
Сравните ViT, DETR, BLIP, ViLT для классификации изображений, сегментации, создания субтитров и визуального ответа на вопросы.
Делиться

Что такое компьютерное зрение и модель зрения?
Computer Vision — это подобласть искусственного интеллекта с широким спектром приложений, ориентированных на обработку и понимание изображений. Традиционно применяемая с помощью сверточных нейронных сетей (CNN), эта область претерпела революцию с появлением архитектуры трансформаторов. Хотя трансформаторы хорошо известны своими приложениями в обработке языка, их можно эффективно адаптировать для формирования основы многих моделей зрения. В этой статье мы рассмотрим самые современные модели зрения и многомодальные модели, такие как ViT (Vision Transformer), DETR (Detection Transformer), BLIP (Boostrapping Language-Image Pretraining) и ViLT (Vision Language Transformer) , которые специализируются на различных задачах компьютерного зрения, включая классификацию изображений, сегментацию, преобразование изображений в текст и визуальные ответы на вопросы . Эти задачи имеют множество реальных приложений: от аннотирования изображений в масштабе, обнаружения отклонений на медицинских изображениях до извлечения текста из документов и генерации текстовых ответов на основе визуальных данных.
Сравнения с CNN
До широкого внедрения базовых моделей сверточные нейронные сети (СНС) были доминирующим решением для большинства задач компьютерного зрения. Вкратце, СНС образуют иерархическую архитектуру глубокого обучения, состоящую из карт признаков, пулинга, линейных и полностью связанных слоёв. В отличие от них, трансформеры зрения используют механизм самовосприятия, позволяющий фрагментам изображения «сфокусироваться» друг на друге. Они также обладают меньшим индуктивным смещением, то есть они менее ограничены конкретными предположениями модели, чем СНС, но, следовательно, требуют значительно больше обучающих данных для достижения высокой производительности при выполнении обобщённых задач.
Сравнение с LLM
Модели машинного зрения на базе преобразователя адаптируют архитектуру, используемую LLM (большими языковыми моделями), добавляя дополнительные слои, которые преобразуют данные изображений в числовые вложения. В задаче обработки естественного языка текстовые последовательности проходят процесс токенизации и встраивания, прежде чем они будут обработаны преобразователем. Аналогичным образом, данные изображений/визуальных данных проходят процедуру патчинга, кодирования позиции и встраивания изображения перед подачей в преобразователь машинного зрения. В этой статье мы подробнее рассмотрим, как преобразователь машинного зрения и его варианты опираются на базовую модель преобразователя и расширяют возможности от обработки языка до понимания и генерации изображений.
Расширения мультимодальных моделей
Развитие моделей машинного зрения обусловило интерес к разработке мультимодальных моделей, способных одновременно обрабатывать как изображения, так и текстовые данные. В то время как модели машинного зрения ориентированы на однонаправленное преобразование изображений в числовые данные и обычно выдают результаты на основе оценок для классификации или обнаружения объектов (т.е. задачи классификации и сегментации изображений), мультимодальные модели требуют двунаправленной обработки и интеграции различных типов данных. Например, мультимодальная модель «изображение-текст» может генерировать связные текстовые последовательности из входных изображений для задач создания подписей к изображениям и решения задач визуального ответа на вопросы.
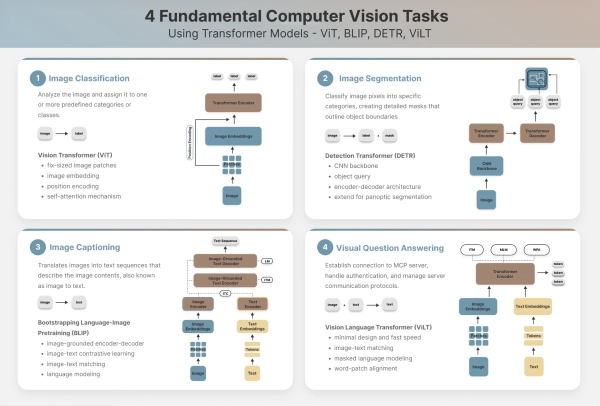
4 типа фундаментальных задач компьютерного зрения
0. Обзор проекта
Мы подробно рассмотрим эти четыре фундаментальные задачи компьютерного зрения и соответствующие модели преобразователей, специализированные для каждой из них. Эти модели различаются, главным образом, архитектурой кодера и декодера, что обеспечивает им уникальные возможности для интерпретации, обработки и перевода различных текстовых и визуальных модальностей.

Чтобы сделать это руководство более интерактивным, я разработал веб-приложение Streamlit для иллюстрации и сравнения результатов выполнения этих задач и моделей компьютерного зрения. В конце статьи мы рассмотрим весь процесс разработки приложения.
Ниже представлен краткий обзор выходных данных, основанных на загруженном изображении, отображающий имя задачи, выходные данные, время выполнения, имя модели, тип модели с использованием моделей по умолчанию из конвейеров Hugging Face.

1. Классификация изображений

Во-первых, давайте рассмотрим классификацию изображений — базовую задачу компьютерного зрения, которая присваивает изображениям предопределенный набор меток. Эту задачу можно выполнить с помощью простого Vision Transformer.
ViT (Трансформатор зрения)

Vision Transformer (ViT) служит краеугольным камнем многих моделей компьютерного зрения, представленных далее в этой статье. Благодаря своей архитектуре преобразователя, использующей только кодировщик, он стабильно превосходит сверточные нейронные сети в задачах классификации изображений. Он обрабатывает входные данные изображений и выдаёт оценки вероятности для меток-кандидатов. Поскольку классификация изображений — это исключительно задача распознавания изображений без необходимости генерации, архитектура ViT, использующая только кодировщик, хорошо подходит для этой цели.
Архитектура ViT состоит из следующих компонентов:
- Патчинг: разбить входные изображения на небольшие фрагменты пикселей фиксированного размера (обычно 16×16 пикселей на фрагмент), чтобы сохранить локальные особенности для последующей обработки.
- Встраивание: преобразование фрагментов изображения в числовые представления, также известные как векторные встраивания, чтобы изображения со схожими характеристиками проецировались как встраивания с большей близостью в векторном пространстве.
- Токен классификации (CLS): извлекает и объединяет информацию из всех участков изображения в одно числовое представление, что делает его особенно эффективным для классификации.
- Кодирование позиции: сохранение относительного положения пикселей исходного изображения. Токен CLS всегда находится в позиции 0.
- Transformer Encoder: обрабатывает вложения через слои многонаправленных сетей внимания и прямой связи.
Механизм ViT обеспечивает эффективность захвата глобальных зависимостей, в то время как CNN в основном полагается на локальную обработку посредством сверточных ядер. С другой стороны, ViT имеет недостаток, заключающийся в необходимости огромного объёма обучающих данных (обычно миллионов изображений) для итеративной настройки параметров модели в слоях внимания для достижения высокой эффективности.
Если вы предпочитаете видеообзор этого руководства, посмотрите наше видео на YouTube 🎬.
Выполнение
Конвейер Hugging Face значительно упрощает реализацию задачи классификации изображений, абстрагируя низкоуровневые этапы обработки изображений.
из трансформаторов импорт трубопровода из PIL импорт изображения изображение = Image.open(image_url) труба = трубопровод(task=»image-classification», model=model_id) вывод = труба(image=image)
- входные параметры:
- модель: вы можете выбрать собственную модель или использовать модель по умолчанию (например, «google/vit-base-patch16-224»), если параметр модели не указан.
- задача: укажите название задачи (например, «классификация изображений», «сегментация изображений»)
- изображение: предоставить объект изображения через URL-адрес или путь к файлу изображения.
- выход: модель генерирует оценки для меток-кандидатов.
Мы сравнили результаты стандартной модели классификации изображений «google/vit-base-patch16-224», предоставив два похожих изображения с разной композицией. Как видим, эту базовую модель легко спутать, выдавая существенно разные результаты («espresso» и «mircowave»), несмотря на то, что оба изображения содержат один и тот же основной объект.
Вывод изображения «Кофейная кружка»

[ { «label»: «эспрессо», «оценка»: 0,40687331557273865 }, { «label»: «чашка», «оценка»: 0,2804579734802246 }, { «label»: «кружка кофе», «оценка»: 0,17347976565361023 }, { «label»: «стол», «оценка»: 0,01198530849069357 }, { «label»: «эгг-ног», «оценка»: 0,00782513152807951 } ]
Вывод изображения «Кофейная кружка с фоном»

[ { «label»: «микроволновая печь», «оценка»: 0,20218633115291595 }, { «label»: «обеденный стол», «оценка»: 0,14855517446994781 }, { «label»: «плита», «оценка»: 0,1345038264989853 }, { «label»: «раздвижная дверь», «оценка»: 0,10262308269739151 }, { «label»: «сёдзи», «оценка»: 0,07306522130966187 } ]
Попробуйте другую модель самостоятельно, используя наше веб-приложение Streamlit, и посмотрите, даст ли она лучшие результаты.
2. Сегментация изображения

Сегментация изображений — ещё одна распространённая задача компьютерного зрения, требующая модели, основанной только на зрении. Задача аналогична задаче обнаружения объектов, но требует более высокой точности на уровне пикселей: создание масок для границ объектов вместо рисования ограничивающих рамок, как это требуется для обнаружения объектов.
Существует три основных типа сегментации изображений:
- Семантическая сегментация: прогнозирование маски для каждого класса объектов.
- Сегментация экземпляров: прогнозирование маски для каждого экземпляра класса объектов.
- Паноптическая сегментация: объединение сегментации экземпляров и семантической сегментации путем назначения каждому пикселю класса объекта и экземпляра этого класса.
DETR (трансформатор обнаружения)

Хотя DETR широко используется для обнаружения объектов, его можно расширить для выполнения задач паноптической сегментации, добавив головку сегментационной маски. Как показано на схеме, она использует архитектуру преобразователя кодер-декодер с опорной сетью CNN для извлечения карты признаков. Модель DETR изучает набор запросов к объектам и обучается прогнозировать ограничивающие рамки для этих запросов, после чего добавляет головку прогнозирования маски для выполнения точной сегментации на уровне пикселей.
Mask2Former
Mask2Former также часто используется для сегментации изображений. Разработанный Facebook AI Research, Mask2Former в целом превосходит модели DETR, демонстрируя более высокую точность и вычислительную эффективность. Это достигается за счёт применения механизма маскированного внимания вместо глобального перекрёстного внимания, что позволяет сосредоточиться исключительно на информации переднего плана и основных объектах изображения.
Выполнение
Мы используем конвейерную реализацию так же, как и при классификации изображений, просто заменив параметр задачи на «image-segmentation». Для обработки выходных данных мы извлекаем метки и маски объектов, а затем отображаем замаскированное изображение с помощью st.image().
из transformers import pipeline из PIL import Image import streamlit as st image = Image.open(image_url) pipe = pipeline(task=»image-segmentation», model=model_id) output = pipe(image=image) output_labels = [i['label'] for i in output] output_masks = [i['mask'] for i in output] for m in output_masks: st.image(m)
Мы сравнили производительность DETR («facebook/detr-resnet-50-panoptic») и Mask2Former («facebook/mask2former-swin-base-coco-panoptic»), которые оба точно настроены на паноптическую сегментацию. Как видно из результатов сегментации, DETR и Mask2Former успешно идентифицируют и извлекают «чашку» и «обеденный стол». Mask2Former делает выводы быстрее (2,47 с против 6,3 с у DETR), а также выделяет «окно-другое» из фона.
Вывод DETR «facebook/detr-resnet-50-panoptic»
[ { 'score': 0.994395, 'label': 'обеденный стол', 'mask':

Вывод Mask2Former «facebook/mask2former-swin-base-coco-panoptic»
[ { 'score': 0.999554, 'label': 'cup', 'mask':

3. Подписи к изображениям

Создание субтитров изображений, также известное как преобразование изображений в текст, преобразует изображения в текстовые последовательности, описывающие их содержимое. Эта задача требует как понимания изображений, так и генерации текста, поэтому хорошо подходит для мультимодальной модели, способной одновременно обрабатывать изображения и текст.
Визуальный кодер-декодер
Визуальный кодер-декодер — это многомодальная архитектура, сочетающая модель зрительного восприятия для понимания изображений с предобученной языковой моделью для генерации текста. Типичным примером является ViT-GPT2, которая объединяет Vision Transformer (представленный в разделе 1. Классификация изображений) в качестве визуального кодера и модель GPT-2 в качестве декодера для авторегрессионной генерации текста.
BLIP (усиливающее предварительное обучение языкам и образам)

Технология BLIP, разработанная Salesforce Research, использует четыре основных модуля: кодировщик изображений, кодировщик текста, а затем кодировщик текста, основанный на изображении, который объединяет визуальные и текстовые характеристики посредством механизмов внимания, а также декодер текста, основанный на изображении, для генерации текстовых последовательностей. Процесс предварительной подготовки включает минимизацию потерь контрастности изображения и текста, потерь сопоставления изображения и текста и потерь языкового моделирования с целью выравнивания семантических связей между визуальной информацией и текстовыми последовательностями. Она обеспечивает большую гибкость в приложениях и может применяться для визуального анализа вопросов (VQA), но также повышает сложность архитектурного проектирования.
Выполнение
Мы используем приведенный ниже фрагмент кода для генерации выходных данных из конвейера создания субтитров изображений.
из трансформаторов импорт трубопровода из PIL импорт изображения изображение = Image.open(image_url) труба = трубопровод(task=»image-to-text», model=model_id) вывод = труба(image=image)
Мы опробовали три различные модели, представленные ниже, и все они генерируют достаточно точные описания изображений, причем более крупная модель работает лучше базовой.
Вывод визуального кодировщика-декодера «ydshieh/vit-gpt2-coco-en»
[{'generated_text': 'чашка кофе стоит на деревянном столе'}]
Вывод BLIP «Salesforce/blip-image-captioning-base»
[{'generated_text': 'чашка кофе на столе'}]
Вывод BLIP «Salesforce/blip-image-captioning-large»
[{'generated_text': 'на столе на блюдце стоит чашка кофе'}]
4. Визуальные ответы на вопросы

Визуальный вопросно-ответный подход (VQA) приобретает всё большую популярность, поскольку позволяет пользователям задавать вопросы по изображению и получать связные текстовые ответы. Для него также требуется мультимодальная модель, способная извлекать ключевую информацию из визуальных данных, а также генерировать текстовые ответы. От субтитров изображений он отличается тем, что принимает в качестве входных данных не только изображение, но и подсказки пользователя, поэтому требует кодировщика, который интерпретирует обе модальности одновременно.
ViLT (преобразователь языка видения)

ViLT — это вычислительно эффективная архитектура модели для выполнения задачи VQA. ViLT объединяет встраивание фрагментов изображений и текста в унифицированный преобразователь-кодер, предварительно обученный для решения трёх задач:
- Сопоставление изображения и текста: изучение семантической связи между парами «изображение-текст»
- Моделирование замаскированного языка: научитесь предсказывать замаскированное слово/токен из словарного запаса на основе входного текста и изображения
- выравнивание фрагментов слов: изучите ассоциации между словами и фрагментами изображений
ViLT использует архитектуру, основанную только на кодере, с головками, ориентированными на конкретные задачи (например, головкой классификации, головкой VQA). Эта минимальная конструкция обеспечивает в десять раз более высокую скорость, чем модель VLP (Vision-and-Language Pretraining), которая использует контроль областей для обнаружения объектов и свёрточную архитектуру для извлечения признаков. Однако эта упрощённая архитектура приводит к неоптимальной производительности при решении сложных задач и требует больших объёмов обучающих данных для достижения обобщённой функциональности. Как будет показано далее, одним из недостатков модели ViLT является то, что она выдаёт для VQA результаты на основе токенов, а не связных предложений, что очень похоже на задачу классификации изображений с большим количеством возможных меток.
БЛИП
Как было отмечено в разделе 3. «Подписи к изображениям», BLIP — это более обширная модель, которую также можно настроить для решения задач визуального ответа на вопросы. Благодаря архитектуре кодер-декодер она генерирует полные текстовые последовательности, а не токены.
Выполнение
VQA реализован с использованием приведенного ниже фрагмента кода, при этом в качестве входных данных модели используются изображение и текстовая подсказка.
из transformers import pipeline из PIL import Image import streamlit as st image = Image.open(image_url) question='describe this image' pipe = pipeline(task=»image-to-text», model=model_id, question=question) output = pipe(image=image)
При сравнении моделей ViLT и BLIP для вопроса «Опишите это изображение» результаты существенно различаются из-за различий в архитектуре моделей. ViLT предсказывает токены с наивысшей оценкой, используя свой существующий словарь, в то время как BLIP генерирует более связные и осмысленные результаты.
Вывод ViLT «dandelin/vilt-b32-finetuned-vqa»
[ { «счет»: 0,044245753437280655, «ответ»: «кухня» }, { «счет»: 0,03294338658452034, «ответ»: «чай» }, { «счет»: 0,030773703008890152, «ответ»: «стол» }, { «счет»: 0,024886665865778923, «ответ»: «офис» }, { «счет»: 0,019653357565402985, «ответ»: «чашка» } ]
Вывод BLIP «Salesforce/blip-vqa-capfilt-large»
[{'answer': 'чашка кофе на блюдце'}]
Источник: towardsdatascience.com

























