
Тест, который доказывает: разбивка контента на части — не развод, а наука
«Чанкинг контента — это развод для SEO-консультантов» — слышали такое?
Майк Кинг (iPullRank, один из ведущих экспертов по техническому SEO) провёл простой, но показательный эксперимент с косинусным сходством, чтобы закрыть этот вопрос раз и навсегда.
Эксперимент: цифры не врут
Исходные данные: Один абзац, заточенный под два разных ключа: machine learning и data privacy.
Косинусное сходство (мера релевантности, где 1.0 = идеальное совпадение): • С «machine learning»: 0.6481 • С «data privacy»: 0.6948
После разбивки на два отдельных, сфокусированных абзаца: • Сходство для обоих запросов выросло
Почему это работает?
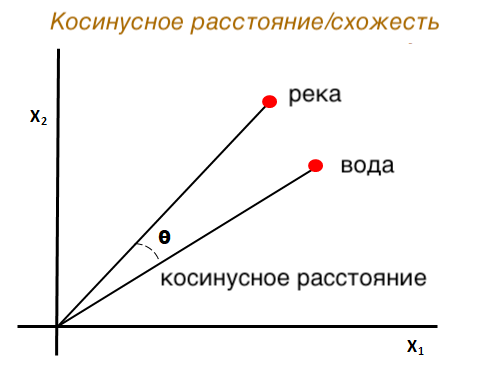
Что такое косинусное сходство? Это математическая метрика, измеряющая угол между двумя векторами в многомерном пространстве. В SEO и NLP 2024-2025 это стало объективным способом измерения семантической релевантности.
Проще говоря: Когда вы вводите запрос, Google (или любая LLM) преобразует его в числовой вектор. То же самое происходит с вашим контентом. Чем меньше «угол» между векторами, тем выше релевантность.
Ключевой принцип: Если релевантность измеряется сравнением векторного представления запроса с векторным представлением пассажей (а не всей страницы), то создание более сфокусированных пассажей логично улучшает этот показатель.
Практический смысл
Цель чанкинга: Разбивать контент на мелкие, очень сфокусированные абзацы, которые: • Системам легче извлечь • Улучшают метрики релевантности • Повышают шансы попадания в выдачу
Историческая справка: Google выкатил это под названием «индексация по пассажам» (Passage Ranking) ещё в феврале 2021 года.
Это был первый шаг от восприятия страницы как единого целого к пониманию её как набора отдельных компонентов.
Актуальность в 2024-2025: эра AI-поиска
Почему это критично сейчас:
1. Chrome использует 1540-мерные векторы Система Chrome History Embeddings обрабатывает веб-страницы в семантические пассажи, конвертирует в векторы высокой размерности для поиска.
2. AI Mode требует «chunk-level verifiable» контент Google AI Overviews, SGE, Perplexity — все они работают на принципе извлечения точных, фактических, семантически ясных фрагментов.
3. RAG-системы (Retrieval-Augmented Generation) LLM вроде ChatGPT, Claude, Gemini используют те же принципы: • Разбивка контента на чанки • Векторизация чанков • Поиск по косинусному сходству • Извлечение наиболее релевантных фрагментов
Ваш контент конкурирует не только в традиционном SEO, но и за место в ответах AI-ассистентов.
Эволюция подхода: Layout-Aware Chunking
Майк Кинг отмечает:
«Нам стоит больше думать о разбивке с учётом верстки (layout-aware chunking), а не только о семантической.»
Что это значит:
Семантический чанкинг (старый подход): • Разбивка по смыслу • Игнорирование визуальной структуры
Layout-aware чанкинг (продвинутый): • Учёт заголовков, списков, таблиц • Сохранение контекста через структуру документа • Может повысить точность на 5-10% (Snowflake Research, март 2025)
Основной принцип тот же: создавать отдельные, извлекаемые компоненты, которые соответствуют тому, как векторный поиск считает релевантность.
Практические рекомендации для SEO
1. Оптимальный размер чанков • Для RAG-систем: 200-500 токенов (примерно 150-400 слов) • Для Google Passage Ranking: короткие, пробивные абзацы (2-4 предложения)
2. Структура контента • Один абзац = одна мысль/тема • Используйте подзаголовки H2-H4 для создания «границ» чанков • Избегайте «кашицы» из нескольких тем в одном абзаце
3. Тестируйте релевантность • Используйте OpenAI API или локальные эмбеддинги • Измеряйте косинусное сходство между целевыми запросами и вашими абзацами • Рефакторьте контент с низким сходством
4. Думайте о «извлекаемости» Каждый абзац должен: • Быть самодостаточным (понятным вне контекста страницы) • Содержать ключевую информацию в первом предложении • Отвечать на конкретный вопрос или раскрывать конкретную тему
Примеры применения
Плохо (смешанный контент): «Machine learning помогает в data privacy, позволяя автоматизировать обнаружение утечек данных, а также применяется в рекомендательных системах и прогнозировании…»
Косинусное сходство с «machine learning»: 0.65 Косинусное сходство с «data privacy»: 0.68
Хорошо (разделённый контент):
Чанк 1: «Machine learning применяется в рекомендательных системах для персонализации контента. Алгоритмы анализируют поведение пользователей и прогнозируют их предпочтения.»
Косинусное сходство с «machine learning»: 0.82
Чанк 2: «Data privacy защищается через автоматизированное обнаружение утечек данных. Системы мониторят доступ к конфиденциальной информации в реальном времени.»
Косинусное сходство с «data privacy»: 0.85
Итог: это не «фокус», а математика
Чанкинг работает не потому, что это «хитрый трюк SEO-шников», а потому что это прямое отражение того, как работают современные системы поиска и AI.
В 2024-2025: • Google ранжирует по пассажам, а не страницам целиком • LLM извлекают информацию чанками • Векторный поиск измеряет релевантность через косинусное сходство
Ваш контент должен соответствовать этой архитектуре.
Не пишите страницы — создавайте коллекции извлекаемых, высокорелевантных пассажей.
Источники: • Mike King — iPullRank • Google Passage Ranking (февраль 2021) • Chrome History Embeddings Analysis (август 2025) • Snowflake Research on Chunking Strategies (март 2025)
Смотрите демонстрацию Майка Кинга: [YouTube](https://www.youtube.com/watch?v=ukpU-EfRtV4&t=2399s)
Источник: www.youtube.com
Источник: ai-news.ru