
Понимание основ федеративного обучения
Делиться

Впервые я столкнулся с концепцией федеративного обучения (ФО) благодаря комиксу от Google в 2019 году. Это был блестящий комикс, отлично объясняющий, как можно улучшать продукты, не отправляя пользовательские данные в облако. В последнее время мне захотелось подробнее разобраться в технической стороне этой области. Обучающие данные стали очень важным ресурсом, поскольку они необходимы для построения хороших моделей, но большая их часть остается неиспользованной, потому что они фрагментированы, неструктурированы или хранятся в изолированных хранилищах.
Начав изучать эту область, я обнаружил, что фреймворк Flower — это самый простой и удобный для начинающих способ начать работу с FL Studio. Он имеет открытый исходный код, документация понятна, а сообщество вокруг него очень активно и отзывчиво. Это одна из причин моего возобновившегося интереса к этой области.
Эта статья — первая часть серии, в которой я более подробно рассматриваю федеративное обучение, рассказывая о том, что это такое, как оно реализуется, с какими открытыми проблемами сталкивается и почему оно важно в условиях, чувствительных к конфиденциальности. В следующих частях я углублюсь в практическую реализацию с использованием фреймворка Flower , обсужу вопросы конфиденциальности в федеративном обучении и рассмотрю, как эти идеи распространяются на более сложные сценарии использования.
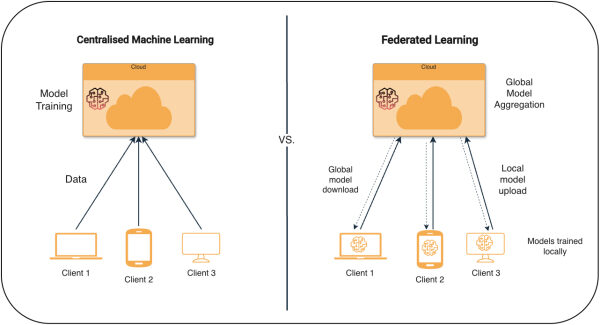
Когда централизованное машинное обучение не является оптимальным решением
Мы знаем, что модели ИИ зависят от больших объемов данных, однако большая часть наиболее полезных данных является конфиденциальной, распределенной и труднодоступной. Вспомните данные, хранящиеся в больницах, телефонах, автомобилях, датчиках и других периферийных системах. Проблемы конфиденциальности, локальные правила, ограниченные возможности хранения и сетевые ограничения делают перемещение этих данных в централизованное хранилище очень сложным или даже невозможным. В результате большие объемы ценных данных остаются неиспользованными. В здравоохранении эта проблема особенно заметна. Больницы ежегодно генерируют десятки петабайт данных, однако исследования показывают, что до 97% этих данных остаются неиспользованными .
Традиционное машинное обучение предполагает, что все обучающие данные могут быть собраны в одном месте, обычно на централизованном сервере или в центре обработки данных. Это работает, когда данные могут свободно перемещаться, но перестает работать, когда данные являются конфиденциальными или защищенными. На практике централизованное обучение также зависит от стабильного соединения, достаточной пропускной способности и низкой задержки, что трудно гарантировать в распределенных или периферийных средах.

В таких случаях обычно выбираются два варианта. Первый — вообще не использовать данные, а это значит, что ценная информация останется запертой внутри изолированных систем.
Другой вариант — позволить каждому локальному объекту обучать модель на собственных данных и делиться только тем, чему модель научилась, при этом исходные данные никогда не покидают свое первоначальное местоположение. Этот второй вариант лежит в основе федеративного обучения, которое позволяет моделям обучаться на распределенных данных, не перемещая их. Хорошо известный пример — Google Gboard на Android, где такие функции, как прогнозирование следующего слова и Smart Compose, работают на сотнях миллионов устройств.
Федеративное обучение: перенос модели на данные
Федеративное обучение можно рассматривать как систему совместного машинного обучения, в которой обучение происходит без сбора данных в одном центральном месте. Прежде чем рассматривать его внутреннюю работу, давайте посмотрим несколько реальных примеров, демонстрирующих важность этого подхода в условиях высокого риска, охватывающих области от здравоохранения до сред, чувствительных к вопросам безопасности.
Здравоохранение
В здравоохранении федеративное обучение позволило проводить раннюю диагностику COVID-19 с помощью системы Curial AI , обученной в нескольких больницах Национальной службы здравоохранения Великобритании на основе рутинных показателей жизненно важных функций и анализов крови. Поскольку данные пациентов не могли передаваться между больницами, обучение проводилось локально в каждом учреждении, и обменивались только обновлениями модели. Полученная глобальная модель показала лучшие обобщающие результаты, чем модели, обученные в отдельных больницах, особенно при оценке на неизвестных ранее учреждениях.
Медицинская визуализация

Федеративное обучение также изучается в медицинской визуализации. Исследователи из Университетского колледжа Лондона и глазной больницы Мурфилдс используют его для тонкой настройки базовых моделей обработки больших изображений на чувствительных снимках глаза, которые невозможно централизовать.
Защита
Помимо здравоохранения, федеративное обучение применяется и в областях, чувствительных к вопросам безопасности, таких как оборона и авиация. В этих областях модели обучаются на распределенных физиологических и оперативных данных, которые должны оставаться локальными.
Различные типы федеративного обучения
В общих чертах, федеративное обучение можно разделить на несколько распространенных типов в зависимости от того, кто является клиентами и как распределяются данные .
• Федеративное обучение между различными устройствами и между изолированными средами
Федеративное обучение на разных устройствах Это предполагает использование множества клиентов, число которых может достигать миллионов, например, персональных устройств или телефонов, каждое из которых имеет небольшой объем локальных данных и ненадежное соединение. Однако в любой конкретный момент времени в каждом раунде участвует лишь небольшая часть устройств. Google Gboard — типичный пример такой схемы.
С другой стороны , междисциплинарное федеративное обучение… Включает в себя гораздо меньшее количество клиентов, обычно это такие организации, как больницы или банки. Каждый клиент владеет большим набором данных и имеет стабильные вычислительные ресурсы и подключение к сети. Большинство реальных сценариев использования в корпоративной среде и здравоохранении выглядят как межотраслевое федеративное обучение.
• Горизонтальное против вертикального федеративного обучения

Горизонтальное федеративное обучение описывает способ распределения данных между клиентами. В этом случае все клиенты используют одно и то же пространство признаков, но каждый хранит разные выборки. Например, несколько больниц могут регистрировать одни и те же медицинские переменные, но для разных пациентов. Это наиболее распространенная форма федеративного обучения.
Вертикальное федеративное обучение используется, когда клиенты используют один и тот же набор сущностей, но имеют разные характеристики. Например, больница и страховая компания могут иметь данные об одних и тех же людях, но с разными атрибутами. В этом случае обучение требует надежной координации, поскольку пространства признаков различаются, и такая схема встречается реже, чем горизонтальное федеративное обучение.
Эти категории не являются взаимоисключающими. Реальная система часто описывается с использованием обеих осей, например, система горизонтального федеративного обучения, охватывающая несколько уровней .
Как работает федеративное обучение
Федеративное обучение представляет собой простой, повторяющийся процесс, координируемый центральным сервером и выполняемый множеством клиентов, хранящих данные локально, как показано на диаграмме ниже.

Обучение в федеративном обучении происходит посредством многократных раундов федеративного обучения . В каждом раунде сервер выбирает небольшое случайное подмножество клиентов, отправляет им текущие веса модели и ожидает обновлений. Каждый клиент обучает модель локально, используя стохастический градиентный спуск , обычно в течение нескольких локальных эпох на своих собственных пакетах данных, и возвращает только обновленные веса. В общих чертах это включает следующие пять шагов:
- Инициализация
На сервере создается глобальная модель, которая выступает в роли координатора. Модель может быть инициализирована случайным образом или начинать работу с предварительно обученного состояния.
2. Распределение модели
В каждом раунде сервер выбирает набор клиентов (на основе случайной выборки или заранее определенной стратегии), которые участвуют в обучении, и отправляет им текущие глобальные веса модели. Этими клиентами могут быть телефоны, устройства IoT или отдельные больницы.
3. Обучение на местном уровне
Затем каждый выбранный клиент обучает модель локально, используя свои собственные данные. Данные никогда не покидают клиентское устройство, и все вычисления происходят на самом устройстве или внутри организации, например, больницы или банка.
4. Коммуникация по обновлению модели
После локального обучения клиенты отправляют на сервер только обновленные параметры модели (это могут быть веса или градиенты), в то время как исходные данные передаются в любой момент времени.
5. Агрегация
Сервер агрегирует обновления, полученные от клиентов, для создания новой глобальной модели. Хотя федеративное усреднение (Fed Avg) является распространенным подходом к агрегированию , используются и другие стратегии. Затем обновленная модель отправляется обратно клиентам, и процесс повторяется до сходимости.
Федеративное обучение — это итеративный процесс, и каждый проход по этому циклу называется раундом. Обучение федеративной модели обычно требует множества раундов, иногда сотен, в зависимости от таких факторов, как размер модели, распределение данных и решаемая задача.
Математическая интуиция, лежащая в основе федеративного усреднения.
Описанный выше рабочий процесс можно также записать более формально. На рисунке ниже показан оригинальный алгоритм федеративного усреднения (Fed Avg) из основополагающей работы Google. Этот алгоритм впоследствии стал основным ориентиром и продемонстрировал, что федеративное обучение может работать на практике. Фактически, эта формулировка стала отправной точкой для большинства современных систем федеративного обучения.

Оригинальный алгоритм федеративного усреднения, демонстрирующий цикл обучения «сервер-клиент» и взвешенное агрегирование локальных моделей.
В основе федеративного усреднения лежит этап агрегирования, на котором сервер обновляет глобальную модель, вычисляя взвешенное среднее локально обученных клиентских моделей. Это можно записать следующим образом:

Это уравнение наглядно демонстрирует вклад каждого клиента в глобальную модель. Клиенты с большим объемом локальных данных оказывают большее влияние, в то время как клиенты с меньшим количеством выборок вносят пропорционально меньший вклад. На практике именно эта простая идея стала причиной того, что Fed Avg стал базовым показателем по умолчанию для федеративного обучения.
Простая реализация на NumPy.
Рассмотрим минимальный пример, в котором выбрано пять клиентов. Для простоты предположим, что каждый клиент уже завершил локальное обучение и вернул обновленные веса своей модели вместе с количеством использованных выборок. Используя эти значения, сервер вычисляет взвешенную сумму, которая создает новую глобальную модель для следующего раунда. Это напрямую отражает уравнение Федеративного уравнения среднего, без добавления деталей, связанных с обучением или обработкой данных на стороне клиента.
import numpy as np # Модели клиентов после локального обучения (w_{t+1}^k) client_weights = [ np.array([1.0, 0.8, 0.5]), # клиент 1 np.array([1.2, 0.9, 0.6]), # клиент 2 np.array([0.9, 0.7, 0.4]), # клиент 3 np.array([1.1, 0.85, 0.55]), # клиент 4 np.array([1.3, 1.0, 0.65]) # клиент 5 ] # Количество выборок у каждого клиента (n_k) client_sizes = [50, 150, 100, 300, 4000] # m_t = общее количество выборок у выбранных клиентов S_t m_t = sum(client_sizes) # 50+150+100+300+400 # Инициализация глобальной модели w_{t+1} w_t_plus_1 = np.zeros_like(client_weights[0]) # Агрегация FedAvg: # w_{t+1} = sum_{k in S_t} (n_k / m_t) * w_{t+1}^k # (50/1000) * w_1 + (150/1000) * w_2 + … for w_k, n_k in zip(client_weights, client_sizes): w_t_plus_1 += (n_k / m_t) * w_k print(«Агрегированная глобальная модель w_{t+1}:», w_t_plus_1) ————————————————————- Агрегированная глобальная модель w_{t+1}: [1.27173913 0.97826087 0.63478261]
Как вычисляется агрегация
Чтобы было понятнее, давайте расширим этап агрегирования всего для двух клиентов и посмотрим, как совпадут цифры.

Проблемы в средах федеративного обучения
Федеративное обучение сопряжено со своими трудностями. Одна из главных проблем при его внедрении заключается в том, что данные между клиентами часто не являются независимыми и одинаково распределенными (non-IID). Это означает, что разные клиенты могут видеть очень разные распределения данных, что, в свою очередь, может замедлить обучение и сделать глобальную модель менее стабильной. Например, больницы в федерации могут обслуживать разные группы населения, которые могут следовать разным моделям поведения.
Федеративные системы могут включать в себя что угодно — от нескольких организаций до миллионов устройств, и управление участием, отсевом и агрегацией становится все сложнее по мере масштабирования системы.
Хотя федеративное обучение сохраняет исходные данные локально, само по себе оно не решает проблему конфиденциальности полностью. Обновления модели по-прежнему могут приводить к утечке конфиденциальной информации, если они не защищены, поэтому часто требуются дополнительные методы обеспечения конфиденциальности. Наконец, источником узкого места может стать коммуникация . Поскольку сети могут быть медленными или ненадежными, а отправка частых обновлений может быть дорогостоящей.
Заключение и дальнейшие планы
В этой статье мы рассмотрели основные принципы работы федеративного обучения на высоком уровне, а также разобрались с простой реализацией на NumPy. Однако вместо написания основной логики вручную, существуют фреймворки, такие как Flower, которые предоставляют простой и гибкий способ построения систем федеративного обучения. В следующей части мы будем использовать Flower для выполнения основной работы, чтобы сосредоточиться на модели и данных, а не на механике федеративного обучения. Мы также рассмотрим федеративные LLM , где размер модели, стоимость обмена данными и ограничения конфиденциальности становятся еще более важными.
Источник: towardsdatascience.com

























