
Понимание архитектуры, конвейера обучения и практического применения TabPFN.
Делиться

Впервые я познакомился с TabPFN благодаря статье на ICLR 2023 — TabPFN: A Transformer That Solves Small Tabular Classification Problems in a Second. В статье была представлена TabPFN, модель трансформера с открытым исходным кодом, созданная специально для табличных наборов данных — области, которая не получила должного развития благодаря глубокому обучению и где по-прежнему доминируют модели деревьев решений с градиентным бустингом.
В то время TabPFN поддерживал только до 1000 обучающих выборок и 100 чисто числовых признаков, поэтому его использование в реальных условиях было довольно ограниченным. Однако со временем были внесены несколько постепенных улучшений, включая TabPFN-2, который был представлен в 2025 году в статье — «Точные прогнозы на небольших данных с помощью табличной базовой модели (TabPFN-2)».

Совсем недавно была выпущена версия TabPFN-2.5, которая может обрабатывать около 100 000 точек данных и примерно 2000 признаков, что делает её достаточно практичной для реальных задач прогнозирования. Я много лет работал с табличными наборами данных, поэтому это, естественно, привлекло моё внимание и подтолкнуло к более глубокому изучению. В этой статье я даю общий обзор TabPFN, а также демонстрирую быструю реализацию с использованием материала из конкурса Kaggle, чтобы помочь вам начать работу.
Что такое TabPFN?
TabPFN расшифровывается как Tabular Prior-data Fitted Network (табличная сеть с априорными данными), это базовая модель, которая Этот подход основан на идее подгонки модели к априорному распределению на основе табличных наборов данных, а не к одному единственному набору данных, отсюда и название.
Читая технические отчеты, я обнаружил много интересных деталей в этих моделях. Например, TabPFN может обеспечивать точные табличные прогнозы с очень низкой задержкой, часто сравнимой с оптимизированными ансамблевыми методами, но без повторных циклов обучения.
С точки зрения организации рабочего процесса, здесь также отсутствует кривая обучения, поскольку он органично вписывается в существующие системы благодаря интерфейсу в стиле scikit-learn. Он может обрабатывать пропущенные значения, выбросы и смешанные типы признаков с минимальной предварительной обработкой, которую мы рассмотрим в процессе реализации позже в этой статье.
Необходимость базовой модели для табличных данных
Прежде чем перейти к описанию принципа работы TabPFN, давайте сначала попробуем понять, какую более широкую проблему он пытается решить.
При традиционном машинном обучении на табличных наборах данных обычно приходится обучать новую модель для каждого нового набора данных. Это часто влечет за собой длительные циклы обучения, а также означает, что ранее обученную модель нельзя использовать повторно.
Однако, если мы посмотрим на базовые модели для текста и изображений, их идея кардинально отличается. Вместо переобучения с нуля, проводится большая предварительная подготовка на множестве наборов данных, и полученная модель затем может быть применена к новым наборам данных без переобучения в большинстве случаев.
На мой взгляд, именно этот пробел модель и пытается заполнить для табличных данных, а именно, уменьшить необходимость обучения новой модели с нуля для каждого набора данных, и это выглядит многообещающим направлением исследований.
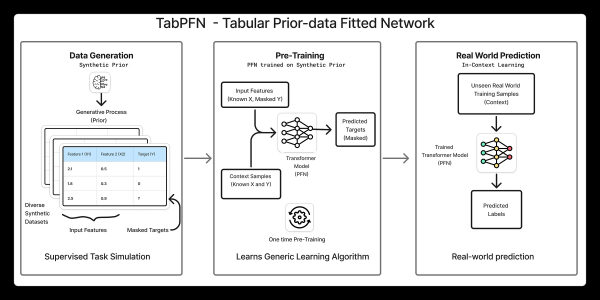
Конвейер обучения и вывода TabPFN на высоком уровне

TabPFN использует контекстное обучение для подгонки нейронной сети к априорному распределению на табличных наборах данных. Это означает, что вместо обучения на одной задаче за раз, модель изучает, как обычно выглядят табличные задачи, а затем использует эти знания для прогнозирования на новых наборах данных за один прямой проход. Вот выдержка из статьи TabPFN в журнале Nature:
TabPFN использует контекстное обучение (ICL), тот же механизм, который привел к поразительной производительности больших языковых моделей, для создания мощного алгоритма табличного прогнозирования, который полностью обучается. Хотя ICL впервые был обнаружен в больших языковых моделях, недавние исследования показали, что трансформеры могут обучаться простым алгоритмам, таким как логистическая регрессия, с помощью ICL.
Процесс можно разделить на три основных этапа:
1. Создание синтетических наборов данных
TabPFN рассматривает весь набор данных как единую точку данных (или токен), подаваемую в сеть. Это означает, что во время обучения требуется работа с очень большим количеством наборов данных. По этой причине обучение TabPFN начинается с синтетических табличных наборов данных . Почему синтетических? В отличие от текста или изображений, существует не так много больших и разнообразных реальных табличных наборов данных, что делает синтетические данные ключевой частью настройки. Для сравнения, TabPFN 2 был обучен на 130 миллионах наборов данных.
Сам процесс генерации синтетических наборов данных представляет интерес. TabPFN использует высокопараметрическую структурную причинно-следственную модель для создания табличных наборов данных с различными структурами, взаимосвязями признаков, уровнями шума и целевыми функциями. Путем выборки из этой модели можно сгенерировать большой и разнообразный набор данных, каждый из которых выступает в качестве обучающего сигнала для сети. Это побуждает модель изучать общие закономерности во многих типах табличных задач, а не переобучаться на каком-либо одном наборе данных.
2. Обучение
Приведённый ниже рисунок взят из упомянутой выше статьи в журнале Nature и наглядно демонстрирует процесс обучения и вывода результатов.

В процессе обучения синтетический табличный набор данных выбирается и разделяется на X train, Y train , X test и Y test. Значения Y test откладываются, а оставшиеся части передаются в нейронную сеть, которая выдает распределение вероятностей для каждой точки данных Y test , как показано на рисунке слева.
Затем отложенные тестовые значения Y оцениваются в соответствии с этими прогнозируемыми распределениями. После этого вычисляется функция потерь кросс-энтропии , и сеть обновляется. минимизировать эту потерю . На этом завершается один шаг обратного распространения ошибки для одного набора данных, и этот процесс затем повторяется для миллионов синтетических наборов данных.
3. Умозаключение
Во время тестирования обученная модель TabPFN применяется к реальному набору данных. Это соответствует рисунку справа, где модель используется для вывода результатов. Как видите, интерфейс остается таким же, как и во время обучения. Вы указываете X train , Y train и X test , и модель выдает прогнозы для Y test за один прямой проход.
Самое важное, что во время тестирования не требуется переобучение, и TabPFN фактически выполняет инференс без предварительного обучения , выдавая прогнозы немедленно, без обновления весов.
Архитектура

Давайте также затронем основную архитектуру модели, как указано в статье. В общих чертах, TabPFN адаптирует архитектуру трансформера для лучшего соответствия табличным данным. Вместо того чтобы преобразовывать таблицу в длинную последовательность, модель рассматривает каждое значение в таблице как отдельную единицу. Она использует двухэтапный механизм внимания, в рамках которого сначала изучается взаимосвязь признаков в пределах одной строки, а затем изучается поведение одного и того же признака в разных строках.
Такой способ организации внимания имеет решающее значение, поскольку он соответствует фактической организации табличных данных. Это также означает, что модели не важен порядок строк или столбцов, что позволяет ей обрабатывать таблицы большего размера, чем те, на которых она обучалась.
Выполнение
Теперь давайте рассмотрим реализацию TabPFN-2.5 и сравним её с обычным классификатором XGBoost , чтобы получить знакомую точку отсчёта. Хотя веса модели можно загрузить с Hugging Face, использование Kaggle Notebooks проще, поскольку модель там уже доступна, а поддержка GPU включена по умолчанию для более быстрого вывода. В любом случае, перед использованием модели необходимо принять её условия. После добавления модели TabPFN в среду Kaggle Notebooks выполните следующую команду для её импорта.
# Импорт модели import os os.environ[«TABPFN_MODEL_CACHE_DIR»] = «/kaggle/input/tabpfn-2-5/pytorch/default/2»
Полный код вы найдете в прилагаемом блокноте Kaggle. здесь .
Установка
Доступ к TabPFN можно получить двумя способами: либо как пакет Python для локального запуска, либо как API-клиент для запуска модели в облаке:
# Установка пакета Python: pip install tabpfn # В качестве API-клиента: pip install tabpfn-client
Набор данных: Набор данных для соревнований Kaggle Playground
Чтобы лучше понять, как TabPFN работает в реальных условиях, я протестировал его на конкурсе Kaggle Playground, который завершился несколько месяцев назад. Задача, «Бинарное прогнозирование с использованием набора данных о количестве осадков» (лицензия MIT), требует прогнозирования вероятности выпадения осадков для каждого идентификатора в тестовом наборе. Оценка проводилась с использованием ROC-AUC, что делает его подходящим для вероятностных моделей, таких как TabPFN. Данные для обучения выглядят следующим образом:

Обучение классификатора TabPFN
Обучение классификатора TabPFN довольно простое и использует привычный интерфейс scikit-learn . Хотя здесь нет обучения, специфичного для конкретной задачи, в традиционном смысле, все же важно включить поддержку GPU , иначе вывод может заметно замедлиться. Следующий фрагмент кода демонстрирует подготовку данных, обучение классификатора TabPFN и оценку его производительности с помощью показателя ROC–AUC.
# Импорт необходимых библиотек from tabpfn import TabPFNClassifier import pandas as pd, numpy as np from sklearn.model_selection import train_test_split # Выбор столбцов признаков FEATURES = [c for c in train.columns if c not in [«rainfall»,'id']] X = train[FEATURES].copy() y = train[«rainfall»].copy() # Разделение данных на обучающую и валидационную выборки train_index, valid_index = train_test_split( train.index, test_size=0.2, random_state=42 ) x_train = X.loc[train_index].copy() y_train = y.loc[train_index].copy() x_valid = X.loc[valid_index].copy() y_valid = y.loc[valid_index].copy() # Инициализация и обучение TabPFN model_pfn = TabPFNClassifier(device=[«cuda:0», «cuda:1″]) model_pfn.fit(x_train, y_train) # Прогнозирование вероятностей классов probs_pfn = model_pfn.predict_proba(x_valid) # # Использование вероятности положительного класса pos_probs = probs_pfn[:, 1] # # Оценка с использованием ROC AUC print(f»ROC AUC: {roc_auc_score(y_valid, pos_probs):.4f}») ————————————————- ROC AUC: 0.8722
Далее давайте обучим базовый классификатор XGBoost.
Обучение классификатора XGBoost
from xgboost import XGBClassifier # Инициализация классификатора XGBoost model_xgb = XGBClassifier( objective=»binary:logistic», tree_method=»hist», device=»cuda», enable_categorical=True, random_state=42, n_jobs=1 ) # Обучение модели model_xgb.fit(x_train, y_train) # Прогнозирование вероятностей классов probs_xgb = model_xgb.predict_proba(x_valid) # Использование вероятности положительного класса pos_probs_xgb = probs_xgb[:, 1] # Оценка с использованием ROC AUC print(f»ROC AUC: {roc_auc_score(y_valid, pos_probs_xgb):.4f}») ———————————————————— ROC AUC: 0.8515
Как видите, TabPFN показывает довольно хорошие результаты сразу после установки. Хотя XGBoost, безусловно, можно дополнительно оптимизировать, моя цель здесь — сравнить базовые, стандартные реализации, а не оптимизированные модели. Он позволил мне занять 22-е место в публичном рейтинге. Ниже приведены 3 лучших результата для сравнения.

А как насчет объяснимости модели?
Модели Transformer по своей природе не поддаются интерпретации, поэтому для понимания прогнозов обычно используются методы постфактумной интерпретации, такие как SHAP (SHapley Additive Explanations), для анализа отдельных прогнозов и вклада признаков. TabPFN предоставляет специальное расширение для интерпретации, которое интегрируется с SHAP, упрощая проверку и анализ прогнозов модели. Для доступа к нему необходимо сначала установить расширение:
# Установка расширения для обеспечения интерпретируемости: pip install «tabpfn-extensions[interpretability]» from tabpfn_extensions import interpretability # Вычисление значений SHAP shap_values = interpretability.shap.get_shap_values( estimator=model_pfn, test_x=x_test[:50], attribute_names=FEATURES, algorithm=»permutation», ) # Создание визуализации fig = interpretability.shap.plot_shap(shap_values)

На графике слева показана средняя важность признаков SHAP по всему набору данных, что дает общее представление о том, какие признаки наиболее важны для модели. График справа — это сводный график SHAP (beeswarm) , который предоставляет более детальное представление, показывая значения SHAP для каждого признака в отдельных прогнозах.
Из приведенных выше графиков видно, что облачность , солнечная активность , влажность и точка росы оказывают наибольшее общее влияние на прогнозы модели, в то время как такие факторы, как направление ветра, давление и переменные, связанные с температурой, играют сравнительно меньшую роль.
Важно отметить, что SHAP объясняет взаимосвязи, усвоенные моделью, а не физическую причинно-следственную связь.
Заключение
TabPFN обладает гораздо большим функционалом, чем я описал в этой статье. Лично мне понравилась как сама идея, так и простота начала работы с ним. Здесь я не затронул множество аспектов, таких как использование TabPFN в прогнозировании временных рядов, обнаружение аномалий, генерация синтетических табличных данных и извлечение эмбеддингов из моделей TabPFN.
Ещё одна область, которая меня особенно интересует, — это тонкая настройка, позволяющая адаптировать эти модели к данным из конкретной предметной области. Тем не менее, эта статья задумывалась как краткое введение, основанное на моём первом практическом опыте. Я планирую более подробно изучить эти дополнительные возможности в будущих публикациях. А пока что официальная документация — хорошее место для более глубокого изучения.
Источник: towardsdatascience.com

























