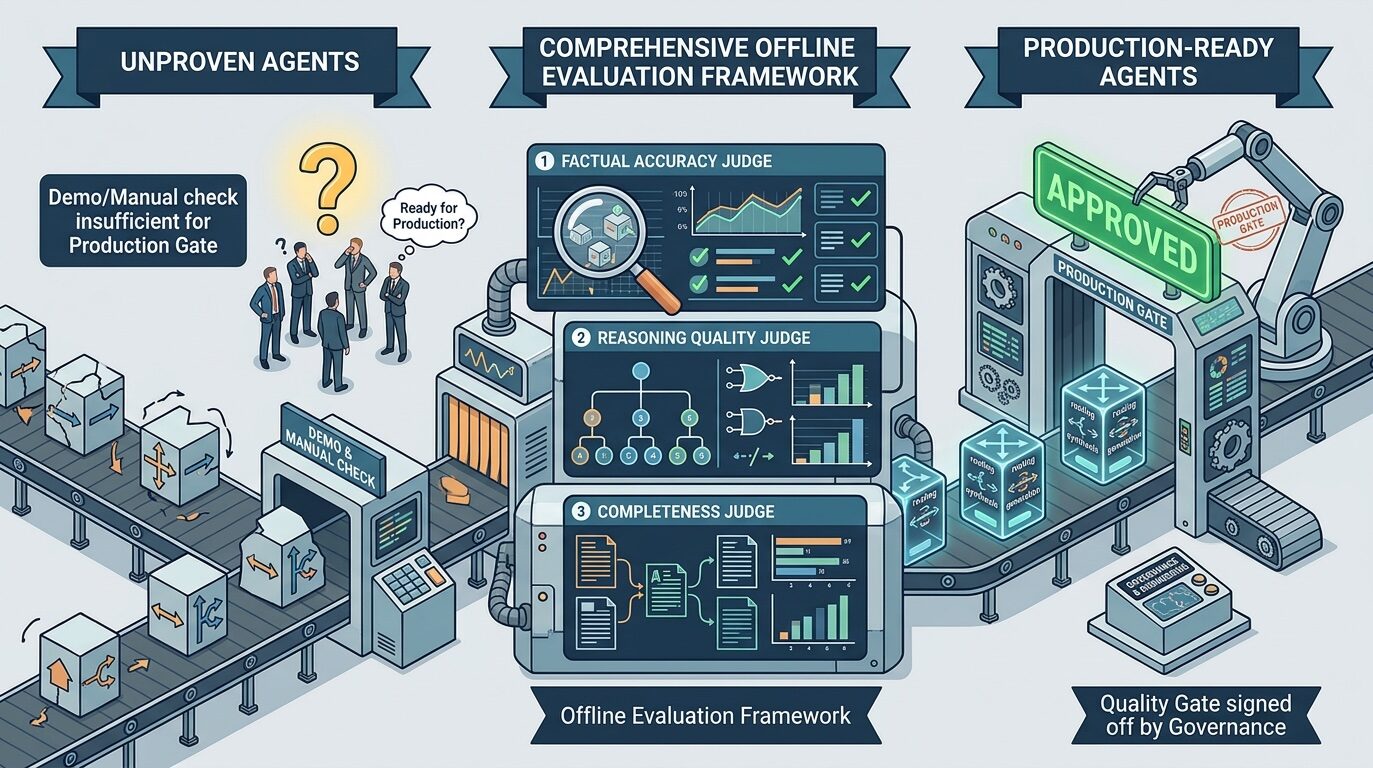
Мы достигли замечательных успехов в создании сложных агентских систем, но нам не хватает той же строгости в доказательстве их работоспособности.
Делиться

Введение и контекст
В прошлом году я наблюдал, как хорошо финансируемая команда разработчиков ИИ демонстрировала исполнительному комитету свою многоагентную финансовую систему-помощника. Система произвела впечатление — она интеллектуально маршрутизировала запросы, извлекала необходимые документы и генерировала четкие ответы. Все кивнули. Бюджеты были утверждены. Затем кто-то спросил: «Как мы узнаем, что она готова к внедрению в производство?» В зале воцарилась тишина.
Подобная ситуация часто встречается в отрасли. Мы достигли невероятных успехов в создании сложных систем агентов, но не выработали такой же строгости в доказательстве их работоспособности. Когда я спрашиваю команды, как они проверяют свои агенты перед развертыванием, я обычно слышу комбинацию фраз: «Мы тестировали вручную», «Демонстрация прошла хорошо» и «Мы будем отслеживать это в производственной среде». Ни одна из этих фраз не является неправильной, но ни одна из них не представляет собой контроль качества, который может быть одобрен руководством или автоматизирован инженерами.
Проблема: Оценка недетерминированных многоагентных систем
Проблема не в том, что командам безразлично качество — оно важно. Проблема в том, что оценка систем на основе LLM действительно сложна, а многоагентные архитектуры делают её ещё сложнее.
Традиционное тестирование программного обеспечения предполагает детерминизм. Имея входные данные X, мы ожидаем выходные данные Y и пишем утверждение для их проверки. Но если мы зададим один и тот же вопрос магистру права дважды, мы получим разные формулировки, разные структуры, иногда разный акцент. Оба ответа могут быть правильными. Или один из них может быть слегка неверным, что неочевидно без экспертных знаний в данной области. Основанная на утверждениях ментальная модель рушится.
Теперь умножьте эту сложность на многоагентную систему. Агент-маршрутизатор решает, какой специалист обработает запрос. Этот специалист может получать документы из базы знаний. Полученный контекст формирует сгенерированный ответ. Сбой в любой точке этой цепочки ухудшает качество выходных данных, но для диагностики того, где произошла ошибка, необходимо оценить каждый компонент.
Я заметил, что командам необходимо ответить на три разных вопроса, прежде чем они смогут уверенно внедрить систему:
- Выполняет ли маршрутизатор свою работу? Когда пользователь задает простой вопрос, попадает ли он к быстрому и недорогому оператору? Когда он задает сложный вопрос, перенаправляет ли его к оператору с более широкими возможностями? Ошибки в этом вопросе имеют реальные последствия — либо вы тратите деньги и время на излишне сложные ответы, либо даете пользователям поверхностные ответы на вопросы, которые заслуживают более глубокого анализа.
- Действительно ли ответы качественные? Это звучит очевидно, но понятие «качественный» имеет множество аспектов. Является ли информация точной? Если агент проводит анализ, насколько обоснованы его рассуждения? Если он генерирует отчет, является ли он полным? Для разных типов запросов требуются разные критерии качества.
- Для агентов, использующих поиск информации, работает ли конвейер RAG? Правильно ли мы получили необходимые документы? Действительно ли агент использовал их, или же он получил ложную информацию, которая звучит правдоподобно, но не соответствует контексту полученной информации?
Офлайн и онлайн: краткое различие
Прежде чем перейти к описанию структуры, я хочу уточнить, что я подразумеваю под «офлайн-оценкой», поскольку эта терминология может вызывать путаницу.
Автономная оценка проводится перед развертыванием на специально подобранном наборе данных, где известны ожидаемые результаты. Тестирование проходит в контролируемой среде без влияния на пользователей. Это ваш контрольный пункт качества — точка, определяющая, готова ли версия модели к использованию в производстве.
Онлайн-оценка проводится после развертывания, в условиях реального трафика. Вы отслеживаете реальные взаимодействия пользователей, выбираете ответы для проверки качества, выявляете отклонения. Это ваша страховка — постоянная гарантия того, что поведение в рабочей среде соответствует ожиданиям.
Оба метода важны, но служат разным целям. Эта статья посвящена офлайн-оценке, поскольку именно здесь, на мой взгляд, наблюдается наибольший пробел в современной практике. Команды часто сразу переходят к принципу «мы будем отслеживать это в рабочей среде», не определив заранее, что именно означает «хорошее» качество. Это неправильный подход. Офлайн-оценка необходима для определения базового уровня качества, прежде чем онлайн-оценка сможет показать, поддерживается ли он на должном уровне.
План развития статьи
Здесь я представлю разработанную и усовершенствованную мной структуру, созданную на основе множества развертываний агентов. Я рассмотрю эталонную архитектуру, иллюстрирующую распространенные проблемы оценки, а затем представлю то, что я называю тремя столпами автономной оценки — маршрутизация, LLM-как-судья и оценка RAG. Для каждого столпа я объясню не только что измерять, но и почему это важно и как интерпретировать результаты. Наконец, я расскажу о том, как внедрить автоматизацию (CI/CD) и связать ее с требованиями управления.
Система, подлежащая оценке
Эталонная архитектура
Чтобы сделать это более наглядным, приведу пример, который становится все более распространенным в современных условиях. Компания, предоставляющая финансовые услуги, модернизирует свои инструменты и сервисы, поддерживающие консультантов, работающих с конечными клиентами. Одним из таких приложений является помощник по финансовым исследованиям, способный находить финансовые инструменты, проводить различные анализы и детальные исследования.

Эта система спроектирована как многоагентная, где разные агенты используют разные модели в зависимости от потребностей и сложности задачи. Агент-маршрутизатор находится на переднем плане, классифицируя входящие запросы по сложности и направляя их соответствующим образом. При правильном подходе это оптимизирует как затраты, так и пользовательский опыт. При неправильном подходе это приводит к досадным несоответствиям — пользователи ждут простых ответов или получают поверхностные ответы на сложные вопросы.
Проблемы оценки
Эта архитектура элегантна в теории, но на практике создает проблемы с оценкой. Разным агентам требуются разные критерии оценки, и это не всегда очевидно с самого начала.
- Простой агент должен быть быстрым и обладать фактической точностью, но никто не ожидает от него глубоких рассуждений.
- Агент анализа должен демонстрировать здравый смысл, а не просто точные факты.
- Исследовательский агент должен быть всесторонним — упущение важного фактора риска в инвестиционном анализе является ошибкой, даже если все остальное верно.
- Затем следует аспект RAG (Research, Acquisition, Logic, Logic, Logic, Logic, Logic, Logic, Logic и Logic). Для агентов, которые извлекают документы, возникает целый ряд отдельных вопросов. Извлекли ли мы нужные документы? Использовал ли агент их на самом деле? Или он проигнорировал извлеченный контекст и сгенерировал что-то правдоподобное, но необоснованное?
Для оценки этой системы необходимо оценить множество компонентов по различным критериям. Давайте посмотрим, как мы к этому подойдем.
Три столпа офлайн-оценки
Обзор структуры
За последние два года, работая над различными реализациями агентов, я пришел к выводу о существовании структуры, состоящей из трех основных элементов оценки. Каждый из них рассматривает отдельный тип сбоя, и вместе они обеспечивают достаточно полное представление о том, что может пойти не так.

Эти компоненты не являются независимыми. Маршрутизация влияет на то, какой агент обрабатывает запрос, что влияет на то, будет ли задействован RAG, а это, в свою очередь, влияет на то, какие критерии оценки применяются. Но аналитическое разделение этих компонентов помогает диагностировать источники проблем, а не просто наблюдать за тем, что что-то пошло не так.
Один важный принцип: не каждая оценка выполняется для каждого запроса. Проведение всесторонней оценки RAG на основе простого поиска цены — это расточительно, поскольку оценивать нечему. Проведение только проверок фактической точности сложного исследовательского отчета не позволяет определить, была ли логика обоснованной или охват данных полным.
Первый столп: Оценка маршрутизации
Оценка маршрутизации отвечает на, казалось бы, простой вопрос: выбрал ли маршрутизатор правильного агента? На практике же правильно ответить на этот вопрос сложнее, чем кажется, а ошибка может иметь каскадные последствия.
Я рассматриваю сбои маршрутизации в двух категориях. Недостаточная маршрутизация происходит, когда сложный запрос попадает к простому агенту. Пользователь запрашивает сравнительный анализ и получает поверхностный ответ, который не затрагивает нюансы его вопроса. Он расстроен, и это вполне оправдано — система имела возможность помочь ему, но не использовала её.
Избыточная маршрутизация — это противоположность: простые запросы направляются сложным агентам. Пользователь запрашивает цену акций и ждет пятнадцать секунд, пока исследовательский агент запустится, получит ненужные документы и сгенерирует подробный ответ на вопрос, который заслуживал всего трех слов. Ответ, вероятно, будет неплохим, но вы зря потратили вычислительные ресурсы, деньги и время пользователя.
В ходе одного из проектов мы обнаружили, что маршрутизатор перенаправлял около 40% простых запросов. Ответы были хорошими, поэтому никто не жаловался, но система тратила на эти запросы в пять раз больше средств, чем должна была. Исправление логики классификации маршрутизатора значительно снизило затраты без ухудшения качества, воспринимаемого пользователями.

Для оценки я использую два подхода в зависимости от ситуации. Детерминированная оценка: создаю тестовый набор данных, где каждый запрос помечен ожидаемым агентом, и измеряю, какой процент запросов маршрутизатор обрабатывает правильно. Это быстро, недорого и дает четкий показатель точности.
Оценка на основе LLM: добавляет нюансы в неоднозначных случаях. Некоторые запросы действительно могут быть решены по-разному — «Расскажите мне о бизнесе Microsoft» может быть как простым обзором, так и глубоким анализом, в зависимости от того, что на самом деле хочет пользователь. Когда выбор маршрутизатора отличается от вашей метки, эксперт с LLM может оценить, был ли выбор разумным, даже если он не соответствовал вашим ожиданиям. Это более дорогостоящий метод, но он помогает отличить истинные ошибки от субъективных оценок.
В число отслеживаемых мною показателей входит общая точность маршрутизации (главный показатель), а также матрица ошибок, показывающая, какие агенты путаются с какими. Если маршрутизатор постоянно отправляет запросы на анализ исследовательскому агенту, это конкретная проблема калибровки, которую можно устранить. Я также отслеживаю показатели избыточной и недостаточной маршрутизации отдельно, поскольку они имеют различное влияние на бизнес и требуют разных способов решения.
Второй столп: Оценка работ магистратуры в качестве судьи.
Сложность оценки результатов LLM заключается в том, что они не являются детерминированными, поэтому их нельзя сопоставить с ожидаемым ответом. Допустимые ответы различаются по формулировкам, структуре и акцентам. Необходима оценка, которая учитывает семантическую эквивалентность, оценивает качество рассуждений и выявляет тонкие фактические ошибки. Человеческая оценка хорошо справляется с этим, но не масштабируема. Нецелесообразно вручную проверять тысячи тестовых случаев при каждом развертывании.
LLM-as-judge решает эту проблему, используя функциональную языковую модель для оценки результатов работы других моделей. Вы предоставляете судье запрос, ответ, ваши критерии оценки и любые имеющиеся у вас эталонные данные, а он возвращает структурированную оценку. Этот подход был подтвержден исследованиями, показавшими сильную корреляцию с человеческими оценками при условии четкого определения критериев оценки.
Прежде чем перейти к параметрам оценки, несколько практических замечаний. Ваша модель оценки должна быть как минимум не хуже моделей, которые вы оцениваете — я обычно использую Клода Сонне или GPT-4 для оценки. Использование более слабой модели в качестве судьи приводит к ненадежным результатам. Кроме того, вопросы для судьи должны быть конкретными и структурированными. Расплывчатые инструкции, такие как «оцените качество», приводят к непоследовательным результатам. Подробные критерии оценки с четкими критериями позволяют получить пригодные для использования результаты.
Я оцениваю три параметра, применяемые выборочно в зависимости от сложности запроса.

Фактическая точность имеет основополагающее значение. Судья извлекает из ответа фактические утверждения и проверяет каждое из них на соответствие вашим истинам. В случае финансового запроса это может означать проверку правильности указанного коэффициента P/E, точности данных о выручке и соответствия темпов роста действительности. Результатом является оценка точности, а также разбивка по фактам: верные, неверные или отсутствующие.
Это относится ко всем запросам, независимо от их сложности. Даже простые запросы требуют проверки фактов — возможно, особенно простые запросы, поскольку пользователи доверяют прямым и достоверным ответам, а ошибки подрывают это доверие.
Качество рассуждений имеет значение для аналитических ответов. Когда агент сравнивает варианты инвестиций или оценивает риск, вам необходимо оценить не только правильность фактов, но и обоснованность логики. Следует ли вывод из предпосылок? Подтверждаются ли утверждения доказательствами? Явно ли сформулированы предположения? Учитывается ли в ответе неопределенность должным образом?
Я провожу оценку логической обоснованности только для запросов средней и высокой сложности. Простые фактические запросы не требуют логического обоснования — оценивать нечего. Но для любых аналитических задач качество логического обоснования часто важнее фактической точности. Ответ может содержать правильные цифры, но при этом делать на их основе неверные выводы, и это серьезный недостаток.
Полнота относится к всесторонним результатам, таким как исследовательские отчеты. Когда пользователь запрашивает инвестиционный анализ, он ожидает охвата определенных элементов: финансовые показатели, конкурентная позиция, факторы риска, катализаторы роста. Отсутствие важного элемента считается неудачей, даже если все включенное является точным и обоснованным.

Я провожу оценку полноты только для запросов высокой сложности, где ожидается исчерпывающее покрытие. Для более простых запросов полнота не имеет смысла — вы же не ожидаете, что поиск цены акции будет охватывать факторы риска.
Структура задания для судей имеет большее значение, чем кажется на первый взгляд. Я всегда указываю исходный запрос (чтобы судья понимал контекст), оцениваемый ответ, истинные значения или критерии оценки, конкретную рубрику, объясняющую, как оценивать каждый параметр, и обязательный формат вывода (я использую JSON для удобства анализа). Вложение времени в разработку задания для судей окупается повышением надежности оценки.
Третий компонент: Оценка RAG
Оценка RAG выявляет причину сбоя, которая незаметна, если смотреть только на конечные результаты: система генерирует правдоподобно звучащие ответы, которые на самом деле не основаны на полученных знаниях.
Конвейер обработки данных RAG состоит из двух этапов, и любой из них может завершиться неудачей. Сбой при извлечении означает, что система не получила нужные документы — либо получила нерелевантное содержимое, либо пропустила релевантные документы. Сбой при генерации означает, что система получила корректные документы, но не использовала их должным образом, либо полностью проигнорировав их, либо получив информацию, отсутствующую в контексте.
Стандартная оценка ответа смешивает эти ошибки. Если окончательный ответ неверен, вы не знаете, произошла ли ошибка при извлечении или при генерации. Специализированная оценка RAG разделяет проблемы, позволяя диагностировать и устранить фактическую проблему.
Для этого я использую структуру RAGAS (Retrieval Augmented Generation Assessment), которая предоставляет стандартизированные показатели, ставшие отраслевым стандартом. Показатели делятся на две группы.

Показатели качества поиска оценивают, были ли найдены правильные документы. Точность контекста измеряет, какая доля найденных документов действительно была релевантной — если вы нашли четыре документа, и только два оказались полезными, это 50% точности. Вы извлекаете шум. Полнота контекста измеряет, какая доля релевантных документов была найдена — если три документа были релевантными, и вы получили только два, это 67% полноты. Вы упускаете информацию.
Метрики качества генерации оценивают, правильно ли был использован полученный контекст. Критически важной является точность: она измеряет, подтверждаются ли утверждения в ответе полученным контекстом. Если ответ содержит пять утверждений, и четыре из них основаны на полученных документах, это 80% точности. Пятое утверждение либо основано на параметрических знаниях модели, либо является вымышленным — в любом случае, оно не основано на ваших данных, что является проблемой, если вы полагаетесь на точность RAG.

Я хочу подчеркнуть достоверность, поскольку это показатель, наиболее непосредственно связанный с риском галлюцинаций в системах RAG. Ответ может звучать авторитетно, но при этом быть полностью сфабрикованным. Оценка достоверности выявляет это, проверяя, соответствует ли каждое утверждение полученному контенту.
В одном из проектов мы обнаружили, что показатели достоверности запросов сильно различались в зависимости от их типа. Для простых фактических запросов достоверность превышала 90%. Для сложных аналитических запросов она падала примерно до 60% — модель выполняла больше «рассуждений», выходящих за рамки полученного контекста. Это не обязательно неправильно, но это означало, что пользователи не могли доверять тому, что аналитические выводы основаны на исходных документах. В итоге мы скорректировали подсказки, чтобы более явно ограничивать модель полученной информацией для определенных типов запросов.
Внедрение и интеграция
Архитектура конвейера
Процесс оценки состоит из четырех этапов: загрузка набора данных, запуск агента на каждом образце, выполнение соответствующих оценок и составление сводного отчета.

Начнём с набора данных для оценки. Для каждого примера необходим сам запрос, метаданные, указывающие на уровень сложности и ожидаемого агента, эталонные данные для оценки точности, а для запросов RAG — соответствующие документы, которые должны быть получены. Создание этого набора данных — трудоёмкая работа, но качество вашей оценки полностью зависит от качества эталонных данных. См. пример ниже (код на Python):
{ "id": "eval_001", "query": "Compare Microsoft and Google's P/E ratios", "category": "comparison", "complexity": "medium", "expected_agent": "analysis_agent", "ground_truth_facts": [ "Microsoft P/E is approximately 35", "Google P/E is approximately 25" ], "ground_truth_answer": "Microsoft trades at higher P/E (~35) than Google (~25)...", "relevant_documents": ["MSFT_10K_2024", "GOOGL_10K_2024"] }Я рекомендую начать как минимум с 50 образцов на каждый уровень сложности, то есть минимум 150 для трехуровневой системы. Чем больше, тем лучше — 400 образцов в общей сложности обеспечат более высокую статистическую достоверность показателей. Разделите запросы по категориям, чтобы случайно не переиндексировать один тип.
Для мониторинга я использую Langfuse, который предоставляет хранилище трассировок, привязку оценок и отслеживание выполнения набора данных. Каждый образец оценки создает трассировку, и каждая метрика оценки прикрепляется к этой трассировке в виде оценки. Со временем вы накапливаете историю выполнения оценок, которую можно сравнивать между версиями модели, изменениями подсказок или модификациями архитектуры. Возможность детального анализа конкретных сбоев и просмотра полной трассировки очень полезна для устранения неполадок.
Автоматизированные (CI/CD) контрольные точки качества
Оценка становится очень эффективной, когда она автоматизирована и блокируется. Хорошим началом является запланированное выполнение оценки на репрезентативном подмножестве данных. В результате выполнения генерируются метрики. Если метрики падают ниже заданных пороговых значений, вступает в действие механизм управления, будь то проверка качества, неудачные проверки на контрольных точках и т. д.
Пороговые значения необходимо откалибровать в соответствии с вашим сценарием использования и допустимым уровнем риска. Для финансового приложения, где точность имеет решающее значение, я бы установил фактическую точность на уровне 90%, а достоверность — на уровне 85%. Для внутреннего инструмента повышения производительности с меньшими рисками приемлемыми могут быть значения 80% и 75%. Ключевым моментом является согласование пороговых значений с командами по управлению и обеспечению качества и их применение стандартным, повторяемым способом.
Я также рекомендую планировать запуск оценки на всем наборе данных, а не только на подмножестве, используемом для проверок запросов на слияние. Это позволит выявить отклонения во внешних зависимостях — изменения API, обновления моделей, модификации базы знаний — которые могут не проявиться в меньшем наборе данных запросов на слияние.
В случае неудачной оценки конвейер должен сгенерировать отчет о сбое, в котором будут указаны метрики, не достигшие порогового значения, и конкретные образцы, не прошедшие проверку. Это обеспечит командам необходимые сигналы для устранения неполадок.
Управление и соблюдение нормативных требований
При внедрении в корпоративной среде оценка включает в себя качество проектирования и организационную ответственность. Группам управления необходимы доказательства того, что системы ИИ соответствуют установленным стандартам. Группам по соблюдению нормативных требований необходимы журналы аудита. Группам по управлению рисками необходима информация о причинах сбоев.
Автономная оценка предоставляет эти доказательства. Каждый запуск создает запись: какая версия модели была оценена, какой набор данных использовался, какие оценки были достигнуты, были ли соблюдены пороговые значения. Эти записи накапливаются в журнале аудита, демонстрирующем систематическое обеспечение качества с течением времени.
Я рекомендую совместно с заинтересованными сторонами, отвечающими за управление, определить критерии приемлемости до первого этапа оценки. Какой порог фактической точности приемлем для вашего случая? Какой уровень достоверности требуется? Достижение согласованности на начальном этапе предотвращает путаницу и конфликты при интерпретации результатов.

Критерии должны отражать реальный риск. Система, предоставляющая медицинскую информацию, требует более высоких пороговых значений точности, чем система, обобщающая протоколы совещаний. Система, дающая финансовые рекомендации, требует более высоких пороговых значений достоверности, чем система, разрабатывающая маркетинговые тексты. Универсального решения не существует, и команды управления понимают это, когда вы формулируете вопрос с точки зрения риска.
Наконец, подумайте о создании отчетов для разных аудиторий. Инженерный отдел хочет получать подробные данные по метрикам и типам запросов. Руководство хочет получать сводную информацию о прохождении/непрохождении тестов с линиями тренда. Руководители хотят видеть панель мониторинга, отображающую статус «зеленый/желтый/красный» по всем системам. Langfuse и аналогичные инструменты поддерживают эти различные представления, но их необходимо целенаправленно настраивать.
Заключение
Разрыв между впечатляющими демонстрациями и готовыми к внедрению системами преодолевается за счет тщательной, систематической оценки. Представленная здесь структура обеспечивает основу для построения системы управления, адаптированной к вашим конкретным агентам, сценариям использования и допустимому уровню риска.
Основные выводы
- Требования к оценке — Требования различаются в зависимости от сценария использования приложения. Для простого поиска необходимы проверки фактической точности. Для сложного анализа требуется оценка логических рассуждений. Для ответа с поддержкой RAG необходима проверка достоверности. Применение правильных оценок к правильным запросам позволяет получить полезную информацию без шума.
- Автоматизация. Ручная оценка не масштабируема и не выявляет регрессии. Интеграция оценки в конвейеры CI/CD с четко определенными пороговыми значениями, блокирующими развертывание, превращает обеспечение качества из разовой операции в повторяемую практику.
- Управление — Отчеты об оценке обеспечивают необходимый для соблюдения нормативных требований контрольный след и доказательства, необходимые руководству для утверждения развертывания в производственной среде. Установление этой связи на раннем этапе превращает управление ИИ в партнерство, а не в препятствие.
С чего начать
Если вы сегодня не проводите систематическую оценку в офлайн-режиме, не пытайтесь внедрить все сразу.
- Начните с точности маршрутизации и фактической точности — это наиболее информативные показатели, и их проще всего реализовать. Создайте небольшой набор данных для оценки, например, 50–100 образцов. Проведите его вручную несколько раз, чтобы скорректировать свои ожидания.
- Добавить оценку логического вывода для сложных запросов и метрики RAG для агентов с поддержкой извлечения данных.
- Интегрируйте в CI/CD. Определите пороговые значения совместно с партнерами по управлению. Создавайте, тестируйте, совершенствуйте.
Цель состоит в том, чтобы начать закладывать фундамент и выстраивать процессы, обеспечивающие подтверждение качества по определенным критериям. Это основа для готовности к производству, доверия заинтересованных сторон и ответственного внедрения ИИ.
Статья получилась довольно длинной, большое спасибо, что дочитали до конца. Надеюсь, она оказалась для вас полезной, и вы попробуете применить эти идеи на практике. Всего наилучшего и удачного строительства! 🙂
Мукул Суд. Все материалы от Мукула Суда.
Источник: towardsdatascience.com