
Практическое руководство по разработке и анализу надежных стратегий агрегации
Делиться

Кому следует прочитать этот документ?
Этот документ предназначен для специалистов, исследователей и инженеров в области машинного обучения, интересующихся изучением пользовательских схем агрегации в федеративном обучении. Он особенно полезен тем, кто хочет разрабатывать, тестировать и анализировать новые методы агрегации в реальных распределённых средах.
Введение
Машинное обучение (МО) продолжает стимулировать инновации в различных областях, таких как здравоохранение, финансы и оборона. Однако, хотя модели МО в значительной степени опираются на большие объёмы централизованных высококачественных данных, вопросы конфиденциальности данных, права собственности и соответствия нормативным требованиям остаются серьёзными препятствиями.
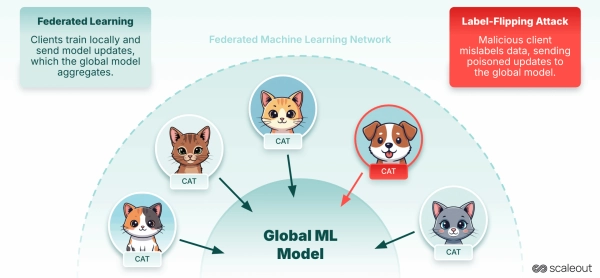
Федеративное обучение (FL) решает эти проблемы, обеспечивая обучение моделей на распределённых наборах данных, что позволяет данным оставаться децентрализованными, сохраняя при этом их вклад в общую глобальную модель. Этот децентрализованный подход делает FL особенно ценным в чувствительных областях, где централизация данных нецелесообразна или ограничена.
Для полного использования возможностей FL важно понимать и разрабатывать собственные схемы агрегации . Эффективная агрегация не только влияет на точность и надёжность модели, но и решает такие проблемы, как гетерогенность данных, надёжность клиента и состязательное поведение. Таким образом, анализ и разработка адаптированных методов агрегации — ключевой шаг к оптимизации производительности и обеспечению равноправия в федеративных средах.
В моей предыдущей статье мы рассмотрели ландшафт кибератак в сфере федеративного обучения и его отличия от традиционного централизованного машинного обучения. В той статье был представлен открытый набор инструментов Scaleout для моделирования атак, который помогает исследователям и практикам анализировать воздействие различных типов атак и оценивать ограничения существующих схем противодействия, особенно в сложных условиях, таких как экстремальный дисбаланс данных, распределения, не соответствующие стандарту IID, и наличие отстающих или поздно присоединившихся участников.
Однако в этой первой статье не рассматривалось, как проектировать, реализовывать и тестировать собственные схемы в реальных распределенных средах.
Это может показаться сложным, но данная статья предлагает краткое пошаговое руководство, охватывающее основные концепции, необходимые для проектирования и разработки пользовательских схем агрегации для реальных федеративных настроек.
Что такое функции сервера?
Пользовательские агрегаторы — это функции, работающие на стороне сервера в системе федеративного обучения. Они определяют, как обрабатываются обновления модели от клиентов, например, агрегация, проверка или фильтрация, перед созданием следующей глобальной модели. Термин «серверная функция» используется в платформе Scaleout Edge AI для обозначения пользовательских агрегаторов.
Помимо простого агрегирования, серверные функции позволяют исследователям и разработчикам разрабатывать новые схемы, включающие сохранение конфиденциальности, справедливость, надёжность и эффективность конвергенции. Настраивая этот уровень, можно также экспериментировать с инновационными механизмами защиты, адаптивными правилами агрегирования или методами оптимизации, адаптированными к конкретным данным и сценариям развертывания.
Серверные функции — это механизм платформы Scaleout Edge AI для реализации пользовательских схем агрегации. Помимо этой гибкости, платформа включает четыре встроенных агрегатора: FedAvg (по умолчанию), FedAdam (FedOpt), FedYogi (FedOpt) и FedAdaGrad (FedOpt). Реализация методов семейства FedOpt соответствует подходу, описанному в статье. Подробнее см. в документации платформы.
Создание пользовательской схемы агрегации
В этой статье я покажу, как создать и протестировать собственную схему противодействия атакам с помощью платформы Edge AI от Scaleout. Одним из ключевых инструментов для этого является функция сервера (Server Function).
В этой статье мы рассмотрим, как разработать и реализовать собственный процесс агрегации в географически распределённой среде. Я пропущу базовую настройку и предположу, что вы уже знакомы с платформой Scaleout. Если вы только начинаете, вот несколько полезных ресурсов:
Пример быстрого старта FL: https://docs.scaleoutsystems.com/en/stable/quickstart.html
Архитектура фреймворка: https://docs.scaleoutsystems.com/en/stable/architecture.html
Справочник по API клиента: https://docs.scaleoutsystems.com/en/stable/apiclient.html Сервер
Руководство по функциям: https://docs.scaleoutsystems.com/en/stable/serverfunctions.html
Пример: атака с подменой меток
Рассмотрим конкретную атаку — подмену меток. В этом сценарии вредоносный клиент намеренно меняет метки в своём локальном наборе данных (например, меняет «кошку» на «собаку»). При отправке этих «отравленных» обновлений на сервер глобальная модель усваивает неверные закономерности, что приводит к снижению точности и надёжности.
Для этого эксперимента мы использовали открытый исходный набор данных MNIST, разделенный на шесть разделов, каждый из которых назначен отдельному клиенту. client-6 действует как злонамеренный участник, меняя метки в своих локальных данных, используя их для обучения и отправляя полученную локальную модель агрегатору.

| Вредоносный клиент | ИДЕНТИФИКАТОР |
|---|---|
| клиент-6 | 07505d04-08a5-4453-ad55-d541e9e4ef57 |
Здесь вы видите пример точки данных (изображение в оттенках серого) от клиента №6, где метки намеренно перевернуты. Изменяя метки, этот клиент пытается испортить глобальную модель в процессе агрегации.

Задача
Не допускать вмешательства клиента-6 в разработку глобальной модели.
Смягчение с помощью косинусного подобия
Чтобы противостоять этому, мы используем в качестве примера подход, основанный на косинусном сходстве . Идея проста: сравнить вектор обновления каждого клиента с глобальной моделью (шаг 1). Если степень сходства ниже заданного порогового значения (s̄ᵢ < 𝓣), обновление, вероятно, исходит от вредоносного клиента (шаги 2–4). На последнем шаге (шаг 5) вклад этого клиента исключается из процесса агрегации, который в данном случае использует схему взвешенного федеративного усреднения (FedAVG).

Примечание : Это простая схема противодействия атакам, в первую очередь предназначенная для демонстрации гибкости поддержки настраиваемого агрегирования в реалистичных сценариях федеративного обучения. Эта же схема может быть неэффективна в сложных случаях, например, при несбалансированных наборах данных или в условиях, не соответствующих требованиям IID.
Реализация Python ниже иллюстрирует рабочий процесс пользовательского агрегатора: идентификация онлайн-клиентов (шаг 1), вычисление оценок косинусного сходства (шаги 2–3), исключение вредоносного клиента (шаг 4) и выполнение федеративного взвешенного усреднения (шаг 5).
Шаг 1
# — Вычислить дельты (клиент — previous_global) — prev_flat = self._flatten_params(previous_global) flat_deltas, norms = [], [] для параметров в client_params: flat = self._flatten_params(params) delta = flat — prev_flat flat_deltas.append(delta) norms.append(np.linalg.norm(delta))
Шаг 2 и 3
# — Матрица косинусного сходства — similarity_matrix = np.zeros((num_clients, num_clients), dtype=float) for i in range(num_clients): for j in range(i + 1, num_clients): denom = norms[i] * norms[j] sim = float(np.dot(flat_deltas[i], flat_deltas[j]) / denom) if denom > 0 else 0.0 similarity_matrix[i, j] = sim similarity_matrix[j, i] = sim # — Среднее сходство на клиента — avg_sim = np.zeros(num_clients, dtype=float) if num_clients > 1: avg_sim = np.sum(similarity_matrix, axis=1) / (num_clients — 1) for cid, s в zip(client_ids, avg_sim): logger.info(f»Округлить {self.round}: Среднее дельта-косинусное сходство для {cid}: {s:.4f}»)
Шаг 4
# — Отметить подозрительных клиентов — suspect_indices = [i for i, s in enumerate(avg_sim) if s < self.similarity_threshold] suspect_clients = [client_ids[i] for i in suspect_indices] if suspect_clients: logger.warning(f"Округлить {self.round}: Исключить подозрительных клиентов: {suspicious_clients}") # --- Оставить только неподозрительных клиентов --- keep_indices = [i for i in range(num_clients) if i not in suspect_indices] if len(keep_indices) < 3: # защитить logger.warning("Слишком много исключений, возвращаемся ко ВСЕМ клиентам.") keep_indices = list(range(num_clients)) held_client_ids = [client_ids[i] for i in keep_indices] logger.info(f"Округлить {self.round}: Клиенты, используемые для FedAvg: {kept_client_ids}")
Шаг 5
# === Weighted FedAvg === weighted_sum = [np.zeros_like(param) for param in previous_global] total_weight = 0 for i in keep_indices: client_id = client_ids[i] client_parameters, metadata = client_updates[client_id] num_examples = metadata.get(«num_examples», 1) total_weight += num_examples for j, param in enumerate(client_parameters): weighted_sum[j] += param * num_examples if total_weight == 0: logger.error(«Ошибка агрегации: total_weight = 0.») return previous_global new_global = [param / total_weight for param in weighted_sum] logger.info(«Модели агрегированы с использованием фильтрации по косинусному сходству FedAvg») return new_global
Полный код доступен на Github: https://github.com/sztoor/server_functions_cosine_similarity_example.git
Пошаговая активация функций сервера
- Войдите в Scaleout Studio и создайте новый проект.
- Загрузите вычислительный пакет и исходную модель в проект.
- Подключите клиентов к Studio, установив клиентские библиотеки Scaleout через pip ( # pip install fedn). Я подключил шесть клиентов.
Примечание: подробные инструкции по выполнению шагов 1–3 см. в кратком руководстве пользователя.
- Клонируйте репозиторий Github по предоставленной ссылке. Это даст вам два файла Python:
- server_functions.py – содержит схему агрегации на основе косинусного сходства.
- scaleout_start_session.py — подключается к Studio, отправляет локальную server_function и запускает сеанс обучения на основе предопределенных настроек (например, 5 раундов, тайм-аут раунда 180 секунд).
- Выполните скрипт scaleout_start_session.py.
Полную информацию об этих шагах можно найти в официальном руководстве по функциям сервера.
Результат и обсуждение
Ниже описаны шаги, необходимые для запуска scaleout_start_session.py.
В этой конфигурации к студии были подключены шесть клиентов, причём клиент 6 использовал намеренно перевёрнутый набор данных для имитации вредоносного поведения. Журналы Scaleout Studio предоставляют подробную информацию о выполнении серверной функции и реакции системы во время агрегации. В разделе 1 журналы показывают, что сервер успешно получил модели от всех клиентов, что подтверждает, что связь и загрузка моделей работают должным образом. В разделе 2 представлены оценки сходства для каждого клиента. Эти оценки количественно определяют, насколько точно обновление каждого клиента соответствует общей тенденции, предоставляя метрику для выявления аномалий.
Раздел 1
2025-10-20 11:35:08 [ИНФОРМАЦИЯ] Получен запрос на выбор клиента. 2025-10-20 11:35:08 [ИНФОРМАЦИЯ] Выбраны клиенты: ['eef3e17f-d498-474c-aafe-f7fa7203e9a9', 'e578482e-86b0-42fc-8e56-e4499e6ca553', '7b4b5238-ff67-4f03-9561-4e16ccd9eee7', '69f6c936-c784-4ab9-afb2-f8ccffe15733', '6ca55527-0fec-4c98-be94-ef3ffb09c872', '07505d04-08a5-4453-ad55-d541e9e4ef57'] 2025-10-20 11:35:14 [INFO] Получена предыдущая глобальная модель 2025-10-20 11:35:14 [INFO] Получены метаданные 2025-10-20 11:35:14 [INFO] Получена модель клиента от клиента eef3e17f-d498-474c-aafe-f7fa7203e9a9 2025-10-20 11:35:14 [INFO] Получены метаданные 2025-10-20 11:35:15 [INFO] Получена модель клиента от клиента e578482e-86b0-42fc-8e56-e4499e6ca553 2025-10-20 11:35:15 [INFO] Получены метаданные 2025-10-20 11:35:15 [INFO] Получена модель клиента от клиента 07505d04-08a5-4453-ad55-d541e9e4ef57 2025-10-20 11:35:15 [INFO] Получены метаданные 2025-10-20 11:35:15 [INFO] Получена модель клиента от клиента 69f6c936-c784-4ab9-afb2-f8ccffe15733 2025-10-20 11:35:15 [INFO] Получено метаданные 2025-10-20 11:35:15 [ИНФОРМАЦИЯ] Получена модель клиента от клиента 6ca55527-0fec-4c98-be94-ef3ffb09c872 2025-10-20 11:35:16 [ИНФОРМАЦИЯ] Получены метаданные 2025-10-20 11:35:16 [ИНФОРМАЦИЯ] Получена модель клиента от клиента 7b4b5238-ff67-4f03-9561-4e16ccd9eee7
Раздел 2
2025-10-20 11:35:16 [ИНФОРМАЦИЯ] Получен запрос на агрегацию: агрегация 2025-10-20 11:35:16 [ИНФОРМАЦИЯ] Раунд 0: Среднее дельта-косинусное сходство для eef3e17f-d498-474c-aafe-f7fa7203e9a9: 0,7498 2025-10-20 11:35:16 [ИНФОРМАЦИЯ] Раунд 0: Среднее дельта-косинусное сходство для e578482e-86b0-42fc-8e56-e4499e6ca553: 0,7531 2025-10-20 11:35:16 [ИНФОРМАЦИЯ] Раунд 0: Среднее дельта-косинусное сходство для 07505d04-08a5-4453-ad55-d541e9e4ef57: -0,1346 2025-10-20 11:35:16 [ИНФОРМАЦИЯ] Раунд 0: Среднее дельта-косинусное сходство для 69f6c936-c784-4ab9-afb2-f8ccffe15733: 0,7528 2025-10-20 11:35:16 [ИНФОРМАЦИЯ] Раунд 0: Среднее дельта-косинусное сходство для 6ca55527-0fec-4c98-be94-ef3ffb09c872: 0,7475 2025-10-20 11:35:16 [ИНФОРМАЦИЯ] Раунд 0: Среднее дельта-косинусное сходство для 7b4b5238-ff67-4f03-9561-4e16ccd9eee7: 0,7460
Раздел 3
2025-10-20 11:35:16 ⚠️ [ВНИМАНИЕ] Раунд 0: Исключение подозрительных клиентов: ['07505d04-08a5-4453-ad55-d541e9e4ef57']
Раздел 4
2025-10-20 11:35:16 [ИНФОРМАЦИЯ] Раунд 0: Клиенты, используемые для FedAvg: ['eef3e17f-d498-474c-aafe-f7fa7203e9a9', 'e578482e-86b0-42fc-8e56-e4499e6ca553', '69f6c936-c784-4ab9-afb2-f8ccffe15733', '6ca55527-0fec-4c98-be94-ef3ffb09c872', '7b4b5238-ff67-4f03-9561-4e16ccd9eee7'] 2025-10-20 11:35:16 [ИНФОРМАЦИЯ] Модели, агрегированные с использованием FedAvg + косинусной фильтрации сходства
В разделе 3 отмечено, что клиент-6 (ID …e4ef57) был идентифицирован как вредоносный. Предупреждающее сообщение указывает на то, что этот клиент будет исключён из процесса агрегации. Это исключение обосновано его крайне низким показателем сходства –0,1346 , самым низким среди всех клиентов, и пороговым значением (𝓣), установленным в серверной функции. Удаление клиента-6 гарантирует, что обновление выбросов не окажет негативного влияния на глобальную модель. В разделе 4 перечислены идентификаторы клиентов, включённые в агрегацию, что подтверждает, что в обновлённую глобальную модель внесли вклад только доверенные клиенты.
Задача выполнена
client-6 был успешно исключен из процесса агрегации с использованием пользовательской схемы агрегации.
В сочетании с сообщениями журнала платформа предоставляет подробную информацию по каждому клиенту, которая улучшает понимание его поведения. К ней относятся потери и точность обучения для каждого клиента, глобальные метрики производительности модели и время обучения для каждого клиента. Ещё одной ключевой функцией является журнал модели, который отслеживает обновления модели с течением времени и позволяет детально анализировать влияние отдельных клиентов на глобальную модель. Разделы и дополнительные данные в совокупности дают полное представление о вкладе клиентов, наглядно иллюстрируя различие между обычными клиентами и вредоносным клиентом-6 (ID …e4ef57) и демонстрируя эффективность функции сервера в противодействии потенциальным атакам.



Графики точности и потерь обучения на стороне клиента демонстрируют производительность каждого клиента. Они показывают, что клиент-6 значительно отличается от остальных. Включение его в процесс агрегации может негативно сказаться на производительности глобальной модели.
Краткое содержание
В этой публикации блога подчёркивается важность использования пользовательских агрегаторов для решения особых задач и создания возможностей для разработки надёжных, эффективных и высокоточных моделей в условиях федеративного машинного обучения. Также подчёркивается ценность использования уже существующих компонентов, а не того, чтобы начинать всё с нуля и тратить много времени на компоненты, не имеющие решающего значения для основной идеи.
Федеративное обучение предлагает эффективный способ доступа к наборам данных, которые сложно или даже невозможно централизовать в одном месте. Подобные исследования показывают, что, несмотря на всю многообещающую перспективность этого подхода, он также требует глубокого понимания базовых систем. К счастью, существуют готовые платформы, которые упрощают изучение реальных сценариев использования, эксперименты с различными схемами агрегации и разработку решений, адаптированных к конкретным потребностям.
Полезные ссылки
- Пользовательские функции сервера в Scaleout Studio
- Начало работы с Scaleout Studio
- Объяснение федеративного обучения: концепции, преимущества и практическое применение
- Кросс-устройствовое федеративное машинное обучение с минимальными ресурсами
- Масштабируемое федеративное машинное обучение с FEDn, 22-й Международный симпозиум IEEE 2022 по кластерным, облачным и интернет-вычислениям (CCGrid).
Данные автора:
Салман Тур
Технический директор и соучредитель Scaleout.
Доцент
Департамент информационных технологий,
Уппсальский университет, Швеция
LinkedIn Google Академия
Источник: towardsdatascience.com

























