Устали от шумихи вокруг ИИ? Давайте поговорим о вероятностных алгоритмах, которые на самом деле лежат в основе высокоэффективных количественных финансовых исследований.
Делиться
: Алгоритм Метрополиса-Хастингса 1")
Если вы изучаете байесовскую статистику, вы, вероятно, уже сталкивались с MCMC (Markov Chain Monte Carlo). В то время как остальной мир зациклен на последних достижениях в области LLM, метод Монте-Карло с цепями Маркова остается незаметным, но надежным инструментом высокоуровневых количественных финансов и управления рисками. Это инструмент выбора, когда «угадывания» недостаточно, и вам необходимо точно определить неопределенность.
Несмотря на пугающую аббревиатуру, метод Монте-Карло на основе цепей Маркова представляет собой сочетание двух простых концепций:
- Цепь Маркова — это стохастический процесс, в котором следующее состояние системы полностью зависит от её текущего состояния, а не от последовательности событий, предшествовавших ему. Это свойство обычно называют отсутствием памяти.
- Метод Монте-Карло — это просто любой алгоритм, основанный на многократной случайной выборке для получения численных результатов.
В этой серии статей мы представим основные алгоритмы, используемые в рамках MCMC. В основном мы сосредоточимся на алгоритмах, применяемых в байесовских методах.
Начнём с алгоритма Метрополиса-Хастингса: основополагающего алгоритма, который позволил совершить первые прорывы в этой области. Но прежде чем углубляться в механику, давайте обсудим проблему, которую помогают решить методы MCMC.
Проблема
Предположим, мы хотим иметь возможность выбирать значения переменных из вероятностного распределения, для которого нам известна формула плотности. В этом примере мы используем стандартное нормальное распределение. Назовем функцию, которая может выбирать значения из него, rnorm .
Чтобы rnorm считался полезным, он должен генерировать значения (x) в долгосрочной перспективе, которые соответствуют вероятностям нашего целевого распределения. Другими словами, если бы мы запустили rnorm (100 000) раз и собрали эти значения, а затем построили гистограмму в зависимости от частоты их появления, форма гистограммы напоминала бы стандартное нормальное распределение.
Как мы можем этого добиться?
Начнём с формулы для ненормированной плотности нормального распределения:
[p(x) = e^{-frac{x^2}{2}}]
Эта функция возвращает плотность для заданного (x) вместо вероятности. Чтобы получить вероятность, нам нужно нормализовать нашу функцию плотности на константу, так чтобы общая площадь под кривой интегрировалась (суммировалась) до (1).
Чтобы найти эту константу, нам нужно проинтегрировать функцию плотности по всем возможным значениям (x).
[C = int^infty_{-infty}e^{-frac{x^2}{2}},dx]
Для неопределенного интеграла от (e^{-x^2}) не существует решения в замкнутой форме. Однако математики решили определенный интеграл (от (-infty) до (infty)), перейдя в полярные координаты (поскольку, по-видимому, преобразование одномерной задачи в двумерную упрощает ее решение) и осознав, что полная площадь равна (sqrt{2pi}).
Следовательно, чтобы сумма площадей под кривой равнялась (1), константа должна быть обратной:
[C = frac{1}{sqrt{2pi}}]
Именно отсюда берется хорошо известная константа нормализации (C) для нормального распределения.
Отлично, у нас есть заданная математиками константа, которая делает наше распределение допустимым вероятностным распределением. Но нам все еще нужно иметь возможность отбирать из него выборки.
Поскольку наша шкала непрерывна и бесконечна, вероятность получения точно определенного числа (например, (x = 1,2345…) с бесконечной точностью) фактически равна нулю . Это происходит потому, что отдельная точка не имеет ширины и, следовательно, не содержит «площади» под кривой.
Вместо этого мы должны говорить в терминах диапазонов, то есть какова вероятность получения значения (x), которое находится между (a) и (b) ((a < x < b)), где (a) и (b) — фиксированные значения?
Другими словами, нам нужно найти площадь под кривой между (a) и (b). И, как вы правильно догадались, для вычисления этой площади нам обычно необходимо проинтегрировать нашу нормированную формулу плотности — полученная интегрированная функция известна как кумулятивная функция распределения ((CDF)).
Поскольку мы не можем решить интеграл, мы не можем вывести функцию распределения, и поэтому снова оказываемся в тупике. Умные математики решили и эту задачу и смогли использовать тригонометрию (в частности, преобразование Бокса-Мюллера) для преобразования равномерно распределенных случайных величин в нормально распределенные случайные величины.
Но вот в чем загвоздка: в реальном мире байесовской статистики и машинного обучения мы имеем дело со сложными многомерными распределениями, где:
- Мы не можем решить интеграл аналитически.
- Следовательно, мы не можем найти константу нормировки (C).
- Наконец, без интеграла мы не можем вычислить функцию распределения вероятностей, поэтому стандартная выборка не работает.
Мы оказались в ситуации, когда используем ненормированную формулу и нет способа вычислить общую площадь. Вот тут-то и пригодится метод Монте-Карло с цепями Маркова (MCMC). Методы MCMC позволяют нам производить выборку из этих распределений, не решая этот невозможный интеграл.
Введение
Марковский процесс однозначно определяется его вероятностями перехода (P(xrightarrow x')).
Например, в системе с (4) состояниями:
[P(xrightarrow x') = begin{bmatrix} 0.5 & 0.3 & 0.05 & 0.15 \ 0.2 & 0.4 & 0.1 & 0.3 \ 0.4 & 0.4 & 0 & 0.2 \ 0.1 & 0.8 & 0.05 & 0.05 end{bmatrix}]
Вероятность перехода из любого состояния (x) в (x') определяется элементом (i rightarrow j) в матрице.
Посмотрите, например, на третью строку: ([0.4,0.4,0,0.2]).
Это означает, что если система в данный момент находится в состоянии (3), то у нее есть 40%-ный шанс перейти в состояние (1), 40%-ный шанс перейти в состояние (2), 0%-ный шанс остаться в состоянии (3) и 20%-ный шанс перейти в состояние (4).
Матрица отображает каждый возможный путь с соответствующими вероятностями. Обратите внимание, что сумма значений каждой строки (i) равна (1), так что наша матрица переходов представляет собой допустимые вероятности.
Марковский процесс также требует начального распределения состояний (pi_0) (начинаем ли мы в состоянии (1) с вероятностью (100%) или в любом из (4) состояний с вероятностью (25%) каждое?).
Например, это может выглядеть так:
[pi_0 = begin{bmatrix} 0.4 & 0.15 & 0.25 & 0.2 end{bmatrix}]
Это просто означает, что вероятность начала из состояния (1) составляет (0,4), из состояния (2) — (0,15) и так далее.
Чтобы найти распределение вероятностей того, где система окажется после первого шага (t_0 + 1), мы умножаем начальное распределение на вероятности перехода:
[ pi_1 = pi_0P]
Умножение матриц фактически дает нам вероятность всех возможных путей достижения состояния (j) путем суммирования всех индивидуальных вероятностей достижения состояния (j) из различных начальных состояний (i).
Почему это работает
Используя матричное умножение, мы исследуем все возможные пути к месту назначения и суммируем их вероятности.
Обратите внимание, что эта операция также прекрасно сохраняет требование, согласно которому сумма вероятностей нахождения в состоянии всегда будет равна (1).
Стационарное распределение
Правильно построенный марковский процесс достигает состояния равновесия, когда число шагов (t) стремится к бесконечности:
[pi^* P = pi^*]
Такое состояние известно как глобальное равновесие.
(pi^*) известно как стационарное распределение и представляет собой момент времени, когда распределение вероятностей после перехода ((pi^*P)) идентично распределению вероятностей до перехода ((pi^*)).
Наличие такого состояния является основой любого метода MCMC.
При выборке целевого распределения с использованием стохастического процесса мы спрашиваем не «Куда дальше?», а «Куда мы в итоге придем?». Чтобы ответить на этот вопрос, нам необходимо ввести в систему долгосрочную предсказуемость.
Это гарантирует существование теоретического состояния (t), в котором вероятности «стабилизируются», а не будут изменяться случайным образом на протяжении всей вечности. Точка, в которой они «стабилизируются», — это точка, в которой мы надеемся начать выборку из нашего целевого распределения.
Таким образом, для эффективной оценки распределения вероятностей с использованием марковского процесса необходимо обеспечить следующее:
- Существует стационарное распределение.
- Это стационарное распределение является единственным, иначе мы могли бы иметь несколько состояний равновесия в пространстве, далеком от целевого распределения.
Математические ограничения, накладываемые алгоритмом, обеспечивают выполнение марковским процессом этих условий, что является центральным элементом всех методов MCMC. Способы достижения этого могут различаться.
Уникальность
В общем случае, для гарантии единственности стационарного распределения необходимо выполнить три условия. Разверните раздел ниже, чтобы увидеть их:
Святая Троица
- Неприводимая система: Система неприводима, если в любом состоянии (x) существует ненулевая вероятность посещения любой точки (x') в пространстве элементарных исходов. Проще говоря, из любого состояния A в любое состояние B можно в конечном итоге попасть.
- Апериодичность: Система не должна возвращаться в определенное состояние через фиксированные интервалы времени. Достаточным условием апериодичности является существование хотя бы одного состояния, в котором вероятность пребывания в нем отлична от нуля.
- Положительная рекуррентность: Состояние (x) является положительно рекуррентным, если, начиная с этого состояния, система гарантированно вернется в него, а среднее число шагов, необходимых для возвращения, конечно. Это обеспечивается моделированием целевой функции, имеющей конечный интеграл и являющейся корректным распределением вероятностей (сумма площадей под кривой должна равняться (1)).
Любая система, удовлетворяющая этим условиям, называется эргодической системой. Таблицы в конце статьи показывают, как алгоритм Менделеева-Хилла обеспечивает эргодичность и, следовательно, единственность решения.
Метрополис-Гастингс
Алгоритм MH начинает с определения детального равновесия — достаточного, но необходимого условия для глобального равновесия. Проще говоря, если наш алгоритм удовлетворяет условию детального равновесия, мы гарантируем, что наша симуляция будет иметь стационарное распределение.
Вывод
Определение детального баланса:
[pi(x) P(x'|x) = pi(x') P(x|x') ,]
Это означает, что поток вероятностей перехода от (x) к (x') совпадает с потоком вероятностей перехода от (x') к (x).
Идея состоит в том, чтобы найти стационарное распределение путем итеративного построения матрицы переходов (P(x',x)), установив (pi) в качестве целевого распределения (P(x)), из которого мы хотим производить выборку.
Для реализации этого мы разложим вероятность перехода (P(x'|x)) на два отдельных шага:
- Предложение ((g)): Вероятность предложения перемещения в (x') при условии, что мы находимся в (x).
- Принятие ((A)): Функция принятия показывает вероятность принятия предложения.
Таким образом,
[P(x'|x) = g(x'|x) a(x',x)]
Поправка Гастингса
Подставив эти значения обратно в приведенное выше уравнение, получаем:
[frac{pi(x)}{pi(x')} = frac{g(x|x') a(x,x')}{g(x'|x) a(x',x)}]
И наконец, после преобразования мы получаем выражение для нашего принятия в виде отношения:
[frac{a(x',x)}{a(x,x')} = frac{g(x|x')pi(x')}{g(x'|x)pi(x)}]
Этот коэффициент показывает, насколько вероятнее мы примем предложение о переезде в (x') по сравнению с предложением вернуться в (x).
Член (frac{g(x|x')pi(x')}{g(x'|x)pi(x)}) известен как поправка Гастингса.
Важное примечание
Поскольку мы часто выбираем симметричное распределение для предложения, вероятность перехода из (x rightarrow x') такая же, как и вероятность перехода из (x' rightarrow x). Следовательно, члены предложения взаимно компенсируются, оставляя только отношение плотностей целевых значений.
Этот частный случай, когда предложение симметрично и члены (g) исчезают, исторически известен как алгоритм Метрополиса (1953) . Более общая версия, допускающая асимметричные предложения (требующая коэффициента (g) – известного как поправка Гастингса), – это алгоритм Метрополиса-Гастингса (1970) .
Прорыв
Вспомним исходную задачу: мы не можем вычислить (pi(x)), потому что нам неизвестна константа нормировки (C) (интеграл).
Однако, внимательно рассмотрим отношение (frac{pi(x')}{pi(x)}). Если мы разложим (pi(x)) на его ненормированную плотность (f(x)) и константу (C):
[frac{pi(x')}{pi(x)} = frac{{f(x')} / C}{f(x) / C} = frac{f(x')}{f(x)}]
Константа (C) сокращается!
Это настоящий прорыв. Теперь мы можем производить выборку из комплексного распределения, используя только ненормированную плотность (которая нам известна) и предлагаемое распределение (которое мы выбираем сами).
Остается лишь найти функцию принятия (A), которая будет удовлетворять условию детального баланса:
[frac{a(x',x)}{a(x,x')} = R ,]
где (R) представляет собой (frac{g(x|x')pi(x')}{g(x'|x)pi(x)}).
Принятие метрополии
В алгоритме используется следующая функция принятия:
[a(x',x) = min(1,R)]
Это гарантирует, что вероятность принятия всегда будет находиться в диапазоне от (0) до (1).
Чтобы понять, почему этот выбор удовлетворяет условию детального равновесия, мы должны убедиться, что уравнение справедливо и для обратного хода. Нам нужно проверить, что:
[frac{a(x',x)}{a(x,x')} = R,]
в двух случаях:
Случай I: Ход выгоден ((R ge 1))
Поскольку (R ge 1), обратное (frac{1}{R} le 1):
- Наше прямое принятие равно (a(x',x) = min(1,R) = 1)
- Наше обратное принятие равно (a(x,x') = min(1,frac{1}{R}) = frac{1}{R})
[frac{1}{a(x,x')} = R]
[frac{1}{frac{1}{R}} = R]
Случай II: Этот ход невыгоден ((R < 1))
Поскольку (R < 1), обратное (frac{1}{R} > 1):
- Наше прямое принятие равно (a(x',x) = min(1,R) = R)
- Наше обратное принятие равно (a(x,x') = min(1,frac{1}{R}) = 1)
Таким образом:
[frac{R}{a(x,x')} = R]
[frac{R}{1} = R,]
и равенство выполняется в обоих случаях.
Выполнение
Давайте реализуем алгоритм MH на python на двух примерах целевых распределений.
I. Оценка гауссова распределения
Если мы построим график распределения выборок относительно истинного нормального распределения, то получим следующее:
: Алгоритм Метрополиса-Хастингса 2")
Возможно, вы задаетесь вопросом, зачем мы вообще использовали метод MCMC для того, что можно сделать с помощью np.random.normal(n_iterations) . И это вполне обоснованный вопрос! На самом деле, для одномерного гауссова распределения решение с обратным преобразованием (с использованием тригонометрии) гораздо эффективнее, и именно его использует numpy .
Но по крайней мере, мы знаем, что наш код работает! Теперь давайте попробуем что-нибудь поинтереснее.
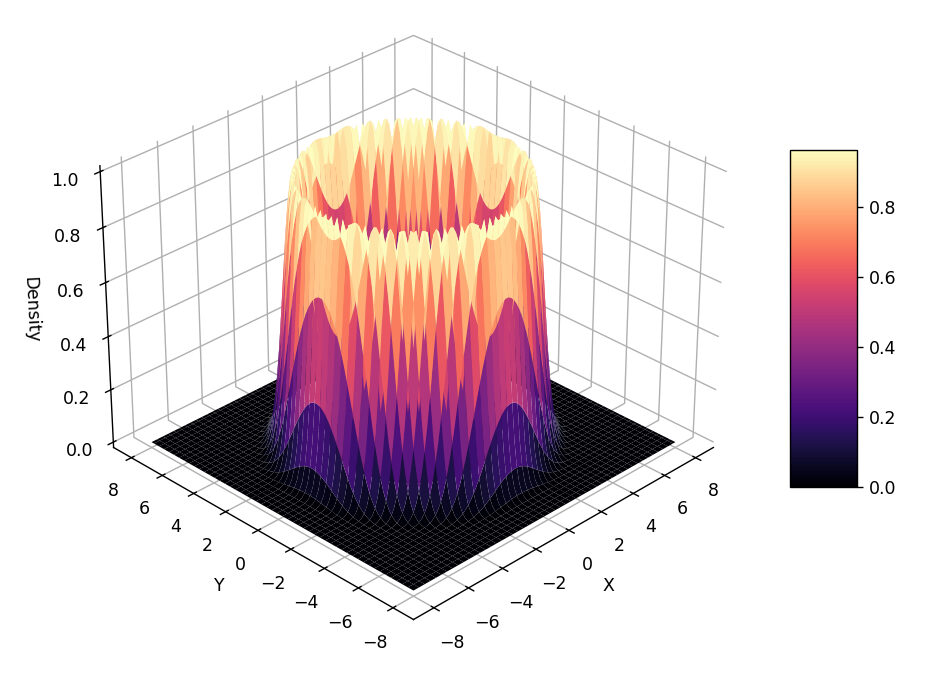
II. Оценка распределения «вулканов»
Давайте попробуем взять выборку из гораздо менее «стандартного» распределения, построенного в двумерном пространстве, где третье измерение представляет плотность распределения.
Поскольку выборка происходит в двумерном пространстве (алгоритм знает только координаты xy а не «наклон» вулкана), мы получаем красивое кольцо вокруг жерла вулкана.
: Алгоритм Метрополиса-Хастингса 3")
Краткое изложение математических условий для MCMC
Теперь, когда мы рассмотрели базовую реализацию, вот краткое изложение математических условий, необходимых для фактической работы метода MCMC:
| Состояние | Механизм |
|---|---|
| Стационарное распределение (Существует набор вероятностей, которые, будучи достигнутыми, не изменятся.) | Детальный баланс Алгоритм разработан таким образом, чтобы удовлетворять уравнению детального баланса. |
| Конвергенция (Гарантируя, что цепь в конечном итоге сойдется к стационарному распределению.) | Эргодичность Система должна удовлетворять условиям, указанным в таблице 2, и быть эргодической. |
| Уникальность стационарного распределения (Существует только одно решение уравнения детального баланса) | Эргодичность Гарантировано, если система является эргодической. |
Вот как алгоритм MH удовлетворяет требованиям эргодичности:
| Состояние | Механизм |
|---|---|
| 1. Неприводимый (Возможность добраться из любого другого штата в любой другой.) | Функция подачи предложений Часто это условие выполняется с помощью предложения (например, гауссова распределения), вероятность которого не равна нулю повсюду. Примечание: если переходы в некоторые области невозможны, это условие не выполняется. |
| 2. Апериодические (Система не зацикливается.) | Этап отклонения «Подбрасывание монеты» позволяет нам отклонить предложенное изменение и остаться в том же состоянии, нарушая любую периодичность, которая могла возникнуть. |
| 3. Положительный рецидив (Ожидаемое время возврата в любое состояние конечно.) | Правильное распределение вероятностей Это гарантируется тем фактом, что мы моделируем целевое значение как корректное распределение (т.е., его интеграл/сумма равна (1)). |
Заключение
В этой статье мы рассмотрели, как метод Монте-Карло с цепями Маркова помогает решить две основные проблемы выборки из распределения, имеющего только его ненормированную функцию плотности (функцию правдоподобия):
- Проблема нормализации : Чтобы распределение являлось допустимым распределением вероятностей, сумма площадей под кривой должна равняться (1). Для этого необходимо вычислить общую площадь под кривой, а затем разделить ненормированные значения на эту константу. Вычисление площади включает интегрирование комплексной функции, и в случае нормального распределения, например, аналитического решения не существует.
- Задача обращения интеграла : Чтобы получить выборку, нам нужно выбрать случайную вероятность и определить, какому значению (x) соответствует эта область? Для этого нам нужно не только решить интеграл, но и обратить его. А поскольку мы не можем записать интеграл, решить его обратный интеграл невозможно.
Методы MCMC, начиная с алгоритма Метрополиса-Гастингса, позволяют нам обходить эти неразрешимые математические задачи, используя хитрые случайные блуждания и коэффициенты принятия решений.
Для более надежной реализации алгоритма Метрополиса-Хастингса и примера выборки с использованием асимметричного предложения (с применением поправки Хастингса) ознакомьтесь с кодом go здесь.
Что дальше?
Мы успешно провели выборку из комплексного двумерного распределения, ни разу не вычисляя интеграл. Однако, если вы посмотрите на код алгоритма Метрополиса-Хастингса, вы заметите, что наш шаг генерации предложений по сути представляет собой слепое случайное предположение ( np.random.normal ).
В низкоразмерных пространствах метод угадывания работает. Но в многомерных пространствах современных байесовских методов случайное угадывание подобно попытке получить более выгодную ставку от ростовщика — почти каждое ваше предложение будет отклонено.
Во второй части мы представим алгоритм Гамильтоновского Монте-Карло (ГМК) , который позволяет эффективно исследовать многомерное пространство, используя геометрию распределения в качестве ориентира.
Аднан Шахбааз Посмотреть все работы Аднана Шахбааза
Источник: towardsdatascience.com