а затем подвергнуты прямому сравнительному анализу, наряду с изучением результатов для подтверждения и понимания полученных данных.
Я начал с создания набора данных, содержащего 256 вопросов, сгенерированных на основе корпуса. Это означает вопросы типа: «Какова основная цель модели Step-Audio 2?»
Это может быть хорошим способом проверить работоспособность вашего конвейера, но если он слишком «чистый», это может создать ложное чувство безопасности.
Обратите внимание, что я не указал, как именно должны генерироваться вопросы. Это значит, что я не просил программу генерировать вопросы, на которые можно ответить во всем разделе, или вопросы, на которые можно ответить только в одном фрагменте текста.

Второй набор данных также был сгенерирован из корпуса, но я намеренно попросил LLM сгенерировать сложные вопросы, например: «Какие три типа функций вознаграждения используются в eviomni?»
Третий и наиболее важный набор данных представлял собой случайный набор данных.
Я попросил ИИ-агента изучить различные вопросы, которые люди задавали в интернете по поводу RAG, например: «Какие лучшие критерии оценки RAG и почему?» и «Когда использование заголовков/аннотаций превосходит поиск по полному тексту?».
Напомним, что в систему обработки данных было включено всего около 150 научных статей за сентябрь/октябрь, в которых упоминался RAG. Поэтому мы не знаем, содержит ли этот корпус вообще ответы.
Для проведения первых оценок я использовал автоматизированные метрики, такие как соответствие (соответствует ли ответ контексту) и релевантность ответа (соответствует ли он запросу) из RAGAS. Я также добавил несколько метрик из DeepEval для оценки релевантности контексту, структуры и наличия галлюцинаций.
Если вы хотите получить общее представление об этих показателях, ознакомьтесь с моей предыдущей статьей.
Мы запустили оба конвейера обработки данных по различным наборам данных, а затем по всем этим метрикам.
Затем я добавил еще одного эксперта для сравнительной оценки качества каждого конвейера обработки данных для каждого набора данных. Этот эксперт не видел контекста, только вопрос, ответ и автоматизированные метрики.
Почему бы не включить контекст в оценку? Потому что нельзя перегружать судей слишком большим количеством переменных. Именно поэтому оценка может казаться сложной. Необходимо понимать, какой ключевой показатель вы хотите измерить для каждого участника.
Следует отметить, что это может быть ненадежный способ тестирования систем. Если оценка галлюцинаций в основном основана на ощущениях, но мы удаляем точку данных из-за этого перед отправкой следующему эксперту, проверяющему качество, то в итоге мы можем получить крайне ненадежные данные после начала агрегирования.
В заключительной части мы рассмотрели семантическое сходство между ответами и изучили те, в которых наблюдались наибольшие различия, а также случаи, когда один метод явно превосходил другой.
Теперь перейдём к проведению эксперимента.
Проведение эксперимента
Поскольку у нас есть несколько разных наборов данных, нам нужно рассмотреть результаты каждого из них. Первые два набора данных оказались довольно невпечатляющими, но они кое-что нам показали, поэтому стоит их рассмотреть.
На данный момент наиболее интересные результаты показал случайный набор данных. Именно на нём я сосредоточусь в основном и немного углублюсь в результаты, чтобы показать, где он потерпел неудачу, а где преуспел.
Помните, я пытаюсь отразить реальность, которая зачастую гораздо сложнее, чем людям хотелось бы видеть.
Очищенные вопросы из корпуса
Очищенный корпус показал практически идентичные результаты по всем показателям. Судья, похоже, отдал предпочтение одному варианту перед другим, исходя из поверхностных предпочтений, но это показало нам проблему использования синтетических наборов данных.
Первый запуск был выполнен на корпусе данных. Помните чистые вопросы, которые были сгенерированы на основе документов, обработанных конвейером.
Результаты автоматизированных метрик оказались поразительно похожими.

Даже релевантность контекста оказалась примерно одинаковой, около 0,95 для обоих случаев. Мне пришлось несколько раз перепроверять, чтобы подтвердить это. Поскольку у меня был большой опыт успешного использования расширения контекста, результаты меня немного обеспокоили.
Однако, оглядываясь назад, становится совершенно очевидно, что вопросы уже хорошо структурированы для поиска, и один отрывок текста может дать на них ответ.
У меня возникла мысль о том, почему релевантность контекста не снижается для расширенного конвейера, если одного фрагмента достаточно. Это связано с тем, что дополнительные контексты берутся из того же раздела, что и исходные фрагменты, что делает их семантически связанными и не считает их «нерелевантными» по классификации RAGAS.
Проведенное нами A/B-тестирование качества показало схожие результаты. Оба варианта победили по одним и тем же причинам: полнота, точность, ясность.

В тех случаях, когда побеждал наивный подход, судье нравилась краткость, ясность и целенаправленность ответа. Сложный процесс отбора наказывался за излишние детали (граничные случаи, дополнительные ссылки), которые не запрашивались напрямую.
Когда побеждал комплексный подход, предпочтение отдавалось полноте/всесторонности ответа, а не наивному варианту. Это означало наличие конкретных цифр/показателей, пошаговых механизмов и объяснений «почему», а не просто «что».
Тем не менее, эти результаты не указывали на какие-либо недостатки. Это скорее вопрос личных предпочтений, чем чисто качественных различий, оба варианта показали исключительно хорошие результаты.
Итак, что мы из этого узнали? В идеальном мире вам не понадобятся никакие сложные дополнения для RAG, а использование тестового набора из корпуса крайне ненадежно.
Сложные вопросы из корпуса
Далее мы протестировали второй набор данных, который показал результаты, аналогичные первому, поскольку был сгенерирован синтетически, но начал двигаться в другом направлении, что оказалось интересным.
Напомню, что ранее я уже рассказывал о более сложных вопросах, сгенерированных на основе корпуса. Этот набор данных был создан так же, как и первый, но с не совсем корректной формулировкой («можете объяснить, как это сделать, пожалуйста…»).
Результаты автоматизированных метрик показали, что результаты по-прежнему очень похожи, хотя в сложном случае релевантность контекста начала снижаться, в то время как достоверность немного возросла.

Среди тех, кто не прошёл проверку по критериям, было несколько ложных срабатываний RAGAS.
Но были и некоторые сбои, связанные с вопросами, которые были сформулированы без конкретики в синтетическом наборе данных, например: «Сколько постов, честно говоря, было использовано в наборе данных?» или «На скольких наборах данных они проводили тестирование?».
В некоторых случаях оптимизатор запросов помог, удалив лишние данные. Но я слишком поздно понял, что сгенерированные вопросы были слишком ориентированы на конкретные фрагменты текста.
Это означало, что отправка запросов в исходном виде давала хорошие результаты на этапе поиска. То есть, вопросы с конкретными именами (например, «как CLAUSE сравнивает…») хорошо соответствовали документам, а оптимизатор запросов только ухудшал ситуацию.
Бывали случаи, когда оптимизация запроса полностью терпела неудачу из-за формулировки вопросов.
Например, вопрос: «Как работает этап предварительной проверки btw в AC-RAG и почему он важен?», где прямой поиск вывел непосредственно на документ AC-RAG, поскольку вопрос был сгенерирован на его основе.
При сравнении результатов с помощью A/B-тестировщика, усовершенствованный конвейер обработки данных показал гораздо лучшие результаты, чем в первом корпусе.

Судья отдал предпочтение краткости и лаконичности подхода, основанного на принципе «наивности», и полноте и всесторонности подхода, основанного на принципе «сложного конвейера».
Причина увеличения числа побед в спорах по поводу сложных процедур заключается в том, что на этот раз судья все чаще отдавал предпочтение «полному, но многословному» варианту вместо «краткого, но потенциально упускающего некоторые аспекты».
Именно тогда мне пришла в голову мысль о том, насколько бесполезен показатель качества ответа. Эти судьи на магистерских экзаменах иногда руководствуются интуицией.
В этом эксперименте я не посчитал, что ответы достаточно сильно отличаются, чтобы оправдать разницу в результатах. Поэтому помните, что использование синтетического набора данных, подобного этому, может дать некоторую информацию, но она может быть довольно ненадежной.
Набор данных случайных вопросов
Наконец, мы рассмотрим результаты, полученные на случайном наборе данных, которые показали гораздо более интересные результаты. Здесь метрики начали меняться с большей разницей, что дало нам возможность для дальнейшего анализа.
До этого момента у меня не было никаких результатов, но этот последний набор данных наконец-то дал мне что-то интересное для изучения.
Результаты, полученные с помощью случайного набора данных, смотрите ниже.

При ответе на случайные вопросы мы фактически наблюдали снижение точности и релевантности ответов по сравнению с базовым вариантом. Релевантность контексту, наряду со структурой, оставалась выше, но это мы уже установили для сложного конвейера в предыдущей статье.
В сложных случаях неизбежен шум, поскольку речь идёт о десятикратно большем количестве фрагментов. Структура цитирования может оказаться сложнее для модели при увеличении контекста (или если у судьи возникнут трудности с оценкой полного контекста).
Однако судья A/B-тестирования поставил ему очень высокую оценку по сравнению с другими наборами данных.

Я запустил программу дважды для проверки, и каждый раз она значительно отдавала предпочтение сложной версии по сравнению с простой.
Почему произошли изменения? На этот раз возникло множество вопросов, на которые один отрывок сам по себе не мог дать ответа.
В частности, сложный конвейер показал хорошие результаты в вопросах компромиссов и сравнения. Судья обосновал это тем, что он «более полный/всеобъемлющий» по сравнению с простым конвейером.
Примером может служить вопрос: «Каковы преимущества и недостатки гибридного алгоритма RAG по сравнению с алгоритмом RAG на основе графов знаний для нечетких запросов?» У Naive было много необоснованных утверждений (отсутствовали метрики GraphRAG, HybridRAG, EM/F1).
На этом этапе мне нужно было понять, почему оно победило, а наивность проиграла. Это дало бы мне информацию о том, где на самом деле помогали эти навороченные функции.
Изучив результаты
Без детального анализа результатов невозможно точно понять, почему что-то побеждает. Поскольку случайный набор данных показал наиболее интересные результаты, я решил сосредоточиться именно на нём.
Во-первых, у судьи возникают серьёзные проблемы с оценкой полного контекста. Именно поэтому я никогда не смог бы создать судью, который оценивал бы каждый контекст в сравнении с другими. Он предпочёл бы наивный подход, потому что с когнитивной точки зрения его проще оценить. Вот что и сделало эту задачу такой сложной.
Тем не менее, мы можем указать на некоторые реальные причины неудач.
Хотя показатель галлюцинаций показал неплохие результаты, при более детальном анализе стало очевидно, что наивный алгоритм чаще фальсифицировал информацию.
Мы могли бы выявить это, проанализировав низкие показатели верности.
Например, на вопрос «как проверить риски внедрения подсказок, если некорректный текст находится внутри полученных PDF-файлов?» простой алгоритм обработки данных заполнил пробелы в контексте, чтобы дать ответ.
Вопрос: Как проверить риски внедрения подсказок, если вредоносный текст находится внутри полученных PDF-файлов? Наивный ответ: Перечисляет стандартные этапы тестирования внедрения подсказок (PoisonedRAG, адаптивные инструкции, многошаговое отравление), но синтезирует общий алгоритм оценки, который не полностью поддерживается конкретными полученными разделами и неявно заполняет пробелы предварительными знаниями. Сложный ответ: Выводит этапы тестирования непосредственно из полученных экспериментальных разделов и моделей угроз, включая многошаговые атаки, измерение смещения генерации одного текста, адаптивные атаки с подсказками и отчеты об уровне успешности, оставаясь в рамках того, что фактически описано в цитируемых статьях. Достоверность: Наивный: 0,0 | Сложный: 0,83 Что произошло: В отличие от наивного ответа, он не изобретает атаки, метрики или методы из ничего. PoisonedRAG, атаки на основе триггеров, возмущения в стиле Hotflip, многошаговые атаки, ASR, DACC/FPR/FNR, PC1–PC3 — все это присутствует в предоставленных документах. Однако, этот сложный конвейер незаметно выходит за рамки дозволенного и демонстрирует пример раздувания масштаба проекта.
Расширенный контент добавил недостающие оценочные показатели, что повысило показатель достоверности на 87%.
Тем не менее, сложный конвейер незаметно выходил за рамки допустимого и имел место случай раздувания масштаба. Это может быть проблемой с генератором LLM, который необходимо настроить таким образом, чтобы каждое утверждение было явно связано с конкретной статьей, и чтобы соответствующим образом помечать межстатьевый синтез.
На вопрос «как оценить эффективность подсказок, которые заставляют модель явно перечислять противоречия?» наивный подход снова использует очень мало метрик, изобретает их, искажает результаты и размывает границы задачи.
Вопрос: Как мне оценить производительность подсказок, которые заставляют модель явно перечислять противоречия? Наивный ответ: Упоминается MAGIC по имени и смутно упоминаются «конфликты» и «оценка производительности», но отсутствуют конкретные механизмы. Нет четкого описания генерации конфликтов, нет разделения обнаружения и локализации, нет фактического протокола оценки. Он заполняет пробелы, придумывая общие шаги, которые не основаны на предоставленном контексте. Сложный ответ: Явно соответствует методологии статьи о MAGIC. Описывает генерацию конфликтов на основе графов знаний, одношаговые и многошаговые конфликты, а также конфликты 1 и N, подсказки на уровне подграфа с малым количеством примеров, пошаговые подсказки (обнаружение, затем локализация) и фактические метрики ID/LOC, используемые в нескольких запусках. Также корректно включает PC1–PC3 в качестве вспомогательных компонентов подсказок и объясняет их роль, в соответствии с цитируемыми разделами. Точность: Наивный: 0,35 | Сложность: 0,73 Что произошло: Сложный подход имеет гораздо большую площадь поверхности, но большая его часть привязана к фактическим разделам статьи MAGIC и соответствующей работе над компонентами задания. Вкратце: наивный ответ является галлюцинаторным по необходимости из-за отсутствия контекста, в то время как сложный ответ многословен, но имеет материальное обоснование. Он чрезмерно синтезирует и чрезмерно предписывает, но в основном остается в рамках фактов. Более высокий показатель верности выполняет свою работу, даже если это оскорбляет человеческое терпение.
Однако в сложных случаях он чрезмерно обобщает и предписывает слишком много, но при этом остается в рамках фактической информации.
Эта закономерность встречается во многих примерах. Наивный алгоритм не располагает достаточной информацией для ответа на некоторые из этих вопросов, поэтому он возвращается к имеющимся знаниям и завершению шаблона. В то время как сложный алгоритм чрезмерно синтезирует информацию, основываясь на ложной согласованности.
По сути, наивность терпит неудачу, выдумывая вещи, а сложность терпит неудачу, слишком обобщая истину.
Этот тест был скорее направлен на выяснение того, помогают ли эти дополнительные функции, но он также указал на необходимость работы над определением области применения утверждений: заставить модель говорить: «В статье А показано X; в статье B показано Y» и так далее.
Вы можете ознакомиться с некоторыми из этих вопросов в таблице, расположенной здесь.
Прежде чем перейти к анализу затрат/задержки, мы можем также попытаться изолировать оптимизатор запросов.
Насколько помог оптимизатор запросов?
Поскольку я не тестировал каждую часть конвейера при каждом запуске, нам пришлось рассматривать разные аспекты, чтобы оценить, помогает ли оптимизатор запросов или вредит.
Сначала мы проанализировали перекрытие начальных фрагментов для сложного и простого конвейеров, показав 8,3% семантического совпадения в случайном конвейере и более 50% совпадения в конвейере на основе корпуса.
Мы уже знаем, что полный конвейер обработки данных победил на случайном наборе данных, и теперь мы также можем увидеть, что он выдал разные документы благодаря оптимизатору запросов.
Большинство документов отличались друг от друга, поэтому я не смог точно определить, ухудшалось ли качество при малом совпадении.
Мы также попросили судью оценить качество оптимизированных запросов по сравнению с исходными с точки зрения сохранения намерений и достаточного разнообразия, и он победил с преимуществом в 8%.
Один из вопросов, на который он отлично ответил, был: «Почему все говорят, что RAG не масштабируется? Как это исправить?»
Оригинал: почему все говорят, что RAG не масштабируется? Как это исправить? Оптимизировано (1): Проблемы масштабируемости RAG (гибридный подход) Оптимизировано (2): Решения для масштабируемости RAG (гибридный подход)
В то время как наивный вопрос, на который можно было ответить самостоятельно, звучал так: «Какие параметры поиска помогают избежать поиска иголки в стоге сена?», другие вопросы были очень хорошо сформулированы с самого начала.
Однако можно с достаточной уверенностью заключить, что для вопросов, содержащих несколько пунктов, и более сложных вопросов оптимизатор показал лучшие результаты, если они не были специфичными для конкретной предметной области. Для хорошо отформатированных вопросов оптимизатор был излишним.
Кроме того, он плохо справлялся с задачами, когда вопрос уже был понятен из исходных документов, в случаях, когда кто-то задавал вопрос, специфичный для предметной области, который оптимизатор запросов не поймет.
Вы можете ознакомиться с несколькими примерами в документе Excel.
Это показывает, насколько важно правильно настроить оптимизатор под вопросы, которые будут задавать пользователи. Если пользователи будут постоянно задавать вопросы, используя специфический для данной области жаргон, который оптимизатор игнорирует или отфильтровывает, он не будет работать эффективно.
Здесь мы видим, что система одновременно отвечает на одни вопросы положительно и не отвечает на другие, поэтому для данного варианта использования потребуется доработка.
Давайте обсудим это.
Я вас перегрузил большим количеством данных, поэтому теперь пришло время рассмотреть компромисс между стоимостью и задержкой, обсудить, какие выводы мы можем и не можем сделать, а также ограничения этого эксперимента.
Компромисс между стоимостью и задержкой
При рассмотрении компромисса между стоимостью и задержкой цель здесь состоит в том, чтобы получить конкретные цифры, показывающие, во сколько обходятся эти функции и откуда они берутся.
Стоимость запуска этого конвейера очень невелика. Речь идёт о 0,00396 доллара за запуск, и это без учёта кэширования. Удаление оптимизатора запросов и расширения соседних узлов снижает затраты на 41%.
Больше ничего и не нужно, потому что входные токены, объем которых увеличивается с добавлением контекста, довольно дешевы.
Фактическими затратами в этом конвейере является инструмент переранжирования от Cohere, который используется как в упрощенном, так и в полном варианте конвейера.
В упрощенном варианте конвейера на функцию переранжирования приходится 70% от общей стоимости. Поэтому стоит проанализировать каждый этап конвейера, чтобы определить, где можно внедрить более простые модели для снижения затрат.
Тем не менее, при объеме около 100 000 вопросов, вы заплатите 400 долларов за полный цикл обработки данных и 280 долларов за базовый.
Также следует учитывать задержку.
Мы зафиксировали увеличение задержки на +49% при использовании сложного конвейера, что составляет около 6 секунд, в основном из-за оптимизатора запросов, использующего GPT-5-mini. В данном случае можно использовать более быструю и компактную модель.
При расширении круга соседей мы измерили среднее увеличение времени на 2–3 секунды. Следует отметить, что это увеличение не является линейным.
Увеличение количества входных токенов в 4,4 раза привело лишь к увеличению времени на 24%.
Полную разбивку вы можете увидеть в таблице здесь.
Это показывает, что разница в стоимости реальна, но не критична, в то время как разница в задержке гораздо более заметна. Большая часть денег по-прежнему тратится на переранжирование, а не на добавление контекста.
Какой вывод мы можем сделать?
Давайте сосредоточимся на том, что сработало, что не сработало и почему. Мы видим, что расширение соседей может быть эффективным, когда вопросы расплывчаты, но у каждого конвейера есть свои собственные причины сбоев.
Наиболее очевидный вывод этого эксперимента заключается в том, что расширение круга соседей оправдывает себя, когда поиск становится сложным и один фрагмент не может ответить на вопрос.
В предыдущей статье мы провели тест, в котором рассматривали, какая часть ответа была сгенерирована из расширенных фрагментов, и на вопросах из чистого корпуса только 22% содержимого ответа было получено из расширенных соседних фрагментов. Мы также увидели, что результаты A/B-тестирования, представленные в этой статье, показали одинаковый результат.
В случае сложных вопросов этот показатель вырос до 30% с 10-процентным отрывом по результатам A/B-тестирования. В случае случайных вопросов он достиг 41% (исходя из контекста) с 44-процентным отрывом по результатам A/B-тестирования. Эта закономерность неоспорима.
В основе проблемы лежит различие в механизмах сбоев. Когда наивный подход терпит неудачу, он происходит из-за упущения. LLM же не располагает достаточным контекстом, поэтому либо дает неполный ответ, либо фальсифицирует информацию, чтобы заполнить пробелы.
Мы ясно увидели это на примере с быстрым внедрением, где наивный пользователь получил 0,0 баллов по показателю верности, потому что чрезмерно углубился в факты.
Когда комплексность терпит неудачу, она терпит неудачу из-за инфляции. В ней так много контекста, что магистерская программа по праву чрезмерно обобщает информацию и делает утверждения, которые не подтверждаются каким-либо одним источником. Но, по крайней мере, эти утверждения имеют под собой какое-то основание.
Показатели достоверности отражают эту асимметрию. В наивном варианте минимальный показатель составляет 0,0 или 0,35, в то время как в сложных случаях наихудшие значения по-прежнему находятся в районе 0,73.
Оптимизатор запросов использовать сложнее. Он помог в 38% случаев, навредил в 27%, а в 35% не оказал никакого влияния. Победы были впечатляющими, когда они случались, спасая ситуацию с такими вопросами, как «почему все говорят, что RAG не масштабируется?», где прямой поиск ничего не выдавал.
Однако потери были невелики, например, когда формулировки пользователя уже соответствовали словарю корпуса, а оптимизатор вносил отклонения.
Это, вероятно, говорит о том, что вам следует тщательно настроить оптимизатор под ваших пользователей или найти способ определить, когда переформулирование, скорее всего, принесет пользу, а когда — вред.
Что касается стоимости и задержки, цифры оказались не такими, как я ожидал. Добавление в 10 раз большего количества фрагментов увеличило время генерации всего на 24%, потому что чтение токенов намного дешевле.
Реальным фактором, определяющим затраты, является переранжирование, составляющее 70% от общей стоимости наивного конвейера.
Оптимизатор запросов вносит наибольший вклад в задержку, составляющую почти 3 секунды на каждый вопрос. Если вы оптимизируете скорость, то в первую очередь следует обратить внимание на него, а также на инструмент переранжирования.
Таким образом, больше контекста не обязательно означает хаос, но это означает, что вам нужно в большей степени контролировать LLM. Когда вопрос не требует такой сложности, будет преобладать наивный подход, но как только вопросы становятся размытыми, более сложный подход может начать играть решающую роль.
Давайте поговорим об ограничениях.
Мне необходимо осветить основные ограничения эксперимента и то, на что следует обращать внимание при интерпретации результатов.
Очевидный вывод заключается в том, что судьи LLM руководствуются интуицией.
Показатели двигались в правильном направлении по всем наборам данных, но я бы не стал доверять абсолютным числам настолько, чтобы устанавливать на их основе пороговые значения для производства.
В этом неструктурированном корпусе наблюдалась разница в 10 баллов для сложных заданий, но, честно говоря, ответы не отличались настолько, чтобы оправдать такую разницу. Возможно, это просто шум.
Я также не рассматривал, что происходит, когда врачи действительно не могут ответить на вопрос.
Случайный набор данных включал вопросы, по которым мы не знали, содержат ли статьи релевантную информацию, но я обработал все 66 вопросов одинаково. Тем не менее, я просмотрел примеры, но всё же возможно, что некоторые из преимуществ сложного конвейера обработки данных были достигнуты благодаря умению лучше признавать своё незнание, а не лучше находить информацию.
Наконец, я протестировал две функции одновременно: оптимизацию запросов и расширение круга соседей, не изолируя полностью вклад каждой из них. Анализ перекрытия начальных точек дал нам некоторое представление об оптимизаторе, но более тщательный эксперимент предполагал бы тестирование их по отдельности.
На данный момент мы знаем, что такое сочетание помогает при решении сложных вопросов, и что стоимость одного запроса увеличивается на 41%. Целесообразность такого компромисса полностью зависит от того, что именно спрашивают ваши пользователи.
Примечания
Думаю, из этой статьи можно сделать вывод, что проводить оценки сложно, а еще сложнее перенести результаты подобного эксперимента на бумагу.
Мне бы хотелось дать вам однозначный ответ, но это сложный вопрос.
Лично я бы сказал, что выдумывание хуже, чем излишняя многословность. Но всё же, если ваш корпус невероятно чистый, и каждый ответ обычно указывает на конкретный фрагмент, то расширение соседей — это излишне.
Это лишь подтверждает, что все эти навороченные функции — своего рода страховка.
Тем не менее, надеюсь, информация была полезной. Поделитесь своим мнением, связавшись со мной в LinkedIn, Medium или через мой сайт.
❤
Напоминаем, что полную разбивку и цифры вы можете посмотреть здесь.
Источник: towardsdatascience.com

























