
TL;DR
Провели РКИ на реальных задачах в крупных OSS-репозиториях: 16 опытных контрибьюторов, 246 задач (исправления, фичи, рефакторинг), на каждую задачу случайно разрешали/запрещали ИИ.
Инструменты при «разрешено»: в основном Cursor Pro + Claude 3.5/3.7; при «запрещено» — обычная работа без генеративного ИИ.
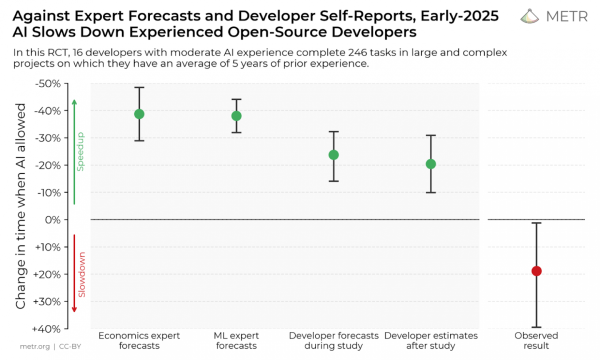
Главный итог: с ИИ задачи выполнялись в среднем на 19% дольше; качество PR сопоставимо между условиями.
Перцепция расходится с данными: разработчики ожидали ускорение (~24%) и постфактум тоже считали, что ускорились (~20%).
Что это не доказывает: не универсальный приговор ИИ; возможны иные домены, команды, процессы и стек, где будет ускорение.
Вероятные причины замедления: издержки «оркестрации» (промпты, перегенерации, проверка), высокие неявные требования в реальных репо (стиль/тесты/дока/линтеры), недостаточная «прокачка» инструментов, ограниченные токены и отсутствие многократных траекторий.
Результаты согласуются с тем, что бенчмарки завышают потенциал (чёткие задачи, авто-проверка, «режим макс-мощности»), а анекдоты — субъективны.
Практический вывод: ускорение появляется там, где ИИ встроен в процесс — есть шаблоны, контекст репозитория (retrieval), автоматическая валидация (тесты/линтеры), и измеряется эффект на метриках (lead time, зелёные прогоны, доля откатов).
Рекомендация: применять ИИ точечно (тест-скелеты, однотипные миграции, черновой рефакторинг, документация, онбординг), а не «везде и сразу».
Авторы планируют повторять исследование, чтобы отслеживать тренд по мере развития моделей и инструментов.
Исследовательская команда METR провела рандомизированное контролируемое исследование (РКИ), чтобы понять, как ИИ-инструменты начала 2025 года влияют на производительность опытных разработчиков открытого ПО, работающих с репозиториями, в которые они давно контрибьютят. Неожиданно выяснилось: при использовании искусственного интеллекта разработчики тратят на 19% больше времени, чем без него — ИИ замедляет их. Мы рассматриваем этот результат как «снимок» возможностей ИИ начала 2025 года в одном показательном контексте; по мере стремительной эволюции систем мы планируем продолжать применять эту методологию, чтобы оценивать ускорение програсса в ИИ за счёт автоматизации НИОКР.[1]
См. полный текст исследования.

Мотивация
Хотя бенчмарки по программированию и агентным системам [2] полезны для оценки возможностей ИИ, они обычно жертвуют реалистичностью ради масштаба и эффективности: задачи самодостаточны, не требуют предварительного контекста и проверяются алгоритмически, что не охватывает множество важных способностей. Эти свойства могут приводить к завышению оценок возможностей ИИ. С другой стороны, поскольку бенчмарки запускаются без живого взаимодействия с человеком, модели могут не доводить задачи до конца, несмотря на существенный прогресс, из-за мелких «узких мест», которые человек при реальном использовании быстро устранил бы. Это, напротив, может занижать оценку возможностей моделей. В целом напрямую переводить результаты бенчмарков в реальный эффект «в полях» сложно.
Одна из причин, по которой нам важно оценивать влияние ИИ «в полевых условиях», — лучше понять его влияние на сам НИОКР в области ИИ, где потенциальные риски могут быть значительными. Например, чрезмерно быстрый прогресс ИИ может привести к сбоям в механизмах контроля и безопасности. Измерение влияния ИИ на продуктивность разработчиков программного обеспечения даёт дополнительное к бенчмаркам свидетельство, которое помогает судить о совокупном влиянии ИИ на ускорение НИОКР в ИИ.
Методология
Чтобы напрямую измерить реальное влияние ИИ-инструментов на разработку ПО, мы привлекли 16 опытных разработчиков — участников крупных open source проектов (в среднем 22 000+ звёзд и более 1 млн строк кода), в которые они контрибьютили на протяжении нескольких лет. Разработчики предоставили списки реальных задач (всего 246), представляющих ценность для репозитория — исправления ошибок, новые функции и рефакторинг, которые обычно входят в их повседневную работу. Затем мы случайным образом распределяли каждую задачу в одну из двух групп: с разрешением использовать ИИ при её выполнении или с запретом на использование ИИ. Когда использование ИИ было разрешено, разработчики могли выбирать любые инструменты (в основном Cursor Pro в связке с Claude 3.5/3.7 Sonnet — на тот момент это были одни из самых сильных моделей); при запрете — работали без помощи генеративного ИИ. Разработчики выполняли эти задачи (в среднем по два часа на задачу) с записью экрана, после чего самостоятельно указывали суммарное время, затраченное на реализацию. В качестве компенсации за участие мы выплачивали разработчикам $150 в час.

Ключевой результат
Когда разработчики используют ИИ-инструменты, на завершение задач уходит на 19% больше времени — это существенное замедление, которое противоречит ожиданиям самих разработчиков и прогнозам экспертов. Разрыв между восприятием и реальностью показателен: разработчики ожидали, что ИИ ускорит их работу на 24%, и даже после фактического замедления они всё равно считали, что ИИ ускорил их работу на 20%.
Ниже мы показываем необработанные средние значения ожидаемого времени по оценкам разработчиков и фактического времени выполнения — видно, что при разрешённом использовании ИИ разработчики тратят значительно больше времени.

С учётом важности корректного понимания возможностей и рисков ИИ и разнообразия взглядов на эту тему мы считаем важным предотвратить неверные трактовки или чрезмерные обобщения результатов. В таблице 2 перечислены утверждения, для которых мы не предоставляем доказательств.
Мы не утверждаем, что: | Пояснение |
ИИ-системы в настоящее время не ускоряют работу многих или большинства разработчиков ПО | Мы не заявляем, что наши разработчики или репозитории представляют большинство или значимую долю всей разработки ПО |
ИИ-системы не ускоряют работу людей или команд в других областях помимо разработки ПО | Мы изучали только разработку программного обеспечения |
В ближайшем будущем ИИ-системы не смогут ускорить разработчиков в том же контексте, что и в нашем исследовании | Прогнозировать прогресс сложно, а за последние пять лет в ИИ был значительный рост [3] |
Не существует способов использовать существующие ИИ-системы более эффективно, чтобы добиться ускорения именно в нашем контексте | Cursor обычно не генерирует много токенов, могут использоваться неоптимальные подходы к проектированию промптов и обвязке (scaffolding); обучение под конкретный домен/репозиторий, дообучение (fine-tuning) и обучение на малом числе примеров (few-shot) потенциально могут дать ускорение. |
Анализ факторов
Мы изучили 20 потенциальных факторов, которые могли бы объяснить замедление, и обнаружили свидетельства того, что 5 из них, вероятно, вносят вклад:

Мы исключили множество возможных артефактов эксперимента — разработчики использовали передовые модели, следовали назначенному условию (разрешено/запрещено использовать ИИ), не отказывались от задач выборочно (например, не «сбрасывали» сложные задачи в группе без ИИ, тем самым снижая среднюю сложность этой группы) и отправляли пулл-реквесты сопоставимого качества как с ИИ, так и без него. Замедление сохраняется по разным итоговым метрикам, при различных методах оценки и во множестве подвыборок и анализов наших данных. За подробностями и дополнительным разбором см. статью.
Обсуждение
Как согласовать наши результаты с впечатляющими показателями бенчмарков и многочисленными анекдотическими свидетельствами пользы и широкого распространения инструментов на основе ИИ? Если рассматривать всё вместе, эти источники дают частично противоречивые ответы о том, насколько ИИ-агенты способны эффективно выполнять задачи или ускорять людей. В следующей таблице мы сопоставляем эти источники и подводим итоги наших наблюдений по каждому из них. Следует отметить, что это не претендует на полноту — мы лишь весьма грубо указываем на несколько существенных различий.
«Наш RCT» | «Бенчмарки» вроде SWE-Bench Verified, RE-Bench | «Анекдоты» и широкое внедрение ИИ | |
Тип задачи | PR-ы в крупных, высококачественных opern source репозиториях | SWE-Bench Verified: PR-ы в проектах с тестами, написанными авторами; RE-Bench: вручную составленные исследовательские задачи по ИИ с алгоритмической проверкой | Разнообразные |
Определение успеха | Пользователь-человек уверен, что код пройдёт ревью — с учётом требований к стилю, тестам и документации | Алгоритмическая оценка (например, автоматические тесты) | Пользователь-человек считает код полезным (вплоть до «одноразового прототипа» или кода разового использования для исследования) |
Вид ИИ | Чат, режим агента Cursor, автодополнение | Обычно полностью автономные агенты, которые могут генерировать миллионы токенов и использовать сложные агентные обвязки и т. п. | Разные модели и инструменты |
Наблюдения | Модели замедляют людей на реалистичных задачах кодинга длительностью ~20 минут — 4 часа | Модели часто успешно решают бенчмарк-задачи, которые очень сложны для людей | Многие (хотя далеко не все) сообщают, что ИИ очень помогает на существенных задачах разработки длительностью более часа, в самых разных сценариях |
Согласование этих разнородных источников данных сложно, но важно и отчасти зависит от того, на какой вопрос мы пытаемся ответить. В некотором смысле разные источники отражают вполне легитимные «подвопросы» о возможностях моделей — например, нас интересует понимание возможностей как при максимально полном раскрытии потенциала модели (например, при генерации миллионов токенов запуске десятков или сотен траекторий на каждую задачу), так и при обычном использовании. Однако некоторые особенности могут сделать результаты мало пригодными для ответов на ключевые практические вопросы — например, самоотчёты могут быть неточными и чрезмерно оптимистичными.
Ниже приведено несколько широких категорий гипотез, которые, на наш взгляд, наиболее правдоподобно объясняют, как можно согласовать эти наблюдения (это очень упрощённая ментальная модель):
Сводка наблюдаемых результатов
ИИ замедляет работу опытных open source разработчиков в нашем РКИ, но демонстрирует впечатляющие результаты на бенчмарках и, по анекдотическим данным, широко полезен.

Гипотеза 1: наше РКИ недооценивает возможности моделей
Результаты бенчмарков и анекдотические свидетельства в целом верны, а в нашем исследовании есть неизвестная методологическая проблема или особенности постановки, отличающие её от других важных контекстов.

Гипотеза 2: бенчмарки и анекдотические свидетельства переоценивают возможности
Наши результаты РКИ в целом верны, а показатели на бенчмарках и анекдотические отчёты переоценивают способности моделей (возможно, каждый по своим причинам).

Гипотеза 3: взаимодополняющие свидетельства для разных условий
Все три подхода в целом корректны, но измеряют подмножества реального распределения задач, которые оказываются более или менее сложными для моделей.

В этих схемах красные различия между источником данных и «истинным» уровнем возможностей модели соответствуют ошибкам измерения или искажениям, из-за которых свидетельства вводят в заблуждение; синие различия (то есть в сценарии «Mix») соответствуют корректным различиям в том, что представляют разные источники, например если они просто нацелены на разные подмножества распределения задач.
Пользуясь этой рамкой, мы можем рассматривать аргументы «за» и «против» разных способов согласования этих источников данных. Например, наши результаты РКИ менее релевантны в условиях, где можно запускать сотни или тысячи траекторий (прогонов) модели — наши разработчики обычно этого не делают. Также возможно, что для ИИ-инструментов вроде Cursor существенные эффекты обучения проявляются лишь после нескольких сотен часов использования — наши разработчики обычно работали с Cursor лишь несколько десятков часов до и во время исследования. Наши результаты также указывают, что возможности ИИ могут быть ниже в условиях с очень высокими стандартами качества или большим числом неявных требований (например, к документации, тестовому покрытию, линтингу и форматированию), на освоение которых людям требуется значительное время.
С другой стороны, бенчмарки могут завышать оценку возможностей моделей, поскольку измеряют результат только на хорошо очерченных задачах с алгоритмической проверкой. И у нас теперь есть убедительные свидетельства того, что анекдотические отчёты и оценки ускорения могут быть весьма неточными.
Ни один метод измерения не идеален — задачи, которые люди хотят поручать ИИ-системам, разнообразны, сложны и трудно поддаются строгому исследованию. Между методами неизбежны компромиссы, и по-прежнему важно развивать и применять разнообразные подходы к оценке, чтобы формировать более целостное представление о текущем состоянии ИИ и о том, куда мы движемся.
Дальнейшая работа
Мы планируем проводить аналогичные версии этого исследования в будущем, чтобы отслеживать тенденции ускорения (или замедления) при использовании ИИ, поскольку такой метод оценки труднее подвергнуть манипуляциям, чем бенчмарки. Если ИИ-системы смогут существенно ускорять разработчиков в нашем контексте, это может сигнализировать о быстром ускорении прогресса НИОКР в области ИИ в целом, что, в свою очередь, может создать риски неконтролируемого распространения, сбоям в защитных механизмах и надзоре или чрезмерной концентрации власти. Эта методика даёт свидетельства, дополняющие бенчмарки, сосредоточенные на реалистичных сценариях внедрения, что помогает более полно понимать возможности и влияние ИИ по сравнению с опорой только на бенчмарки и анекдотические данные.
Исследование показало: без методики ИИ легко превращается в тормоз. Чтобы он действительно ускорял, нужны чёткие приёмы — формулировать задачи, проверять результат, встраивать инструменты в процесс. На курсе «AI для разработчиков» от OTUS разбираются практические сценарии — генерация кода и тестов, рефакторинг, онбординг в чужой код, автоматизация документации, плюс в программе работа с Copilot и Cody, а также безопасное подключение AI к инфраструктуре.
Чтобы узнать больше о формате обучения, приходите на демо-уроки, которые бесплатно проведут преподаватели курса:
12 ноября: «Обзор AI-технологий для разработчиков: от идей до рабочих решений». Записаться
17 ноября: «Создание UI с Claude Code и Playwright MCP». Записаться
Источник: habr.com

























