
Почему не стоит усложнять решения простых проблем
Делиться

В нынешнюю эпоху ажиотажа вокруг искусственного интеллекта складывается впечатление, что все используют модели Vision-Language и крупные Vision Transformers для решения любых задач в области компьютерного зрения. Многие считают эти инструменты универсальными и сразу же используют самую современную, блестящую модель, вместо того чтобы понять, какой именно сигнал они хотят извлечь. Но зачастую красота кроется в простоте. Это один из важнейших уроков, которые я усвоил как инженер: не усложняйте решения простых задач.

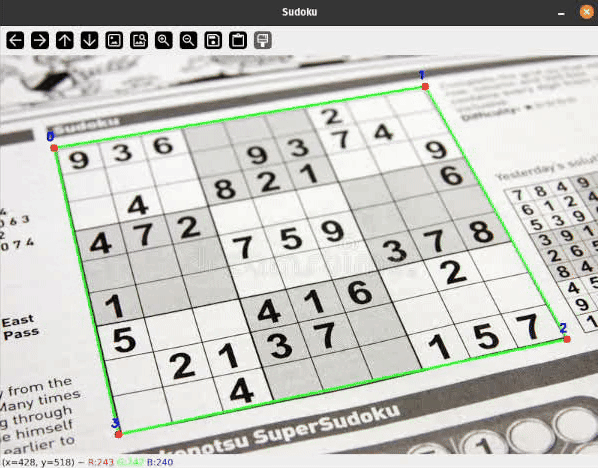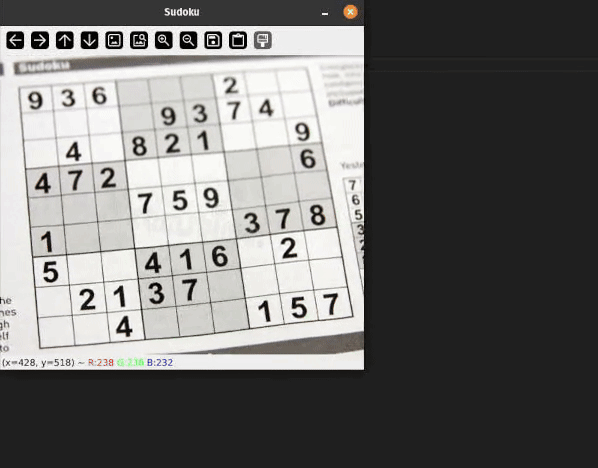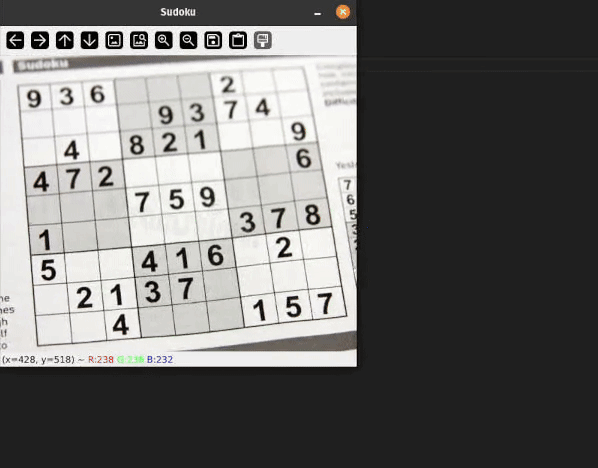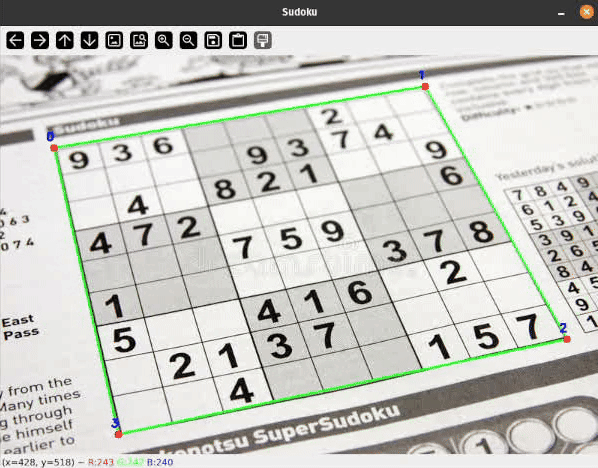
Позвольте мне показать вам практическое применение некоторых простых классических методов компьютерного зрения для обнаружения прямоугольных объектов на плоских поверхностях и применения перспективного преобразования для преобразования наклонного прямоугольника. Подобные методы широко используются, например, в приложениях сканирования и извлечения документов.
По пути вы изучите некоторые интересные концепции, начиная от стандартных классических методов компьютерного зрения и заканчивая тем, как упорядочивать точки многоугольника и как это связано с задачей комбинаторного назначения.
Обзор
- Обнаружение
- Оттенки серого
- Обнаружение краев
- Расширение
- Обнаружение контура
- Трансформация перспективы
- Вариант А: Простая сортировка на основе суммы/разности
- Вариант B: Задача оптимизации назначения
- Вариант C: Циклическая сортировка с якорем
- Применение преобразования перспективы
- Заключение
Обнаружение
Для обнаружения сеток судоку я рассмотрел множество различных подходов: от простого порогового значения, преобразований линий Хафа или какой-либо формы обнаружения границ до обучения модели глубокого обучения для сегментации или обнаружения ключевых точек.
Давайте определим некоторые предположения , чтобы определить масштаб проблемы:
- Сетка судоку отчетливо и полностью видна в кадре с четкой четырехугольной рамкой, с сильным контрастом к фону.
- Поверхность, на которой печатается сетка судоку, должна быть плоской, но при съемке под углом она может выглядеть перекошенной или повернутой.

Я покажу вам простой конвейер с несколькими этапами фильтрации для определения границ сетки судоку. На высоком уровне конвейер обработки выглядит следующим образом:


Оттенки серого
На этом первом этапе мы просто преобразуем входное изображение из трех цветовых каналов в одноканальное изображение в оттенках серого, поскольку для обработки этих изображений нам не нужна никакая цветовая информация.
def find_sudoku_grid( image: np.ndarray, ) -> np.ndarray | None: «»» Находит наибольший квадратный контур на изображении, вероятно, сетку судоку. Возвращает: контур найденной сетки в виде массива numpy или None, если не найдено. «»» gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
Обнаружение краев
После преобразования изображения в оттенки серого мы можем использовать алгоритм обнаружения границ Кэнни для выделения границ. Для этого алгоритма можно выбрать два пороговых значения, которые определяют, принимаются ли пиксели за границы:

В нашем случае обнаружения сеток судоку мы предполагаем наличие очень чётких границ на границах сетки. Мы можем выбрать высокий верхний порог, чтобы исключить появление шума в маске, и не слишком низкий нижний порог, чтобы исключить появление в маске небольших шумных границ, связанных с основной границей.
Перед передачей изображений в Canny часто используется фильтр размытия для уменьшения шума, но в этом случае края очень четкие, но узкие, поэтому размытие не применяется.
def find_sudoku_grid( image: np.ndarray, canny_threshold_1: int = 100, canny_threshold_2: int = 255, ) -> np.ndarray | None: «»» Находит наибольший квадратный контур на изображении, вероятно, это сетка судоку. Аргументы: image: Входное изображение. canny_threshold_1: Нижний порог для детектора рёбер Canny. canny_threshold_2: Верхний порог для детектора рёбер Canny. Возвращает: Контур найденной сетки в виде массива numpy или None, если не найдено. «»» … canny = cv2.Canny(gray, threshold1=canny_threshold_1, threshold2=canny_threshold_2)

Расширение
На следующем этапе мы выполняем постобработку маски обнаружения краев с использованием ядра расширения, чтобы закрыть небольшие зазоры в маске.
def find_sudoku_grid( изображение: np.ndarray, canny_threshold_1: int = 100, canny_threshold_2: int = 255, morph_kernel_size: int = 3, ) -> np.ndarray | None: «»» Находит наибольший квадратный контур на изображении, вероятно, сетку судоку. Args: image: Входное изображение. canny_threshold_1: Первый порог для детектора рёбер Кэнни. canny_threshold_2: Второй порог для детектора рёбер Кэнни. morph_kernel_size: Размер ядра морфологической операции. Возвращает: Контур найденной сетки в виде массива numpy или None, если не найдено. «»» … kernel = cv2.getStructuringElement( shape=cv2.MORPH_RECT, ksize=(morph_kernel_size, morph_kernel_size) ) mask = cv2.morphologyEx(canny, op=cv2.MORPH_DILATE, kernel=kernel, iterations=1)

Обнаружение контура
Теперь, когда бинарная маска готова, мы можем запустить алгоритм обнаружения контуров, чтобы найти связные пятна и отфильтровать их до одного контура с четырьмя точками.
контуры, _ = cv2.findContours( маска, режим = cv2.RETR_EXTERNAL, метод = cv2.CHAIN_APPROX_SIMPLE )

Это первоначальное обнаружение контура вернёт список контуров, содержащих каждый отдельный пиксель, являющийся его частью. Мы можем использовать алгоритм Дугласа–Пейкера для итеративного сокращения количества точек контура и аппроксимации контура простым многоугольником. Мы можем выбрать минимальное расстояние между точками для алгоритма.


Если предположить, что даже для некоторых наиболее асимметричных прямоугольников кратчайшая сторона составляет не менее 10% длины окружности фигуры, мы можем отфильтровать контуры до многоугольников, имеющих ровно четыре точки.
contour_candidates: list[np.ndarray] = [] for cnt in contours: # Аппроксимируем контур до многоугольника epsilon = 0.1 * cv2.arcLength(curve=cnt, closed=True) approx = cv2.approxPolyDP(curve=cnt, epsilon=epsilon, closed=True) # Оставляем только многоугольники с 4 вершинами, если len(approx) == 4: contour_candidates.append(approx)
Наконец, мы берём самый большой обнаруженный контур, предположительно, финальную сетку судоку. Мы сортируем контуры по площади в обратном порядке, а затем берём первый элемент, соответствующий наибольшей площади контура.
best_contour = sorted(contour_candidates, key=cv2.contourArea, reverse=True)[0]

Трансформация перспективы
Наконец, нам нужно преобразовать полученную сетку обратно в квадрат. Для этого можно использовать перспективное преобразование. Матрицу преобразования можно рассчитать, указав, где в итоге должны располагаться четыре точки контура сетки судоку: в четырёх углах изображения.
rect_dst = np.array( [[0, 0], [ширина — 1, 0], [ширина — 1, высота — 1], [0, высота — 1]], )

Чтобы сопоставить точки контура с углами, их необходимо сначала упорядочить, чтобы их можно было правильно назначить. Давайте определим следующий порядок для угловых точек:

Вариант А: Простая сортировка на основе суммы/разности
Чтобы отсортировать извлеченные углы и назначить их этим целевым точкам, простой алгоритм может рассматривать сумму и разность координат x и y для каждого угла.
p_сумма = p_x + p_y p_дифф = p_x — p_y
На основании этих значений теперь можно дифференцировать углы:
- В левом верхнем углу есть как малые значения x, так и y, у него наименьшая сумма argmin(p_sum)
- В правом нижнем углу находится самая большая сумма argmax(p_sum)
- В правом верхнем углу находится самая большая разница argmax(p_diff)
- В левом нижнем углу наименьшая разница argmin(p_diff)
В следующей анимации я попытался визуализировать это назначение четырёх углов вращающегося квадрата. Цветные линии обозначают соответствующий угол изображения, назначенный каждому углу квадрата.

def order_points(pts: np.ndarray) -> np.ndarray: «»» Упорядочивает четыре угловые точки контура в последовательной последовательности: верхний левый, верхний правый, нижний правый, нижний левый. Аргументы: pts: Массив numpy формы (4, 2), представляющий четыре угла. Возвращает: Массив numpy формы (4, 2) с упорядоченными точками. «»» # При необходимости изменяет форму с (4, 1, 2) на (4, 2) pts = pts.reshape(4, 2) rect = np.zeros((4, 2), dtype=np.float32) # Верхняя левая точка будет иметь наименьшую сумму, тогда как # нижняя правая точка будет иметь наибольшую сумму s = pts.sum(axis=1) rect[0] = pts[np.argmin(s)] rect[2] = pts[np.argmax(s)] # Верхняя правая точка будет иметь наименьшую разницу, # тогда как нижняя левая точка будет иметь наибольшую разницу diff = np.diff(pts, axis=1) rect[1] = pts[np.argmin(diff)] rect[3] = pts[np.argmax(diff)] return rect
Это работает хорошо, если только прямоугольник не сильно перекошен, как показано ниже. В данном случае очевидно, что метод несовершенен, поскольку одному и тому же углу прямоугольника назначены несколько углов изображения.

Вариант B: Задача оптимизации назначения
Другой подход заключается в минимизации расстояний между каждой точкой и назначенным ей углом. Это можно реализовать с помощью вычисления pairwise_distances между каждой точкой и углами и функции linear_sum_assignment из Scipy, которая решает задачу назначения, минимизируя при этом функцию стоимости.
def order_points_simplified(pts: np.ndarray) -> np.ndarray: «»» Упорядочивает набор точек для наилучшего соответствия целевому набору угловых точек. Аргументы: pts: Массив numpy формы (N, 2), представляющий упорядочиваемые точки. Возвращает: Массив numpy формы (N, 2) с упорядоченными точками. «»» # При необходимости изменяем форму с (N, 1, 2) на (N, 2) pts = pts.reshape(-1, 2) # Рассчитываем расстояние между каждой точкой и каждым целевым углом D = pairwise_distances(pts, pts_corner) # Находим оптимальное однозначное назначение # row_ind[i] должно сопоставляться с col_ind[i] row_ind, col_ind = linear_sum_assignment(D) # Создаём пустой массив для хранения отсортированных точек order_pts = np.zeros_like(pts) # Размещаем каждую точку в правильном слоте в зависимости от угла, с которым она была сопоставлена. # Например, точка, сопоставленная с target_corners[0], попадает в order_pts[0]. order_pts[col_ind] = pts[row_ind] return order_pts

Несмотря на то, что это решение работает, оно не идеально, поскольку зависит от расстояния на изображении между точками фигуры и её углами, и требует больших вычислительных затрат, поскольку необходимо построить матрицу расстояний. Конечно, в случае четырёх точек это пренебрежимо мало, но это решение не очень подходит для многоугольника с большим количеством точек!
Вариант C: Циклическая сортировка с якорем
Третий вариант — очень простой и эффективный способ сортировки и назначения точек фигуры углам изображения. Идея заключается в вычислении угла для каждой точки фигуры на основе положения её центроида.

Поскольку углы циклические, нам необходимо выбрать якорь, гарантирующий абсолютный порядок точек. Мы просто выбираем точку с наименьшей суммой x и y.
def order_points(self, pts: np.ndarray) -> np.ndarray: «»» Упорядочивает точки по углу вокруг центроида, затем поворачивает их, начиная с верхнего левого угла. Аргументы: pts: Массив numpy формы (4, 2). Возвращает: Массив numpy формы (4, 2) с упорядоченными точками.»»» pts = pts.reshape(4, 2) center = pts.mean(axis=0) angles = np.arctan2(pts[:, 1] — center[1], pts[:, 0] — center[0]) pts_cyclic = pts[np.argsort(angles)] sum_of_coords = pts_cyclic.sum(axis=1) top_left_idx = np.argmin(sum_of_coords) return np.roll(pts_cyclic, -top_left_idx, ось=0)

Теперь мы можем использовать эту функцию для сортировки точек контура:
rect_src = order_points(grid_contour)
Применение преобразования перспективы
Теперь, когда мы знаем, какие точки куда нужно поместить, мы можем наконец перейти к самой интересной части: созданию и фактическому применению перспективного преобразования к изображению.

Поскольку у нас уже есть список точек для обнаруженного четырехугольника, отсортированный в rect_src, и у нас есть целевые угловые точки в rect_dst, мы можем использовать метод OpenCV для вычисления матрицы преобразования:
warp_mat = cv2.getPerspectiveTransform(rect_src, rect_dst)
Результатом является матрица деформации размером 3×3, определяющая преобразование из наклонного трёхмерного перспективного вида в плоский вид сверху вниз. Чтобы получить этот плоский вид сверху вниз для нашей сетки судоку, мы можем применить к исходному изображению следующее перспективное преобразование:
warped = cv2.warpPerspective(img, warp_mat, (side_len, side_len))
И вуаля, у нас есть идеально квадратная сетка судоку!

Заключение
В этом проекте мы рассмотрели простой процесс извлечения сеток судоку из изображений с помощью классических методов компьютерного зрения. Эти методы позволяют легко определить границы сеток судоку. Конечно, из-за своей простоты этот подход имеет некоторые ограничения на обобщение для различных условий и экстремальных сред, таких как слабое освещение или резкие тени. Использование подхода, основанного на глубоком обучении, может быть целесообразным, если обнаружение должно быть обобщено для большого количества различных условий.
Затем применяется перспективное преобразование, чтобы получить плоское изображение сетки сверху вниз. Это изображение теперь можно использовать для дальнейшей обработки, например, для извлечения чисел из сетки и решения судоку. В следующей статье мы подробнее рассмотрим эти естественные шаги в рамках этого проекта.
Ознакомьтесь с исходным кодом проекта ниже и дайте мне знать, если у вас есть вопросы или мысли по поводу этого проекта. А пока — удачного программирования!
Источник: towardsdatascience.com

























