
Визуальный тур и руководство «с нуля» по обучению моделей рассуждений GRPO в PyTorch
Делиться

Модели рассуждений сейчас в моде. DeepSeek-R1, Gemini-2.5-Pro, модели O-серии от OpenAI, Claude, Magistral и Qwen3 от Anthropic — каждый месяц появляется новая. Когда вы задаёте этим моделям вопрос, они прокручивают цепочку мыслей, прежде чем сгенерировать ответ.

Недавно я задал себе вопрос: «Хм… Интересно, стоит ли мне написать цикл обучения с подкреплением с нуля, который научит этому „мыслительному“ поведению очень маленькие модели — всего 135 миллионов параметров?». Должно быть, это просто, правда?
Ну, это не так.
У малых моделей просто нет такого же знания мира, как у больших. Это лишает модели с параметрами менее 1B «здравого смысла», необходимого для легкого решения сложных логических задач. Следовательно, нельзя полагаться только на вычисления, чтобы обучить их мышлению.
Вам нужны дополнительные козыри в рукаве.
В этой статье я не буду просто рассказывать о приёмах. Я расскажу об основных идеях, лежащих в основе обучения рассуждениям в языковых моделях, поделюсь простыми фрагментами кода и практическими советами по тонкой настройке малых языковых моделей (МЯМ) с помощью RL.
Эта статья разделена на 5 разделов:
- Введение в RLVR (обучение с подкреплением и проверяемыми вознаграждениями) и почему это суперкруто
- Визуальный обзор алгоритма GRPO и усеченных суррогатных потерь PPO.
- Пошаговое руководство по коду!
- Контролируемая тонкая настройка и практические советы по тренировке моделей рассуждения
- Результаты!
Если не указано иное, все изображения, использованные в данной статье, являются иллюстрациями автора.
В конце статьи я приведу ссылку на 50-минутное видео на YouTube, посвящённое этой статье. Если у вас есть вопросы, в этом видео, вероятно, есть ответы/разъяснения. Вы также можете связаться со мной через X (@neural_avb).
1. Обучение с подкреплением и проверяемыми вознаграждениями (RLVR)
Прежде чем углубляться в конкретные проблемы, связанные с малыми моделями, давайте сначала введем некоторые термины.
Групповая оптимизация относительной политики (GRPO) — это (довольно новый) метод обучения с подкреплением (RL), который исследователи используют для точной настройки больших языковых моделей (LLM) для решения логических и аналитических задач. С момента своего появления в исследовательской среде LLM появился новый термин: RLVR ( обучение с подкреплением и проверяемым вознаграждением ).
Чтобы понять уникальность RLVR, полезно сравнить её с наиболее распространённым применением RL в языковых моделях: RLHF ( Reinforcement Learning with Human Feedback). В RLHF модуль RL обучается максимизировать результаты, полученные с помощью отдельной модели вознаграждения, которая служит прокси — сервером для человеческих предпочтений. Эта модель вознаграждения обучается на наборе данных, в котором люди ранжируют или оценивают различные ответы модели.
Другими словами, RLHF обучается так, чтобы LLM могли выдавать ответы, более соответствующие человеческим предпочтениям. Он стремится заставить модели точнее следовать инструкциям.
RLVR пытается решить другую проблему. RLVR обучает модель проверяемой корректности, часто обучая её генерировать собственную цепочку мыслей.
В то время как в RLHF использовалась субъективная модель вознаграждения, в RLVR используется объективный верификатор. Основная идея заключается в том, чтобы предоставлять вознаграждения, основанные на доказуемой правильности ответа, а не на прогнозе предпочтений человека.

Именно поэтому эта система называется «обучение с поддающимися проверке наградами». Не на каждый вопрос можно легко проверить ответ. Особенно это касается открытых вопросов, таких как «Какой iPhone мне купить?» или «В какой колледж мне поступить?». Однако некоторые примеры использования легко вписываются в парадигму «поддающихся проверке наград», например, математика, логические задачи и написание кода. В разделе «Спортзал рассуждений» ниже мы рассмотрим, как именно можно моделировать эти задачи и как генерировать награды.
Но прежде вы можете спросить: какое место во всем этом занимает «рассуждение»?
Мы обучим модель магистра права генерировать произвольно длинные цепочки рассуждений, прежде чем сгенерировать окончательный ответ. Мы поручим модели заключать ход своих мыслей в теги
Полный ответ языковой модели будет выглядеть примерно так:
Эта структура позволяет нам легко извлечь только окончательный ответ и проверить его правильность. Проверяющий элемент — это единственный источник истины, и он может представлять собой простой фрагмент кода, который (буквально) подсчитывает буквы алфавита.
def count_alphabets(слово, буква): возвращает сумму([1 для l в слове, если l == буква]) вознаграждение = 1 если (lm_answer == count_alphabets(«клубника», «r») иначе -1
Мы будем вести учет опыта модели — её ответов и соответствующих вознаграждений, полученных от верификатора. Затем алгоритм обучения с подкреплением будет обучаться, стимулируя поведение, повышающее вероятность получения правильных окончательных ответов.
Последовательно поощряя правильные ответы и хорошее форматирование, мы увеличиваем вероятность появления маркеров рассуждения, которые приводят к правильным ответам.
Поймите: нам не нужно напрямую оценивать промежуточные токены рассуждений. Просто вознаграждая за окончательный ответ, мы косвенно включаем шаги рассуждения в цепочку рассуждений магистра права, которые приводят к правильным ответам!

2. GRPO (оптимизация групповой политики)
Я пропущу здесь обычное введение в курс обучения с подкреплением (Reinforcement Learning 101). Я ожидаю, что большинство из вас, дочитавших до этого места, понимают основы обучения с подкреплением (RL). Есть агент, который наблюдает за состоянием окружающей среды и выполняет действие — среда вознаграждает агента в зависимости от того, насколько хорошо было выполнено действие. Агент сохраняет этот опыт и обучается выполнять более эффективные действия в будущем, что приводит к более высокому вознаграждению. Занятия по курсу RL 101 закончены.
Но как перенести парадигму RL на язык?
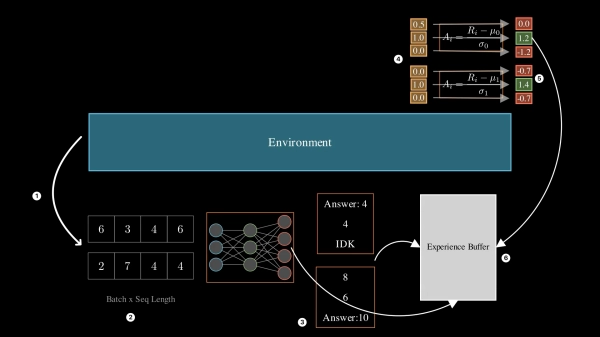
Давайте поговорим о выбранном нами алгоритме — оптимизации относительной групповой политики , чтобы понять, как он работает. GRPO работает в двух итеративно самоповторяющихся фазах: фазе сбора опыта, где языковая модель (LM) накапливает опыт в среде с текущими весами. И фазе обучения, где она использует собранные воспоминания для обновления своих весов с целью улучшения. После обучения она снова переходит к этапу сбора опыта с обновлёнными весами.
Коллекция опыта
Давайте теперь разберем каждый шаг на этапе сбора опыта.
- Шаг 1: Окружающая среда — это чёрный ящик, который генерирует вопросы, связанные с логическими или математическими задачами. Мы обсудим это в следующем разделе, посвящённом библиотеке «Гимнастика рассуждений».
- Шаг 2: Мы токенизируем входные вопросы в последовательность целочисленных токенов.

- Шаг 3: «Агент» или «политика» — это текущий обучаемый SLM. Он отслеживает токенизированные вопросы среды и генерирует ответы. Ответ LLM преобразуется в текст и возвращается в среду. Среда вознаграждает за каждый ответ.

- Шаг 4: На основе вознаграждений мы рассчитываем преимущество каждого ответа. В GRPO преимущество — это относительная ценность каждого ответа в группе. Важно отметить, что преимущества рассчитываются для каждой группы, то есть мы не стандартизируем вознаграждения для разных вопросов.

- Шаг 5: Исходный вопрос, логарифмические вероятности для каждого токена, сгенерированного LM, и преимущества накапливаются в буфере памяти.
- Шаги 1–5 повторяются до тех пор, пока размер буфера не достигнет желаемого порога.

Фаза обучения
После завершения фазы сбора опыта наша цель — перейти к фазе обучения. Здесь мы изучим закономерности вознаграждения, наблюдаемые LLM, и используем RL для улучшения его весов. Вот как это работает:
- Случайным образом выберите мини-пакет воспоминаний. Помните, что каждое воспоминание уже содержало своё преимущество относительно группы (шаг 5 из этапа сбора опыта). Случайный выбор пар «вопрос-ответ» повышает надёжность обучения, поскольку градиенты рассчитываются как среднее значение разнообразного набора воспоминаний, что предотвращает переобучение по каждому отдельному вопросу.
- Для каждого мини-пакета мы хотим максимизировать этот член, следуя стандартной формуле PPO (Proximal Policy Optimization). Главное отличие GRPO заключается в том, что нам не нужна дополнительная модель вознаграждения или сеть создания ценности для расчёта преимуществ. Вместо этого GRPO выбирает несколько ответов на один и тот же вопрос, чтобы рассчитать относительное преимущество каждого ответа. Потребляемая память значительно сокращается, поскольку нам не нужно обучать эти дополнительные модели!
- Повторите вышеуказанные шаги.

Что означает убыток PPO
Позвольте мне объяснить убыток PPO интуитивно понятно и пошагово. Убыток PPO выглядит следующим образом.

- Здесь pi_old — это нейронная сеть старой политики, которую мы использовали на этапе сбора данных.
- π — это текущая обучаемая нейронная сеть политики. Поскольку веса π меняются после каждого обновления градиента, π и π_old не остаются неизменными на этапе обучения, отсюда и различие.
- G — количество сгенерированных ответов на один вопрос. |o_i| — длина i-го ответа в группе. Таким образом, операция суммирования и нормализации вычисляет среднее значение по всем токенам по всем ответам. Что же вычисляется в результате? Это π/π_old * A_{it}. Что это значит?

- A_it — это преимущество t-го токена в i-м ответе. Помните, как мы вычисляли преимущество каждого ответа на шаге 5 во время сбора опыта? Самый простой способ назначить преимущество каждому токену — просто продублировать одно и то же преимущество для каждого токена. Это означает, что каждый токен в равной степени отвечает за генерацию правильного ответа.
- Наконец, чему равно π(o_it | q, o_i < t)? Это означает, какова вероятность появления t-го токена в i-м ответе? То есть, насколько вероятным был этот токен на момент его генерации?
- Коэффициент важности выборки переоценивает преимущества между текущей политикой обновления и старой политикой разведки.
- Ограничение гарантирует, что обновления сети не станут слишком большими, а веса не будут слишком сильно отличаться от старой политики. Это повышает стабильность процесса обучения, поддерживая обновления модели близко к «области доверия» политики сбора данных.

Когда мы максимизируем цель PPO, мы фактически просим LLM увеличить логарифмическую вероятность токенов, которые привели к высокому преимуществу, одновременно уменьшая логарифмическую вероятность токенов, которые имели низкое преимущество.
Другими словами: сделайте токены, которые генерируют хорошие преимущества, более вероятными, а токены, которые генерируют низкие преимущества, менее вероятными.
Понимание убытка PPO на примере
Давайте пока забудем об отсечении и π_old и посмотрим, что означает максимизация 𝜋(𝑜_i) * A_i. Напоминаем, что эта часть уравнения означает просто «произведение вероятности i-го токена (o_i) и преимущества i-го токена (A_i)».
Допустим, в задании LLM сгенерировал две последовательности: «AB C» и «DE F», и получил преимущество +1 для первой и -1 для второй*. Допустим, у нас есть логарифмические вероятности для каждого из трёх токенов, как показано ниже.
* на самом деле, поскольку относительные групповые преимущества всегда имеют стандартное отклонение 1, правильные преимущества должны быть +0,707 и -0,707.
Обратите внимание, что происходит, когда вы умножаете преимущества A_it на текущее значение logprobs pi. А теперь подумайте, что значит максимизировать среднее значение этой матрицы-произведения.

Помните, что мы можем изменять только вероятности, получаемые в результате LLM. Преимущества исходят из окружающей среды и поэтому рассматриваются как константы. Следовательно, увеличение этого ожидаемого значения означает увеличение вероятности появления токенов с положительным преимуществом и уменьшение ценности примера с отрицательным преимуществом.

Ниже представлен пример изменения логарифмических вероятностей после нескольких раундов обучения. Обратите внимание, как синяя линия приближается к нулю при высоком преимуществе? Это означает, что логарифмические вероятности увеличились (или вероятности увеличились) после прохождения обучения с обратным обучением. Сравните это с графиком справа, где показан другой ответ при низком преимуществе. Синяя линия удаляется от нуля, становясь менее вероятной для отбора в последующих раундах.

В следующем разделе давайте рассмотрим библиотеку «гимнастического зала рассуждений» и разберемся, как можно делать выборки задач.
3. Реализация
Итак, для обучения с подкреплением (RL) нам сначала нужны задачи. Обычно это делается с помощью существующего набора данных математических задач, например, GSM-8K. В этой статье рассмотрим другой случай — процедурную генерацию задач с помощью библиотеки Python Reasoning-Gym.
Для своих экспериментов я использовал две задачи: силлогизм и пропозициональную логику . Reasoning-gym содержит множество различных репозиториев разной степени сложности.
Задача на силлогизм — это тип логической головоломки, предназначенной для проверки дедуктивного мышления. По сути, мы предоставляем магистру права (LLM) две посылки и спрашиваем, верно ли заключение. Задача на пропозициональную логику — это задание на символическое рассуждение, где магистр права (LLM) получает задания с символами и должен сделать вывод. В отличие от силлогизма, это не классификационный ответ «ДА/НЕТ» — магистр должен сам сделать правильный вывод. Это значительно усложняет задачу.

Прежде чем приступить к кодированию, я думаю, принято уточнять, что я подразумеваю под «маленькими» моделями.
Пока ещё не решено, какую модель считать «маленькой» (некоторые говорят <14 Б, некоторые — <7 Б), но для своего видео на YouTube я выбрал ещё более мелкие модели: SmolLM-135M-Instruct, SmolLM-360M-Instruct и Qwen3-0.6B. Это модели ~135 Мб, ~360 Мб и ~600 Мб соответственно.
Давайте посмотрим, как настроить базовый цикл обучения. Для начала мы можем использовать библиотеку трансформаторов Huggingface для загрузки модели, которую хотим обучить, например, небольшой модели SmolLM-135M-Instruct со 135 млн параметров.
Например, чтобы сгенерировать некоторые задачи пропозициональной логики, вы просто вызываете функцию reasoning_gym.create_dataset, как показано ниже.
import re from reasoning_gym import create_dataset, get_score_answer_fn from transformers import AutoModelForCausalLM, AutoTokenizer import torch model_name = «HuggingfaceTB/SmolLM-135M-Instruct» # загрузить модель из huggingface lm = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.bfloat16) tokenizer = AutoTokenizer.from_pretrained(model_name) # Это делает все модели обучаемыми for param in lm.parameters(): param.requires_grad = True # В моих экспериментах я использовал адаптер LORA (подробнее об этом позже) # указать имя окружения environment_name = «propositional_logic» # На практике вам следует обернуть это в загрузчик данных torch # для выборки мини-пакета вопросов dataset = create_dataset( environment_name, seed=42, size=DATA_SIZE ) для d в наборе данных: question = d[«question»] # Доступ к вопросу # Мы воспользуемся этим позже, чтобы проверить правильность ответа validation_object = d[«metadata»][«source_dataset»] score_fn = get_score_answer_fn(validation_object)
Для генерации данных для рассуждений нам нужно, чтобы LM генерировал мышление, а затем давал ответ. Ниже приведена системная подсказка, которую мы будем использовать.
system_prompt = «»»Разговор между пользователем и помощником. Пользователь задаёт вопрос, а помощник отвечает на него. Помощник сначала обдумывает ход рассуждений, а затем предоставляет пользователю ответ. Процесс рассуждений и ответ заключены в теги
Чтобы сгенерировать ответы, мы сначала токенизируем системную подсказку и вопрос, как показано ниже.
# Создать структуру сообщений messages = [ {«role»: «system», «content»: system_prompt}, {«role»: «user», «content»: question}, # Получено из reasoning-gym ] # Создать токенизированное представление inputs = tokenizer.apply_chat_template( messages, tokenize=True, return_tensors=»pt», add_generation_prompt=True )
Затем мы передаём его через LM — генерируем несколько ответов с помощью параметра num_return_sequences и детокенизируем его обратно, чтобы получить строковый ответ. На этом этапе градиенты не рассчитываются.
generated_response = lm.generate( input_ids=inputs[«input_ids»], attention_mask=inputs[«attention_mask»], max_new_tokens=max_new_tokens, # Максимальное количество генерируемых токенов do_sample=True, # Вероятностная выборка top_p=0.95, # Ядерная выборка num_return_sequences=G, # Количество последовательностей на вопрос temperature=1, # Увеличение случайности eos_token_id=eos_token_id, pad_token_id=eos_token_id, )
Мы также пишем функцию extract_answer, которая использует регулярные выражения для извлечения ответов между тегами ответов.
def extract_answer(response): answer = re.search(r»
Наконец, мы используем полученную ранее функцию оценки для генерации вознаграждения в зависимости от правильности ответа LM. Для расчета вознаграждения мы добавляем вознаграждение за формат и вознаграждение за исправление. Вознаграждение за исправление исходит из среды, а вознаграждение за формат присуждается, если модель правильно генерирует теги
Преимущества рассчитываются путем стандартизации по каждой группе.
# Ответ — массив строк длиной [B*G] # B — количество вопросов, G — количество ответов на вопрос correctness_reward = score_fn(response, validation_object) format_reward = calculate_format_reward(response) # Общая награда — это взвешенная сумма наград за правильность и форматирование reward = correctness_reward * 0.85 + format_reward * 0.15 # Преобразуем награды из [B*G, 1] -> [B, G] rewards = rewards.reshape(B, G) # Рассчитать преимущества advantage = (rewards — np.mean(rewards, axis=1, keepdims=True)) / ( np.std(rewards, axis=1, keepdims=True) + 1e-8 ) advantage = advantage.reshape(-1, 1)
Сохраните (старый) журнал вероятностей, преимуществ, ответов и масок ответов в буфере памяти.
# Функция, возвращающая логарифм вероятности каждого выбранного токена log_probs = calculate_log_probs(lm, generated_response) buffer.extend([{ «full_response»: generated_response[i], «response_mask»: response_mask[i], # Двоичная маска для обозначения того, какие токены в сгенерированном ответе сгенерированы ИИ, 0 для системных подсказок и вопросов «old_log_probs»: log_probs[i], «advantages»: advantage[i] } for i in range(len(generated_response))])
После этапа сбора множественного опыта, когда буфер заполнен, мы запускаем цикл обучения. Здесь мы выбираем мини-пакеты из нашего опыта, вычисляем логарифм вероятности, вычисляем потери и фон.
# full_response, response_mask, old_log_probs, advantage <--- Buffer # Пересчитать новый log_probs. Обратите внимание, что torch.no_grad() отсутствует, поэтому здесь БУДУТ ИСПОЛЬЗОВАТЬСЯ градиенты. logits = llm(input_ids=full_response).logits # Извлечь log-prob из logits # Выполнить log_softmax по словарю и извлечь log-prob каждого выбранного токена log_probs = calculate_log_probs( logits, full_responses ) # Вычислить усеченные суррогатные потери reasoning_loss = calculate_ppo_loss( log_probs, # Обучаемые old_log_probs, # Получено из исследования, необучаемые advantage, # Получено из среды, необучаемые response_mask # Получено из исследования, необучаемые ) # Шаги оптимизации accelerator.backward(reasoning_loss) optimizer.step() optimizer.zero_grad()
Здесь вы можете использовать дополнительные потери энтропии или минимизировать KLD с помощью вашей эталонной модели, как предлагалось в исходной статье Deepseek-R1, но в последующих статьях сделан вывод, что это ограничивает процесс обучения и не является обязательным требованием.
4. Разогрев с контролируемой тонкой настройкой
Технически мы можем попробовать провести масштабное обучение с подкреплением прямо сейчас и надеяться, что небольшие модели справятся с поставленными задачами. Однако вероятность этого крайне мала.
Есть одна большая проблема: наши небольшие модели недостаточно обучены генерировать форматированные выходные данные и не справляются с этими задачами. Изначально их ответы имеют определённую логическую структуру благодаря предварительной подготовке или настройке инструкций, проведённой разработчиками, но для нашей целевой задачи они недостаточно хороши.

Подумайте сами: обучение с подкреплением (RL) происходит путём сбора опыта и обновления политики для максимизации положительного опыта. Но если большинство опыта совершенно отрицательные, и модель получает нулевое вознаграждение, у неё нет возможности оптимизироваться, поскольку она вообще не получает сигнала для улучшения. Поэтому рекомендуемый подход — сначала обучить модель поведению, которому вы хотите обучиться, с помощью контролируемой тонкой настройки. Вот простой скрипт:
клиент = openai.AsyncClient() СРЕДА = «propositional_logic» модель = «gpt-4.1-mini» семафор = asyncio.Semaphore(50) num_datapoints = 200 system_prompt = ( system_prompt + «»»Вам также будет предоставлен настоящий ответ. Ваши размышления должны в конечном итоге привести к получению настоящего ответа.»»» ) dataloader = create_dataset(name=ENVIRONMENT, size=num_datapoints) @backoff.on_exception(backoff.expo, openai.RateLimitError) async def generate_response(item): async with semaphore: messages = [ {«role»: «system», «content»: system_prompt}, { «role»: «user», «content»: f»»» Вопрос: {item['question']} Метаданные: {item['metadata']} Ответ: {item['answer']} «»», }, ] response = await client.chat.completions.create(messages=messages, model=model) return { «question»: item[«question»], «metadata»: item[«metadata»], «answer»: item[«answer»], «response»: response.choices[0].message.content, } async def main(): responses = await asyncio.gather(*[generate_response(item) for item in dataloader]) fname = f»responses_{ENVIRONMENT}_{model}.json» json.dump(responses, open(fname, «w»), indent=4) print(f»Saved answers to {fname}») if __name__ == «__main__»: asyncio.run(main())
Чтобы создать набор данных для тонкой настройки, я сначала сгенерировал теги «мышление» и «ответ» с помощью небольшой LLM-подобной библиотеки GPT-4.1-mini. Сделать это невероятно просто: мы выбираем около 200 примеров для каждой задачи, вызываем API OpenAI для генерации ответа и сохраняем его на диск.
В процессе SFT мы загружаем базовую модель, которую хотим обучить, подключаем обучаемый адаптер LORA и выполняем тонкую настройку параметров с эффективным подбором. Вот конфигурации LORA, которые я использовал.
lora: r: 32 lora_alpha: 64 lora_dropout: 0 target_modules: [«q_proj», «v_proj», «k_proj», «o_proj», «up_proj», «down_proj», «gate_proj»]
LORA позволяет эффективнее использовать память при обучении, а также снижает риск повреждения исходной модели. Подробности параметрически эффективной контролируемой тонкой настройки можно найти в моём видео на YouTube, которое можно посмотреть здесь.
Я обучил адаптер LORA на 200 примерах данных силлогизмов с самой маленькой языковой моделью, которую мне удалось найти — HuggingfaceTB/SmolLM-135M-Instruct, — и получил точность 46%. Грубо говоря, это означает, что мы генерируем правильный ответ в 46% случаев. Что ещё важнее, мы часто правильно форматируем ответы, поэтому наше регулярное выражение может безопасно извлекать ответы из ответов чаще, чем нет.
Еще несколько оптимизаций для SLM и практических соображений
- Не все задачи на рассуждение могут быть решены всеми моделями. Простой способ проверить, является ли задача слишком сложной или слишком лёгкой для модели, — это проверить её базовую точность . Если она, скажем, ниже 10–20%, задача, вероятно, очень сложная, и вам требуется дополнительная разминка под руководством опытного специалиста.
- SFT, даже на небольших наборах данных, обычно может демонстрировать значительный прирост точности на небольших моделях. Если вам удастся получить хороший набор данных, во многих сценариях вам, возможно, даже не понадобится обучение с подкреплением. SLM обладают невероятной гибкостью настройки.
- В таких работах, как DAPO и Critical Perspectives on R1, утверждается, что исходная нормализация потерь DeepSeek имеет смещение длины . Они предложили другие методы нормализации, которые стоит рассмотреть. В моём проекте стандартная нормализация потерь DeepSeek сработала отлично.
- DAPO также упоминает об удалении члена KLD в исходной статье R1. Изначально целью этой потери было гарантировать, что политика обновления никогда не будет слишком далека от базовой политики, но DAPO рекомендует не использовать это, поскольку поведение политики может радикально меняться в процессе рассуждений, превращая член KLD в ненужный регуляризирующий член, который ограничит интеллектуальность модели.
- Генерация разнообразных ответов — КЛЮЧЕВОЙ фактор, делающий возможным обучение с подкреплением (RL). Если вы генерировали только правильные ответы или только неправильные, преимущество будет равно 0, и это не даст алгоритму RL никакого обучающего сигнала. Мы можем генерировать разнообразные ответы, увеличивая параметры temperature, top_p и num_return_sequences в методе generate().
- Вы также можете генерировать разнообразные вознаграждения , добавляя больше членов в функцию вознаграждения. Например, вознаграждение за длину, которое наказывает за слишком длинные рассуждения.
- Следующие параметры повышают стабильность обучения за счет увеличения объема вычислений : увеличение числа поколений на развертывание, увеличение размера буфера и снижение скорости обучения.
- Если у вас ограниченные ресурсы для обучения этих моделей, используйте накопление градиента (или даже контрольные точки градиента).
- В этой статье я пропустил несколько мелких деталей, связанных с заполнением . При сохранении опыта в буфере рекомендуется полностью удалить маркеры заполнения и создать их заново при загрузке мини-пакета во время обучения.
- Лучше всего оставлять пробелы вокруг
и (и их закрывающих тегов). Это обеспечивает единообразие токенизации и немного упрощает обучение SLM.
4. Результаты
Вот мое видео на YouTube, в котором все, что я написал в этом блоге, объясняется более наглядно и дается практическое руководство по написанию кода для подобных вещей.
На SmolLM-135M с контролируемой настройкой в задаче на силлогизмы мы получили повышение до 60%! Здесь вы можете видеть кривую вознаграждения — хорошее стандартное отклонение вознаграждения показывает, что мы действительно получали разнообразные ответы на протяжении всего времени, что является положительным фактором, если мы хотим тренироваться с RL.

Вот набор гиперпараметров, которые мне хорошо подошли.
config: name: «path/to/sft_model» max_new_tokens: 300 # бюджет токенов рассуждения + ответа research_batchsize: 8 # количество вопросов в пакете во время развертывания G: 6 # количество ответов в группе temperature: 0.7 batch_size: 16 # размер мини-пакета во время обучения gradient_accumulation_steps: 12 learning_rate: 0.000001 # Рекомендуется поддерживать это значение низким, например 1e-6 или 1e-7 top_p: 0.95 buffer_size: 500
Я также повторил этот эксперимент с более крупными моделями — SmolLM-360M-Instruct и Qwen3-0.6B. В последней мне удалось добиться точности до 81%, что просто потрясающе! В среднем в задаче на силлогизмы мы получили аддитивный прирост на 20%!
В задаче на пропозициональную логику, которая, на мой взгляд, является более сложной задачей на рассуждение, я также наблюдал схожий прирост во всех небольших моделях! Уверен, что с более тщательной настройкой инструкций и подстройкой обучения с подкреплением, возможно, на нескольких задачах одновременно, мы сможем значительно повысить интеллектуальность этих моделей. Обучение на одной задаче может дать быстрые результаты, чего я и добивался в этом видео на YouTube, но оно также может стать узким местом для общего интеллекта модели.
Завершим статью GIF-изображением небольших моделей, выводящих данные для рассуждений и решающих задачи. Наслаждайтесь и будьте великолепны!

Ссылки
Канал автора на YouTube : https://www.youtube.com/@avb_fj
Patreon автора : www.patreon.com/NeuralBreakdownwithAVB
Аккаунт автора в Twitter (X) : https://x.com/neural_avb
Математика Deepseek: https://arxiv.org/pdf/2402.03300
DeepSeek R1: https://arxiv.org/abs/2501.12948
ДАПО: https://arxiv.org/abs/2503.14476
Критические взгляды на R1: https://arxiv.org/abs/2503.20783
Библиотека Reasoning Gym: github.com/open-thought/reasoning-gym
Хорошее место, где можно почитать о Reasoning: https://github.com/willccbb/verifiers
Отличное место для изучения кода: https://github.com/huggingface/trl/blob/main/trl/trainer/grpo_trainer.py
Источник: towardsdatascience.com

























