
Почему важно качество извлечения вашего конвейера RAG и какие показатели использовать для его оценки
Делиться

В предыдущих публикациях я рассказал вам о создании простейшего конвейера RAG на Python, а также о том, как разбить большие текстовые документы на фрагменты. Мы также рассмотрели, как документы преобразуются в вложения, что позволяет быстро искать похожие документы в векторной базе данных, и как используется переранжирование для определения наиболее подходящих документов, отвечающих запросу пользователя.
Итак, после того как мы извлекли релевантные документы, пора передать их в LLM для этапа генерации. Но перед этим важно убедиться, что механизм извлечения работает корректно и способен успешно идентифицировать релевантные результаты. Ведь извлечение фрагментов, содержащих ответ на запрос пользователя, — это самый первый шаг к созданию осмысленного ответа.
Именно это мы и рассмотрим в сегодняшней статье. В частности, мы рассмотрим некоторые из самых популярных метрик для оценки эффективности поиска и реранжирования.
🍨 DataCream — это новостная рассылка с историями и обучающими материалами по искусственному интеллекту, данным и технологиям. Если вам интересны эти темы, подпишитесь здесь.
. . .
Зачем нужно измерять эффективность поиска?
Итак, наша цель — оценить, насколько хорошо наша модель встраивания и векторная база данных возвращают фрагменты текста-кандидатов. По сути, мы пытаемся выяснить: «Есть ли нужные документы где-то в топ-k найденных данных?», или наш векторный поиск возвращает полный мусор? 🙃 Для ответа на этот вопрос можно использовать несколько различных показателей. Большинство из них взяты из области информационного поиска.
Прежде чем начать, полезно различать два типа мер релевантности: бинарные и градуированные . Более конкретно, бинарные меры характеризуют извлеченный фрагмент текста как релевантный или нерелевантный для ответа на запрос пользователя — промежуточного значения не существует. Градуированные же меры, напротив, присваивают каждому извлеченному фрагменту текста значение релевантности, варьирующееся от полной нерелевантности до полной релевантности.
В целом, бинарные меры характеризуют каждый фрагмент как релевантный или нерелевантный, попадание или промах, положительный или отрицательный. В результате при рассмотрении бинарных мер поиска мы можем столкнуться с одной из следующих ситуаций:
- Истинно положительный ➔ Результат извлечен из первых k и действительно соответствует запросу пользователя; он извлечен правильно.
- Ложный положительный результат ➔ Результат извлечен из первых k, но на самом деле он нерелевантный; он извлечен ошибочно.
- Верно Отрицательно ➔ Результат не извлечен из первых k и действительно не соответствует запросу пользователя; он действительно не извлечен.
- Ложный отрицательный результат ➔ Результат не извлечен из первых k, но на самом деле он был релевантным; он ошибочно не извлечен.

Как вы можете себе представить, мы ищем именно истинные ситуации — истинно положительные и истинно отрицательные. С другой стороны, ложные ситуации — ложноотрицательные и ложноположительные — мы пытаемся минимизировать, но это довольно противоречивая цель. Более конкретно, чтобы включить все существующие релевантные результаты (то есть минимизировать ложноотрицательные), нам нужно сделать поиск более инклюзивным, но, делая поиск более инклюзивным, мы также рискуем увеличить количество ложноположительных.
Другое различие, которое мы можем провести, — это меры релевантности, учитывающие и не учитывающие порядок. Как следует из их названий, меры релевантности, учитывающие порядок, отражают только наличие релевантного результата в первых k извлеченных текстовых фрагментах. С другой стороны, меры, учитывающие порядок, также учитывают рейтинг, в котором появляется текстовый фрагмент, помимо того, появляется ли он только в первых k фрагментах.
Все показатели оценки поиска можно рассчитать для различных значений k, поэтому мы обозначаем их как «некая мера» @k, например, HitRate@k или Precision@k (ну и ну!). В любом случае, в оставшейся части этой статьи я рассмотрю некоторые базовые бинарные метрики оценки поиска, не учитывающие порядок.
. . .
Некоторые бинарные меры, не учитывающие порядок
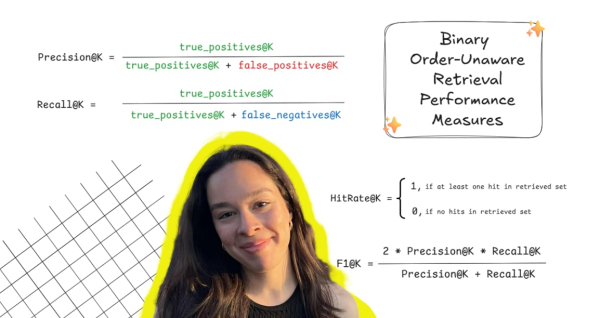
Бинарные меры, не учитывающие порядок, для оценки поиска являются наиболее простыми и интуитивно понятными. Таким образом, они служат отличной отправной точкой для понимания того, что именно мы пытаемся измерить и оценить. Некоторые распространённые и полезные бинарные меры, не учитывающие порядок, — это HitRate@k, Recall@k , Precision@k и F1@k . Давайте рассмотрим их более подробно.
🎯 HitRate@K
HitRate@K — простейший показатель для оценки качества поиска. Это двоичный показатель, показывающий, есть ли хотя бы один релевантный результат в первых k извлеченных фрагментах. Таким образом, он может принимать только два значения: 1 (если в извлеченном наборе есть хотя бы один релевантный документ), либо 0 (если ни один из извлеченных документов на самом деле не является релевантным). Это, по сути, самый базовый показатель успеха, который только можно себе представить — по крайней мере, попадание в цель. Для одного запроса и соответствующего извлеченного набора результатов HitRate@k можно рассчитать следующим образом:

Таким образом, мы можем рассчитать различные показатели попадания для всех запросов и полученных результатов в тестовом наборе и, наконец, рассчитать средний показатель HitRate@K всего тестового набора.

Вероятно, показатель попаданий является самым простым, понятным и легким для расчета показателем извлечения; таким образом, он служит хорошей отправной точкой для оценки этапа извлечения нашего конвейера RAG.
🎯 Recall@K
Recall@K показывает, насколько часто релевантные документы встречаются в первых k найденных документах. По сути, он оценивает, насколько хорошо нам удалось избежать ложноотрицательных результатов. Recall@k рассчитывается следующим образом:

Таким образом, он может принимать значения от 0 до 1, где 0 означает, что получены только нерелевантные результаты, а 1 — что получены только релевантные результаты (без ложноотрицательных результатов). Это как спросить: «Из всех имеющихся элементов, сколько мы получили?». Это показывает, сколько из первых k результатов действительно релевантны.
Полнота фокусируется на количестве найденных результатов — сколько из всех релевантных результатов нам удалось найти? Таким образом, она хорошо подходит в качестве меры поиска в ситуациях, когда нам нужно найти как можно больше релевантных результатов, даже извлекая вместе с ними некоторые нерелевантные.
Таким образом, чем выше показатель Recall@k, тем больше релевантных документов мы извлекли с помощью векторного поиска из всех существующих релевантных документов. Напротив, извлечение документов с низким показателем Recall@k — довольно неудачное начало для этапа извлечения в нашем конвейере RAG: если нужных релевантных документов и информации изначально нет, никакое волшебное переранжирование или модель LLM не исправят ситуацию.
🎯 Точность@k
Точность@k показывает, сколько из первых k найденных документов действительно релевантны. По сути, она оценивает, насколько хорошо мы справились с исключением ложноположительных результатов. Точность@k можно рассчитать следующим образом:

Другими словами, точность — это ответ на вопрос: «Сколько из найденных элементов являются правильными?». Она показывает, сколько действительно релевантных результатов было успешно получено из первых k. В результате точность может принимать значения от 0 до 1, где 0 означает, что были получены только нерелевантные результаты, а 1 — что были получены только релевантные результаты (нерелевантные результаты не получены — нет ложноположительных результатов).
Таким образом, Precision@k в значительной степени подчёркивает валидность каждого полученного результата, а не исчерпывающе ищет каждый результат. Другими словами, Precision@k может служить эффективным средством измерения эффективности поиска в ситуациях, когда качество результатов важнее количества. То есть, он позволяет получать результаты, релевантность которых мы уверены, даже если это означает, что мы ошибочно отклоняем некоторые из них.
🎯 F1@K
Но что, если нам нужны как верные, так и полные результаты — например, если нам нужно, чтобы полученный набор данных имел высокие показатели как полноты, так и точности? Для этого можно объединить показатели полноты@K и точности@K в единый показатель F1@K, что позволит нам создать оценку, которая одновременно учитывает валидность и полноту полученных результатов. В частности, F1@k можно рассчитать следующим образом:

F1@k, опять же, может принимать значения от 0 до 1. Значение F1@k, близкое к 1, означает, что и Precision@k, и Recall@k высоки, то есть полученные результаты точны и полны. С другой стороны, значение F1@k, близкое к нулю, означает, что Recall@k или Recall@k низкий, или даже оба. Таким образом, F1@k служит эффективной единой метрикой для оценки сбалансированного поиска, поскольку он будет высоким только при высоких показателях точности и полноты.
. . .
Итак, хорош ли наш векторный поиск?
Итак, давайте посмотрим, как всё это работает на примере «Войны и мира», ещё раз ответив на мой любимый вопрос: «Кто такая Анна Павловна?». Как и в предыдущих публикациях, я снова буду использовать в качестве примера текст «Войны и мира», лицензированный как общественное достояние и легко доступный через Project Gutenberg. Наш код на данный момент выглядит так:
import torch from sentence_transformers import CrossEncoder import os from langchain.chat_models import ChatOpenAI from langchain.document_loaders import TextLoader from langchain.embeddings import OpenAIEmbeddings from langchain.vectorstores import FAISS from langchain.text_splitter import RecursiveCharacterTextSplitter from langchain.docstore.document import Document import faiss api_key = «your_api_key» #%% # инициализация LLM llm = ChatOpenAI(openai_api_key=api_key, model=»gpt-4o-mini», temperature=0.3) # инициализация модели кросс-энкодера cross_encoder = CrossEncoder('cross-encoder/ms-marco-TinyBERT-L-2', device='cuda' if torch.cuda.is_available() else 'cpu') def rerank_with_cross_encoder(query, relevant_docs): pairs = [(query, doc.page_content) for doc in relevant_docs] # пары (query, document) for cross-encoder scores = cross_encoder.predict(pairs) # оценки релевантности из модели кросс-кодировщика ranked_indices = np.argsort(scores)[::-1] # сортировка документов на основе оценки кросс-кодировщика (чем выше, тем лучше) ranked_docs = [relevant_docs[i] for i in ranked_indices] ranked_scores = [scores[i] for i in ranked_indices] return ranked_docs, ranked_scores # инициализация модели встраиваний embeddings = OpenAIEmbeddings(openai_api_key=api_key) # загрузка документов в будет использоваться для RAG text_folder = «RAG files» documents = [] for filename in os.listdir(text_folder): if filename.lower().endswith(«.txt»): file_path = os.path.join(text_folder, filename) loader = TextLoader(file_path) documents.extend(loader.load()) splitter = RecursiveCharacterTextSplitter(chunk_size=1000, chunk_overlap=100) split_docs = [] for doc in documents: chunks = splitter.split_text(doc.page_content) for chunk in chunks: split_docs.append(Document(page_content=chunk)) documents = split_docs # нормализовать вложения базы знаний import numpy as np def normalize(vectors): vectors = np.array(vectors) norms = np.linalg.norm(vectors, axis=1, keepdims=True) return vectors / norms doc_texts = [doc.page_content for doc in documents] doc_embeddings = embeddings.embed_documents(doc_texts) doc_embeddings = normalize(doc_embeddings) # индекс faiss с импортом внутреннего произведения faiss dimension = doc_embeddings.shape[1] index = faiss.IndexFlatIP(dimension) # индекс внутреннего произведения index.add(doc_embeddings) # создание базы данных векторов w FAISS vector_store = FAISS(embedding_function=embeddings, index=index, docstore=None, index_to_docstore_id=None) vector_store.docstore = {i: doc for i, doc in enumerate(documents)} def main(): print(«Добро пожаловать в Помощник RAG. Введите «exit», чтобы выйти.n») while True: user_input = input(«Вы: «).strip() if user_input.lower() == «exit»: print(«Выход…») break # встраивание + нормализация запроса query_embedding = embeddings.embed_query(user_input) query_embedding = normalize([query_embedding]) k_ = 10 # поиск по индексу FAISS D, I = index.search(query_embedding, k=k_) # получение релевантных документов relevant_docs = [vector_store.docstore[i] for i in I[0]] # переранжирование с помощью нашей функции reranked_docs, reranked_scores = rerank_with_cross_encoder(user_input, relevant_docs) # получение верхних переранжированных фрагментов retrieved_context = «nn».join([doc.page_content for doc in reranked_docs[:5]]) # получить релевантные документы relevant_docs = [vector_store.docstore[i] for i in I[0]] retrieved_context = «nn».join([doc.page_content for doc in relevant_docs]) # D содержит оценки внутреннего произведения == косинусное сходство (с нормализации) print(«nЛучшие фрагменты и их оценки косинусного сходства:n») for rank, (idx, score) in enumerate(zip(I[0], D[0]), start=1): print(f»Фрагмент {rank}:») print(f»Косинусное сходство: {score:.4f}») print(f»Содержимое:n{vector_store.docstore[idx].page_content}n{'-'*40}») # системное приглашение system_prompt = ( «Вы полезный помощник. » «Используйте ТОЛЬКО следующий контекст базы знаний для ответа пользователю. » «Если ответ отсутствует в контексте, скажите, что вы его не знаете.nn» f»Context:n{retrieved_context}» ) # сообщения для LLM messages = [ {«role»: «system», «content»: system_prompt}, {«role»: «user», «content»: user_input} ] # сформировать ответ response = llm.invoke(messages) assistant_message = response.content.strip() print(f»nAssistant: {assistant_message}n») if __name__ == «__main__»: main()
Давайте немного изменим его, чтобы рассчитать некоторые меры по извлечению.
Прежде всего, мы можем добавить следующий раздел в начало нашего скрипта, чтобы определить метрики оценки поиска, которые мы хотим рассчитать:
#%% метрики оценки поиска # Функция для нормализации текста def normalize_text(text): return » «.join(text.lower().split()) # Коэффициент попаданий @ K def hit_rate_at_k(retrieved_docs, ground_truth_texts, k): for doc in retrieved_docs[:k]: doc_norm = normalize_text(doc.page_content) if any(normalize_text(gt) in doc_norm or doc_norm in normalize_text(gt) for gt in ground_truth_texts): return True return False # Точность @ k def precision_at_k(retrieved_docs, ground_truth_texts, k): hits = 0 for doc in retrieved_docs[:k]: doc_norm = normalize_text(doc.page_content) if any(normalize_text(gt) in doc_norm или doc_norm в normalize_text(gt) для gt в ground_truth_texts): количество попаданий += 1 return количество попаданий / k # Повторный вызов @ k def recall_at_k(retrieved_docs, ground_truth_texts, k): matched = set() for i, gt в enumerate(ground_truth_texts): gt_norm = normalize_text(gt) for doc в retrieved_docs[:k]: doc_norm = normalize_text(doc.page_content) если gt_norm в doc_norm или doc_norm в gt_norm: matched.add(i) break return len(matched) / len(ground_truth_texts) если ground_truth_texts else 0 # F1 @ K def f1_at_k(precision, recall): return 2 * precision * recall / (precision + recall) if (точность + полнота) > 0 иначе 0
Чтобы рассчитать любую из этих метрик оценки, нам необходимо сначала определить набор запросов и соответствующие им действительно релевантные фрагменты. Это довольно объёмное упражнение, поэтому я продемонстрирую процесс только для одного запроса — «Кто такая Анна Павловна?» — и соответствующие релевантные фрагменты текста, которые в идеале должны быть извлечены. В любом случае, эту информацию — как для одного запроса, так и для реального набора данных — можно определить в виде словаря истинных данных , что позволит нам сопоставлять различные тестовые запросы с ожидаемыми релевантными фрагментами текста.
В частности, мы можем считать, что релевантными фрагментами, которые следует включить в словарь основных данных для нашего запроса «Кто такая Анна Павловна?», являются следующие:
- «Дело было в июле 1805 года, и говорила известная Анна Павловна Шерер, фрейлина и фаворитка императрицы Марии Федоровны. Этими словами она приветствовала князя Василия Курагина, человека знатного и важного, который первым прибыл к ней на приём. Анна Павловна уже несколько дней кашляла. Она, как она выразилась, страдала гриппом; грипп был тогда новым словом в Петербурге, употребляемым только элитой. Все её приглашения без исключения, написанные по-французски и доставленные утром лакеем в алой ливрее, гласили следующее: «Если вам нечего делать получше, граф (или князь), и если перспектива провести вечер с бедной больной не слишком ужасна, я буду очень рада видеть вас сегодня вечером между 7 и 10 часами — Аннет Шерер».
- «Домашний вечер Анны Павловны был похож на предыдущий, только новинкой, которую она предложила гостям, на этот раз был не Мортемар, а дипломат, только что приехавший из Берлина, с самыми последними подробностями о визите императора Александра в Потсдам и о том, как два августейших друга заключили нерушимый союз, чтобы отстаивать дело справедливости против врага рода человеческого. Анна Павловна приняла Пьера с оттенком грусти, очевидно, связанной с недавней утратой молодого человека – смертью графа Безухова (все постоянно считали своим долгом уверить Пьера, что он глубоко огорчен смертью отца, которого почти не знал), и грусть её была совершенно такой же, как губернская грусть, которую она выказывала при упоминании её августейшего величества императрицы Марии Фёдоровны. Пьер был польщён этим. Анна Павловна расставила различные группы в своей гостиной вместе со своими Привычный навык. Большая группа, в которой были…
- «гостиную с её обычным искусством. Большая группа, в которой находились князь Василий и генералы, пользовалась преимуществом дипломата. Другая группа сидела за чайным столом. Пьер хотел присоединиться к первой, но Анна Павловна, находившаяся в возбуждённом состоянии полководца на поле боя, которому в голову приходят тысячи новых и блестящих идей, которые едва успевают воплотить в жизнь, увидев Пьера, тронула его пальцем за рукав, сказав:»
Таким образом, мы можем определить основную истину для этого запроса и соответствующие фрагменты, содержащие информацию, которая может дать ответ на вопрос, следующим образом:
query = «Кто такая Анна Павловна?» ground_truth_texts = [ «Дело было в июле 1805 года, и говорила известная Анна Павловна Шерер, фрейлина и фаворитка императрицы Марии Федоровны. Этими словами она приветствовала князя Василия Курагина, человека высокого и важного, который первым прибыл к ней на приём. Анна Павловна уже несколько дней кашляла. Она, как она сказала, страдала гриппом; грипп был тогда новым словом в Петербурге, употребляемым только элитой. Все её приглашения без исключения, написанные по-французски и доставленные лакеем в алой ливрее в то утро, гласили следующее: «Если вам нечего делать получше, граф (или князь), и если перспектива провести вечер с бедной больной не слишком ужасна, я буду очень рада видеть вас сегодня вечером между 7 и 10 часами — Аннет Шерер».», «Анна «Домашний» вечер Павловны был похож на предыдущий, только новинкой, которую она предложила гостям, на этот раз был не Мортемар, а дипломат, только что приехавший из Берлина, с самыми свежими подробностями о визите императора Александра в Потсдам и о том, как два августейших друга заключили нерушимый союз, чтобы отстаивать дело справедливости против врага рода человеческого. Анна Павловна приняла Пьера с оттенком грусти, очевидно, связанной с недавней утратой молодого человека – смертью графа Безухова (все постоянно считали своим долгом уверить Пьера, что он глубоко опечален смертью отца, которого почти не знал), и грусть её была совершенно такой же, как губернская грусть, которую она испытывала при упоминании её августейшего величества императрицы Марии Фёдоровны. Пьер был польщён этим. Анна Павловна с присущим ей мастерством расставила группы в своей гостиной. Большой Группа, в которой находились», «гостиная с её обычным искусством. Большая группа, в которой находились князь Василий и генералы, пользовалась преимуществом дипломата. Другая группа сидела за чайным столом. Пьер хотел присоединиться к первой, но Анна Павловна, находившаяся в возбуждённом состоянии полководца на поле боя, которому в голову приходят тысячи новых и блестящих идей, которые едва успевают привести в действие, увидев Пьера, тронула его пальцем за рукав, сказав:
Наконец, мы также можем добавить следующий раздел в нашу функцию main() для правильного расчета и отображения показателей оценки:
… k_ = 10 # поиск по индексу FAISS D, I = index.search(query_embedding, k=k_) # получение релевантных документов relevant_docs = [vector_store.docstore[i] for i in I[0]] # переранжирование с помощью нашей функции reranked_docs, reranked_scores = rerank_with_cross_encoder(user_input, relevant_docs) # — НОВЫЙ РАЗДЕЛ — # Оценка переранжированных документов с использованием метрик top_k_docs = reranked_docs[:k_] # или изменение `k` по мере необходимости precision = precision_at_k(top_k_docs, ground_truth_texts, k=k_) recall = recall_at_k(top_k_docs, ground_truth_texts, k=k_) f1 = f1_at_k(precision, recall) hit = hit_rate_at_k(top_k_docs, ground_truth_texts, k=k_) print(«n— Показатели оценки поиска —«) print(f»Hit@6: {hit}») print(f»Precision@6: {precision:.2f}») print(f»Recall@6: {recall:.2f}») print(f»F1@6: {f1:.2f}») print(«-» * 40) # — НОВЫЙ РАЗДЕЛ — # получить верхние переоцененные фрагменты retrieved_context = «nn».join([doc.page_content for doc in reranked_docs[:2]]) …
Обратите внимание, что мы запускаем оценку после переранжирования . Поскольку вычисляемые нами метрики, такие как Precision@K, Recall@K и F1@K, не зависят от порядка, их оценка на первых k извлеченных фрагментах до или после переранжирования даёт одинаковые результаты, при условии, что набор первых k элементов остаётся прежним.
Итак, на наш вопрос «Кто такая Анна Павловна?» и @k = 10 мы получаем следующие баллы:

Но что это значит?
- @k = 10, что означает, что мы рассчитываем все метрики оценки для 10 верхних извлеченных фрагментов.
- Hit@10 = True, что означает, что по крайней мере один из правильных (истинных) фрагментов был найден среди 10 первых извлеченных фрагментов.
- Точность при 10 = 0,20, что означает, что из 10 извлеченных фрагментов только 2 были верными (0,20 = 2/10). Другими словами, ретривер также выдал нерелевантную информацию; только 20% из того, что он извлек, было действительно полезным.
- Recall@10 = 0,67, что означает, что мы извлекли 67% всех релевантных фрагментов, доступных в исходных данных из 10 лучших документов.
- F1@10 = 0,31, что отражает общее качество поиска, сочетающее как точность, так и полноту. Значение F1 0,31 указывает на среднюю эффективность, и мы знаем, что это обусловлено хорошей полнотой, но низкой точностью.
Как упоминалось ранее, мы можем рассчитать эти метрики для любого значения k — имеет смысл проводить расчёт только для значений k, превышающих количество фрагментов на запрос в исходных данных. Таким образом, мы можем экспериментировать с различными значениями k и понимать, как работает наша система поиска при расширении или сужении области извлекаемых результатов.
У меня на уме
Хотя такие метрики, как Precision@K, Recall@K и F1@K, могут быть вычислены для один запрос и соответствующий ему набор извлеченных фрагментов (как мы (как было сделано здесь), в реальной оценке они обычно оцениваются по набору запросов, называемому тестовым набором. Точнее, каждый запрос в тестовом наборе связан со своим собственным набором релевантных фрагментов данных. Затем мы рассчитываем метрики поиска индивидуально для каждого запроса, а затем усредняем результаты по всем запросам.
В конечном счёте, понимание значения различных метрик поиска, которые можно рассчитать, крайне важно для эффективной оценки и настройки конвейера RAG. И, что ещё важнее, эффективный механизм поиска — поиск подходящих документов — является основой для получения содержательных ответов с помощью RAG.
. . .
Понравился этот пост? Давайте дружить! Присоединяйтесь ко мне:
📰 Substack 💌 Medium 💼 LinkedIn ☕ Купите мне кофе!
. . .
А как насчет пиалгоритмов?
Хотите использовать возможности RAG в своей организации?
pialgorithms может сделать это для вас 👉 закажите демонстрацию сегодня
Источник: towardsdatascience.com

























