

Мы представляем Test-Time Diffusion Deep Researcher (TTD-DR) — фреймворк, использующий глубокого исследовательского агента для составления и редактирования собственных черновиков на основе высококачественной полученной информации. Этот подход позволяет достичь новых передовых результатов в написании объемных исследовательских отчетов и выполнении сложных задач логического мышления.
Быстрые ссылки
- Бумага
- Делиться
Последние достижения в области больших языковых моделей (LLM) способствовали появлению агентов глубокого исследования (DR). Эти агенты демонстрируют замечательные возможности, включая генерацию новых идей, эффективный поиск информации, выполнение экспериментов и последующее составление исчерпывающих отчетов и научных статей.
В настоящее время большинство общедоступных агентов DR используют множество хитрых методов для улучшения своих результатов, например, проводят рассуждения по принципу логической цепочки или генерируют несколько ответов и выбирают лучший. Несмотря на впечатляющий прогресс, они часто объединяют различные инструменты, не учитывая итеративный характер человеческих исследований. Им не хватает ключевого процесса (т.е. планирования, составления черновика, исследования и итерации на основе обратной связи), на который люди полагаются при написании работы на сложную тему. Ключевой частью этого процесса редактирования является проведение дополнительных исследований для поиска недостающей информации или усиления аргументов. Эта человеческая модель удивительно похожа на механизм моделей диффузионного поиска с дополненной реальностью, которые начинают с «шумного» или некачественного результата и постепенно улучшают его до высококачественного результата. Что если черновик агента ИИ — это шумная версия, а инструмент поиска выступает в качестве этапа шумоподавления, очищая её новыми фактами?
Сегодня мы представляем Test-Time Diffusion Deep Researcher (TTD-DR), агента глубокого исследования, имитирующего способ проведения исследований человеком. Насколько нам известно, TTD-DR — это первый исследовательский агент, моделирующий написание исследовательского отчета как процесс диффузии, где неряшливый первый черновик постепенно дорабатывается до высококачественной финальной версии. Мы представляем два новых алгоритма, которые работают вместе, чтобы обеспечить работу TTD-DR. Во-первых, покомпонентная оптимизация посредством самоэволюции повышает качество каждого шага в исследовательском процессе. Затем, уточнение на уровне отчета посредством шумоподавления с использованием полученных данных применяет вновь полученную информацию для пересмотра и улучшения черновика отчета. Мы демонстрируем, что TTD-DR достигает самых современных результатов в задачах написания длинных отчетов и многошагового рассуждения.
Исследователь, занимающийся распространением знаний в условиях ограниченного времени тестирования.
TTD-DR разработан таким образом, чтобы принимать запрос пользователя в качестве входных данных и создавать предварительный черновик, который служит развивающейся основой для плана исследования. Этот развивающийся черновик итеративно уточняется с помощью процесса шумоподавления с поиском информации (уточнение на уровне отчета), который использует найденную информацию для улучшения черновика на каждом этапе. Это происходит в непрерывном цикле, улучшая отчет с каждым циклом. Вдобавок ко всему, алгоритм самосовершенствования постоянно улучшает весь процесс, от первоначального плана до окончательного отчета. Это мощное сочетание уточнения и самосовершенствования приводит к более согласованному процессу написания отчетов.

Иллюстрация TTD-DR. Мы разработали ее таким образом, чтобы имитировать типичные исследовательские практики, выполняя итеративные циклы составления и редактирования черновиков.
Проектирование магистральной сети DR
Проектирование магистральной сети аварийного восстановления состоит из трех этапов, которые мы опишем ниже.
- Разработка плана исследования: Создает структурированный план исследования по запросу пользователя. Этот план содержит список ключевых областей, необходимых для итогового отчета, и служит первоначальным руководством для последующего процесса сбора информации.
- Итеративный поиск: включает два подагента: генерация поискового вопроса (этап 2a на рисунке ниже) формирует поисковый запрос на основе плана исследования, запроса пользователя и контекста предыдущих итераций поиска (т.е. прошлых вопросов и ответов). Поиск ответа (этап 2b) осуществляет поиск в доступных источниках для нахождения релевантных документов и возвращает сводный ответ, аналогично системам генерации с расширенным поиском (RAG).
- Создание итогового отчета: формирует всеобъемлющий и связный итоговый отчет путем объединения всей собранной структурированной информации, то есть плана и серии пар вопросов и ответов.

Наш основной агент аварийного восстановления работает в три этапа. Этап 1 генерирует подробный план исследования; Этап 2a итеративно генерирует поисковые вопросы, а затем использует систему, подобную RAG, для синтеза точных ответов из полученных документов (2b); Этап 3 синтезирует всю собранную информацию для составления окончательного отчета.
Компонентная самоэволюция
Мы используем самоэволюционный алгоритм для повышения производительности агентов на каждом этапе с целью поиска и сохранения высококачественного контекста.
- Начальные состояния: Крайние левые блоки на диаграмме ниже представляют собой множество различных вариантов ответов, основанных на результатах предыдущих этапов, которые используются для исследования более широкого пространства поиска. В идеале это приводит к обнаружению более ценной информации.
- Обратная связь от пользователя: Каждый вариант ответа оценивается судьей, имеющим степень магистра права (LLM), с использованием автоматизированных систем оценки таких показателей, как полезность и полнота. Эти системы оценки не только выставляют баллы за соответствие, но и генерируют текстовые комментарии, которые помогают улучшить ответ.
- Корректировка: На основе оценок и обратной связи, полученных на предыдущем этапе, каждый вариант проходит этап корректировки для улучшения показателей пригодности. Этапы обратной связи и корректировки повторяются до достижения максимального числа итераций или до тех пор, пока агент не определит, что дальнейшие корректировки не требуются.
- Пересечение: Наконец, несколько переработанных вариантов объединяются в единый высококачественный результат. Этот процесс объединения консолидирует лучшую информацию из всех эволюционных путей, создавая превосходный контекст для основного процесса генерации отчетов.

Иллюстрация алгоритма самоэволюции по компонентам, применяемого к задаче поиска ответа (этап 2b). Процесс начинается с множества вариантов исходных ответов, каждый из которых проходит эпизод самоэволюции, в ходе которого сначала взаимодействует с окружающей средой для получения оценки пригодности и обратной связи. Затем он корректируется на основе полученной обратной связи. Этот процесс повторяется до достижения максимального числа итераций. Наконец, несколько скорректированных вариантов из всех эпизодов объединяются для получения окончательного ответа.
Шумоподавление на уровне отчета с возможностью поиска
Поскольку предварительный черновой вариант с шумом бесполезен для сложных тем без реального исследования, TTD-DR использует инструмент поиска, который очищает черновой вариант от шума и дорабатывает его.
В частности, мы передаем текущий черновой отчет на этап генерации поиска (этап 2a) основного рабочего процесса DR, чтобы использовать его для генерации следующего поискового запроса. После получения синтезированного ответа на этапе поиска ответа (этап 2b) новая информация используется для пересмотра чернового отчета путем добавления новых деталей или проверки существующей информации. Этот процесс передачи очищенного от шума отчета обратно для генерации следующего поискового запроса повторяется. Черновик постепенно очищается от шума до завершения процесса поиска, после чего конечный агент составляет окончательный отчет на основе всех исторических ответов на поисковые запросы и внесенных изменений (этап 3).
Результаты
Мы оцениваем производительность TTD-DR, используя эталонные наборы данных, ориентированные на две основные задачи: 1) сложные запросы, требующие от агентов-исследователей составления подробного отчета (DeepConsult), и 2) многошаговые запросы, требующие обширного поиска и логического вывода для ответа (Humanity's Last Exam [HLE] и GAIA). Мы отбираем 200 запросов из HLE, требующих более тщательного поиска и логического вывода (HLE-Search). Обе категории соответствуют нашей цели — созданию универсального, применимого в реальных условиях инструмента для проведения исследований. Мы сравниваем наши системы DR с OpenAI Deep Research.
TTD-DR неизменно демонстрирует лучшие результаты по всем показателям. В частности, по сравнению с OpenAI DR, TTD-DR достигает 74,5% успеха в задачах генерации длинных исследовательских отчетов. Кроме того, он превосходит OpenAI DR на 7,7% и 1,7% на двух обширных наборах данных для исследований с краткими эталонными ответами.

Производительность TTD-DR по сравнению с различными базовыми системами на эталонных наборах данных. Слева : процент выигрышей (%) рассчитан на основе OpenAI DR. Справа : правильность вычисляется как совпадение между предсказанным системой ответом и эталонным ответом. TTD-DR значительно превосходит OpenAI DR.
Исследование абляции
Для исследования методом абляции мы постепенно добавляем три метода, описанные в разделе выше. Наши агенты DR используют Gemini-2.5-pro в качестве базовой модели. Все остальные базовые агенты используют свои стандартные LLM. На диаграммах ниже показано исследование методом абляции для наших агентов DR. Базовый агент DR показывает худшие результаты, чем OpenAI DR. С добавлением предложенного алгоритма самоэволюции мы наблюдаем, что для DeepConsult наша система превосходит OpenAI Deep Research с показателем успешности 59,8%. Показатели корректности на наборах данных HLE-Search и GAIA также демонстрируют улучшение на 4,4% и 1,2% соответственно. Наконец, включение диффузии в процесс поиска приводит к существенному улучшению по всем показателям.

Производительность TTD-DR повышается за счет постепенного добавления 1) базовой архитектуры DR, 2) самоэволюции и 3) диффузии с поиском. Мы наблюдаем поэтапные улучшения по всем параметрам, которые помогают нам достичь новых передовых результатов.
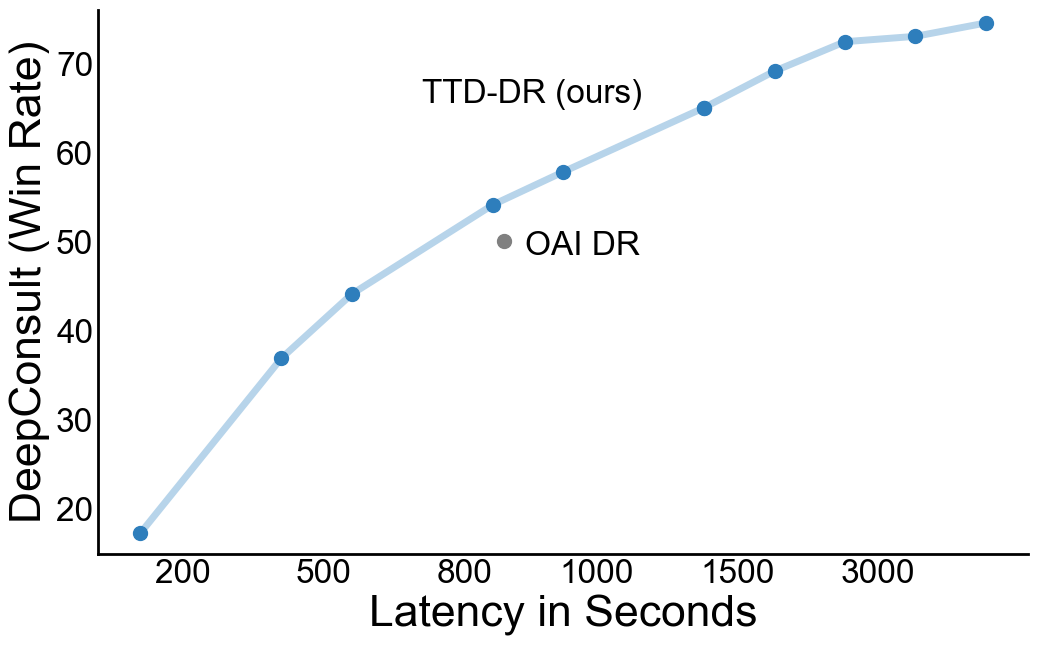
Приведенная ниже диаграмма Парето-границы дополнительно демонстрирует эффективность масштабирования времени тестирования TTD-DR по сравнению с другими агентами DR. Мы обнаружили, что TTD-DR более эффективен, чем OpenAI DR, поскольку при той же задержке он обеспечивает лучшее качество на единицу процента выигрышей. Подробнее см. статью.

Граница Парето качества отчетов об исследованиях в зависимости от задержки в секундах. Синяя линия обозначает TTD-DR, а серые точки — сравниваемые агенты DR.
Заключение
Deep Researcher with Test-Time Diffusion (TTD-DR) — это новая платформа, вдохновленная итеративным методом проведения исследований человеком. Этот агент устраняет ограничения существующих агентов DR, рассматривая генерацию отчетов как процесс распространения информации. Платформа TTD-DR значительно превосходит существующие агенты DR по различным показателям, требующим интенсивного поиска и многошагового анализа. Она демонстрирует передовые результаты в генерации исчерпывающих отчетов и поиске кратких ответов для задач многошагового поиска и анализа. Мы считаем, что ее успех обусловлен концепцией «сначала черновик», которая обеспечивает сфокусированность и согласованность всего процесса исследования, предотвращая потерю важной информации.
Доступно на платформе Google Cloud.
Продуктовая версия этой работы доступна на Google Agentspace и реализована с использованием Google Cloud Agent Development Kit.
Благодарности
Это исследование провели Руджун Хань, Яньфэй Чен, Гуань Сунь, Лесли Микуличич, Зои ЦуйЧжу, Юаньцзюнь (София) Би, Вэймин Вэнь, Хуэй Ван, Чуньфэн Вэнь, Солен Мэтр, Джордж Ли, Виши Тирумалашетти, Сяовей Ли, Эмили Сюэ, Цзыжао Чжан, Салем Хайкал, Бурак Гоктюрк, Томас. Пфистер и Чен-Ю Ли.
Источник: research.google






















