
Давайте рассмотрим материю на атомном уровне.
Делиться
 1")
Различные предметы вокруг нас могут быть слегка радиоактивными. Америций в датчиках дыма, радий в некоторых винтажных часах или уран в старинном стекле — полный список может быть длинным. В большинстве случаев эти предметы безопасны и не представляют опасности для здоровья. Интересно также идентифицировать их и изучать вещество на атомном уровне. И мы можем сделать это с помощью детектора излучения. В первой части я провёл разведочный анализ данных гамма-спектроскопии. Во второй части я создал модель машинного обучения для обнаружения радиоактивных изотопов. Это последняя, третья часть, и пришло время добавить созданную модель в настоящее приложение!
В этой истории я проверю два подхода:
- Я создам публичное приложение Streamlit, которое будет бесплатно размещено в Streamlit Cloud (ссылка на приложение добавлена в конец статьи).
- В качестве более гибкого и универсального решения я создам приложение на базе Python HTMX, которое сможет взаимодействовать с реальным оборудованием и делать прогнозы в реальном времени.
Как и в предыдущей части, я буду использовать сцинтилляционный детектор Radiacode для получения данных (примечание: устройство, использованное в этом тесте, было предоставлено производителем; я не получаю никакой коммерческой прибыли от его продаж и не получал никаких редакционных комментариев по всем тестам). Читатели, у которых нет оборудования Radiacode, смогут протестировать приложение и модель, используя файлы, доступные на Kaggle.
Давайте начнем!
1. Модель классификации изотопов
Эта модель была описана в предыдущей части. Она основана на XGBoost, и я обучил её на различных радиоактивных образцах. Я использовал образцы, которые можно легально приобрести, например, старинное урановое стекло или старые часы с радиевым циферблатом, выпущенные в 1950-х годах. Как уже упоминалось, я также использовал сцинтилляционный детектор Radiacode, позволяющий получить гамма-спектр объекта. Всего 10–20 лет назад такие детекторы были доступны только в крупных лабораториях; сегодня их можно купить по цене смартфона среднего класса.
Модель содержит три компонента:
- Сама модель на базе XGBoost.
- Список радиоактивных изотопов (например, свинец-214 или актиний-228), на которых обучалась модель. Сцинтилляционный детектор Radiacode возвращает 1024 значения спектра, 23 из которых были использованы для модели.
- Кодировщик меток для преобразования индексов списков в понятные человеку имена.
Давайте объединим все это в один класс Python:
из xgboost импорт XGBClassifier из sklearn.preprocessing импорт LabelEncoder класс IsotopesClassificationModel: «»» Модель классификации гамма-спектра «»» def __init__(self): «»» Загрузка моделей «»» path = self._get_models_path() self._classifier = self._load_model(path + «/XGBClassifier.json») self._isotopes = self._load_isotopes(path + «/isotopes.json») self._labels_encoder = self._load_labels_encoder(path + «/LabelEncoder.npy») def predict(self, spectrum: Spectrum) -> str: «»» Предсказать изотоп «»» features = SpectrumPreprocessing.convert_to_features( spectrum, self._isotopes ) preds = self._classifier.predict([features]) preds = self._labels_encoder.inverse_transform(preds) return preds[0] @staticmethod def _load_model(filename: str) -> XGBClassifier: «»» Загрузить модель из файла «»» bst = XGBClassifier() bst.load_model(filename) return bst @staticmethod def _load_isotopes(filename: str) -> Список: с открытым(filename, «r») как f_in: return json.load(f_in) @staticmethod def _load_labels_encoder(filename: str) -> LabelEncoder: le = LabelEncoder() le.classes_ = np.load(filename) return le @staticmethod def _get_models_path() -> str: «»» Получить путь к моделям. Файлы моделей хранятся в папке 'models/V1/' «»» parent_dir = os.path.dirname(os.path.dirname(os.path.abspath(__file__))) return parent_dir + f»/models/{IsotopesClassificationModel.VERSION}»
Класс Spectrum содержит данные спектра, которые мы получаем от детектора излучения:
@dataclass класс Спектр: «»» Данные спектра излучения «»» длительность: datetime.timedelta a0: float a1: float a2: float количество: list[int]
Здесь counts — это гамма-спектр, представленный списком из 1024 значений каналов. Данные спектра можно экспортировать с помощью официального приложения Radiacode для Android или получить непосредственно с устройства с помощью библиотеки Radiacode для Python.
Чтобы загрузить спектр в модель, я создал класс SpectrumPreprocessing:
class SpectrumPreprocessing: «»» Предварительная обработка гамма-спектра «»» @staticmethod def convert_to_features(spectrum: Spectrum, isotopes: List) -> np.array: «»» Преобразует спектр в список признаков для прогнозирования «»» sp_norm = SpectrumPreprocessing._normalize(spectrum) energy = [energy for _, energy in isotopes] channels = [SpectrumPreprocessing.energy_to_channel(spectrum, energy) for energy in energy] return np.array([sp_norm.counts[ch] for ch in channels]) @staticmethod def load_from_xml_file(file_path: str) -> Spectrum: «»» Загрузить спектр из файла приложения Radiacode для Android «»»
Здесь я пропускаю некоторые блоки кода, которые уже были опубликованы в предыдущей части. Там же объяснялось извлечение признаков из гамма-спектра, и я настоятельно рекомендую сначала прочитать эту часть.
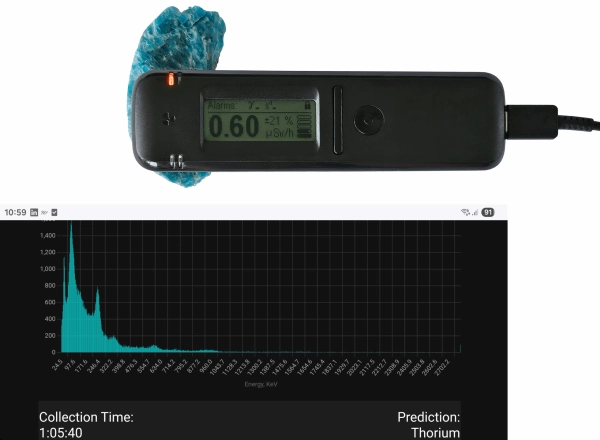
А теперь давайте протестируем модель! Я взял детектор Radiacode и собрал гамма-спектр за 10 минут:
 2")
Этот китайский кулон рекламировался как «ионно-генерируемый», и он слегка радиоактивен. Его гамма-спектр, полученный в официальном приложении Radiacode для Android, выглядит так:
 3")
Подождав около 10 минут, я экспортировал спектр в XML-файл. Теперь можно запустить модель:
из спектра импорта SpectrumPreprocessing из ml_models импорта IsotopesClassificationModel sp = SpectrumPreprocessing.load_from_file(«spectrum.xml») model = IsotopesClassificationModel() result = model.predict(sp) print(result) #> Торий
Как видим, модель работает хорошо. Мы можем сравнить пики со спектрами известных изотопов (например, здесь или здесь) и подтвердить, что спектр принадлежит торию.
2. Стримлит
Модель работает, однако мы живём в XXI веке, и мало кто будет запускать консольное приложение, чтобы получить результаты. Вместо этого мы можем сделать приложение доступным онлайн, и все пользователи Radiacode смогут его запустить.
Существует множество фреймворков Python для создания браузерных приложений, и Streamlit, пожалуй, самый популярный в сообществе специалистов по анализу данных. И, что важно для нас, платформа Streamlit Community Cloud позволяет каждому публиковать свои приложения совершенно бесплатно. Для этого давайте сначала создадим приложение.
2.1 Приложение Streamlit
Фреймворк Streamlit относительно прост в использовании, по крайней мере, если нам подходит стандартное приложение. Лично я не сторонник такого подхода. Эти фреймворки скрывают от пользователей все низкоуровневые детали реализации. Создать прототип несложно, но логика пользовательского интерфейса будет тесно связана с узкоспециализированным фреймворком и не сможет быть использована где-либо ещё. Реализация чего-либо нестандартного, что не поддерживается фреймворком, может быть практически невозможна или сложно реализуема без погружения в огромное количество абстракций и страниц кода. Однако в нашем случае прототип — это всё, что нам нужно.
В целом код Streamlit прост, и нам нужно лишь описать логическую иерархию нашей страницы:
import streamlit as st import logging logger = logging.getLogger(__name__) def is_xml_valid(xml_data: str) -> bool: «»» Проверьте, имеет ли XML допустимый размер и данные «»» return len(xml_data) < 65535 и xml_data.startswith(" Optional[Spectrum]: «»» Загрузите спектр из потока StringIO «»» xml_data = stringio.read() if is_xml_valid(xml_data): return SpectrumPreprocessing.load_from_xml(xml_data) return None def main(): «»» Основное приложение «»» st.set_page_config(page_title=»Гамма-спектр») st.title(«Обнаружение спектра Radiacode») st.text( «Экспортируйте спектр в XML с помощью приложения Radiacode и » «загрузите его в см. результаты.» ) # Загрузка файла uploaded_file = st.file_uploader( «Выберите XML-файл», type=»xml», key=»uploader», ) if uploaded_file is not None: stringio = StringIO(uploaded_file.getvalue().decode(«utf-8″)) if sp := get_spectrum(stringio): # Модель прогнозирования = IsotopesClassificationModel() result = model.predict(sp) logger.info(f»Предсказание спектра: {result}») # Показать результат st.success(f»Результат прогнозирования: {result}») # Нарисовать fig = get_spectrum_barchart(sp) st.pyplot(fig) if __name__ == «__main__»: logger.setLevel(logging.INFO) main()
Как видите, для полноценного приложения требуется минимум кода на Python. Streamlit отрисует весь HTML-код, включая заголовок, загрузку файла и результаты. В качестве бонуса я также покажу спектр с помощью Matplotlib:
def get_spectrum_barchart(sp: Spectrum) -> plt.Figure: «»» Получить столбчатую диаграмму Matplotlib «»» counts = SpectrumPreprocessing.get_counts(sp) energy = [ SpectrumPreprocessing.channel_to_energy(sp, x) for x in range(len(counts)) ] fig, ax = plt.subplots(figsize=(9, 6)) ax.spines[«top»].set_color(«lightgray») ax.spines[«right»].set_color(«lightgray») # Столбцы ax.bar(energy, counts, width=3.0, label=»Counts») # Значения X ticks_x = [SpectrumPreprocessing.channel_to_energy(sp, ch) for ch in range(0, len(counts), len(counts) // 20)] labels_x = [f»{int(ch)}» for ch в ticks_x] ax.set_xticks(ticks_x, labels=labels_x, вращение=45) ax.set_xlim(energy[0], energy[-1]) ax.set_ylim(0, None) ax.set_title(«Гамма-спектр») ax.set_xlabel(«Энергия, кэВ») ax.set_ylabel(«Количество») вернуть рис.
Теперь мы можем запустить приложение локально:
streamlit запустите st-app.py
После этого наше приложение полностью работоспособно и его можно протестировать в браузере:
 4")
Как я уже упоминал, я не фанат высокоуровневых фреймворков и предпочитаю лучше понимать, как всё работает «под капотом». Однако, учитывая, что я потратил всего около 100 строк кода на создание полнофункционального веб-приложения, жаловаться не на что — для прототипирования оно подходит отлично.
2.2 Облако сообщества Streamlit
После локального тестирования приложения пора выкладывать его в открытый доступ! Streamlit Cloud — бесплатный сервис, и, очевидно, у него есть ряд ограничений:
- Приложение работает в контейнере, подобном Docker. Ваша учётная запись GitHub должна быть связана со Streamlit. При запуске контейнер загружает ваш код с GitHub и запускает его.
- На момент написания этого текста ресурсы контейнера ограничены двумя ядрами и 2,7 ГБ оперативной памяти. Для запуска LLM размером 70 байт этого было бы слишком мало, но для небольшой модели XGBoost этого более чем достаточно.
- Streamlit не предоставляет постоянного хранилища. После выключения или перезапуска все журналы и временные файлы будут утеряны (при необходимости вы можете использовать секреты API и подключиться к любому другому облачному хранилищу из своего кода на Python).
- После периода бездействия (около 30 минут) контейнер будет остановлен, а все временные файлы будут удалены. Если кто-то откроет ссылку на приложение, оно запустится снова.
Как читатели могут догадаться, неактивное приложение практически ничего не стоит Streamlit, поскольку хранит лишь небольшой файл конфигурации. И это отличное решение для бесплатного сервиса: оно позволяет нам бесплатно публиковать приложение и предоставлять пользователям ссылку для его запуска.
Чтобы опубликовать приложение в Streamlit , нам нужно выполнить три простых шага.
Для начала нам нужно закоммитить наше Python-приложение на GitHub. Файл requirements.txt также обязателен. Контейнер Streamlit использует его для установки необходимых зависимостей Python. В моём случае это выглядит так:
xgboost==3.0.2 scikit-learn==1.6.1 numpy==1.26.4 streamlit==1.47.0 pillow==11.1.0 matplotlib==3.10.3 xmltodict==0.14.2
Настройки сервера можно изменить с помощью файла .streamlit/config.toml. В моём случае я ограничил размер загружаемого файла 1 МБ, поскольку все файлы спектров меньше:
[сервер] # Максимальный размер файлов, загружаемых с помощью file_uploader, в мегабайтах. # По умолчанию: 200 maxUploadSize = 1
Во-вторых, нам нужно войти в share.streamlit.io, используя учетную запись GitHub, и дать разрешение на доступ к исходному коду.
Наконец, мы можем создать новый проект Streamlit. В настройках проекта мы также можем выбрать нужный URL и окружение:
 5")
Если все сделано правильно, мы увидим работающее приложение:
 6")
Теперь к нашему приложению могут получить доступ пользователи по всему миру! В моём случае я выбрал имя для гамма-спектрального обнаружения, и приложение доступно по этому URL-адресу.
3. Приложение FastAPI + HTMX
Как видите читатели, Streamlit — отличное решение для простого прототипа. Однако в случае с детектором радиации мне хотелось бы видеть данные, поступающие с реального оборудования Radiacode. В Streamlit это сделать невозможно; эта библиотека просто не предназначена для этого. Вместо этого я буду использовать несколько готовых к использованию фреймворков:
- Фреймворк HTMX позволяет нам создать полнофункциональный веб-интерфейс.
- FastAPI запустит сервер.
- Модель МО будет обрабатывать данные, полученные в режиме реального времени от детектора излучения, с использованием библиотеки Radiacode.
Как уже упоминалось, те читатели, у которых нет устройства Radiacode, смогут воспроизвести данные, используя необработанные файлы журнала, сохранённые с реального устройства. Ссылка на приложение и все файлы доступна в конце статьи.
Давайте приступим!
3.1 HTML/HTMX
Приложение подключено к детектору Radiacode, и я решил отображать на странице состояние подключения, уровень радиации и график спектра. Внизу будут отображаться время сбора спектра и прогноз модели машинного обучения.
Файл index.html для этого макета выглядит так:
н/д
н/д