
Что на самом деле и делают некоторые люди.
Делиться

Одна из проблем, с которой вы столкнетесь при работе над проектированием ИИ, — отсутствие какого-либо реального чертежа, которому можно следовать.
Да, для самых базовых этапов поиска (буква «R» в аббревиатуре RAG) можно разбивать документы на фрагменты, использовать семантический поиск по запросу, переранжировать результаты и т. д. Эта часть хорошо известна.
Но как только начинаешь углубляться в эту область, начинаешь задаваться вопросами вроде: как можно назвать систему интеллектуальной, если она способна читать лишь отдельные фрагменты документа? Как же убедиться, что у неё достаточно информации для действительно разумного ответа?
Вскоре вы обнаружите, что погружаетесь в пучину неизвестности, пытаясь понять, что делают другие в своих организациях, поскольку ничего из этого должным образом не документировано, и люди по-прежнему создают свои собственные системы.
Это приведет к необходимости внедрения различных стратегий оптимизации: создание пользовательских фрагментов, переписывание пользовательских запросов, использование различных методов поиска, фильтрация с использованием метаданных и расширение контекста для включения соседних фрагментов.

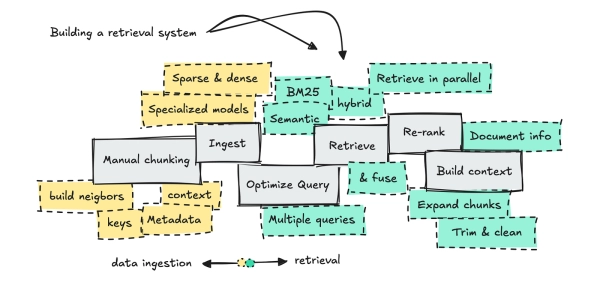
Вот почему я создал довольно громоздкую систему поиска, чтобы показать вам, как она работает. Итак, давайте разберём её пошагово, чтобы увидеть результаты каждого шага, а также обсудить компромиссы.
Чтобы продемонстрировать эту систему публично, я решил встроить 150 недавних статей ArXiv (2250 страниц), в которых упоминается RAG. Это означает, что тестируемая нами система предназначена для научных статей, и все тестовые запросы будут связаны с RAG.
Я собрал необработанные выходные данные для каждого шага для нескольких запросов в этом репозитории, если вы хотите рассмотреть все подробно.
Что касается технологического стека, я использую Qdrant и Redis для хранения данных, а также Cohere и OpenAI для LLM. Я не использую никакие фреймворки для построения конвейеров (так как это затрудняет отладку).
Как всегда, я делаю краткий обзор того, что мы делаем, для новичков, так что если RAG вам уже знаком, можете смело пропустить первый раздел.
Повторный поиск и RAG
При работе с системами знаний ИИ, такими как Copilot (где вы передаете ему пользовательские документы для ответа), вы работаете с системой RAG.
RAG расшифровывается как Retrieval Augmented Generation и разделен на две части: часть поиска и часть генерации.
Извлечение — это процесс извлечения информации из файлов с использованием ключевых слов и семантического соответствия на основе запроса пользователя. Генерация — это этап, где вступает в дело LLM, который выдаёт ответы на основе предоставленного контекста и запроса пользователя.

Для новичков в RAG это может показаться слишком громоздким способом построения систем. Разве не должен магистр права выполнять большую часть работы самостоятельно?
К сожалению, LLM статичны, и нам необходимо разработать системы так, чтобы каждый раз, когда мы к ним обращаемся, мы заранее предоставляли им всю необходимую информацию, чтобы они могли ответить на вопрос.
Я уже писал о создании RAG-ботов для Slack. Этот бот использует стандартные методы фрагментации, если вам интересно понять, как люди создают что-то простое.
В этой статье делается шаг вперед и предпринимается попытка перестроить весь конвейер поиска без каких-либо фреймворков, чтобы реализовать некоторые необычные функции, например построить оптимизатор многозапросов, объединить результаты и расширить фрагменты для создания лучшего контекста для LLM.
Однако, как мы увидим, за все эти необычные дополнения нам придется платить задержками и дополнительной работой.
Обработка различных документов
Как и в любой задаче по инжинирингу данных, первым шагом станет выбор архитектуры хранения данных. В случае с извлечением данных мы фокусируемся на так называемом фрагментировании (chunking), и то, как вы это делаете и что именно вы храните, имеет решающее значение для построения хорошо спроектированной системы.
При поиске мы ищем текст, и для этого нам нужно разделить текст на отдельные фрагменты информации. Именно эти фрагменты текста мы впоследствии будем искать, чтобы найти соответствие запросу.
Большинство простых систем используют общие блоки, просто разбивая весь текст по длине, абзацу или предложению.

Но каждый документ индивидуален, поэтому, поступая так, вы рискуете потерять контекст.
Чтобы понять это, следует изучить различные документы и увидеть, как они структурированы. У вас будет документ HR с чёткими заголовками разделов и документы API с ненумерованными разделами, использующими блоки кода и таблицы.
Если применить одну и ту же логику разделения ко всем этим текстам, вы рискуете разбить каждый текст неправильно. Это означает, что после того, как LLM получит фрагменты информации, она будет неполной, что может привести к тому, что он не сможет дать точный ответ.
Более того, для каждого фрагмента информации вам также необходимо подумать о том, какие данные вы хотите в нем хранить.
Должен ли он содержать определённые метаданные, чтобы система могла применять фильтры? Должен ли он ссылаться на похожую информацию, чтобы можно было сопоставлять данные? Должен ли он содержать контекст, чтобы LLM понимал, откуда поступает информация?
Это означает, что архитектура хранения данных становится важнейшей частью. Если вы начнёте хранить информацию, а потом поймёте, что этого недостаточно, вам придётся переделывать. Если вы поймёте, что усложнили систему, вам придётся начинать с нуля.
Эта система будет обрабатывать данные Excel и PDF, уделяя особое внимание добавлению контекста, ключей и соседей. Это позволит вам увидеть, как это будет выглядеть при последующем извлечении данных.
Для этой демонстрации я сохранил данные в Redis и Qdrant. Мы используем Qdrant для семантического поиска, поиска по BM25 и гибридного поиска, а для расширения контента мы извлекаем данные из Redis.
Загрузка табличных файлов
Сначала мы рассмотрим, как можно разбить табличные данные на фрагменты, добавить контекст и связать информацию с ключами.
При работе с уже структурированными табличными данными, например, в файлах Excel, может показаться очевидным решение — позволить системе искать их напрямую. Но на самом деле семантическое сопоставление довольно эффективно для сложных пользовательских запросов.
SQL-запросы или прямые запросы работают только в том случае, если вы уже знаете схему и точные поля. Например, если пользователь запрашивает что-то вроде «Mazda 2023 характеристики», семантическое соответствие строк даст нам основу для анализа.
Я общался с компаниями, которым нужна была система для сопоставления документов в разных файлах Excel. Для этого мы можем хранить ключи вместе с фрагментами (без полного перехода на KG).
Например, если мы работаем с файлами Excel, содержащими данные о покупках, мы можем загрузить данные для каждой строки следующим образом:
{ «chunk_id»: «Sales_Q1_123::row::1», «doc_id»: «Sales_Q1_123:1234» «location»: {«sheet_name»: «Sales Q1», «row_n»: 1}, «type»: «chunk», «text»: «OrderID: 1001234f67 n Клиент: Элис Хемсворт n Товары: Синий свитер 4, Красные брюки 6», «context»: «Квартальный обзор продаж», «keys»: {«OrderID»: «1001234f67»}, }
Если позже в процессе поиска мы решим объединить информацию, мы можем выполнить стандартный поиск по ключам для нахождения связующих фрагментов. Это позволяет нам быстро перемещаться между документами, не добавляя ещё один этап маршрутизатора в конвейер.

Мы также можем настроить сводку для каждого документа. Это служит своего рода «контролёром» для фрагментов.
{ «chunk_id»: «Sales_Q1::summary», «doc_id»: «Sales_Q1_123:1234» «location»: {«sheet_name»: «Sales Q1»}, «type»: «summary», «text»: «Лист отслеживает заказы за Q1 за 2025 год, тип продукта и имена клиентов для сверки.», «context»: «» }
Идея сводки привратника может показаться немного сложной для понимания на первый взгляд, но она также полезна, поскольку позволяет хранить сводку на уровне документа, если она понадобится вам при построении контекста позже.
Когда LLM настраивает это резюме (и краткую строку контекста), он может предложить ключевые столбцы (т. е. идентификаторы заказов и т. д.).
Обратите внимание: по возможности всегда устанавливайте ключевые столбцы вручную. Если это невозможно, настройте некоторую логику проверки, чтобы убедиться, что ключи не являются просто случайными (может случиться, что LLM выберет странные столбцы для хранения, проигнорировав самые важные).
Для этой системы с документами ArXiv я подключил два файла Excel, которые содержат информацию об уровне заголовка и автора.
Фрагменты будут выглядеть примерно так:
{ «chunk_id»: «titles::row::8817::250930134607», «doc_id»: «titles::250930134607», «location»: { «sheet_name»: «titles», «row_n»: 8817 }, «type»: «chunk», «text»: «id: 2507 2114ntitle: Гендерные сходства доминируют в математическом познании на нейронном уровне: японское исследование фМРТ с использованием расширенного вейвлет-анализа и генеративного ИИnkeywords: ФМРТ; Функциональная магнитно-резонансная томография; Гендерные различия; Машинное обучение; Математическая производительность; Частотно-временной анализ; Вейвлетnabstract_url: https://arxiv.org/abs/2507.21140ncreated: 2025-07-23 00:00:00 UTCnauthor_1: Тацуру Кикучи», «context»: «Анализ тенденций в статьях об искусственном интеллекте и вычислительных исследованиях.», «keys»: { «id»: «2507 2114», «author_1»: «Тацуру Кикучи» } }
Строго говоря, эти файлы Excel не были необходимы (файлов PDF было бы достаточно), но они позволяют продемонстрировать, как система может искать ключи для нахождения связующей информации.
Я также создал аннотации для этих файлов.
{ «chunk_id»: «titles::summary::250930134607», «doc_id»: «titles::250930134607», «location»: { «sheet_name»: «titles» }, «type»: «summary», «text»: «Набор данных состоит из статей с различными атрибутами, включая идентификатор, название, ключевые слова, авторов и дату публикации. Он содержит в общей сложности 2508 строк с богатым разнообразием тем, преимущественно связанных с ИИ, машинным обучением и передовыми вычислительными методами. Авторы часто работают в составе групп, что обозначено несколькими столбцами с авторами. Набор данных предназначен для академических и исследовательских целей, позволяя использовать catego», }
Мы также храним информацию в Redis на уровне документа, где указано, о чём он, где его найти, кому он доступен и когда последний раз обновлялся. Это позволит нам позже обновлять устаревшую информацию.
Теперь давайте обратимся к PDF-файлам — это худшее, с чем вам придется столкнуться.
Загрузка PDF-документов
Для обработки PDF-файлов мы делаем то же, что и с табличными данными, но разбить их на фрагменты гораздо сложнее, и вместо ключей мы храним соседей.
Чтобы начать обрабатывать PDF-файлы, нам нужно работать с несколькими фреймворками, такими как LlamaParse и Docling, но ни один из них не идеален, поэтому нам придется дальше развивать систему.
PDF-документы очень сложно обрабатывать, поскольку большинство из них не имеют единой структуры. Кроме того, они часто содержат рисунки и таблицы, которые большинство систем не могут корректно обработать.
Тем не менее, такой инструмент, как Docling, может помочь нам, по крайней мере, правильно анализировать обычные таблицы и сопоставлять каждый элемент с правильной страницей и номером элемента.
Отсюда мы можем создать собственную программную логику, сопоставляя разделы и подразделы для каждого элемента, а также интеллектуально объединяя фрагменты, чтобы фрагменты читались естественно (т. е. не разделялись на полуслове).
Мы также группируем фрагменты по разделам, объединяя их путем связывания их идентификаторов в поле, называемом «соседи».

Это позволяет нам сохранять фрагменты небольшими, но при этом расширять их после извлечения.
Конечный результат будет примерно таким:
{ «chunk_id»: «S3::C02::251009105423», «doc_id»: «2507.18910v1», «location»: { «page_start»: 2, «page_end»: 2 }, «type»: «chunk», «text»: «1 Введениеnn1.1 Предыстория и мотивацияnnКрупномасштабные предобученные языковые модели продемонстрировали способность хранить огромные объёмы фактических знаний в своих параметрах, но им сложно получить доступ к актуальной информации и предоставить проверяемые источники. Это ограничение побудило к появлению методов, дополняющих генеративные модели информационным поиском. Генерация дополненного поиска (RAG) появилась в качестве решения этой проблемы, сочетая нейронный ретривер с генератором последовательностей для получения выходных данных во внешних документах [52]. В основополагающей работе [52] RAG был представлен для задач, требующих больших знаний, что показало, что Генеративная модель (построенная на кодере-декодере BART) может извлекать релевантные тексты из Википедии и включать их в свои ответы, тем самым достигая высочайшего уровня производительности при ответах на вопросы в открытой области. RAG разработан на основе предыдущих разработок, в которых поиск использовался для улучшения ответов на вопросы и моделирования языка [48, 26, 45]. В отличие от более ранних подходов, основанных на извлечении данных, RAG выдаёт ответы в свободной форме, используя при этом непараметрическую память, предлагая преимущества обоих подходов: повышенную фактическую точность и возможность цитировать источники. Эта возможность особенно важна для уменьшения галлюцинаций (т.е. получения правдоподобных, но неверных результатов) и для обновления знаний без переобучения модели [52, 33].», «context»: «Систематический обзор разработки и применения RAG в обработке естественного языка, рассматривающий проблемы и достижения.», «section_neighbours»: { «before»: [ «S3::C01::251009105423» ], «after»: [ «S3::C03::251009105423», «S3::C04::251009105423», «S3::C05::251009105423», «S3::C06::251009105423», «S3::C06::251009105423», «S3::C07::251009105423» ] }, «ключи»: {} }
При такой настройке данных мы можем рассматривать эти фрагменты как исходные данные. Мы ищем, где может быть релевантная информация, основанная на запросе пользователя, и расширяем её.
Отличие от более простых систем RAG заключается в том, что мы пытаемся воспользоваться растущим контекстным окном LLM, чтобы отправлять больше информации (но, очевидно, здесь есть компромиссы).
Вы сможете увидеть примерное решение того, как это выглядит, когда позже будете строить контекст в конвейере поиска.
Строительство поискового трубопровода
Поскольку я выстраивал этот конвейер шаг за шагом, это позволяет нам протестировать каждую часть и разобраться, почему мы делаем тот или иной выбор в отношении того, как извлекаем и преобразуем информацию, прежде чем передать ее магистрам права.
Мы рассмотрим семантический, гибридный и BM25 поиск, построим оптимизатор многозапросов, переранжируем результаты, расширим контент для создания контекста, а затем передадим результаты LLM для ответа.
Мы закончим раздел обсуждением задержек, ненужной сложности и того, что следует убрать, чтобы сделать систему быстрее.
Если вы хотите посмотреть на результаты нескольких запусков этого конвейера, перейдите в этот репозиторий.
Семантический, BM25 и гибридный поиск
Первая часть этого процесса — убедиться, что мы получаем релевантные документы по запросу пользователя. Для этого мы используем семантический поиск, BM25 и гибридный поиск.
Для простых поисковых систем обычно используется семантический поиск. Для выполнения семантического поиска мы встраиваем плотные векторы для каждого фрагмента текста, используя модель встраивания.
Если вы с этим в новинку, обратите внимание, что вложения представляют каждый фрагмент текста как точку в многомерном пространстве. Положение каждой точки отражает то, как модель понимает его смысл, основываясь на закономерностях, усвоенных в процессе обучения.

В результате тексты со схожим значением окажутся близко друг к другу.
Это означает, что если модель увидела много примеров похожего языка, она лучше размещает связанные тексты рядом друг с другом и, следовательно, лучше сопоставляет запрос с наиболее релевантным контентом.
Если вам интересно узнать больше, я уже писал об этом ранее, используя кластеризацию на различных моделях встраивания, чтобы посмотреть, как они работают в конкретном случае.
Для создания плотных векторов я использовал модель большого встраивания OpenAI, поскольку я работаю с научными статьями.
Эта модель дороже, чем их маленькая, и, возможно, не идеальна для этого варианта использования.
Я бы рассмотрел специализированные модели для конкретных областей или рассмотрел возможность тонкой настройки собственной. Помните, если встраиваемая модель не имеет достаточно примеров, похожих на тексты, которые вы встраиваете, будет сложнее сопоставить их с релевантными документами.
Для поддержки гибридного поиска и поиска BM25 мы также создаём лексический индекс (разреженные векторы). BM25 работает с точными токенами (например, «ID 826384»), а не возвращает текст со «схожим значением», как это делает семантический поиск.
Чтобы протестировать семантический поиск, мы создадим запрос, на который, как я думаю, могут ответить собранные нами статьи, например: «Почему студенты магистратуры права хуже справляются с более длинными контекстными окнами, и что с этим делать?»
[1] оценка=0,5071 doc=docs_ingestor/docs/arxiv/2508.15253.pdf chunk=S3::C02::251009131027 текст: 1 Введение Эта проблема усугубляется, когда неверные, но высоко оцененные контексты служат жесткими отрицаниями. Традиционный RAG, т. е. простое добавление * Автор-корреспондент 1 https://github.com/eunseongc/CARE Рисунок 1: LLM пытаются разрешить конфликт контекста и памяти. Зелёные столбцы показывают количество вопросов, на которые даны правильные ответы без поиска в закрытой книге. Синие и жёлтые столбцы показывают производительность при наличии положительного или отрицательного контекста соответственно. Закрытая книга с положительным контекстом, отрицательным контекстом 1 8k 25,1% 49,1% 39,6% 47,5% 6k 4k 1 2k 4 Mistral-7b LLaMA3-8b GPT-4o-mini Claude-3.5 извлек контекст из подсказки, с трудом различает неверный внешний контекст и правильные параметрические знания (Ren et al., 2025). Это несоответствие приводит к переопределению правильных внутренних представлений, что приводит к существенному снижению производительности при ответах на вопросы, на которые модель изначально ответила правильно. Как показано на рисунке 1, мы наблюдали значительное падение производительности на 25,149,1% по всему состоянию [2] оценка=0,5022 doc=docs_ingestor/docs/arxiv/2508.19614.pdf фрагмент=S3::C03::251009132038 текст: 1 Введения Несмотря на эти достижения, LLM могут недостаточно использовать точные внешние контексты, непропорционально отдавая предпочтение внутренним параметрическим знаниям во время генерации [50, 40]. Эта чрезмерная зависимость рискует распространением устаревшей информации или галлюцинаций, подрывая надежность систем RAG. Удивительно, но недавние исследования выявляют парадоксальный феномен: внедрение шума — случайных документов или токенов — в извлеченные контексты, которые уже содержат релевантные ответу фрагменты, может повысить точность генерации [10, 49]. Хотя этот подход с внедрением шума прост и эффективен, его основное влияние на LLM остается неясным. Кроме того, длинные контексты, содержащие шумовые документы, создают вычислительные затраты. Поэтому важно разработать более принципиальные стратегии, которые могут достичь аналогичных преимуществ без чрезмерных затрат. [3] оценка=0.4982 doc=docs_ingestor/docs/arxiv/2508.19614.pdf фрагмент=S6::C18::251009132038 текст: 4 эксперимента 4.3 Анализ экспериментов Качественное исследование В таблице 4 мы анализируем исследование случая из набора данных NQ с использованием модели Llama2-7B, оценивая четыре стратегии декодирования: GD(0), CS, DoLA и LFD. Несмотря на доступ к документам Groundtruth, как GD(0), так и DoLA генерируют неверные ответы (например, «18 минут»), что указывает на ограниченные возможности для интеграции контекстных доказательств. Аналогичным образом, хотя CS и дает частично релевантный ответ («Техасская революция»), он демонстрирует пониженную фактическую согласованность с исходным материалом. Напротив, LFD демонстрирует превосходное использование извлеченного контекста, синтезируя точный и фактически выровненный ответ. Дополнительные тематические исследования и анализы приведены в Приложении F. [4] оценка=0,4857 doc=docs_ingestor/docs/arxiv/2507.23588.pdf фрагмент=S6::C03::251009122456 текст: 4 Результаты Рисунок 4: Изменение распределения паттернов внимания в различных моделях. Для вариантов DiffLoRA мы строим график массы внимания для основного компонента (зеленый) и компонента шумоподавления (желтый). Обратите внимание, что масса внимания нормализована по количеству токенов в каждой части последовательности. Отрицательное внимание показано после того, как оно масштабировано по λ. DiffLoRA соответствует варианту с изучаемыми параметрами λ и LoRa в обоих терминах. BOS CONTEXT 1 MAGIC NUMBER CONTEXT 2 QUERY 0 0.2 0.4 0.6 BOS CONTEXT 1 MAGIC NUMBER CONTEXT 2 QUERY BOS CONTEXT 1 MAGIC NUMBER CONTEXT 2 QUERY BOS CONTEXT 1 MAGIC NUMBER CONTEXT 2 QUERY Llama-3.2-1B LoRA DLoRA-32 DLoRA, Tulu-3 работают аналогично исходной модели, однако уступают LoRA. При увеличении длины контекста с большим количеством демонстрационных примеров DiffLoRA, похоже, испытывает ещё большие трудности в TREC-fine и Banking77. Это может быть связано с природой данных, настроенных на инструкции, и max_sequence_length = 4096, применяемым во время тонкой настройки. LoRA подвержен меньшему влиянию, вероятно, потому, что он меньше расходится [5] оценка=0.4838 doc=docs_ingestor/docs/arxiv/2508.15253.pdf chunk=S3::C03::251009131027 текст: 1 Введение. Для смягчения конфликта контекста и памяти существующие исследования, такие как адаптивный поиск (Ren et al., 2025; Baek et al., 2025) и стратегии декодирования (Zhao et al., 2024; Han et al., 2025), корректируют влияние внешнего контекста до или во время формирования ответа. Однако из-за ограниченной способности LLM обнаруживать конфликты он подвержен вводящим в заблуждение контекстным данным, которые противоречат параметрическим знаниям LLM. В последнее время надежная подготовка дала возможность LLM выявлять конфликты (Asai et al., 2024; Wang et al., 2024). Как показано на рисунке 2(a), она позволяет LLM [6] score=0.4827 doc=docs_ingestor/docs/arxiv/2508.05266.pdf chunk=S27::C03::251009123532 text: B. Критерии подклассификации для неверной интерпретации спецификаций проектирования Изначально, касаясь сценариев с длинным контекстом, мы наблюдали, что прямое побуждение LLM генерировать RTL-код на основе длинных контекстов часто приводило к тому, что определенные сегменты кода неточно отражали высокоуровневые требования. Однако, вручную разложив длинный контекст — сохранив только ключевой описательный текст, относящийся к ошибочным сегментам, и опустив ненужные детали — LLM регенерировал RTL-код, который правильно соответствовал спецификациям. Как показано на рис. 23, после ручной разложения длинного контекста LLM успешно сгенерировал правильный код. Это показывает, что избыточность в длинных контекстах является ограничивающим фактором в способности LLM генерировать точный RTL-код. [7] score=0.4798 doc=docs_ingestor/docs/arxiv/2508.19614.pdf chunk=S3::C02::251009132038 text: 1 Введения Рисунок 1: Иллюстрация послойного поведения в LLM для RAG. При наличии запроса и извлеченных документов с правильным ответом («Реал Мадрид») поверхностные слои фиксируют локальный контекст, средние слои фокусируются на контенте, релевантном ответу, в то время как глубокие слои могут чрезмерно полагаться на внутренние знания и создавать иллюзии (например, «Барселона»). Наше предложение: LFD объединяет сигналы среднего слоя в конечный результат для сохранения внешних знаний и повышения точности. Поверхностные слои Средние слои Глубокие слои У кого больше титулов Ла Лиги: у «Реала» или «Барселоны»? … Девять команд становились чемпионами, причем «Реал Мадрид» выигрывал титул рекордные 33 раза, а «Барселона» — 25 раз… Запрос Полученный документ …при этом «Реал Мадрид» выигрывал титул рекордные 33 раза, а «Барселона» — 25 раз… Моделирование в кратком контексте Фокус на правильном ответе Ответ: «Барселона» Неправильный ответ LLM …при этом «Реал Мадрид» выигрывал титул рекордные 33 раза, а «Барселона» — 25 раз… …при этом «Реал Мадрид» выигрывал титул рекордные 33 раза, а «Барселона» — 25 раз… Внутренние знания Confou
Из приведенных выше результатов мы видим, что поисковик смог найти несколько интересных отрывков, в которых обсуждаются темы, которые могут ответить на запрос.
Если мы попробуем BM25 (который соответствует точным токенам) с тем же запросом, мы получим следующие результаты:
[1] score=22.0764 doc=docs_ingestor/docs/arxiv/2507.20888.pdf chunk=S4::C27::251009115003 text: 3 APPROACH 3.2.2 Извлечение знаний о проекте Извлечение похожего кода. Похожие фрагменты в пределах одного проекта ценны для автодополнения кода, даже если они не полностью воспроизводимы. На этом этапе мы также извлекаем похожие фрагменты кода. Следуя RepoCoder, мы больше не используем незаконченный код в качестве запроса, а вместо этого используем черновик кода, потому что черновик кода ближе к истинному по сравнению с незаконченным кодом. Мы используем индекс Жаккара для вычисления сходства между черновиком кода и фрагментами кода-кандидатами. Затем мы получаем список, отсортированный по оценкам. Из-за потенциально больших различий в длине между фрагментами кода мы больше не используем метод top-k. Вместо этого мы получаем фрагменты кода от самых высоких к самым низким оценкам, пока не будет заполнена предустановленная длина контекста. [2] оценка = 17,4931 doc = docs_ingestor / docs / arxiv / 2508.09105.pdf chunk = S20::C08::251009124222 текст: C. Исследования абляции Результат абляции по атрибуции White Box: Таблица V показывает сравнительный результат методов атрибуции White Box с шумом, отсева White Box с альтернативной моделью и нашего текущего метода атрибуции Black Box с нулевым градиентом и шумом по двум категориям LLM. Мы можем знать, что: во-первых, атрибуция White Box с шумом находится в желаемом состоянии, поэтому средний балл точности двух LLM получает 0,8612 и 0,8073. Во-вторых, альтернативные модели (две модели обмениваются для атрибуции) достигают 0,7058 и 0,6464. Наконец, наш текущий метод атрибуции черного ящика с шумом получает точность 0,7008 и 0,6657 двумя LLM. [3] оценка=17,1458 doc=docs_ingestor/docs/arxiv/2508.05100.pdf фрагмент=S4::C03::251009123245 текст: Предварительные сведения Основываясь на этом, вдохновленные существующими анализами (Чжан и др., 2024c), мы измеряем количество информации, которую получает позиция, с помощью дискретной энтропии, как показано в следующем уравнении: которое количественно определяет, сколько информации ti получает с точки зрения внимания. Это понимание предполагает, что LLM испытывают трудности с более длинными последовательностями, когда не обучены на них, вероятно, из-за расхождения в информации, полученной токенами в более длинных контекстах. Исходя из предыдущего анализа, оптимизация энтропии внимания должна быть сосредоточена на двух аспектах: Информационная энтропия в позициях, которые относительно важны и, вероятно, содержат ключевую информацию, должна увеличиваться.
В данном случае результаты по этому запросу не впечатляют, но иногда запросы включают в себя определенные ключевые слова, которые нам нужно сопоставить, и тогда BM25 будет лучшим выбором.
Мы можем проверить это, изменив запрос на «документы Анирбана Саха Аника» с помощью BM25.
[1] оценка=62.3398 doc=authors.csv chunk=authors::row::1::251009110024 текст: имя_автора: Анирбан Саха Аник n_papers: 2 article_1: 2509.01058 article_2: 2507.07307 [2] оценка=56.4007 doc=titles.csv chunk=titles::row::24::251009110138 текст: идентификатор: 2509.01058 заголовок: Говорение на правильном уровне: генерация контрречи, контролируемая грамотностью, с помощью RAG-RL ключевые слова: контролируемая грамотность; Дезинформация о здоровье; Общественное здравоохранение; RAG; RL; Обучение с подкреплением; Генерация дополненной реальности с поиском abstract_url: https://arxiv.org/abs/2509.01058 created: 2025-09-10 00:00:00 UTC author_1: Сяоин Сун author_2: Анирбан Саха Аник author_3: Дибакар Баруа author_4: Пэнчэн Ло author_5: Цзюньхуа Дин author_6: Линцзы Хун [3] score=56.2614 doc=titles.csv chunk=titles::row::106::251009110138 text: id: 2507.07307 title: Многоагентная расширенная структура поиска для контраргументации на основе фактических данных против дезинформации о здоровье keywords: Улучшение доказательств; Дезинформация о здоровье; LLM; Большие языковые модели; RAG; Уточнение ответа; Генерация дополненной реальности для поиска. abstract_url: https://arxiv.org/abs/2507.07307 Создано: 2025-07-27 00:00:00 UTC Автор_1: Анирбан Саха Аник Автор_2: Сяоин Сун Автор_3: Эллиот Ван Автор_4: Брайан Ван Автор_5: Бенгису Яримбас Автор_6: Линцзы Хун
Во всех результатах выше упоминается «Anirban Saha Anik», и это именно то, что мы ищем.
Если бы мы запустили это с семантическим поиском, он бы вернул не только имя «Анирбан Саха Аник», но и похожие имена.
[1] оценка = 0,5810 doc = authors.csv фрагмент = authors::row::1::251009110024 текст: имя автора: Анирбан Саха Аник количество статей: 2 статья_1: 2509,01058 статья_2: 2507,07307 [2] оценка = 0,4499 doc = authors.csv фрагмент = authors::row::55::251009110024 текст: имя автора: Ананд А. Раджашекар количество статей: 1 статья_1: 2508,0199 [3] оценка = 0,4320 doc = authors.csv фрагмент = authors::row::59::251009110024 текст: имя автора: Ануп Маямпурах количество статей: 1 статья_1: 2508.14817 [4] оценка = 0,4306 doc=authors.csv фрагмент = авторы::строка::69::251009110024 текст: имя_автора: Авишек Ананд количество статей: 1 статья_1: 2508.15437 [5] оценка = 0,4215 doc=authors.csv фрагмент = авторы::строка::182::251009110024 текст: имя_автора: Ганеш Анантанараянан количество статей: 1 статья_1: 2509.14608
Это хороший пример того, что семантический поиск не всегда является идеальным методом — схожие названия не обязательно означают, что они релевантны запросу.
Таким образом, есть случаи, когда семантический поиск является идеальным вариантом, а есть случаи, когда BM25 (сопоставление токенов) является лучшим выбором.
Мы также можем использовать гибридный поиск, который сочетает семантический поиск и BM25.
Ниже вы увидите результаты гибридного поиска по исходному запросу: «почему LLM-программы работают хуже при более длинных контекстных окнах и что с этим делать?»
[1] оценка=0,5000 doc=docs_ingestor/docs/arxiv/2508.15253.pdf chunk=S3::C02::251009131027 текст: 1 Введение Эта проблема усугубляется, когда неверные, но высоко оцененные контексты служат жесткими отрицаниями. Традиционный RAG, т. е. простое добавление * Автор-корреспондент 1 https://github.com/eunseongc/CARE Рисунок 1: LLM пытаются разрешить конфликт контекста и памяти. Зелёные столбцы показывают количество вопросов, на которые даны правильные ответы без поиска в закрытой книге. Синие и жёлтые столбцы показывают производительность при наличии положительного или отрицательного контекста соответственно. Закрытая книга с положительным контекстом, отрицательным контекстом 1 8k 25,1% 49,1% 39,6% 47,5% 6k 4k 1 2k 4 Mistral-7b LLaMA3-8b GPT-4o-mini Claude-3.5 извлек контекст из подсказки, с трудом различает неверный внешний контекст и правильные параметрические знания (Ren et al., 2025). Это несоответствие приводит к переопределению правильных внутренних представлений, что приводит к существенному снижению производительности при ответах на вопросы, на которые модель изначально ответила правильно. Как показано на рисунке 1, мы наблюдали значительное падение производительности на 25,149,1% по всему state-of-the- [2] score=0.5000 doc=docs_ingestor/docs/arxiv/2507.20888.pdf chunk=S4::C27::251009115003 text: 3 APPROACH 3.2.2 Извлечение знаний о проекте Извлечение похожего кода. Похожие фрагменты в одном проекте ценны для автодополнения кода, даже если они не полностью воспроизводимы. На этом этапе мы также извлекаем похожие фрагменты кода. Следуя RepoCoder, мы больше не используем незаконченный код в качестве запроса, а вместо этого используем черновик кода, потому что черновик кода ближе к истинному по сравнению с незаконченным кодом. Мы используем индекс Жаккара для вычисления сходства между черновиком кода и фрагментами кода-кандидатами. Затем мы получаем список, отсортированный по оценкам. Из-за потенциально больших различий в длине фрагментов кода мы больше не используем метод «top-k». Вместо этого мы получаем фрагменты кода от наивысшей к наименьшей оценке, пока не будет заполнена заданная длина контекста. [3] оценка=0.4133 doc=docs_ingestor/docs/arxiv/2508.19614.pdf chunk=S3::C03::251009132038 текст: 1 Введение Несмотря на эти достижения, LLM могут недоиспользовать точные внешние контексты, непропорционально отдавая предпочтение внутренним параметрическим знаниям при генерации [50, 40]. Такая чрезмерная зависимость рискует привести к распространению устаревшей информации или галлюцинаций, что подрывает надежность систем RAG. Удивительно, но недавние исследования выявили парадоксальный феномен: внедрение случайных документов или токенов, содержащих шум, в извлеченные контексты, уже содержащие фрагменты, релевантные ответам, может повысить точность генерации [10, 49]. Хотя этот подход к внедрению шума прост и эффективен, его фундаментальное влияние на LLM остаётся неясным. Более того, длинные контексты, содержащие шумовые документы, создают дополнительные вычислительные затраты. Поэтому важно разработать более принципиальные стратегии, которые позволят достичь аналогичных результатов без чрезмерных затрат. [4] оценка=0,1813 doc=docs_ingestor/docs/arxiv/2508.19614.pdf chunk=S6::C18::251009132038 текст: 4 Эксперименты 4.3 Анализ Эксперименты Качественное исследование В таблице 4 мы анализируем исследование случая из набора данных NQ с использованием модели Llama2-7B, оценивая четыре стратегии декодирования: GD(0), CS, DoLA и LFD. Несмотря на доступ к документам Groundtruth, как GD(0), так и DoLA генерируют неверные ответы (например, «18 минут»), что указывает на ограниченную способность интегрировать контекстные доказательства. Аналогичным образом, хотя CS дает частично релевантный ответ («Техасская революция»), он демонстрирует пониженную фактическую согласованность с исходным материалом. Напротив, LFD демонстрирует превосходное использование извлеченного контекста, синтезируя точный и фактологически согласованный ответ. Дополнительные исследования случаев и анализы приведены в Приложении F.
Я обнаружил, что семантический поиск лучше всего подходит для этого запроса, поэтому может быть полезно выполнить несколько запросов с разными методами поиска, чтобы извлечь первые фрагменты (хотя это также добавляет сложности).
Итак, давайте перейдем к созданию чего-то, что сможет преобразовать исходный запрос в несколько оптимизированных версий и объединить результаты.
Оптимизатор многозапросов
В этой части мы рассмотрим, как оптимизировать сложные пользовательские запросы, генерируя несколько целевых вариантов и выбирая правильный метод поиска для каждого из них. Это может улучшить полноту, но требует компромиссов.
Все системы абстракции агентов, которые вы видите, обычно преобразуют пользовательский запрос при выполнении поиска. Например, при использовании QueryTool в LlamaIndex он использует LLM для оптимизации входящего запроса.

Мы можем перестроить эту часть самостоятельно, но вместо этого наделим её возможностью создавать несколько запросов, а также настраивать метод поиска. При работе с большим количеством документов вы также можете настроить фильтры на этом этапе.
Что касается создания большого количества запросов, я бы постарался сделать всё просто, поскольку подобные проблемы приведут к низкому качеству результатов поиска. Чем больше нерелевантных запросов генерирует система, тем больше шума она вносит в конвейер.
Функция, которую я здесь создал, будет генерировать 1–3 запроса в академическом стиле, а также метод поиска, который будет использоваться, на основе сложного запроса пользователя.
Исходный запрос: Почему все говорят, что RAG не масштабируется? Как это исправить? Сгенерированные запросы: — гибридный: проблемы масштабируемости RAG — гибридный: решения проблем масштабирования RAG
Мы получим такие результаты:
Запрос 1 (гибридный) топ-20 для запроса: проблемы масштабируемости RAG [1] оценка = 0,5000 doc = docs_ingestor / docs / arxiv / 2507.18910.pdf фрагмент = S22::C05::251104142800 текст: 7 Проблемы RAG 7.2.1 Масштабируемость и инфраструктура Масштабное развертывание RAG требует существенной инженерии для поддержки больших корпусов знаний и эффективных индексов поиска. Системы должны обрабатывать миллионы или миллиарды документов, требуя значительных вычислительных ресурсов, эффективного индексирования, распределенной вычислительной инфраструктуры и стратегий управления затратами [21]. Эффективные методы индексации, кэширование и многоуровневые подходы к поиску (например, каскадный поиск) становятся необходимыми при масштабировании, особенно в крупных развертываниях, таких как поисковые системы. [2] оценка=0,5000 doc=docs_ingestor/docs/arxiv/2507.07695.pdf chunk=SDOC::SUM::251104135247 текст: В данной статье предлагается фреймворк KeyKnowledgeRAG (K2RAG) для повышения эффективности и точности систем поиска-дополнения-генерации (RAG). Он решает проблемы высоких вычислительных затрат и масштабируемости, связанные с простыми реализациями RAG, путем внедрения таких методов, как графы знаний, гибридный подход к поиску и реферирование документов, для сокращения времени обучения и повышения точности ответов. Оценки показывают, что K2RAG значительно превосходит традиционные реализации, обеспечивая большую схожесть ответов и более быстрое время выполнения, тем самым предоставляя масштабируемое решение для компаний, которым требуются надежные вопросно-ответные системы. […] Запрос 2 (гибридный) топ-20 для запроса: решения проблем масштабирования RAG [1] оценка=0,5000 doc=docs_ingestor/docs/arxiv/2507.18910.pdf фрагмент=S22::C05::251104142800 текст: 7 проблем RAG 7.2.1 Масштабируемость и инфраструктура Масштабное развертывание RAG требует существенной инженерии для поддержки больших корпусов знаний и эффективных индексов поиска. Системы должны обрабатывать миллионы или миллиарды документов, что требует значительных вычислительных ресурсов, эффективного индексирования, распределенной вычислительной инфраструктуры и стратегий управления затратами [21]. Эффективные методы индексации, кэширование и многоуровневые подходы к поиску (например, каскадный поиск) становятся необходимыми при масштабировании, особенно в крупных развертываниях, таких как поисковые системы. [2] оценка=0,5000 doc=docs_ingestor/docs/arxiv/2508.05100.pdf chunk=S3::C06::251104155301 текст: Введение. Эмпирический анализ, проведённый в рамках нескольких реальных тестов, показывает, что BEE-RAG фундаментально изменяет законы масштабирования энтропии, регулирующие традиционные системы RAG, что обеспечивает надёжное и масштабируемое решение для систем RAG, работающих с контекстами с большой длиной. Наши основные достижения можно резюмировать следующим образом: мы вводим концепцию сбалансированной контекстной энтропии — новую формулировку внимания, которая обеспечивает инвариантность энтропии при разной длине контекста и распределяет внимание по важным сегментам. Это решает критическую проблему расширения контекста в RAG. […]
Мы также можем протестировать систему с определенными ключевыми словами, такими как имена и идентификаторы, чтобы убедиться, что она выбирает BM25, а не семантический поиск.
Исходный запрос: есть ли статьи Чэньсиня Дяо? Сгенерированные запросы: — BM25: Чэньсинь Дяо
Это выведет результаты, в которых Чэньсинь Дяо будет явно упомянут.
Стоит отметить, что BM25 может вызывать проблемы, когда пользователи неправильно пишут имена, например, запрашивают «Chenx Dia» вместо «Chenxin Diao». Поэтому на самом деле вам, возможно, стоит просто применить гибридный поиск ко всем этим запросам (а затем позволить системе повторного ранжирования отсеять нерелевантные результаты).
Если вы хотите сделать это еще лучше, вы можете создать систему поиска, которая генерирует несколько примеров запросов на основе входных данных, поэтому, когда поступает исходный запрос, вы извлекаете примеры, которые помогут оптимизатору.
Это помогает, поскольку меньшие модели не очень хорошо справляются с преобразованием запутанных человеческих запросов в запросы с более точными академическими формулировками.
Например, когда пользователь спрашивает, почему LLM лжет, оптимизатор может преобразовать запрос во что-то вроде «причины неточностей в больших языковых моделях», а не искать напрямую «галликунации».
После параллельной выборки результатов мы их объединяем. Результат будет выглядеть примерно так:
RRF Fusion топ-38 по запросу: почему все говорят, что RAG не масштабируется? как люди это исправляют? [1] оценка = 0,0328 doc = docs_ingestor / docs / arxiv / 2507.18910.pdf chunk = S22:: C05:: 251104142800 текст: 7 Проблемы RAG 7.2.1 Масштабируемость и инфраструктура Масштабное развертывание RAG требует существенной инженерии для поддержки больших корпусов знаний и эффективных индексов поиска. Системы должны обрабатывать миллионы или миллиарды документов, требуя значительных вычислительных ресурсов, эффективной индексации, распределенной вычислительной инфраструктуры и стратегий управления затратами [21]. Эффективные методы индексации, кэширование и многоуровневые подходы к поиску (например, каскадный поиск) становятся необходимыми при масштабировании, особенно в крупных развертываниях, таких как поисковые системы. [2] оценка=0,0313 doc=docs_ingestor/docs/arxiv/2507.18910.pdf chunk=S22::C42::251104142800 текст: 7 Проблемы RAG 7.5.5 Масштабируемость Проблемы масштабируемости возникают по мере расширения корпусов знаний. Расширенное индексирование, распределенный поиск и методы приблизительного ближайшего соседа облегчают эффективную обработку крупномасштабных баз знаний [57]. Выборочное индексирование и курирование корпусов в сочетании с улучшениями инфраструктуры, такими как кэширование и параллельный поиск, позволяют системам RAG масштабироваться до огромных хранилищ знаний. Исследования показывают, что модели среднего размера, дополненные большими внешними корпусами, могут значительно превосходить более крупные автономные модели, что указывает на преимущества в эффективности параметров [10]. [3] оценка=0,0161 doc=docs_ingestor/docs/arxiv/2507.07695.pdf chunk=SDOC::SUM::251104135247 текст: В данной статье предлагается фреймворк KeyKnowledgeRAG (K2RAG) для повышения эффективности и точности систем поиска-дополнения-генерации (RAG). Он решает проблемы высоких вычислительных затрат и масштабируемости, связанные с простыми реализациями RAG, путем внедрения таких методов, как графы знаний, гибридный подход к поиску и реферирование документов, для сокращения времени обучения и повышения точности ответов. Оценки показывают, что K2RAG значительно превосходит традиционные реализации, достигая большего сходства ответов и более быстрого выполнения, тем самым предоставляя масштабируемое решение для компаний, которым требуются надежные вопросно-ответные системы. [4] оценка=0,0161 doc=docs_ingestor/docs/arxiv/2508.05100.pdf chunk=S3::C06::251104155301 текст: Введение. Эмпирический анализ, проведённый в рамках нескольких реальных тестов, показывает, что BEE-RAG фундаментально изменяет законы масштабирования энтропии, регулирующие традиционные системы RAG, что обеспечивает надёжное и масштабируемое решение для систем RAG, работающих с контекстами с большой длиной. Наши основные достижения можно резюмировать следующим образом: мы вводим концепцию сбалансированной контекстной энтропии — новую формулировку внимания, которая обеспечивает инвариантность энтропии при различной длине контекста и распределяет внимание по важным сегментам. Это решает критическую проблему расширения контекста в RAG. […]
Мы видим, что есть несколько хороших совпадений, но также и несколько нерелевантных, которые нам нужно будет отфильтровать дальше.
Прежде чем мы продолжим, хотим отметить, что это тот шаг, который вы, скорее всего, сократите или оптимизируете, если попытаетесь уменьшить задержку.
Я считаю, что обладатели степени магистра права не очень хорошо справляются с созданием ключевых запросов, которые на самом деле извлекают полезную информацию, поэтому, если это сделано неправильно, это просто добавляет больше шума.
Добавление реранжера
Мы получаем результаты от поисковой системы, и некоторые из них хороши, а другие нерелевантны, поэтому большинство поисковых систем используют тот или иной механизм повторного ранжирования.
Реранжировщик принимает несколько фрагментов и присваивает каждому из них оценку релевантности на основе исходного запроса пользователя. У вас есть несколько вариантов, включая использование более мелкого варианта, но я буду использовать реранжировщик Cohere.
Мы можем протестировать этот реранжировщик на первом вопросе, который мы задали в предыдущем разделе: «Почему все говорят, что RAG не масштабируется? Как это исправить?»
[… optimizer… retrieval… fuse…] Сводка по переранжированию: — strategy=cohere — model=rerank-english-v3.0 — candidates=32 — eligible_above_threshold=4 — held=4 (reranker_threshold=0.35) Переранжировано Релевантно (4/32 сохраняется ≥ 0.35) топ-4 для запроса: почему все говорят, что RAG не масштабируется? как люди это исправляют? [1] score=0.7920 doc=docs_ingestor/docs/arxiv/2507.07695.pdf chunk=S4::C08::251104135247 text: 1 Введение Масштабируемость: Наивные реализации Retrieval-Augmented Generation (RAG) часто полагаются на 16-битные модели больших языков с плавающей точкой (LLM) для компонента генерации. Однако этот подход создаёт серьёзные проблемы масштабируемости из-за повышенных требований к памяти для размещения LLM, а также увеличения времени вывода из-за использования числового типа с более высокой точностью. Для более эффективного масштабирования критически важно интегрировать методы или методики, сокращающие объём памяти и время вывода моделей-генераторов. Квантованные модели предлагают более масштабируемые решения благодаря меньшим вычислительным требованиям, поэтому при разработке систем RAG следует стремиться использовать квантованные LLM для более экономичного развёртывания по сравнению с полностью настроенными LLM, производительность которых может быть высокой, но развёртывание которых обходится дороже из-за более высоких требований к памяти. Роль квантованного LLM в самом конвейере RAG должна быть минимальной и для средств переписывания извлеченной информации в презентабельный вид для конечных пользователей [2] оценка = 0,4749 doc = docs_ingestor / docs / arxiv / 2507.18910.pdf chunk = S22:: C42:: 251104142800 текст: 7 Проблемы RAG 7.5.5 Масштабируемость Проблемы масштабируемости возникают по мере расширения корпусов знаний. Расширенное индексирование, распределенный поиск и методы приблизительного ближайшего соседа облегчают эффективную обработку крупномасштабных баз знаний [57]. Выборочное индексирование и курирование корпусов в сочетании с улучшениями инфраструктуры, такими как кэширование и параллельный поиск, позволяют системам RAG масштабироваться до огромных хранилищ знаний. Исследования показывают, что модели среднего размера, дополненные большими внешними корпусами, могут значительно превосходить более крупные автономные модели, что указывает на преимущества в эффективности параметров [10]. [3] оценка=0,4304 doc=docs_ingestor/docs/arxiv/2507.18910.pdf chunk=S22::C05::251104142800 текст: 7 Проблемы RAG 7.2.1 Масштабируемость и инфраструктура Развертывание RAG в больших масштабах требует значительных инженерных усилий для поддержки больших корпусов знаний и эффективных индексов поиска. Системы должны обрабатывать миллионы или миллиарды документов, что требует значительных вычислительных ресурсов, эффективного индексирования, распределенной вычислительной инфраструктуры и стратегий управления затратами [21]. Эффективные методы индексации, кэширование и многоуровневые подходы к поиску (например, каскадный поиск) становятся необходимыми при масштабировании, особенно в крупных развертываниях, таких как поисковые системы. [4] оценка = 0,3556 doc = docs_ingestor / docs / arxiv / 2509.13772.pdf chunk = S11:: C02:: 251104182521 текст: 7. Обсуждение и ограничения Масштабируемость RAGOrigin: Мы расширяем нашу оценку, масштабируя базу знаний набора данных NQ до 16,7 миллионов текстов, объединяя записи из баз знаний NQ, HotpotQA и MS-MARCO. Используя те же вопросы пользователей из NQ, мы оцениваем производительность RAGOrigin при больших объемах данных. Как показано в таблице 16, RAGOrigin сохраняет стабильную эффективность и производительность даже на этой значительно расширенной базе данных. Эти результаты показывают, что RAGOrigin остается надежным при масштабировании, что делает его подходящим для приложений корпоративного уровня, требующих больших
Помните, на этом этапе мы уже преобразовали запрос пользователя, выполнили семантический или гибридный поиск и объединили результаты перед передачей фрагментов в средство повторного ранжирования.
Если взглянуть на результаты, то можно ясно увидеть, что он способен выделить несколько релевантных фрагментов, которые можно использовать в качестве исходных данных.
Помните, что изначально в нем всего 150 документов.
Вы также видите, что он возвращает несколько фрагментов из одного документа. Мы настроим это позже при построении контекста, но если вы хотите получать уникальные документы, вы можете добавить сюда пользовательскую логику, чтобы задать ограничение на количество уникальных документов, а не фрагментов.
Давайте попробуем это с другим вопросом: «Галлюцинации при РАГ по сравнению с обычными ЛЛМ и как их уменьшить»
[… оптимизатор… поиск… fuse…] Сводка по повторному ранжированию: — стратегия = cohere — модель = rerank-english-v3.0 — кандидаты = 35 — подходящий_выше_порог = 12 — сохранено = 5 (порог = 0,2) Повторно ранжированный Релевантный (5/35 сохранено ≥ 0,2) топ-5 для запроса: галлюцинации в rag против обычных llms и как их уменьшить [1] оценка = 0,9965 doc = docs_ingestor/docs/arxiv/2508.19614.pdf фрагмент = S7::C03::251104164901 текст: 5 Связанные работы Галлюцинации в LLM Галлюцинации в LLM относятся к случаям, когда модель генерирует ложную или неподтвержденную информацию, не основанную на ее справочных данных [42]. Существующие стратегии снижения риска включают многоагентные дебаты, где несколько экземпляров LLM совместно выявляют несоответствия посредством итеративных дебатов [8, 14]; проверку самосогласованности, которая объединяет и согласует несколько путей рассуждений для уменьшения индивидуальных ошибок [53]; и редактирование модели, которое напрямую изменяет веса нейронной сети для исправления систематических фактических ошибок [62, 19]. Хотя системы RAG стремятся обосновывать ответы на основе полученных внешних знаний, недавние исследования показывают, что они всё ещё демонстрируют галлюцинации, особенно те, которые противоречат полученному содержанию [50]. Чтобы устранить это ограничение, в нашей работе проводится эмпирическое исследование, анализирующее, как LLM внутренне обрабатывают внешние знания [2] оценка=0.9342 doc=docs_ingestor/docs/arxiv/2508.05509.pdf chunk=S3::C01::251104160034 текст: Введение Большие языковые модели (LLM), такие как Claude (Anthropic 2024), ChatGPT (OpenAI 2023) и серия Deepseek (Liu et al. 2024), продемонстрировали выдающиеся возможности во многих реальных задачах (Chen et al. 2024b; Zhou et al. 2025), таких как ответы на вопросы (Allam and Haggag 2012), понимание текста (Wright and Cervetti 2017) и генерация контента (Kumar 2024). Несмотря на успех, эти модели часто подвергаются критике за их склонность вызывать галлюцинации, выдавая неверные утверждения по задачам, выходящим за рамки их знаний и восприятия (Цзи и др., 2023; Чжан и др., 2024). В последнее время перспективным решением для облегчения таких галлюцинаций стала модель дополненной генерации (RAG) (Гао и др., 2023; Льюис и др., 2020). Благодаря динамическому использованию внешних знаний из текстовых корпусов, RAG позволяет LLM генерировать более точные и надежные ответы без дорогостоящего переобучения (Lewis et al. 2020; Рисунок 1: Сравнение трех парадигм. LAG демонстрирует более легкие свойства по сравнению с GraphRAG, в то время как [3] оценка = 0,9030 doc=docs_ingestor/docs/arxiv/2509.13702.pdf chunk=S3::C01::251104182000 текст: АННОТАЦИЯ Галлюцинация остается критическим препятствием для надежного развертывания больших языковых моделей (LLM) в приложениях с высокими ставками. Существующие стратегии смягчения, такие как генерация дополненного поиска (RAG) и апостериорная верификация, часто являются реактивными, неэффективными или не устраняют первопричину в генеративном процессе. Вдохновленные теорией когнитивных двухпроцессов, мы предлагаем D Динамическая самоусиливающая калибровка для подавления галлюцинаций (DSCC-HS) – это новая проактивная структура, которая непосредственно вмешивается в процесс авторегрессионного декодирования. DSCC-HS работает по двухфазному механизму: (1) Во время обучения компактная прокси-модель итеративно выравнивается на две состязательные роли – прокси-модель фактического выравнивания (FAP) и прокси-модель обнаружения галлюцинаций (HDP) – посредством оптимизации контрастного логарифмического пространства с использованием дополненных данных и параметрически эффективной адаптации LoRA. (2) Во время вывода эти замороженные прокси-модели динамически управляют большой целевой моделью, вводя управляющий вектор, выровненный по словарному запасу, в режиме реального времени (вычисляется как [4] оценка = 0,9007 doc=docs_ingestor/docs/arxiv/2509.09360.pdf chunk=S2::C05::251104174859 текст: 1 Введение Рисунок 1. Стандартный рабочий процесс поиска-расширенной генерации (RAG). Пользовательский запрос кодируется в векторное представление с использованием модели встраивания и запрашивается из векторной базы данных, созданной на основе корпуса документов. Наиболее релевантные фрагменты документа извлекаются и добавляются к исходному запросу, который затем предоставляется в качестве входных данных для большой языковой модели (LLM) для генерации окончательного ответа. Корпус Извлеченные_фрагменты Vectpr DB Модель встраивания Запрос Ответ LLM Поиск-расширенная генерация (RAG) [17] направлена на смягчение галлюцинаций путем заземления выходных данных модели в извлеченных актуальных документах, как показано на рисунке 1. Путем внедрения извлеченного текста из ре- [5] оценка=0,8986 doc=docs_ingestor/docs/arxiv/2508.04057.pdf chunk=S20::C02::251104155008 текст: Параметрические знания могут генерировать точные ответы. Эффекты галлюцинаций LLM. Чтобы оценить влияние галлюцинаций, когда большие языковые модели (LLM) генерируют ответы без поиска, мы проводим контролируемый эксперимент, основанный на простой эвристике: если сгенерированный ответ содержит числовые значения, он с большей вероятностью будет подвержен галлюцинациям. Это связано с тем, что LLM, как правило, менее надежны при получении точных фактов, таких как числа, даты или количества, только из параметрической памяти (Ji et al. 2023; Singh et al. 2025). Мы отфильтровываем все запросы с прямым ответом (DQ), ответы на которые содержат числа, а затем повторно запускаем наш DPR-AIS для этих запросов (см. Исключить число). Результаты представлены в табл. 5. В целом, исключая числовые DQs приводит к небольшому улучшению результатов. Среднее точное совпадение (EM) увеличивается с 35,03 до 35,12, а средний результат F1 — с 35,68 до 35,80. Хотя эти улучшения незначительны, они сопровождаются повышением коэффициента активации ретривера (RA) с 75,5% до 78,1%.
Этот запрос также выполняется достаточно хорошо (если посмотреть на полные возвращаемые фрагменты).
Мы также можем тестировать более сложные запросы пользователей, например: «почему llm лжет и тряпка помогают с этим?»
[… optimizer…] Исходный запрос: почему llm лжет, а rag help в этом? Сгенерированные запросы: — семантический: изучить причины неточностей LLM — гибридный: методы RAG для достоверности LLM […поиск… fuse…] Сводка по повторному ранжированию: — стратегия=cohere — модель=rerank-english-v3.0 — кандидаты=39 — допустимый_выше_порог=39 — сохранено=6 (порог=0) Повторно ранжировано: релевантно (6/39 сохранено ≥ 0) топ-6 для запроса: почему llm лжет, а rag help в этом? [1] оценка=0,0293 doc=docs_ingestor/docs/arxiv/2507.05714.pdf chunk=S3::C01::251104134926 текст: 1 Введение Генерация дополнения поиска (далее именуемая RAG) помогает большим языковым моделям (LLM) (OpenAI и др., 2024) уменьшить галлюцинации (Чжан и др., 2023) и получить доступ к данным в реальном времени 1 *Равный вклад. [2] оценка = 0,0284 doc = docs_ingestor / docs / arxiv / 2508.15437.pdf chunk = S3::C01::251104164223 текст: 1 Введение. Большие языковые модели (LLM), дополненные поиском, стали доминирующей парадигмой для задач обработки естественного языка, требующих больших знаний. В типичной схеме генерации с дополненным поиском (RAG) LLM извлекает документы из внешнего корпуса и обуславливает генерацию на основе извлеченных данных (Lewis et al., 2020b; Izacard and Grave, 2021). Такая схема смягчает ключевой недостаток LLM — галлюцинации — за счёт того, что генерация основана на знаниях из внешних источников. Системы RAG теперь поддерживают контроль качества в открытой области (Карпухин и др., 2020), проверку фактов (В и др., 2024; Шлихткрулл и др., 2023), диалог, основанный на знаниях, и контроль качества с пояснениями. [3] оценка=0.0277 doc=docs_ingestor/docs/arxiv/2509.09651.pdf chunk=S3::C01::251104180034 текст: 1 Введение Большие языковые модели (LLM) преобразили обработку естественного языка, достигнув передовых показателей в реферировании, переводе и ответах на вопросы. Однако, несмотря на свою универсальность, LLM склонны генерировать ложный или вводящий в заблуждение контент, явление, обычно называемое галлюцинацией [9, 21]. Хотя иногда они безвредны в повседневных приложениях, такие неточности создают значительные риски в областях, требующих строгой фактической корректности, включая медицину, юриспруденцию и телекоммуникации. В этих условиях дезинформация может иметь серьезные последствия, начиная от финансовых потерь и заканчивая угрозами безопасности и правовыми спорами. [4] оценка=0.0087 doc=docs_ingestor/docs/arxiv/2507.07695.pdf chunk=S4::C08::251104135247 текст: 1 Введение Масштабируемость: наивные реализации поиска и расширенной генерации (RAG) часто полагаются на 16-битные модели больших языков с плавающей точкой (LLM) для компонента генерации. Однако этот подход создает значительные проблемы с масштабируемостью из-за повышенных требований к памяти, необходимой для размещения LLM, а также более длительного времени вывода из-за использования числового типа с более высокой точностью. Для более эффективного масштабирования критически важно интегрировать методы и методики, сокращающие объём памяти и время вывода моделей-генераторов. Квантованные модели предлагают более масштабируемые решения благодаря меньшим вычислительным требованиям, поэтому при разработке систем RAG следует стремиться использовать квантованные LLM для более экономичного развертывания по сравнению с полностью настроенными LLM, производительность которых может быть хорошей, но развертывание которых требует больших затрат памяти. Роль квантованного LLM в самом конвейере RAG должна быть минимальной и служить средством преобразования полученной информации в презентабельный вид для конечных пользователей.
Прежде чем мы продолжим, мне нужно отметить, что есть моменты, когда этот реранжировщик не очень хорош, как вы увидите выше по оценкам.
Иногда он считает, что фрагменты не отвечают на вопрос пользователя, но на самом деле это не так, по крайней мере, если рассматривать эти фрагменты как семена.
Обычно при повторном ранжировании фрагменты должны намекать на весь контент, но мы используем эти фрагменты в качестве исходных данных, поэтому в некоторых случаях он будет оценивать результаты очень низко, но для нас этого достаточно, чтобы двигаться дальше.
Вот почему я установил очень низкий порог оценки.
Возможно, есть более удачные варианты, которые вы захотите изучить, например, создание собственного инструмента повторного ранжирования, который понимает, что вы ищете.
Тем не менее, теперь, когда у нас есть несколько релевантных документов, мы воспользуемся их метаданными, которые мы установили ранее при приеме, чтобы расширить и разбить фрагменты так, чтобы LLM получил достаточно контекста для понимания того, как ответить на вопрос.
Создайте контекст
Теперь, когда у нас есть несколько фрагментов в качестве исходных данных, мы извлечем больше информации из Redis, расширим ее и построим контекст.
Этот шаг, очевидно, намного сложнее, поскольку вам нужно построить логику для того, какие фрагменты извлекать и как (ключи, если они существуют, или соседи, если таковые имеются), извлекать информацию параллельно, а затем очищать фрагменты дальше.
После того как вы получили все фрагменты (плюс информацию о самих документах), вам необходимо объединить их, то есть удалить дубликаты фрагментов, возможно, установить ограничение на то, насколько далеко может расшириться система, и выделить, какие фрагменты были извлечены, а какие — расширены.
Конечный результат будет выглядеть примерно так:
Расширенные контекстные окна (поддержка Markdown): ## Документ № 1 — Объединение знаний и языка: сравнительное исследование ответов на вопросы на основе графов знаний с участием степеней LLM — `doc_id`: `doc::6371023da29b4bbe8242ffc5caf4a8cd` — **Последнее обновление:** 2025-11-04T17:44:07.300967+00:00 — **Контекст:** Сравнительное исследование методологий интеграции графов знаний в системы обеспечения качества с участием степеней LLM. — **Содержимое, извлеченное из документа:** «`текст [начало на странице 4] степеней LLM в обеспечении качества Появление степеней LLM ознаменовало собой эпоху преобразований в обработке естественного языка, особенно в области обеспечения качества. Эти модели, предварительно обученные на огромных корпусах разнообразных текстов, демонстрируют сложные возможности как в понимании естественного языка, так и в его генерации. Их способность выдавать связные, контекстно-релевантные и человекоподобные ответы на широкий спектр подсказок делает их исключительно подходящими для задач контроля качества, где предоставление точных и информативных ответов имеет первостепенное значение. Недавние достижения таких моделей, как BERT [57] и ChatGPT [58], значительно продвинули эту область вперед. LLM продемонстрировали высокую производительность в сценариях контроля качества в открытой области, таких как рассуждения на основе здравого смысла [20], благодаря их обширным встроенным знаниям об окружающем мире. Более того, их способность понимать и формулировать ответы на абстрактные или контекстно-дифференцированные запросы и задачи рассуждения [22] подчеркивает их полезность в решении сложных задач контроля качества, требующих глубокого семантического понимания. Несмотря на свои сильные стороны, LLM также создают проблемы: они могут демонстрировать контекстную неоднозначность или чрезмерную уверенность в своих выходных данных («галлюцинации»)[21], а их существенные вычислительные требования и требования к памяти усложняют развертывание в средах с ограниченными ресурсами. RAG, тонкая настройка в обеспечении качества ———————- это был отрывок, который мы сопоставили с запросом ————- LLM также сталкиваются с проблемами, когда дело доходит до обеспечения качества, специфичного для предметной области, или задач, где от них требуется точно вспомнить фактическую информацию, а не просто вероятностно генерировать то, что будет дальше. Исследования также изучили различные методы подсказки, такие как подсказка с цепочкой мыслей[24] и методы, основанные на выборке[23], для уменьшения галлюцинаций. Современные исследования все чаще изучают такие стратегии, как тонкая настройка и увеличение поиска, для улучшения систем обеспечения качества на основе LLM. Было показано, что тонкая настройка на доменно-специфичных корпусах (например, BioBERT для биомедицинских текстов [17], SciBERT для научных текстов [18]) заостряет фокус модели, сокращая нерелевантные или общие ответы в специализированных условиях, таких как медицинский или юридический контроль качества. Архитектуры с дополненным поиском, такие как RAG [19], объединяют LLM с внешними базами знаний, чтобы попытаться еще больше смягчить проблемы фактической неточности и обеспечить включение новой информации в режиме реального времени. Основываясь на способности RAG соединять параметрические и непараметрические знания, многие современные конвейеры контроля качества вводят легкий шаг повторного ранжирования [25] для просеивания извлеченных контекстов и продвижения отрывков, наиболее релевантных запросу. Однако RAG по-прежнему сталкивается с рядом проблем. Одна из ключевых проблем заключается в самом шаге поиска: если извлекателю не удается извлечь релевантные документы, генератор остается в состоянии галлюцинации или выдает неполные ответы. Более того, интеграция зашумленных или слабо релевантных контекстов может ухудшить качество ответа, а не улучшить его, особенно в областях с высокими ставками, где точность имеет решающее значение. Конвейеры RAG также чувствительны к качеству и согласованности домена базовой базы знаний и часто требуют обширной настройки для эффективного баланса полноты и точности. ————————————————————————————— [конец на странице 5] «` ## Документ № 2 — Каждый сам за себя: исследование оптимального встраивания в RAG — `doc_id`: `doc::3b9c43d010984d4cb11233b5de905555` — **Последнее обновление:** 2025-11-04T14:00:38.215399+00:00 — **Контекст:** Улучшение больших языковых моделей с использованием методов генерации дополненного поиска. — **Содержимое извлечено из документа:** «`текст [начало на странице 1] 1 Введение Большие языковые модели (LLM) в последнее время ускорили темпы трансформации во многих областях, включая транспорт (Lyu et al., 2025), искусство (Zhao et al., 2025) и образование (Gao et al., 2024), с помощью различных парадигм, таких как прямая генерация ответов, обучение с нуля на разных типах данных и тонкая настройка на целевых доменах. Однако проблема галлюцинаций (Henkel et al., 2024), связанная с LLM, долгое время сбивала людей с толку, вытекая из множества факторов, таких как недостаток знаний о заданной подсказке (Huang et al., 2025b) и предвзятый процесс обучения (Zhao, 2025). Будучи высокоэффективным решением, технология RetrievalAugmented Generation (RAG) широко применяется для построения базовых моделей (Chen et al., 2024) и практических агентов (Arslan et al., 2024). По сравнению с такими методами обучения, как тонкая настройка и настройка подсказок, её функция «plug-and-play» делает RAG эффективным, простым и экономичным подходом. Основная парадигма RAG заключается в том, чтобы сначала вычислить сходство между вопросом и фрагментами во внешнем корпусе знаний, а затем включить K наиболее релевантных фрагментов в подсказку для руководства LLM (Lewis et al., 2020). Несмотря на преимущества RAG, выбор подходящих моделей встраивания остаётся важной задачей, поскольку качество извлечённых ссылок напрямую влияет на результаты генерации LLM (Tu et al., 2025). Различия в обучающих данных и архитектуре модели приводят к появлению различных моделей встраивания, обеспечивающих преимущества в различных областях. Различные расчеты сходства между моделями встраивания часто оставляют исследователей в неопределенности относительно того, как выбрать оптимальную. Следовательно, повышение точности RAG с точки зрения моделей встраивания продолжает оставаться текущей областью исследований. ———————- это был отрывок, который мы сопоставили с запросом ————- Чтобы заполнить этот пробел в исследованиях, мы предлагаем два метода улучшения RAG путем объединения преимуществ нескольких моделей встраивания. Первый метод называется Mixture-Embedding RAG, который сортирует извлеченные материалы из нескольких моделей встраивания на основе нормализованного сходства и выбирает первые K материалов в качестве окончательных ссылок. Второй метод называется Confident RAG, где мы сначала используем vanilla RAG для генерации ответов несколько раз, каждый раз применяя другую модель встраивания и записывая связанные метрики уверенности, а затем выбираем ответ с наивысшим уровнем уверенности в качестве окончательного ответа. Проверяя наш подход с использованием нескольких LLM и моделей встраивания, мы иллюстрируем превосходную производительность и обобщение Confident RAG, хотя MixtureEmbedding RAG может проигрывать vanilla RAG. Основные достижения этой статьи можно резюмировать следующим образом: сначала мы отмечаем, что в RAG различные модели встраивания работают в своих собственных априорных доменах. Чтобы использовать сильные стороны различных моделей встраивания, мы предлагаем и тестируем два новых метода RAG: MixtureEmbedding RAG и Confident RAG. Эти методы эффективно используют полученные результаты из различных моделей встраивания в их полной мере. ————————————————————————————— Хотя Mixture-Embedding RAG работает аналогично vanilla RAG, метод Confident RAG демонстрирует превосходную производительность по сравнению как с vanilla LLM, так и с vanilla RAG, со средним улучшением на 9,9% и 4,9% соответственно при использовании наилучшей метрики уверенности. Кроме того, мы обсуждаем оптимальное количество моделей встраивания для метода Confident RAG на основе полученных результатов. […]
Общий контекст будет содержать несколько документов и около 2–3 тысяч токенов. Здесь есть некоторые потери, но вместо того, чтобы принимать решение о LLM, мы отправляем больше информации, чтобы система могла сканировать целые документы, а не отдельные фрагменты.
Помните, вы можете взглянуть на конвейер для пяти различных запросов здесь, чтобы увидеть, как он работает.
Для создаваемой вами системы вы также можете кэшировать этот контекст, чтобы LLM мог ответить на последующие вопросы.
Добавьте LLM для ответа (буква G в слове RAG)
Давайте закончим с последним шагом, просто чтобы посмотреть, как магистр права отвечает, учитывая переданный ему контекст.
Я не планировал добавлять эту часть, так как статья в первую очередь посвящена конвейеру поиска, но неплохо было бы протестировать ее с LLM, чтобы увидеть, сможет ли он интерпретировать информацию во что-то связное.
При использовании более крупной модели LLM можно ожидать значительного увеличения задержки. В то же время, при использовании модели меньшего размера ответ может быть не столь интеллектуальным.
Я решил протестировать GPT-5 (с низким уровнем рассуждений), так как он очень прост в использовании, но при этом довольно медленный. Ниже вы увидите результат на примере сложного запроса пользователя: «Почему llm лагает и может ли rag помочь с этим?»
[оптимизировать запрос… извлечь… объединить… переранжировать… расширить… построить контекст…] Ответы LLM: LLM иногда «лгут», потому что они генерируют следующие вероятные слова на основе шаблонов, а не на проверенных фактах. Без опоры на источники они могут производить уверенные, но ложные утверждения, известные как галлюцинации, и их встроенные знания могут быть устаревшими или неполными [6][3]. Это рискованно в областях, требующих строгой точности (например, юриспруденция или телекоммуникационные правила), где небольшие ошибки имеют большие последствия [3]. RAG помогает, поскольку модель сначала извлекает соответствующие документы из внешнего корпуса, а затем генерирует ответы, основанные на этих доказательствах. Это уменьшает галлюцинации и приносит актуальную информацию [2][6][1]. На практике RAG, адаптированный к предметной области, значительно повысил точность; Например, конвейер RAG для регулирования радиосвязи повысил точность GPT-4o на 11,9% по сравнению с обычными подсказками и достиг точности поиска до 97%, обеспечивая более надёжные ответы [3]. Однако RAG хорош лишь настолько, насколько хорош его поиск и насколько хорошо модель использует полученный текст. Статичные, готовые ретриверы могут быть ненадёжными для сложных задач (например, многоадресных вопросов или процедурных запросов), требующих итеративного поиска или переформулировки запроса [2]. Наивный RAG также может утопить модель в длинных, зашумлённых контекстах или извлекать семантически похожие, но нерелевантные фрагменты — проблема «иголки в стоге сена», — что приводит к неверным ответам [4]. Более эффективные практики RAG решают эту проблему: настройка инструкций для RAG, обучающая фильтрации, объединению нескольких источников и специфическому для RAG рассуждению с подходом «подумай, прежде чем ответить» (HIRAG), улучшает использование доказательств [1]; адаптивный поиск с обратной связью определяет, когда и как извлекать и повторно ранжировать доказательства [2]; а конвейерные решения, оптимизирующие разделение на фрагменты и поиск, повышают точность ответов [4]. Если галлюцинации всё ещё сохраняются, методы, напрямую управляющие декодированием (за пределами RAG), могут ещё больше их подавить [5]. цитируемые документы: [1] doc::b0610cc6134b401db0ea68a77096e883 — HIRAG: Иерархическая мысленная инструкция-настройка поиска-расширенной генерации [2] doc::53b521e646b84289b46e648c66dde56a — Тестовая обратная связь корпуса: от поиска к RAG [3] doc::9694bd0124d0453c81ecb32dd75ab489 — Поиск-расширенная генерация для надежной интерпретации правил радиосвязи [4] doc::6d7a7d88cfc04636b20931fdf22f1e61 — KeyKnowledgeRAG (K^2RAG): Улучшенный метод RAG для улучшения возможностей ответов на вопросы LLM [5] doc::3c9a1937ecbc454b8faff4f66bdf427f — DSCC-HS: Динамическая самоподкрепляющаяся структура для подавления галлюцинаций в больших языковых моделях [6] doc::688cfbc0abdc4520a73e219ac26aff41 — Систематический обзор ключевых систем генерации дополненного поиска (RAG): прогресс, пробелы и будущие направления
Вы увидите, что он правильно цитирует источники и использует переданную ему информацию, но поскольку мы используем GPT-5, задержка при таком большом контексте довольно высокая.
Для получения первого токена с помощью GPT-5 требуется около 9 секунд (но это будет зависеть от вашей среды).
Если весь конвейер извлечения занимает около 4–5 секунд (и он не оптимизирован), это означает, что последняя часть займет примерно в 2–3 раза больше времени.
Некоторые утверждают, что нужно отправлять меньше информации в контекстное окно, чтобы уменьшить задержку для этой части, но это также противоречит цели того, что мы пытаемся сделать.
Другие будут выступать за использование цепочечных подсказок, когда один LLM меньшего уровня извлекает полезную информацию, а затем позволяет другому LLM большего уровня отвечать с оптимизированным контекстным окном, но я не уверен, сколько это сэкономит времени и стоит ли это того.
Другие будут использовать максимально компактные решения, жертвуя «интеллектом» ради скорости и стоимости. Но использование меньших размеров с окном более 2 КБ также сопряжено с риском возникновения галлюцинаций.
Тем не менее, вам решать, как оптимизировать систему. Это самая сложная часть.
Если вы хотите изучить весь конвейер по нескольким запросам, смотрите эту папку.
Давайте поговорим о задержке и стоимости
Те, кто говорит об отправке целых документов в LLM, вероятно, не занимаются безжалостной оптимизацией задержек в своих системах. Именно на это вы потратите больше всего времени: пользователи не хотят ждать.
Да, вы можете использовать некоторые UX-трюки, но разработчики могут посчитать вас ленивым, если ваш конвейер извлечения данных будет медленнее нескольких секунд.
Вот почему интересно, что мы видим этот переход к агентному поиску в реальности: гораздо медленнее добавляются большие контекстные окна, преобразования запросов на основе LLM, цепочки автоматических «маршрутизаторов», разложение подвопросов и многошаговые «агентные» механизмы запросов.
Для этой системы (построенной в основном с использованием Codex и моих инструкций) время извлечения в среде Serverless составляет около 4–5 секунд.

Это довольно медленно (но довольно дёшево).
Вы можете оптимизировать каждый шаг, чтобы снизить это число, сохраняя при этом большую часть времени. Однако, используя API, вы не всегда можете контролировать скорость ответа.
Некоторые люди будут утверждать, что вам следует размещать собственные меньшие модели для оптимизатора и маршрутизаторов, но тогда вам придется добавить расходы на хостинг, которые могут легко добавить несколько сотен долларов в месяц.
При использовании этого конвейера каждый запуск (без кэширования) обходится нам в 1,2 цента (0,0121 долл. США), так что если бы ваша организация задавала 200 вопросов каждый день, вы бы заплатили около 2,42 долл. США с GPT-5.
Если переключиться на GPT-5-mini для основного LLM, один запуск конвейера снизится до 0,41 цента и составит около 0,82 доллара в день за 200 запусков.
Что касается встраивания документов, я заплатил около 0,5 доллара за 200 PDF-файлов, используя большую модель OpenAI. Стоимость будет увеличиваться по мере масштабирования, что следует учитывать, поэтому в этом случае может быть целесообразно использовать небольшую или специализированную, доработанную модель.
Как это улучшить
Поскольку мы работаем только с последними статьями RAG, после масштабирования вы можете добавить некоторые элементы, чтобы сделать ее более надежной.
Однако следует отметить, что вы можете не заметить большинство реальных проблем, пока ваши документы не начнут расти. То, что кажется надёжным при наличии нескольких сотен документов, начнёт казаться запутанным, когда вы обработаете десятки тысяч.
Вы можете настроить оптимизатор на установку фильтров, например, с использованием семантического соответствия тем. Вы также можете настроить его на установку дат, чтобы информация оставалась актуальной, и одновременно использовать сигнал авторитетности при повторном ранжировании, который повышает позиции определённых источников.
Некоторые команды идут немного дальше и разрабатывают собственные функции оценки, чтобы решить, что должно быть отображено и как расставить приоритеты среди документов, но это полностью зависит от того, как выглядит ваш корпус.
Если вам нужно загрузить несколько тысяч документов, возможно, имеет смысл пропустить LLM во время загрузки и использовать его в конвейере поиска, где он анализирует документы только при запросе. Затем вы можете кэшировать этот результат для следующего раза.
Наконец, всегда не забывайте добавлять корректные оценки, чтобы показать качество и обоснованность поиска, особенно если вы меняете модели для оптимизации стоимости. Я постараюсь написать об этом в будущем.
Источник: towardsdatascience.com

























