
Подробное изучение того, как именно текстовые языковые модели настраиваются для *распознавания* изображений.
Делиться

Недавно я отправился в увлекательное путешествие, чтобы преобразовать небольшую текстовую языковую модель и наделить её возможностями машинного зрения. Эта статья призвана обобщить все полученные знания и более подробно рассмотреть сетевые архитектуры, лежащие в основе современных языковых моделей машинного зрения.
Код является открытым, ссылку на GitHub вы можете найти в конце статьи. Также есть 30-минутное видео на YouTube, которое наглядно и наглядно объясняет всю статью.
Кроме того, если не указано иное, все изображения в этой статье созданы автором.
Подождите, вы действительно собираетесь «тренироваться с нуля»?
Да… то есть нет… здесь есть некоторые нюансы.
В 2026 году исследовательские лаборатории больше не будут обучать мультимодальные модели «с нуля». Обучение модели одновременно распознаванию визуальной информации и (текстового) языка стало слишком дорогим! Это требует больше данных, вычислительных мощностей, времени и денег. Кроме того, это часто приводит к худшим результатам.
Вместо этого лаборатории берут существующие предварительно обученные языковые модели, работающие только с текстом, и дорабатывают их, чтобы получить «возможности компьютерного зрения». В теории (и на практике) это гораздо более эффективно с точки зрения вычислительных ресурсов.

Стандартная архитектура
Хотя это и менее ресурсоемкий процесс, тонкая настройка языковых моделей, работающих только с текстом, для внезапного появления изображений, безусловно, создаст свои собственные проблемы.
- Как нам встроить изображение, то есть преобразовать его в числовые представления, понятные нейронной сети?
- Как настроить векторные представления изображений, чтобы они были совместимы с текстом ?
- Как нам скорректировать веса текстовой модели таким образом, чтобы она сохраняла свои предыдущие знания об окружающем мире, но при этом генерировала текст из векторных представлений изображений ?

Эти модули:
- Image Backbone: модель, которая преобразует необработанные изображения в векторные представления (эмбеддинги).
- Адаптерный слой: это модели, которые преобразуют векторные представления изображений в «текстосовместимые» векторные представления. Это основная сложная часть — какие архитектуры использовать, какие функции потерь и т. д.
- Языковой слой: языковая модель, которую мы будем обучать для ввода адаптированных эмбеддингов и генерации текста на их основе.
Давайте обсудим их по очереди.
1. Основа изображения
Цель вашей системы формирования изображений проста:
Входные данные: Необработанная двумерная пиксельная карта/изображение.
Результат: Последовательность векторных представлений, иллюстрирующих изображение.
Как правило, мы используем готовую модель обработки изображений, предварительно обученную на большом корпусе изображений, обычно в задачах самообучения.
В качестве основы для обработки изображений можно использовать сверточную нейронную сеть (например, ResNet). Однако современные передовые VLM-системы почти полностью перешли на ViT-системы, поскольку они лучше масштабируются по мере обработки данных и более гибки для мультимодального слияния.

Мне нужно обучать базовую модель обработки изображений или оставить её в неизменном виде?
В большинстве исследований в области VLM наблюдается явная тенденция к сохранению базовых моделей в статичном (замороженном) состоянии для экономии средств. Кроме того, для обучения моделей обработки изображений и текста обычно требуются парные наборы данных «изображение — текст». Поскольку эти наборы данных всегда намного меньше, чем набор данных для предварительного обучения VIT, тонкая настройка базовой модели часто приводит к переобучению и ухудшению производительности.
Сохраняя эти веса неизменными, мы, по сути, передаем управление процессом обучения визуально-языковым представлениям последующим частям сети (т. е. адаптерному слою и текстовой архитектуре).
В своих экспериментах я использовал модель ViT-Base. Эта модель принимает на вход изображение, разбивает его на фрагменты размером 16×16 пикселей и применяет к ним механизм самовнимания для генерации последовательности встраивания из 197 векторов. Каждый вектор имеет длину 768 измерений (размер встраивания VIT).
2. Адаптерный слой
Здесь мы и проведём большую часть времени. Мы уже преобразовали изображения в векторные представления, но эти представления совершенно не учитывают текст.
Модели Vision Transformers предварительно обучаются исключительно на пикселях изображений, а не на их подписях или каких-либо локальных текстовых признаках. Роль адаптера заключается в преобразовании пиксельных векторных представлений изображений в (часто более короткую последовательность) текстовые векторные представления изображений.
Существует множество способов сделать это, например, используя модели CLIP, но мы рассмотрим один из наиболее популярных подходов — Query Former из Q-Former.
Q-Формер
Итак, что же такое Q-формер? Q-формер, или формер запросов, был представлен в статье BLIP-2.

Как обучить Q-Former?
Стандартные Q-Former можно обучать, используя любой набор данных, содержащий мультимодальные пары изображение-текст. Например, можно использовать набор данных Conceptual Captions, представляющий собой огромный корпус изображений и соответствующих им подписей. В моем проекте для обучения Q-Former я использовал всего 50 000 пар.
Можно обучить Q-Former с нуля, но в BLIP-2 рекомендуется использовать предварительно обученную модель BERT. Поэтому мы так и поступим.
В общих чертах, вот наш основной план действий:
- Обучите многомодальное объединенное пространство встраивания. Пространство, где текст и изображения «знают» друг друга.
- По сути, мы будем вводить пары изображений и подписей — и встраивать их оба в одно и то же общее пространство.
- Изображения и несовместимые подписи будут отображаться в разных местах в этом новом пространстве встраивания, а совместимые подписи будут отображаться близко друг к другу.


Настройка слоев перекрестного внимания
Проблема в том, что модели BERT — это чисто текстовые модели. Они понятия не имеют, что такое изображение.
Итак, наша цель — сначала ввести новые слои перекрестного внимания, чтобы объединить векторные представления изображений, полученные из VIT, и векторные представления текста из BERT. Давайте пошагово разберем, как мы преобразуем BERT в Q-Former:
- Выберите пару «изображение — текст» из набора данных.
- Пропустите изображение через замороженную модель VIT, чтобы преобразовать изображение в векторные представления изображений, имеющие форму [197, 768]
- Инициализируем «обучаемые векторные представления запросов». Это (например, 32) векторные представления, которые мы будем использовать для преобразования последовательности векторных представлений изображения в последовательность векторных представлений токенов, привязанных к тексту. Обратите внимание, что 32 значительно меньше исходной длины последовательности векторных представлений VIT (197).
- В первый слой BERT мы подаем на вход векторные представления текстовых подписей и векторные представления запросов. Этот слой применяет механизм самовнимания к этим входным данным.
Пока предположим, что токены запроса взаимодействуют только между собой, а текстовые токены — только между собой (то есть токены запроса и текстовые токены не видят друг друга).
- На втором слое BERT происходит нечто ИНТЕРЕСНОЕ. Два набора эмбеддингов проходят через еще один слой самовнимания, как и раньше. Но на этот раз мы также используем слой перекрестного внимания для контекстуализации эмбеддингов запроса с эмбеддингами изображений ViT, которые мы рассчитали ранее.
Разумеется, в стандартном BERT отсутствуют слои перекрестного внимания, поэтому мы сами вводим эти многоголовые слои перекрестного внимания.
- Таким же образом мы чередуем слой чистого самовнимания (где запросы и текст независимо друг от друга взаимодействуют) со слоем перекрестного внимания (где векторные представления запросов взаимодействуют с зафиксированными векторными представлениями VIT).
- На заключительном слое мы выбираем функцию потерь для совместного обучения с использованием векторных представлений, например, ITC (Image Text Contrastive Loss), ITM (Image Text Matching Loss) или ITG (Image Text Generation Loss и т. д.). Подробнее об этом позже.
Что делает механизм перекрестного внимания?
Это позволяет сопоставить содержимое изображения с векторными представлениями запроса. Можно представить, что каждый запрос пытается сопоставить определенный шаблон векторного представления с 197 векторными представлениями VIT.
Например, если запрос имеет высокое соответствие с одним векторным изображением, он будет очень четко отображать именно этот признак. Если запрос соответствует комбинации векторов, он будет представлять собой среднее значение этих векторных представлений, и так далее.
Помните, что мы обучили 32 таких векторных представления запроса, поэтому вы позволяете Q-Former изучать множество различных коактиваций внутри векторных представлений изображений. В силу особенностей обучения, эти коактивации поощряются для максимального выравнивания изображения и текста.
В процессе обучения Q-Former будут оптимизированы как начальные векторные представления запросов, так и веса перекрестного внимания, чтобы мы могли извлекать релевантные признаки из токенов изображений VIT.
Исходные эмбеддинги запроса не пытаются уловить каждую деталь этих 197 эмбеддингов — вместо этого они пытаются научиться объединять их в компактную последовательность из 32 токенов.
Обратите внимание, что после обучения Q-Former мы фактически не будем использовать текстовую часть Q-Former ни для чего. Мы просто будем пропускать векторные представления запросов через Q-Former и, по желанию, применять к ним только механизмы самовнимания и перекрестного внимания.
Функции потерь для обучения Q-формеров
Можно сделать ТАК МНОГО КРУТЫХ вещей, просто настроив маску внимания разными способами.
Итак, icydk, я буду обучать небольшую языковую модель, работающую только с текстом, чтобы она обладала возможностями компьютерного зрения. В качестве предварительного этапа обучения мне сначала нужно обучить объединенное пространство встраивания изображений и текста, которое будет использоваться позже… https://t.co/Dxf2Q2hhBG pic.twitter.com/EFmWsWRbgA
— AVB (@neural_avb) 16 декабря 2025 г.
Способ обучения модели Q-Former тесно связан с тем, как мы различаем токены запроса и текста на протяжении всех слоев.
- Функция контрастной потери изображения-текста (наша настройка)
Для решения этой задачи мы используем одномодальную маску самовнимания . Запросные токены взаимодействуют друг с другом, текстовые токены — друг с другом.Функция потерь может быть любой стандартной контрастной функцией потерь, подобной CLIP. Мы будем выравнивать изображение и текст в одном и том же пространстве встраивания. По сути, мы берем выходные данные запросов и выходные данные кодировщика текста и вычисляем их сходство. Если изображение и подпись принадлежат друг другу, мы хотим, чтобы их векторы были как можно ближе друг к другу.
Это заставляет запросы извлекать «глобальное» визуальное представление, соответствующее общей тематике текста, без фактического просмотра самих слов.
- Функция потерь при сопоставлении изображения и текста (ITM)
Здесь используется двунаправленная маска самовнимания . В этом случае каждый токен запроса может видеть каждый текстовый токен, а каждый текстовый токен может видеть каждый запрос!В качестве функции потерь мы используем задачу бинарной классификации, где модель должна предсказать: «Соответствуют ли это изображение и этот текст — Да или Нет?». Бинарная кросс-энтропийная функция потерь.
Поскольку модальности полностью смешаны, модель может выполнять детальные сравнения. Запросы могут анализировать конкретные объекты на изображении (с помощью механизма перекрестного внимания) и проверять, соответствуют ли они конкретным словам в тексте. Это гораздо детальнее, чем контрастная функция потерь, и гарантирует, что 32 токена улавливают локализованные детали.
- Функция потерь при генерации изображения и текста (ITG)
Наконец, у нас есть задача генерации. Для этого мы используем многомодальную причинно-следственную маску . Запросы по-прежнему могут видеть друг друга, но текстовые токены теперь рассматриваются как последовательность. Каждый текстовый токен может видеть все 32 токена запроса, которые выступают в качестве визуального префикса. Но они могут видеть только те текстовые токены, которые были до него.В качестве функции потерь мы просто обучаем модель предсказывать следующий токен в подписи. Заставляя модель буквально «писать» описание на основе запросов, мы гарантируем, что эти 32 токена содержат всю необходимую визуальную информацию для понимания сцены языковой моделью.
Для своего проекта я использовал самый простой метод — ITC. Для небольшого набора данных, который я использовал, это был самый простой способ! BLIP-2 рекомендует использовать сочетание всех этих методов обучения. В репозитории GitHub, ссылка на который приведена в конце статьи, есть инструкция по использованию любой из вышеперечисленных схем внимания.

В следующем разделе мы перейдем к заключительному этапу — обучению VLM!
3. Языковой слой
Теперь переходим к заключительному шагу. Мы будем использовать VIT и Q-Former для преобразования языковой модели в модель компьютерного зрения. Я выбрал одну из самых маленьких языковых моделей, оптимизированных под конкретные инструкции — SmolLM2-135M. К счастью, эта часть не так сложна, как обучение Q-Former.
У нас есть векторные представления изображений (полученные из VIT и Q-Former), а также текстовые токены (полученные из токенизатора SmolLM). Давайте рассмотрим некоторые детали.

- Мы выбираем изображение и подпись из нашего набора данных.
- Мы случайным образом выбираем из списка простых системных подсказок, например: «Вы полезный помощник. Отвечайте пользователю честно».
Мы также выбираем пользовательский запрос из списка подсказок, например: «Что вы видите на этом изображении?»
Мы также токенизируем выходные подписи, отобранные из набора данных.
Эти три элемента образуют текстовые токены. Мы токенизируем их все с помощью токенизатора SmolLM2, но пока не будем вставлять его в LLM — сначала нужно обработать изображение.
- Мы пропускаем изображение через замороженный VIT, затем через Q-Former (опять же, обратите внимание, что текстовые подписи не передаются в Q-Former, выполняется только конвейер обработки изображений).
- Мы вводим небольшой слой MLP, который преобразует выходные данные Q-Former в новые эмбеддинги, имеющие ту же форму, что и ожидаемый размер эмбеддинга LLM. В процессе обучения этот слой MLP будет отображать эмбеддинг Q-Former в пространство эмбеддингов LLM.
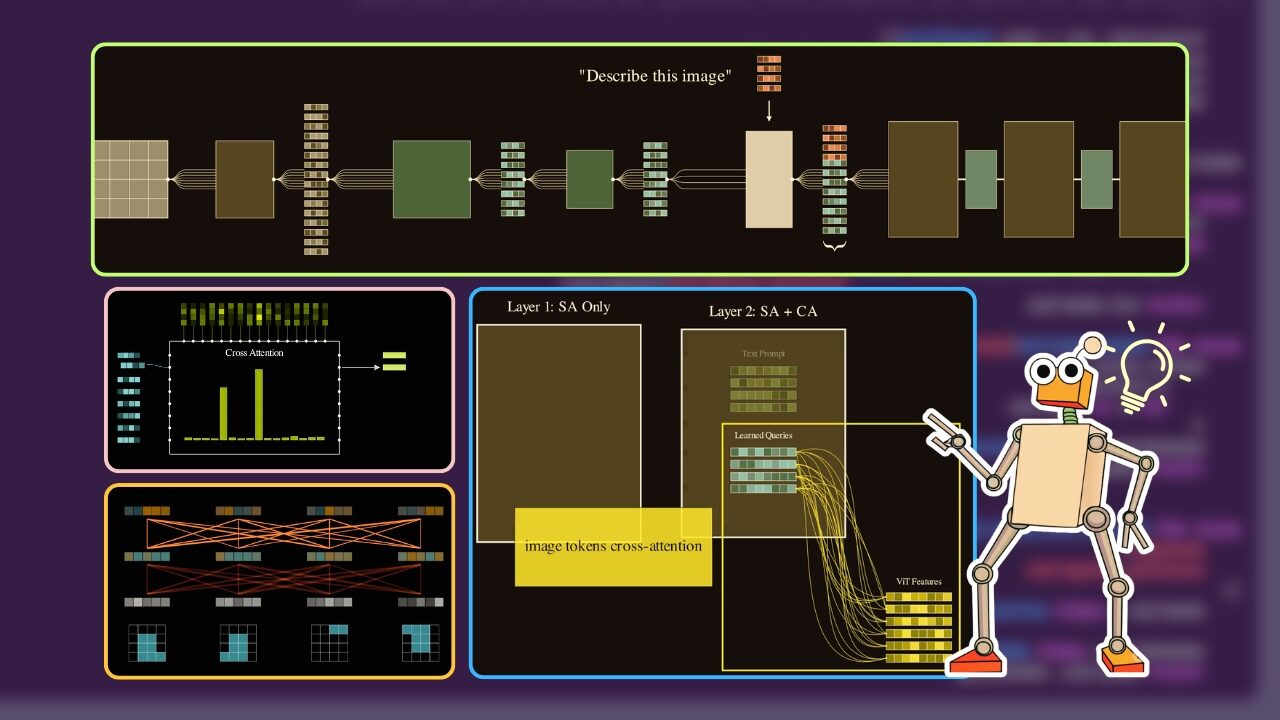
- Теперь, когда у нас есть последовательность текстовых токенов и новые векторные представления изображений (VIT -> Q-Former -> MLP), мы передадим текстовые токены через собственный слой векторного представления LLM. Мы расположим векторные представления текста и изображений в следующей последовательности:
- Почему именно эта последовательность? Поскольку авторегрессивные LLM используют причинное маскирование, мы, по сути, будем обучать модели генерировать выходную последовательность (подпись), имея весь префикс (системную подсказку, пользовательскую подсказку и векторные представления изображений).
- Вместо обучения всей модели LLM с нуля мы добавляем адаптеры LoRA (матрицы адаптации низкого ранга). Обернув нашу модель LLM матрицами LoRA, мы замораживаем исходные миллионы параметров и обучаем только крошечные матрицы низкого ранга, внедряемые в слои внимания. Это позволяет обучать модель на потребительском оборудовании, сохраняя при этом все существующие интеллектуальные возможности.
- Вот и всё! Мы передаём эти сшитые эмбеддинги и метки в LLM. Модель одновременно обрабатывает текстовые инструкции и визуальные токены, и благодаря LoRA она учится обновлять свою внутреннюю структуру, чтобы понимать этот новый визуальный язык. Обучаются только слои Q-Former, слой MLP и адаптеры LORA. Всё остальное остаётся неизменным.

После обучения всего за несколько часов на небольшом подмножестве данных, обученная модель VLM теперь может распознавать изображения и генерировать текст о них. Машинное обучение — это нечто невероятное, когда оно работает.
В итоге
Полный репозиторий на GitHub можно найти здесь:
https://github.com/avbiswas/vlm
А посмотреть видео на YouTube можно здесь:
Давайте подведем итоги работы всех модулей конвейеров обработки изображений на языке Vision Language.
- Компьютерная архитектура (подобная VIT), которая принимает на вход изображение и преобразует его в эмбеддинги.
- Адаптерный слой (подобный Q-Former), который связывает изображение с текстом.
- Мы обучаем LLM для объединения векторных представлений текста и изображений с целью изучения языка зрения.
Мой Patreon:
https://www.patreon.com/NeuralBreakdownwithAVB
Мой канал на YouTube:
https://www.youtube.com/@avb_fj
Подписывайтесь на меня в Твиттере:
https://x.com/neural_avb
Я создаю Paper Breakdown, платформу для изучения научных работ.
https://paperbreakdown.com
Читайте мои статьи:
https://towardsdatascience.com/author/neural-avb/
Авишек Бисвас Посмотреть все в Авишек Бисвас
Источник: towardsdatascience.com





















