
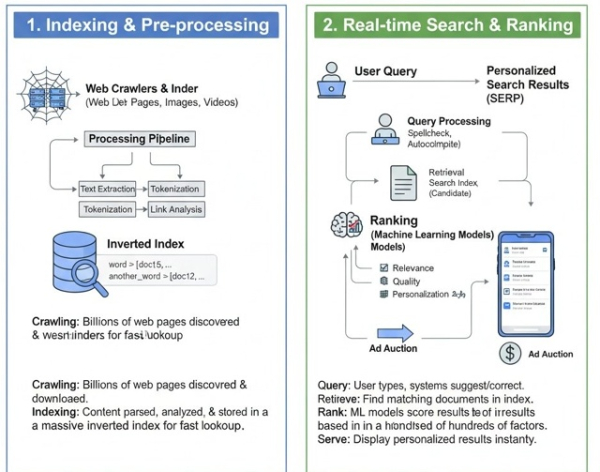

Google Search работает на распределённой архитектуре массового масштаба, которая разбивает интернет на фрагменты и обрабатывает их параллельно на сотнях тысяч серверов.
Когда вы вводите запрос, система не ищет информацию в реальном времени. Вместо этого она обращается к предварительно созданному, высокооптимизированному индексу — цифровой карте интернета, которая хранится в многочисленных дата-центрах по всему миру. Ваш запрос отправляется в ближайший дата-центр, где его одновременно обрабатывают несколько «индексных серверов», находя наиболее релевантные страницы за доли секунды.
Результаты затем ранжируются в мгновение ока с помощью сложных алгоритмов ранжирования (таких как BERT и MUM), которые учитывают сотни факторов — от релевантности ключевых слов и качества сайта до вашего местоположения и истории поиска, и всё это происходит ещё до полной загрузки страницы.
Основной поиск Google состоит из нескольких ключевых систем:
* Web Crawlers (Googlebot) постоянно находят и загружают новые страницы из интернета.
* Система индексирования обрабатывает эти страницы, разбивает их на термины и сохраняет в огромной распределённой базе данных индекса.
* Система обработки запросов понимает ваши намерения при поиске, исправляет опечатки и расширяет термины.
* Система ранжирования (PageRank как изначальный базовый алгоритм) использует машинное обучение для оценки и упорядочивания результатов по предполагаемому качеству и релевантности.
За кулисами Google запускает массовые пакетные и реальные процессы. Весь веб-индекс постоянно перестраивается в циклах, при этом инкрементальные обновления обрабатываются для отражения нового контента и свежих ссылок.
Эти данные хранятся в специализированных высокопроизводительных базах данных — Bigtable для веб-индекса, Spanner для транзакционных данных и колоссальных кэшах в оперативной памяти для мгновенной обработки распространённых запросов. Вся система спроектирована с учётом отказоустойчивости и низкой латентности, обеспечивая ответ даже при выходе из строя целых дата-центров.
Самое впечатляющее — это масштаб. Индекс Google содержит сотни миллиардов веб-страниц. Система обрабатывает триллионы поисковых запросов в год, обрабатывая каждый из них менее чем за секунду путём распределения рабочей нагрузки по глобальной сети специально созданных серверов.
## Технические характеристики Google Search
* Фронтенд: C++, Java, JavaScript
* Бэкенд: C++, Java, Go, Python, Protocol Buffers
* Базы данных и хранение: Bigtable, Spanner, Colossus (файловая система)
* Обмен данными и оркестрация: MapReduce, FlumeJava, Dataflow, Apache Beam
* Обработка данных: Borg (управление кластером), Dremel (BigQuery), Millwheel (потоковая обработка)
* Безопасность: Проприетарная аппаратная защита, TLS, непрерывное сканирование уязвимостей
* Инфраструктура: Глобальные проприетарные дата-центры, специальные чипы TPU/AI, сетевая структура Jupiter
* Девопс и мониторинг: Внутренние проприетарные инструменты (мониторинг Borgmon)
* Машинное обучение/ИИ: TensorFlow, BERT, MUM, RankBrain, LaMDA
Источник: vk.com
Источник: ai-news.ru

























