Изучите распределенные операции PyTorch для многопроцессорных задач искусственного интеллекта.
Делиться

Эта статья является частью серии материалов о распределенном искусственном интеллекте на нескольких графических процессорах:
- Часть 1: Понимание парадигмы «Хост и устройство»
- Часть 2: Перевозки между двумя точками и коллективные перевозки (данная статья)
- Часть 3: Как взаимодействуют графические процессоры (скоро будет опубликовано)
- Часть 4: Накопление градиента и распределенный параллелизм данных (DDP) (скоро будет опубликовано)
- Часть 5: ZeRO (скоро будет доступна)
- Часть 6: Тензорный параллелизм (скоро будет опубликована)
Введение
В предыдущей статье мы изучили парадигму «хост-устройство» и представили концепцию рангов для многопроцессорных рабочих нагрузок. Теперь мы рассмотрим конкретные шаблоны взаимодействия, предоставляемые модулем torch.distributed в PyTorch для координации работы и обмена данными между этими рангами. Эти операции, известные как коллективы , являются строительными блоками распределенных рабочих нагрузок.
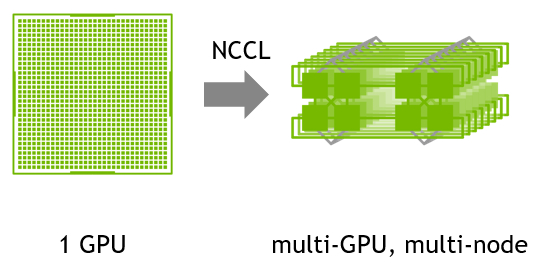
Хотя PyTorch предоставляет доступ к этим операциям, в конечном итоге он обращается к бэкэнд-фреймворку, который фактически реализует коммуникацию. Для графических процессоров NVIDIA это NCCL (NVIDIA Collective Communications Library), а для AMD — RCCL (ROCm Communication Collectives Library).
NCCL реализует примитивы связи для нескольких графических процессоров и нескольких узлов, оптимизированные для графических процессоров NVIDIA и сетевых технологий. Он автоматически определяет текущую топологию (каналы связи, такие как PCIe, NVLink, InfiniBand) и выбирает наиболее эффективный из них.
Примечание 1: Поскольку графические процессоры NVIDIA являются наиболее распространенными, в этой статье мы сосредоточимся на бэкэнде NCCL.
Примечание 2: Для краткости приведенный ниже код содержит только основные аргументы каждого метода, а не все доступные аргументы.
Примечание 3: Для простоты мы не показываем освобождение памяти тензоров, но такие операции, как scatter, не освобождают автоматически память исходного ранга (если вы не понимаете, что я имею в виду, это нормально, скоро станет ясно).
Коммуникация: блокировка против неблокировки
Для совместной работы графические процессоры должны обмениваться данными. Центральный процессор инициирует связь, помещая ядра NCCL в потоки CUDA (если вы не знаете, что такое потоки CUDA, ознакомьтесь с первой статьей этой серии), но фактическая передача данных происходит напрямую между графическими процессорами по межсоединению, полностью минуя основную память центрального процессора. В идеале графические процессоры соединены высокоскоростным межсоединением, таким как NVLink или InfiniBand (эти межсоединения рассматриваются в третьей статье этой серии).
Эта коммуникация может быть синхронной (блокирующей) или асинхронной (неблокирующей), которые мы рассмотрим ниже.
Синхронная (блокирующая) связь
- Поведение: При вызове метода синхронной связи хост-процесс останавливается и ожидает, пока ядро NCCL не будет успешно поставлено в очередь для текущего активного потока CUDA. После постановки в очередь функция возвращает управление. Обычно это простой и надежный способ. Обратите внимание, что хост не ожидает завершения передачи, а только постановки операции в очередь. Однако он блокирует переход данного потока к следующей операции до тех пор, пока ядро NCCL не будет выполнено до конца.
Асинхронная (неблокирующая) связь
- Поведение: При вызове метода асинхронной связи вызов немедленно возвращает управление, и операция добавления данных в очередь происходит в фоновом режиме. Данные добавляются не в текущий активный поток, а в выделенный внутренний поток NCCL для каждого устройства. Это позволяет вашему процессору продолжать выполнение других задач — метод, известный как перекрытие вычислений и связи . Асинхронный API более сложен, поскольку может привести к неопределенному поведению, если вы неправильно используете метод `.wait()` (описано ниже) и изменяете данные во время их передачи. Однако освоение этого метода является ключом к достижению максимальной производительности в крупномасштабном распределенном обучении.
Точка-точка (один к одному)
Эти операции не считаются коллективными , но являются основополагающими коммуникационными примитивами. Они обеспечивают прямую передачу данных между двумя конкретными уровнями и имеют фундаментальное значение для задач, где одному графическому процессору необходимо отправить определенную информацию другому.
- Синхронный (блокирующий) : хост-процесс ожидает, пока операция будет поставлена в очередь потока CUDA, прежде чем продолжить. Ядро ставится в очередь в текущий активный поток.
- torch.distributed.send(tensor, dst): Отправляет тензор на указанный целевой ранг.
- torch.distributed.recv(tensor, src): Принимает тензор из источника ранга. Принимающий тензор должен быть предварительно выделен с правильной формой и типом данных.
- Асинхронный (неблокирующий) : хост-процесс инициирует операцию постановки задачи в очередь и немедленно переходит к выполнению других задач. Ядро помещается в выделенный внутренний поток NCCL для каждого устройства, что позволяет осуществлять перекрывающуюся связь с вычислениями. Эти операции возвращают запрос (технически объект Work), который можно использовать для отслеживания статуса постановки в очередь.
- request = torch.distributed.isend(tensor, dst): Инициирует асинхронную операцию отправки.
- request = torch.distributed.irecv(tensor, src): Инициирует асинхронную операцию приема.
- request.wait(): Блокирует хост только до тех пор, пока операция не будет успешно поставлена в очередь потока CUDA. Однако это блокирует выполнение последующих ядер текущим активным потоком CUDA до завершения этой конкретной асинхронной операции.
- request.wait(timeout): Если вы укажете аргумент timeout, поведение хоста изменится. Он заблокирует поток ЦП до завершения работы NCCL или истечения времени ожидания (с выдачей исключения). В обычных случаях пользователям не нужно устанавливать timeout.
- request.is_completed(): Возвращает True, если операция успешно добавлена в поток CUDA. Может использоваться для опроса. Не гарантирует фактическую передачу данных.
Когда PyTorch запускает ядро NCCL, он автоматически вставляет зависимость (т.е. принудительно устанавливает синхронизацию) между текущим активным потоком и потоком NCCL. Это означает, что поток NCCL не запустится, пока не завершится вся ранее поставленная в очередь работа с активным потоком, гарантируя, что отправляемый тензор уже содержит окончательные значения.
Аналогично, вызов req.wait() вставляет зависимость в обратном направлении. Любая работа, которую вы ставите в очередь в текущем потоке после req.wait(), не будет выполняться до завершения операции NCCL , поэтому вы можете безопасно использовать полученные тензоры.
Основные «подводные камни» в NCCL
Хотя функции send и recv помечены как «синхронные», их поведение в NCCL может вызывать путаницу. Синхронный вызов тензора CUDA блокирует поток ЦП хоста только до тех пор, пока ядро передачи данных не будет поставлено в очередь потока, а не до завершения передачи данных . После этого ЦП может свободно ставить в очередь другие задачи.
Есть исключение: самый первый вызов torch.distributed.recv() в процессе является действительно блокирующим и ожидает завершения передачи, вероятно, из-за внутренних процедур подготовки NCCL. Последующие вызовы будут блокироваться только до тех пор, пока операция не будет поставлена в очередь.
Рассмотрим пример, когда процесс на первом уровне зависает, потому что ЦП пытается получить доступ к тензору, который еще не был получен графическим процессором:
rank = torch.distributed.get_rank() if rank == 0: t = torch.tensor([1,2,3], dtype=torch.float32, device=device) # torch.distributed.send(t, dst=1) # Операция отправки не выполняется else: # rank == 1 (предполагая только 2 ранга) t = torch.empty(3, dtype=torch.float32, device=device) torch.distributed.recv(t, src=0) # Блокировка выполняется только до постановки в очередь (после первого запуска) print(«Это будет напечатано, если NCCL прогрет») print(t) # ЦП нужны данные от ГП, что приводит к блокировке print(«Это НЕ будет напечатано»)
Процесс ЦП на первом уровне зависает на вызове print(t), поскольку он запускает синхронизацию между хостом и устройством для доступа к данным тензора, которые так и не поступают.
Если вы запустите этот код несколько раз, обратите внимание, что фраза «This WILL print if NCCL is warmed up» не будет выведена в последующих запусках, поскольку процессор все еще находится в состоянии print(t).
Коллективы
Каждая функция коллективной операции поддерживает как синхронные, так и асинхронные операции с помощью аргумента async_op. По умолчанию он имеет значение False, что означает синхронные операции.
Коллективы «один ко всем»
Эти операции включают в себя отправку данных одним рангом всем остальным рангам в группе.
Транслировать
- torch.distributed.broadcast(tensor, src) : Копирует тензор из одного исходного ранга (src) во все остальные ранги. В результате каждый процесс получает идентичную копию тензора. Параметр tensor служит двум целям: (1) если ранг процесса совпадает с src, то тензор является отправляемыми данными; (2) в противном случае тензор используется для сохранения полученных данных.
rank = torch.distributed.get_rank() if rank == 0: # исходный ранг tensor = torch.tensor([1,2,3], dtype=torch.int64, device=device) else: # целевые ранги tensor = torch.empty(3, dtype=torch.int64, device=device) torch.distributed.broadcast(tensor, src=0)

Рассеивание
- torch.distributed.scatter(tensor, scatter_list, src) : Распределяет фрагменты данных из исходного ранга по всем рангам. Список scatter_list в исходном ранге содержит несколько тензоров, и каждый ранг (включая исходный) получает один тензор из этого списка в свою переменную tensor. Для рангов назначения просто передается значение None для списка scatter_list.
# Для всех рангов, не являющихся исходными, scatter_list должен быть равен None. scatter_list = None, если rank != 0, иначе [torch.tensor([i, i+1]).to(device) for i in range(0,4,2)] tensor = torch.empty(2, dtype=torch.int64).to(device) torch.distributed.scatter(tensor, scatter_list, src=0) print(f'Rank {rank} received: {tensor}')

Всеобщие Коллективы
Эти операции собирают данные со всех рангов и объединяют их в единый целевой ранг.
Уменьшать
- torch.distributed.reduce(tensor, dst, op) : Берет тензор из каждого ранга, применяет операцию редукции (например, SUM, MAX, MIN) и сохраняет конечный результат только в целевом ранге (dst).
rank = torch.distributed.get_rank() tensor = torch.tensor([rank+1, rank+2, rank+3], device=device) torch.distributed.reduce(tensor, dst=0, op=torch.distributed.ReduceOp.SUM) print(tensor)

Собирать
- torch.distributed.gather(tensor, gather_list, dst) : Собирает тензор из каждого ранга в список тензоров целевого ранга. gather_list должен представлять собой список тензоров (правильного размера и типа) целевого ранга и None во всех остальных.
# Параметр gather_list должен быть равен None для всех рангов, кроме целевого. rank = torch.distributed.get_rank() world_size = torch.distributed.get_world_size() gather_list = None if rank != 0 else [torch.zeros(3, dtype=torch.int64).to(device) for _ in range(world_size)] t = torch.tensor([0+rank, 1+rank, 2+rank], dtype=torch.int64).to(device) torch.distributed.gather(t, gather_list, dst=0) print(f'После операции ранг {rank} имеет: {gather_list}')
Переменная world_size — это общее количество рангов. Её можно получить с помощью torch.distributed.get_world_size(). Но пока не стоит беспокоиться о деталях реализации, самое важное — понять основные понятия.

Всеобщие коллективы
В ходе этих операций каждый ранг отправляет и получает данные от всех других рангов.
Все сокращают
- torch.distributed.all_reduce(tensor, op) : То же самое, что и reduce, но результат сохраняется на каждом ранге, а не только в одном месте назначения.
# Пример использования torch.distributed.all_reduce rank = torch.distributed.get_rank() tensor = torch.tensor([rank+1, rank+2, rank+3], dtype=torch.float32, device=device) torch.distributed.all_reduce(tensor, op=torch.distributed.ReduceOp.SUM) print(f»Ранг {rank} после all_reduce: {tensor}»)

Все соберитесь!
- torch.distributed.all_gather(tensor_list, tensor) : То же самое, что и gather, но собранный список тензоров доступен на каждом ранге.
# Пример использования torch.distributed.all_gather rank = torch.distributed.get_rank() world_size = torch.distributed.get_world_size() input_tensor = torch.tensor([rank], dtype=torch.float32, device=device) tensor_list = [torch.empty(1, dtype=torch.float32, device=device) for _ in range(world_size)] torch.distributed.all_gather(tensor_list, input_tensor) print(f»Rank {rank} gathered: {[t.item() for t in tensor_list]}»)

Уменьшить рассеяние
- torch.distributed.reduce_scatter(output, input_list) : Эквивалентно выполнению операции редукции над списком тензоров с последующим распределением результатов. Каждый ранг получает свою часть редуцированного выходного значения.
# Пример использования torch.distributed.reduce_scatter rank = torch.distributed.get_rank() world_size = torch.distributed.get_world_size() input_list = [torch.tensor([rank + i], dtype=torch.float32, device=device) for i in range(world_size)] output = torch.empty(1, dtype=torch.float32, device=device) torch.distributed.reduce_scatter(output, input_list, op=torch.distributed.ReduceOp.SUM) print(f»Ранг {rank} получил уменьшенное значение: {output.item()}»)

Синхронизация
Две наиболее часто используемые операции — это request.wait() и torch.cuda.synchronize(). Крайне важно понимать разницу между ними:
- request.wait(): Эта функция используется для асинхронных операций. Она синхронизирует текущий активный поток CUDA для данной операции, гарантируя, что поток ожидает завершения обмена данными, прежде чем продолжить. Другими словами, она блокирует текущий активный поток CUDA до завершения передачи данных. На стороне хоста это приводит к тому, что хост ожидает только постановки ядра в очередь; хост не ожидает завершения передачи данных.
- torch.cuda.synchronize(): Это более строгая команда, которая приостанавливает поток ЦП хоста до завершения всех ранее поставленных в очередь задач на графическом процессоре. Она гарантирует, что графический процессор полностью освободится перед переходом ЦП, но при неправильном использовании может создавать узкие места в производительности. При проведении бенчмарк-измерений следует использовать эту команду, чтобы точно зафиксировать момент завершения работы графических процессоров.
Заключение
Поздравляем с тем, что вы дошли до конца! В этом посте вы узнали о:
- Операции «точка-точка»
- Синхронные и асинхронные операции в NCCL
- Коллективные операции
- Методы синхронизации
В следующем посте мы подробно рассмотрим PCIe, NVLink и другие механизмы, обеспечивающие связь в распределенной среде!
Ссылки
- Документация PyTorch
- Документы NCCL P2P
Источник: towardsdatascience.com