Исследование показало: ИИ теряется в длинных диалогах и вводит пользователей в заблуждение
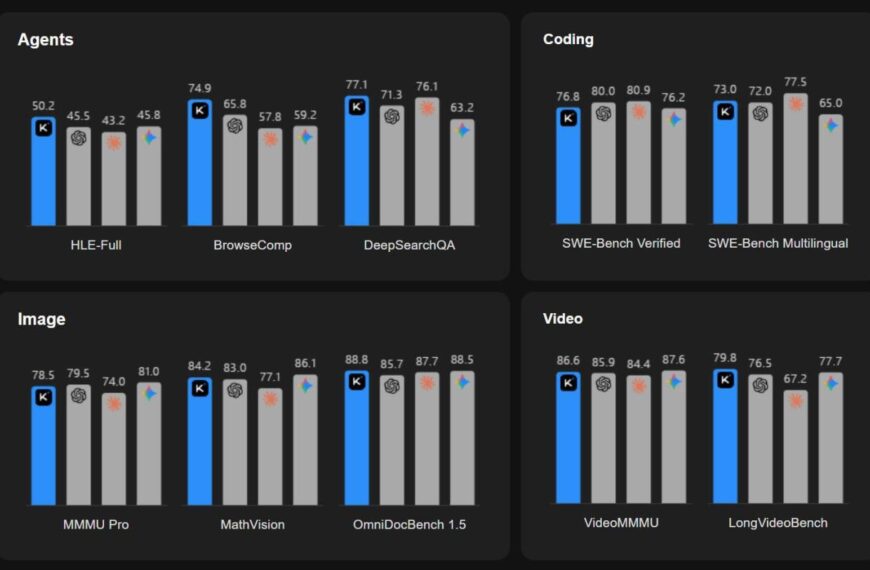
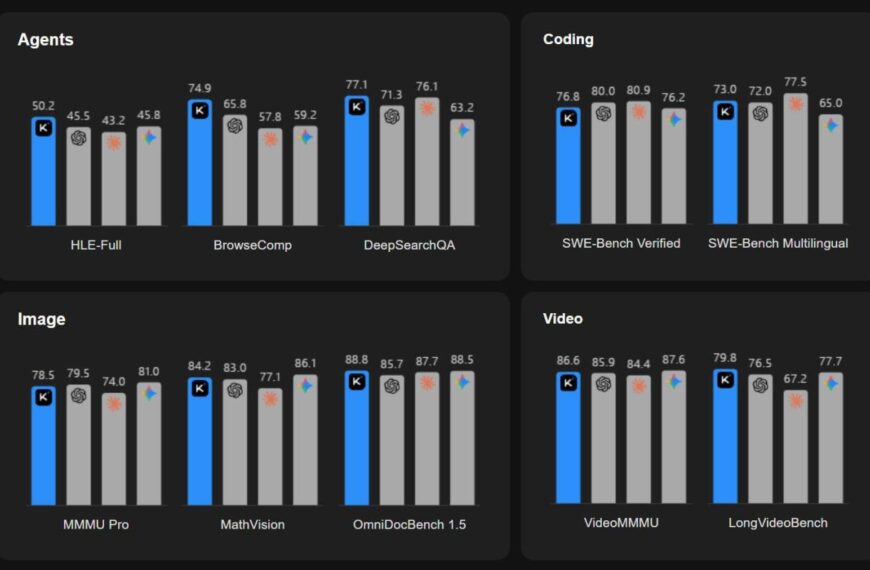
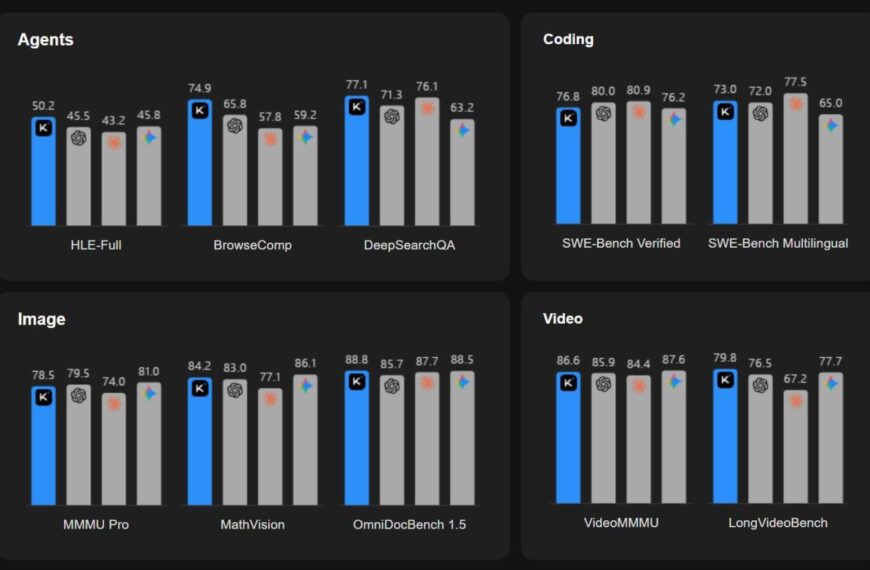
Совместное исследование Microsoft Research и Salesforce охватило более 200 000 диалогов с продвинутыми LLM, включая GPT-4.1, Gemini 2.5 Pro, Claude 3.7 Sonnet, o3, DeepSeek R1 и Llama 4, и выявило серьёзные недостатки в многоходовых диалогах. Как оказалось, модели успешно справляются с одиночными запросами, достигая 90% точности, но при последовательных вопросах точность падает примерно до 65%.
Исследователи объясняют, что модели «спешат с ответом», стараясь завершить решение задачи до того, как пользователь закончит пояснение. Это приводит к феномену «ответного зацепления»: ИИ использует предыдущий ответ как основу для следующего, даже если он был неверен.