
Третья и последняя часть оценки качества извлечения вашего трубопровода RAG с использованием градуированных мер
Делиться
: DCG@k и NDCG@k 1")
Обязательно ознакомьтесь с предыдущими частями:
👉 Часть 1: Precision@k, Recall@k и F1@k
👉 Часть 2: Средний обратный ранг (MRR) и средняя точность (AP)
В предыдущих частях моей серии публикаций, посвящённых показателям оценки эффективности поиска для конвейеров RAG, мы подробно рассмотрели бинарные метрики оценки поиска. В частности, в части 1 мы рассмотрели бинарные метрики оценки поиска, не учитывающие порядок, такие как HitRate@K, Recall@K, Precision@K и F1@K. Бинарные метрики оценки поиска, не учитывающие порядок, — это, по сути, самый базовый тип показателей, которые мы можем использовать для оценки эффективности нашего механизма поиска; они просто классифицируют результат как релевантный или нерелевантный и оценивают, попал ли релевантный результат в набор результатов поиска.
Затем, во второй части, мы рассмотрели бинарные метрики оценки, учитывающие порядок, такие как средний обратный ранг (MRR) и средняя точность (AP). Бинарные метрики, учитывающие порядок, классифицируют результаты как релевантные или нерелевантные и проверяют их наличие в выборке, но, помимо этого, они также количественно оценивают ранжирование результатов. Другими словами, они учитывают и ранжирование, с которым каждый результат был получен, помимо того, был ли он получен изначально.
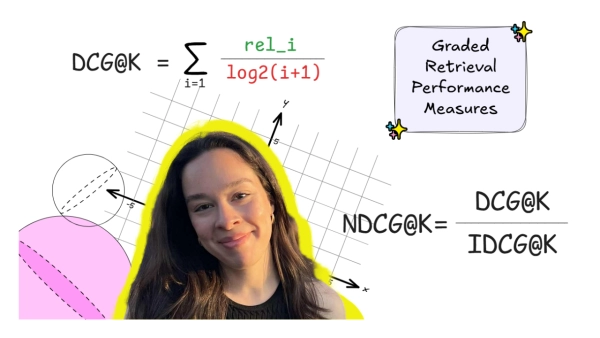
В этой заключительной части серии публикаций, посвящённой метрикам оценки поиска, я более подробно расскажу о другой обширной категории метрик, выходящей за рамки бинарных. Это градуированные метрики . В отличие от бинарных метрик, где результаты либо релевантны, либо нерелевантны, для градуированных метрик релевантность представляет собой спектр. Таким образом, извлечённый фрагмент может быть более или менее релевантным запросу пользователя.
Две часто используемые градуированные метрики релевантности, которые мы рассмотрим в сегодняшнем посте, — это дисконтированный кумулятивный прирост (DCG@K) и нормализованный дисконтированный кумулятивный прирост (NDCG@k).
Источник: towardsdatascience.com

























